


django路由匹配、反向解析、无名有名反向解析、路由分发、名称空间
django请求生命周期流程图
1.Django请求的生命周期的含义
Django请求的生命周期是指:当用户在浏览器上输入URL到用户看到网页的这个时间段内,Django后台所发生的事情。
2.Django请求的生命周期图解及流程
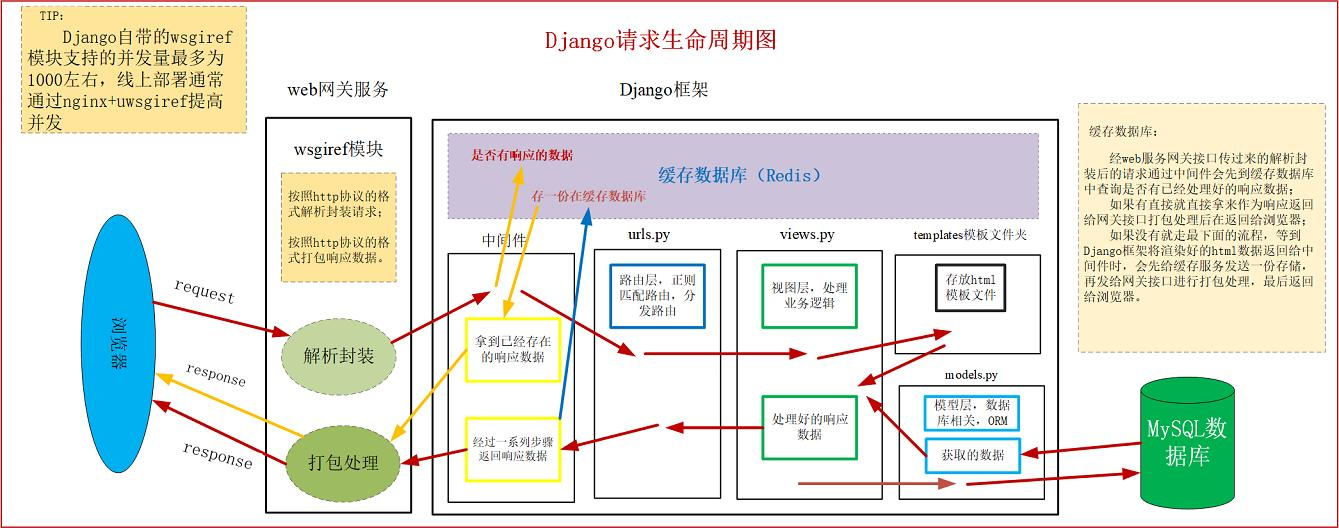
1.浏览器默认市=是基于HTTP协议发送请求的
2.发送请求进入一个web服务网关接口,其实就是wsgiref(帮我们分装了socket代码,帮我们把请求过来的数进行数据处理,变成了一个大字典)它是Django默认的,但是它的并发能力特别低非常差,所以在Django上线之后都会切换为uwsgi,该服务并发能力强,并发量大
3.wsgiref与uwsgi都是属于WSG协议,它们俩个是实现这个协议的模块
4.请求进来的时候拆建数据,响应走的时候封装数据
------->进入了Django后端
1.首先会经过一个Django中间件,请求会经过它的层层筛选,才会进入urls.py
2.urls.py(路由层),进来之后完成一个地址的匹配,查看功能是否开设好了,如果开设好了就会进入views.py(视图层),执行核心逻辑,如果需要模板进入模板层
3.templates文件夹(模板层),models.py(模型层),模板层可能会需要用到模板语法,然后进入模型层拿取数据,用orm进入数据库操作数据,返回一个数据,然后orm会操作封装成对象,回到views.py层,然后会做一个模板渲染,最后依次返回
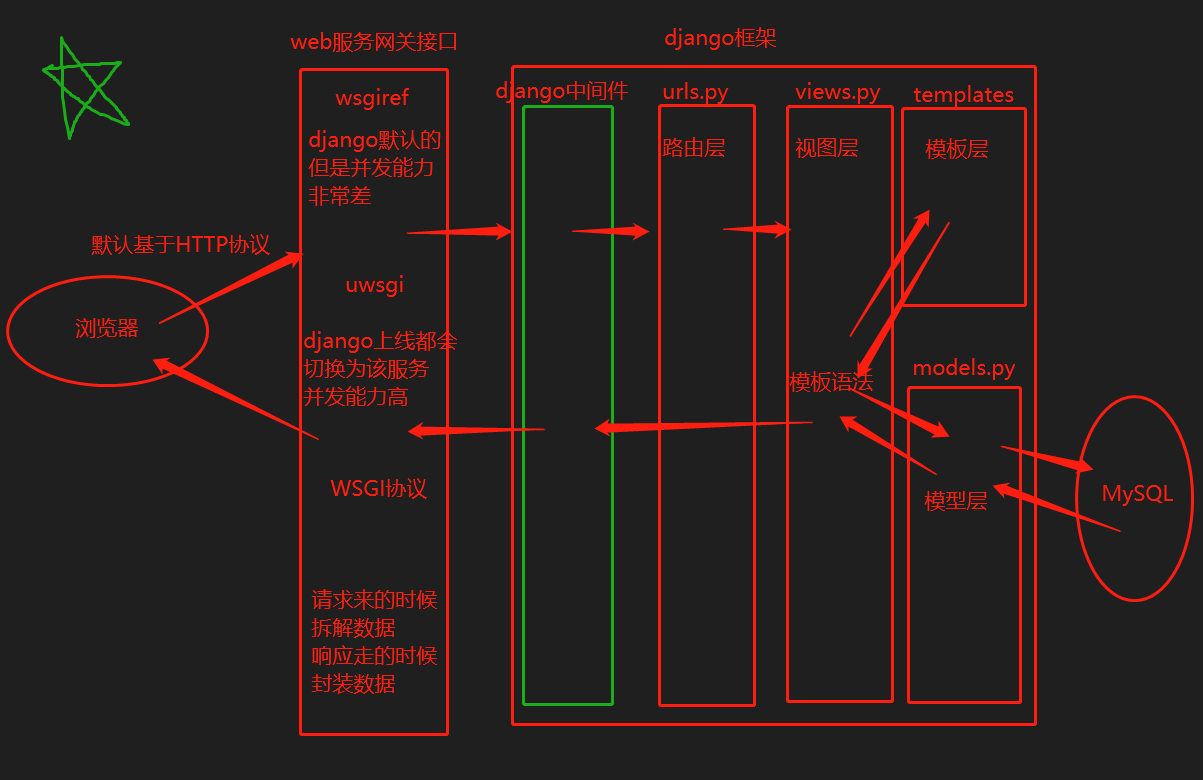
3.Django的请求生命周期(分步解析)
浏览器
发送请求(HTTP协议)
web服务网关接口
1.请求来的时候解析封装
响应走的时候打包处理
2.django默认的wsgiref模块不能承受高并发 最大只有1000左右
上线之后会替换成uwsgi来增加并发量
3.WSGI跟wsgiref和uwsgi是什么关系
WSGI是协议
wsgiref和uwsgi是实现该协议的功能模块
django后端
1.django中间件(暂时不考虑 后面讲)
类似于django的保安 门户
2.urls.py 路由层
识别路由匹配对应的视图函数
3.views.py 视图层
网站整体的业务逻辑
4.templates文件夹 模版层
网站所有的html文件
5.models.py 模型层
ORM
额外扩展:缓存数据库的作用
路由层
1.路由匹配
path('网址后缀',函数名)
一旦网址后缀匹配上了就会自动执行后面的函数
并结束整个路由的匹配
ps:ip和端口号后面必须要家斜杠的
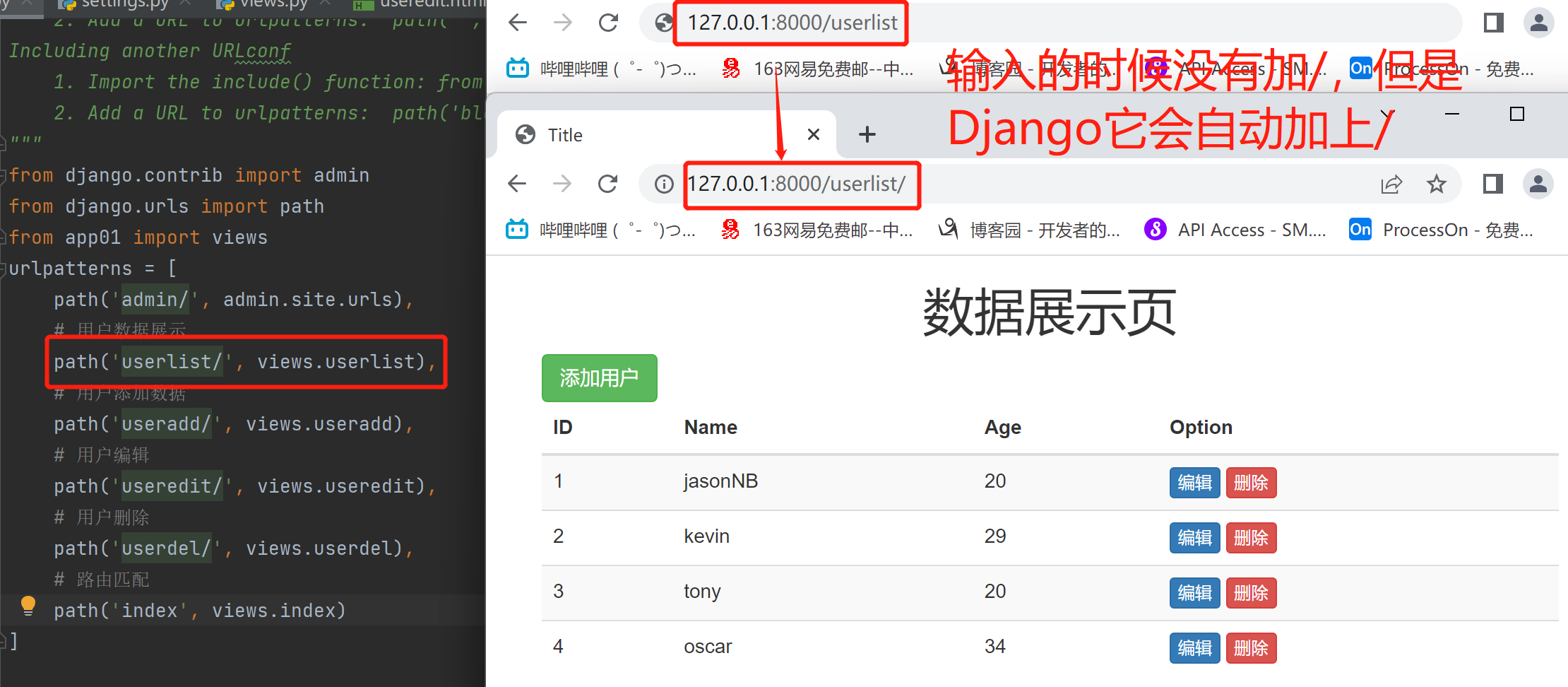
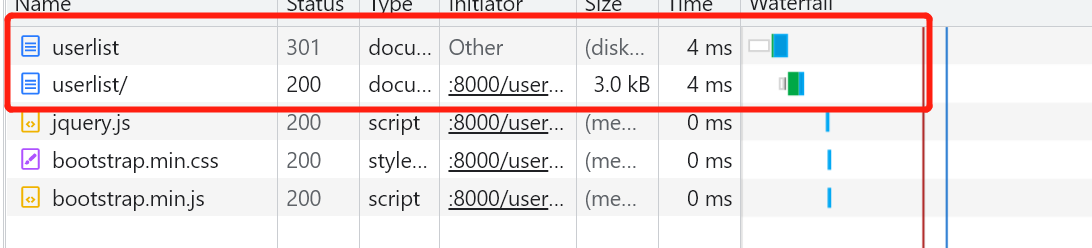
不加/去请求访问的时候原理
首先它会去查看一遍有没有这个地址,然后发现没有,301是重定向的状态码,那么此时它会考虑给加一个/去重新执行一次,所有就有了俩次
路由结尾的斜杠
默认情况下不写斜杠 django会做二次处理
第一次匹配不上 会让浏览器加斜杠再次请求
django配置文件中可以指定是否自动添加斜杠
APPEND_SLASH = False(默认是True,改成false的时候,不加的话就不能访问到了)
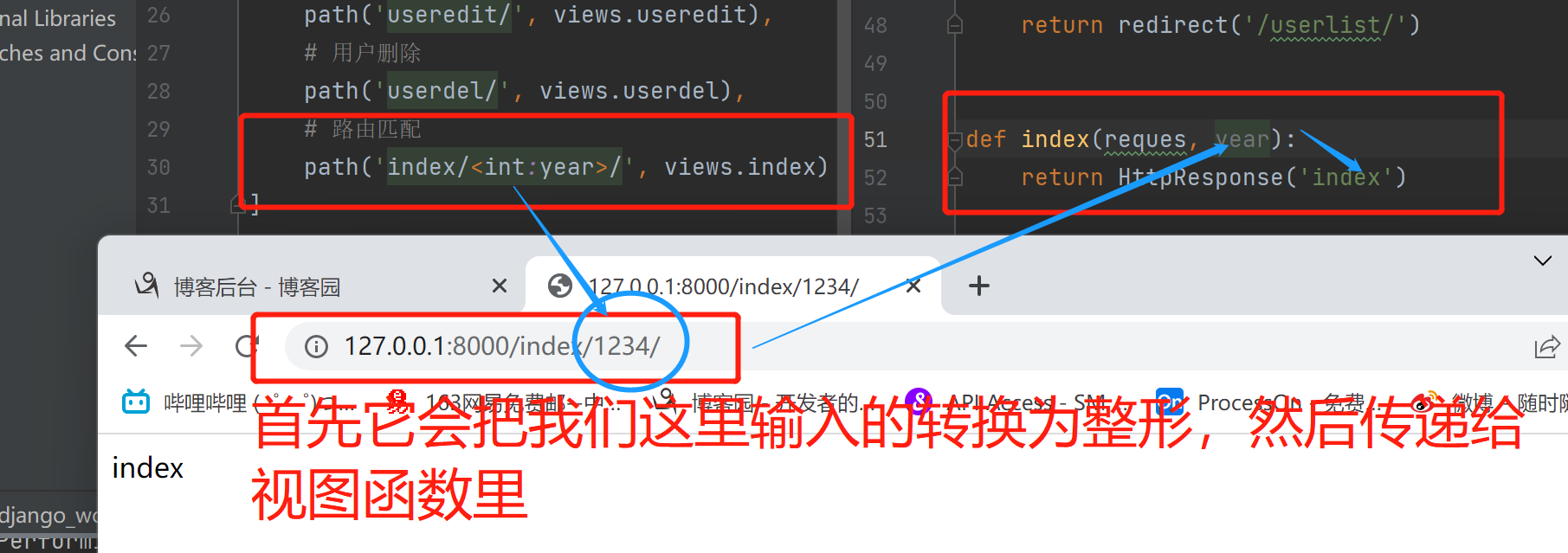
2.path转换器
转换器只有在django2以上才会有
当网址后缀不固定的时候 可以使用转换器来匹配
'int': IntConverter(),
'path': PathConverter(),
'slug': SlugConverter(),
'str': StringConverter(),
'uuid': UUIDConverter(),
以后不知道固定的视图函数后面写什么就这么写:
path('func/<int:year>/<str:info>/', views.func)
转换器匹配到的内容会当做视图函数的关键字参数传入
转换器有几个叫什么名字 那么视图函数的形参必须对应
def func(request,year,info):
pass
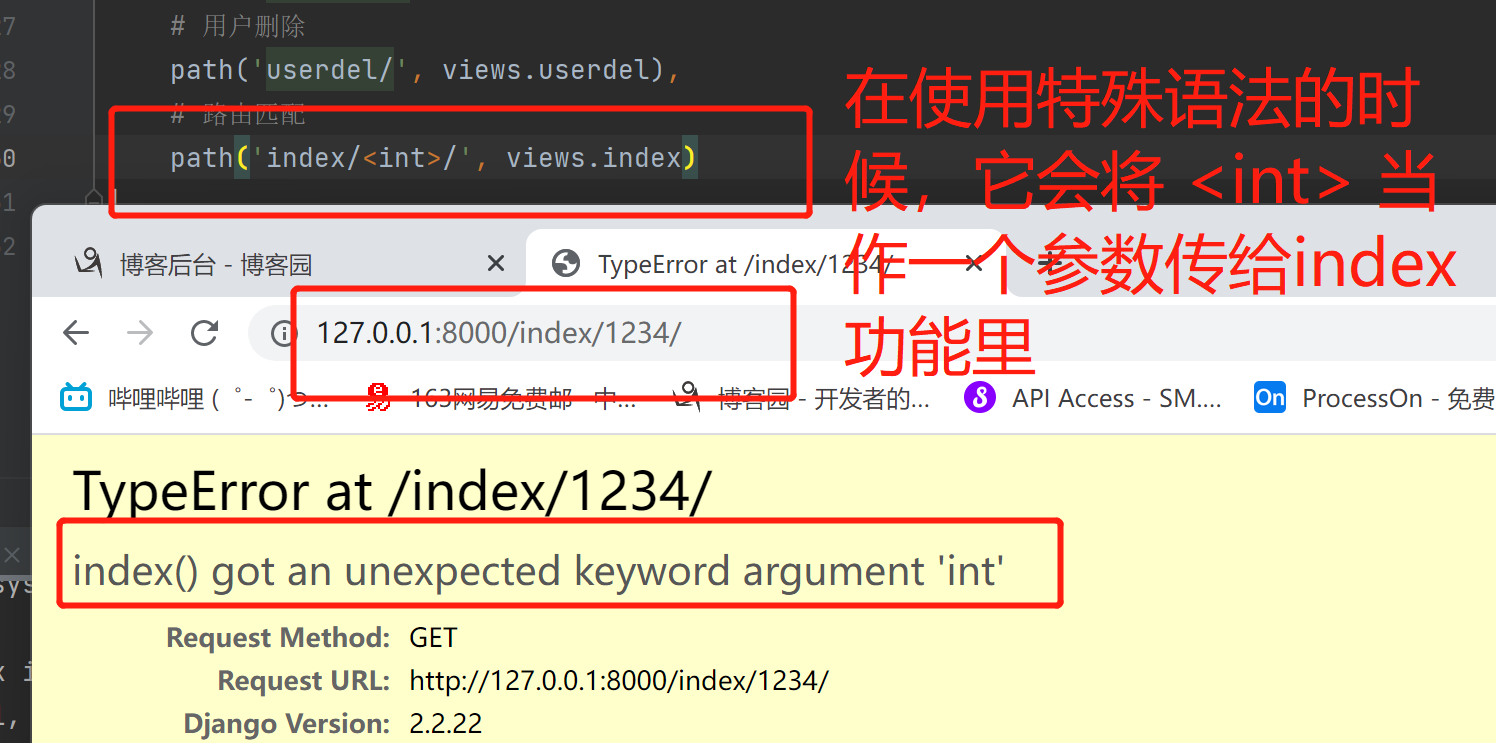
在固定的路由后面添加些不确定的数
3.re_path正则匹配
re_path('test', views.test),
re_path('testadd', views.testadd),
输入网址:http://127.0.0.1:8000/testadd的时候,返回的是test的内容,re_path的特点是在我们输入的网址的后缀,它会去匹配,只要能匹配到这个后缀的,就算匹配上了
1.怎么去区分开呢??
re_path('test/', views.test),
re_path('testadd/', views.testadd),
加上/后它完整的是test/,所以它只能匹配到它自己的
2.但是还存在问题
http://127.0.0.1:8000/wfdrfffg/test/egddddddd/6ygg
这个样子还能匹配到,不太精准
那么如果想要使用正则去做匹配的话,在前面加上^,后面加上$
re_path('^test/$', views.test)
3.re_path(正则表达式,函数名)
一旦网址后缀的正则能够匹配到内容就会自动执行后面的函数
并结束整个路由的匹配
当网址后缀不固定的时候 可以使用转换器来匹配
4.正则匹配之无名分组
re_path('^test/(\d+)/', views.test)
正则表达式匹配到的内容会当做视图函数的位置参数传递给视图函数
5.正则匹配之有名分组
re_path('^test/(?P<year>\d+)/(?P<others>.*?)/', views.test)
正则表达式匹配到的内容会当做视图函数的关键字参数传递给视图函数
6.django版本区别
在django1.11中 只支持正则匹配 并且方法是 url()
django2,3,4中 path() re_path() 等价于 url()
反向解析
1.什么是反向解析
当路由频繁变化的时候,html界面与后端上的连接地址如何做到动态解析?
根据自己设置的一个别名,动态解析出一个结果,该结构可以直接访问对应的url
2.反向解析概念
通过一些方法得到一个结果 该结果可以直接访问对应的url触发视图函数
实现url路由频繁变化,html界面与后端动态解析连接地址操作步骤:
3.反向解析路由配置
1.先给路由与视图函数起一个别名
url(r'^func_kkk/',views.func,name='ooo') # name='ooo' 起别名
4.前后端反向解析
# 后端视图函数反向解析
1.导入模块reverse
from django.shortcuts import render,HttpResponse,redirect,reverse
2.反向解析 关键字 reverse('ooo')
def home(request):
print(reverse('ooo'))
return render(request,'home.html')
# 前端反向解析
3.前端模板文件反向解析
<a href="{% url 'ooo' %}">111</a>
5.无名有名反向解析
1.当路由出现无名有名分组反向解析需要传递额外的参数
2.无名有名分组反向解析,目的就是需要给一个参数,如果有多个就是需要手动的给多个,这多个参数一般情况都是当前操作数据的主键值。
path('reg/<str:info>/', views.reg, name='reg_view')
当路由中有不确定的匹配因素 反向解析的时候需要人为给出一个具体的值
后端:
reverse('reg_view', args=('jason',))
前端:
{% url 'reg_view' 'jason' %}
ps:反向解析的操作三个方法都一样path() re_path() url()
路由分发
1.django是专注于开发应用的,当一个django项目特别庞大的时候,所有的路由与视图函数映射关系全部写在项目名下urls.py(总路由层),很明显太冗余也不便于管理,这个时候也可以利用路由分发来减轻总路由的压力。
2.django的每一个应用(app)都可以有自己独立的urls.py路由器,static文件夹,templates文件夹。
3.基于上述特点,使用django做分组开发非常的简便。每个人只需要写自己的应用即可,互不干扰。最后由组长统一汇总到一个空的django项目中然后使用路由分发将多个应用关联在一起,即可完成大项目的拼接。
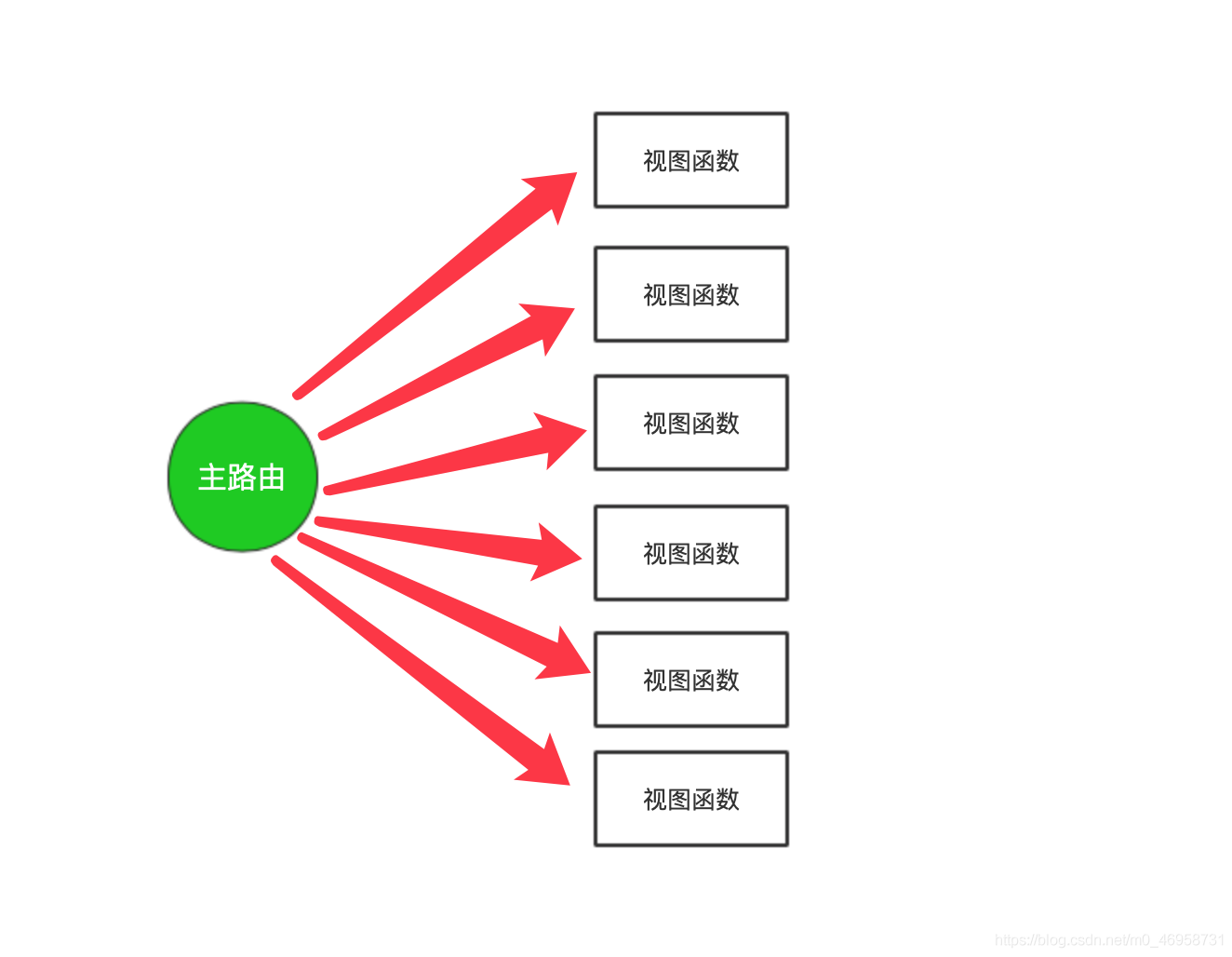
路由分发解决的就是项目的总路由匹配关系过多的情况
利用路由分发之后 总路由不再干路由与视图函数的直接对应关系
总路由而是做一个分发处理(识别当前url是属于那个应用下的 直接分发对应的应用去处理)
请求来了之后 总路由不做对应关系 只询问你要访问哪个app的功能 然后将请求转发给对应的app去处理
提前创建好 应用app01 应用app02 然后记得注册
1.总路由配置
# 1.需要导入一个include路由分发模块
from django.conf.urls import url,include
# 2.导入子路由的uls(重名问题 起别名)
from app01 import urls as app01_urls
from app02 import urls as app02_urls
urlpatterns = [
path('admin/', admin.site.urls),
# 1.路由分发
path('app01/',include(app01_urls)), # 只要url前缀是app01开头 全部交给app01下的urls处理
path('app02/',include(app02_urls)) # 只要url前缀是app02开头 全部交给app02下的urls处理
]


名称空间
当多个应用出现了相同的别名 我们研究反向解析会不会自动识别应用前缀
反向解析:正常情况下的反向解析是没有办法自动识别前缀的
解决 方式一:名称空间
# 总路由增加一个名称空间
path('app01/', include(('app01.urls', 'app01'), namespace='app01')), # 创建名称空间app01
path('app01/', include(('app01.urls', 'app02'), namespace='app02')), # 创建名称空间app02
# 子路由app01
urlpatterns = [
path('after/',views.after, name='after_view')
]
# 后端
def reg(request):
print(reverse('app01:after_view'))
return HttpResponse('下午好 from app01')
# 前端
{% url 'app01:after_view' %}
解决 方式二:起别名
# 子路由app01
urlpatterns = [
path('after/',views.after, name='app01_after_view')
]
# 后端
def reg(request):
print(reverse('app01_after_view'))
return HttpResponse('下午好 from app01')
# 前端
{% url 'app01:after_view' %}
1.其实只要保证名字不冲突 就没有必要使用名称空间
2.解决方法
一般情况下 有多个app的时候我们在起别名的时候会加上app的前缀
这样的话就能够确保多个app之间名字不冲突的问题

