



事务、存储过程
目录
一、事务
1.事务的四大特性(ACID)
A:原子性
每个事务都是不可分割的最小单位(同一个事务内的多个操作要么同时成功要么同时失败)
C:一致性
事务必须是使数据从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的
I:隔离性
事务与事务之间彼此不干扰
D:持久性
一个事务一旦提交,它对数据库中数据的改变就应该是永久性的
2.事务存在的必要性
比如银行ATM机,转账功能比喻:
A有1000元,B有1000元,C有1000元
A使用工行 通过交行ATM机给B转账90元
A使用工行 通过交行ATM机给C转账10元
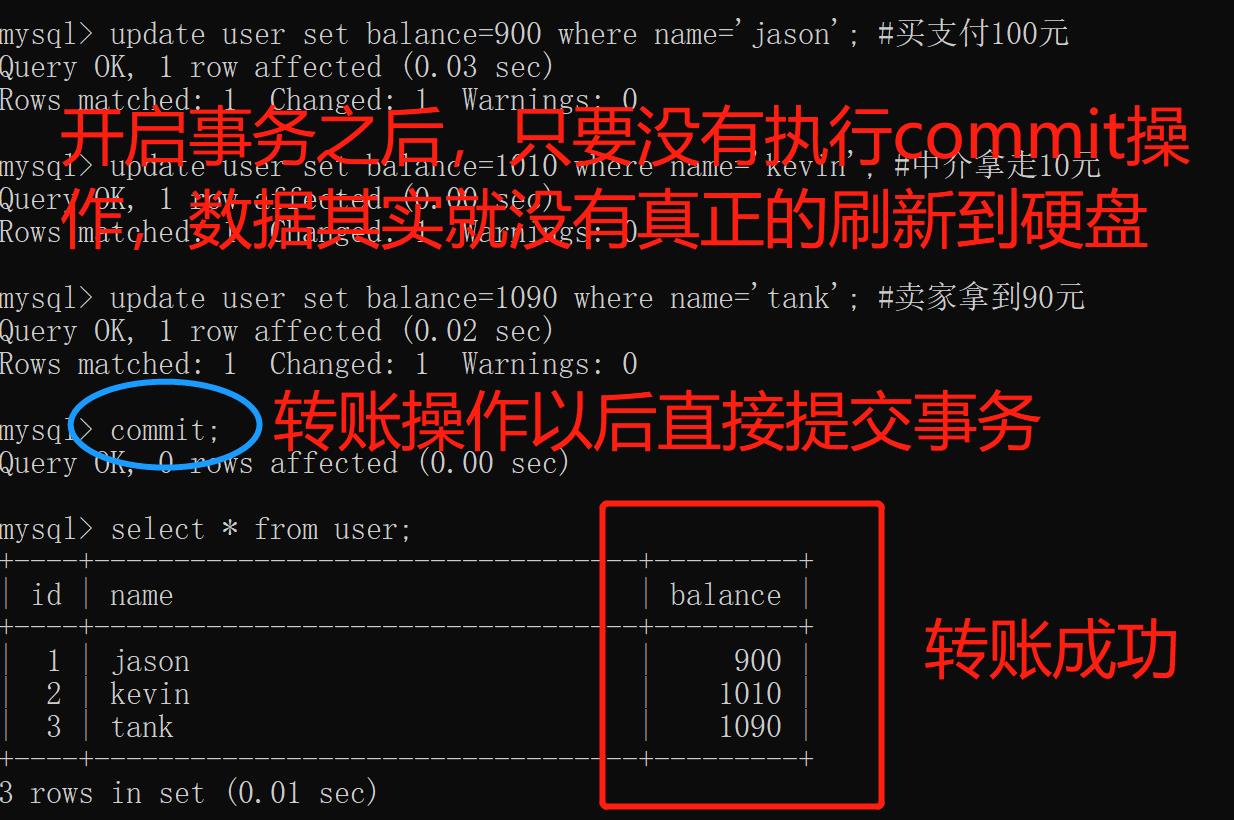
A有900元,B有1090元,C有1010元
create table user(
id int primary key auto_increment,
name char(32),
balance int
);
insert into user(name,balance)
values
('jason',1000),
('kevin',1000),
('tank',1000);
# 修改数据之前先开启事务操作
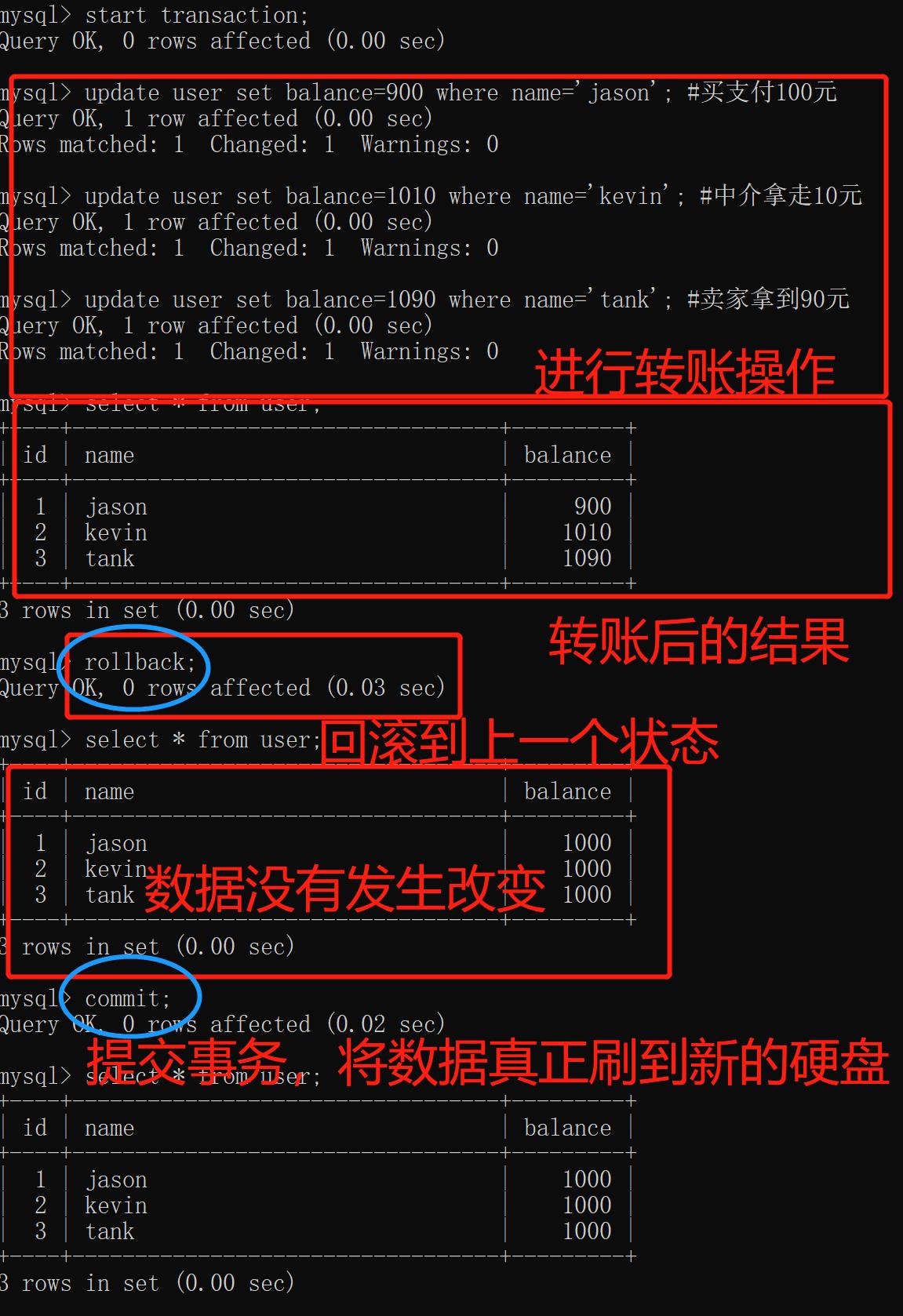
start transaction;
# 修改操作
update user set balance=900 where name='jason'; #买支付100元
update user set balance=1010 where name='kevin'; #中介拿走10元
update user set balance=1090 where name='tank'; #卖家拿到90元
'''
但是在事物里边这个数据还没有到硬盘中,在内存中,还没有保存。
现在这个状态还可以回退,我反悔了我不买了(双方同时失败)
回滚操作:rollback;
'''
# 回滚到上一个状态
rollback;
# 开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘
commit;
"""开启事务检测操作是否完整,不完整主动回滚到上一个状态,如果完整就应该执行commit操作"""
# 站在python代码的角度,应该实现的伪代码逻辑,
try:
update user set balance=900 where name='jason'; #买支付100元
update user set balance=1010 where name='kevin'; #中介拿走10元
update user set balance=1090 where name='tank'; #卖家拿到90元
except 异常:
rollback;
else:
commit;
3.开启事务-回滚-确认
开启事务
start transaction;
回滚
rollback;
确认
commit;
4.总结事务
1.开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘
2.开启事务检测操作是否完整,不完整主动滚回上一个状态,如果完整就应该执行commit操作
5.扩展事务
事务处理中有几个关键词汇会反复出现
事务(transaction)
回滚(rollback)
提交(commit)
保留点(savepoint)
为了支持回退部分事务处理,必须能在事务处理块中合适的位置放置占位符,这样如果需要回退可以回退到某个占位符(保留点),但是它违反了事务的原理,是一个冷门知识
创建占位符可以使用savepoint
savepoint sp01;
回退到占位符地址
rollback to sp01;
# 保留点在执行rollback或者commit之后自动释放
6.隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改
InnoDB支持所有隔离级别
set transaction isolation level 级别
1.read uncommitted(未提交读)
事务中数据修改即使没有提交,对其他事务也都是可见的,在内存中,没有提交到硬盘,别人可能也是引用的我内存中的数据,读的是修改的但是没有提交的,该现象称之为“脏读”
2.read committed(提交读)
大多数数据库系统默认的隔离级别
一个事务从开始直到提交之前所作的任何修改对其他事务都是不可见的,这种级别也叫做"不可重复读"
该事务修改了,只要没有提交,别人是不可读的,其他人用的就是没有改之前原表里面的数据,两者之间不会发生冲突,该现象称之为“不可重复读”
3.repeatable read(可重复读)
MySQL默认隔离级别
能够解决"脏读"问题,但是无法解决"幻读"
所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题
4.serializable(可串行读)
强制事务串行执行,很少使用该级别
一个个排队执行,效率太低,不可能使用
7.事务日志
事务日志可以帮助提高事务的效率
存储引擎在修改表的数据时只需要修改其内存拷贝再把该修改记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘
事务日志采用的是追加方式因此写日志操作是磁盘上一小块区域内的顺序IO而不像随机IO需要次哦按的多个地方移动磁头所以采用事务日志的方式相对来说要快的多
事务日志持久之后内存中被修改的数据再后台可以慢慢刷回磁盘,目前大多数存储引擎都是这样实现的,通常称之为"预写式日志"修改数据需要写两次磁盘
8.锁
读锁
多个用户同一时间可以同时读取一个资源互不干扰
写锁
一个写锁会阻塞其他的写锁和读锁
死锁
1.多个事务试图以不同的顺序锁定资源时就可能会产生死锁
2.多个事务同时锁定同一个资源时也会产生死锁
二、存储过程
1.什么是存储过程?
存储过程包含了一系列可执行的sql语句,存储过程存放MySQL中,通过调用它的名字可以执行其内部的一堆sql,类似于python中的自定义函数
2.存储过程格式
关键字: procedure
格式:
create procedure 函数名(参数)
begin
功能体代码
end
调用其内部sql代码格式
call 函数名()
查看存储过程具体信息
show create procedure status;
查看所有存储过程
show procedure status;
删除存储过程
drop procedure pro2;
3.无参存储过程
delimiter $$ # 修改结束符
create procedure p1()
begin
select * from user;
end $$
delimiter ; # 修改回来结束符
# 通过p1()调用其内部sql代码
call p1();
4.有参存储过程
delimiter $$
create procedure p2(
in m int, # in表示这个参数必须只能是传入不能被返回出去
in n int,
out res int # out表示这个参数可以被返回出去,还有一个inout表示即可以传入也可以被返回出去
)
begin
select * from user where id > m and id < n;
set res=0; # 用来标志存储过程是否执行
end $$
delimiter ;
# 针对res需要提前定义
set @res=10; # 定义/赋值 # 指定res=10
select @res; # 查看
call p2(1,3,@res); # 调用
select @res; # 调用
5.pyMySQL代码调用存储过程
import pymysql
# 创建链接
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='123',
db='db6',
charset='utf8',
autocommit=True # 涉及到增删改,二次确认
)
# 生成一个游标对象(操作数据库)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 调用存储过程固定语法callproc('p2',(1,3,10))
cursor.callproc('p2',(1,3,10)) # 内部原理 @_p1_0=1,@_p1_1=3,@_p1_2=10;
# 查看结果
print(cursor.fetchall())


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!