
垃圾回收机制、字符编码与文件操作
垃圾回收机制
说明:我们在编写代码的时候涉及到存储空间的申请和存储空间的释放的操作,在python中它会帮我们去处理这些事情,但是其他编程语言需要我们自己去申请存储空间或者释放存储空间。
垃圾数据:
name = 'dog'
name1 = 'cat'
name = name1
print(name) # cat
'''此时name指向的是cat,不再是dog,那么dog就变为了垃圾数据'''
引用计数
数据值被谁用过
当数据值的引用计数变为0的时候,它就会被垃圾回收机制回收,如果不为0说明该数据值还有用,不会被删掉
标记清除
将内存中程序产生的所有数据值全部检查一遍,就是看有没有俩个数据值没有变量名但是一直循环使用,那么他就会检测到然后标记后一次性清除,每隔一段时间就会将所有的数据排查一遍
'''循环引用:数据直接互相循环引用'''
l1 = ['java',]
l2 = ['python',]
l1.append(l2) # 引用计数为2
l2.append(l1) # 引用计数为2
del l1 # 解除变量名l1与列表的绑定关系,列表引用计数-1
del l2 # 解除变量名l2与列表的绑定关系,列表引用计数-1
print(l1)
print(l2)
分代回收
因为标记清除每隔一段时间就需要去排查一遍数据,消耗资源太大,所有我们可以用分代回收来处理数据,经常用的数据先放在后面,可能就是隔很长时间去处理一次,将不怎么用的先做优先处理,越往后的数据检测的频率越低用来节约资源,为了节省资源的消耗,开发了三代管理
字符编码
简介
1.只有文本文件才有字符编码的概念
2.计算机内部存储数据的本质是二进制,也就是计算机只认识0和1
3.字符编码表:记录了人类的字符与数字的对应关系
发展史
1.一家独大
计算机是美国人发明,计算机只能识别英文字母,当时并没有考虑其他国家
美国---ASCLII码:内部只记录了英文字符,大写字母与小写字母之间相差32
A-Z 65-90
2.群雄割据
中国--GBK(国标码)
内部记录了中文字符、英文字符与数字对应关系
2bytes起步存储中文(生僻字用的更多的字节),1bytes存储英文
韩国--Euc_kr码
内部记录了韩文字符、英文字符与数字对应关系
日本--shift_JIs码
内部记录了日文字符、英文字符与数字对应关系
ps:各国之间计算机文本文件无法直接交互 会出现乱码的情况,就是在做编码解码的时候使用的编码是不一致的
3.统一
万国码(Unicode):兼容各国字符,它的要求是所有的字符全部使用2bytes进行存储
缺陷:存储英文的时候,ASCLL码与GBK码用的是1bytes,而Unicode使用的是2bytes,,这个时候当我们存储一串英文的时候存储空间就得在原来的基础上翻个倍。
utf家族(针对Unicode的优化版本):1bytes存储英文,3bytes存储其他。
现在内存里用的是Unicode,硬盘里用的是utf家族的
字符编码的实操
1.为什么会出现乱码
存编码的时候与解它的时候的编码不一样,硬盘在加载到内存的时候使用与它相同的编码去解码

2.编码与解码
编码:人类的字符转为计算机的字符
解码:计算机的字符转为人类的字符
'''
只有字符串可以参与编码解码,其他数据类型需要先转换成字符串才可以
在python中bytes类型的数据可以直接看成是二进制数据
保证不乱码的情况就是解码与编码要一致
'''
s1 = 'jason是个大可爱'
res = s1.encode('utf8')
print(res, type(res))
# b'jason\xe6\x98\xaf\xe4\xb8\xaa\xe5\xa4\xa7\xe5\x8f\xaf\xe7\x88\xb1' <class 'bytes'>
# 解码
res1 = res.decode('utf8')
print(res1)
# jason是个大可爱
3.解释器
python2默认解释器是ASCLL码,在使用的时候要在字符串前面加u
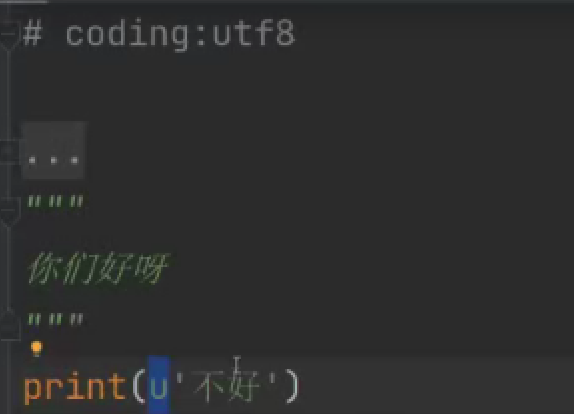
python3默认解释器是utf8
文件操作
1.文件操作?
通过编写代码自动操作文件读写
2.什么是文件?
打开文件,双击文件图标是从硬盘加载数据到内存
保存操作其实就是将内存中的数据刷到硬盘
ps:文件其实是操作系统暴露给用户操作计算机硬盘的快捷方式之一
3.如何代码操作文件?
open(文件路径,读写模式,字符编码)
res = open('aaa.txt', 'r', encoding='utf8')
print(res)
# <_io.TextIOWrapper name='aaa.txt' mode='r' encoding='utf8'>
print(res.read())
# 我是个大聪明
res.close() # 关闭文件
方式1
f = open()
f.close()
方式2
with open() as 变量名:
子代码运行结束之后自动调用close()方法
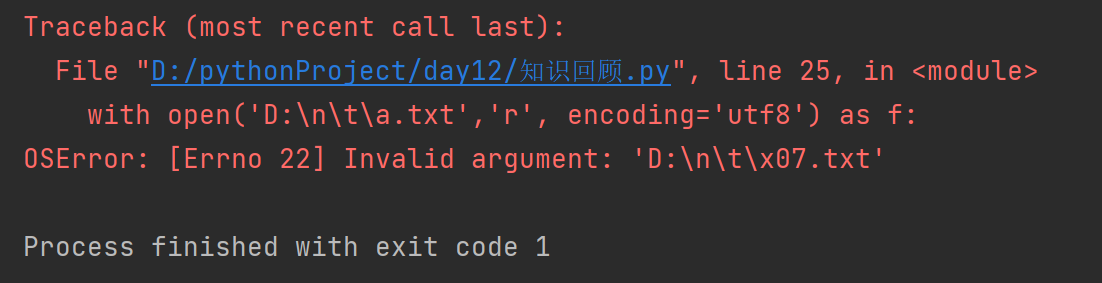
针对文件路径需要注意 可能存在特殊含义(字母与撬棍的组合)
在字符串的前面加字母r即可取消特殊含义
# with open('D:\n\t\a.txt','r', encoding='utf8') as f:
# print(f.read())
with open(r'D:\n\t\a.txt','r', encoding='utf8') as f:
print(f.read()) # 来打我啊
作业
1.统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
# 1.统计列表中每个数据值出现的次数并组织成字典展示
# eg: l1 = ['jason','jason','kevin','oscar']
# 结果:{'jason':2,'kevin':1,'oscar':1}
# 真实数据
l1 = ['jason', 'jason', 'kevin', 'oscar', 'kevin', 'tony', 'kevin']
# 先设置一个空字典
empty_dict = {}
for i in l1:
if i in empty_dict:
empty_dict[i] += 1
else:
empty_dict[i] = 1
print(empty_dict) # {'jason': 2, 'kevin': 3, 'oscar': 1, 'tony': 1}
