HDFS原理
HDFS由namenode以及datanode两个角色组成
NameNode
作用
1、NameNode 负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名、数据块的 ID 以及存储位置等信息
2、接受DD上报的信息
3、给DD分配任务(维护副本数)
元数据的存储文件方式:edits与fsimages
元数据保存于内存+硬盘(fsimage文件、edits文件中),内存中的全量数据用于加速NameNode读取处理元数据的速度,而持久化的fsimage以及edits用于配合保存元数据,在能保证元数据安全的前提下加快保存恢复的速度,edits提升增量写元数据的速度,fsimages(执行checkpoint策略:1h or 100万次操作)用于整合或者合并操作,加速恢复内存元数据所用
存放于${hadoop_home}/data/tmp/dfs/name/current
其实分布式文件系统玩的就是元数据,由NameNode管理分布式机器中的文件,就是管理分布式机器中文件的元数据而已
fsimage
第一次格式化后生成一个fsimages文件(fsimage_000000000)
NN启动时会将所有的edits和fsimage文件全部加载到内存合并得到最新的元数据,并将合并后的元数据持久化到一个新的fsimage中
edits
NN启动后每次的写命令都会记录到edits文件中
edits文件每隔一段时间或大小就会滚动生成一个新的edits文件
edits_inprogress表示正在写入的文件
上传后操作动作会写入edits_inprogress_000000000001文件,读操作不记录
<inode> <id>16386</id> <type>FILE</type> <name>hello</name> <replication>3</replication> <mtime>1629810520020</mtime> <atime>1629810519641</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>hadoop:supergroup:rw-r--r--</permission> <blocks> <block> <id>1073741825</id> <genstamp>1001</genstamp> <numBytes>27</numBytes> </block> </blocks> </inode> <inode> <id>16387</id> <type>DIRECTORY</type> <name>wc</name> <mtime>1629810620719</mtime> <permission>hadoop:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode>
NameNode元数据管理流程
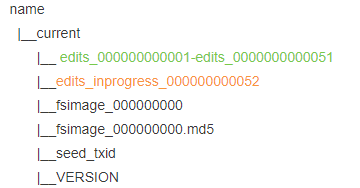
当写入一段时间后,edits文件会把之前的51次操作生成一个edits_000000000001-edits_0000000000051文件,关闭
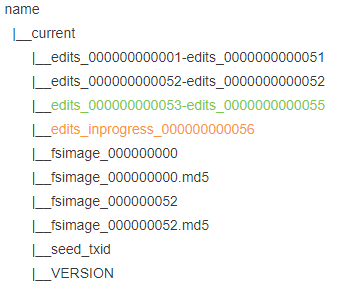
DataNode
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验(crc校验算法,用户数据完整性校验)和,以及时间戳(mate)
${hadoop_home}/data/tmp/dfs/data/current/BP-1077754861-192.168.126.128-1629810385198/current/finalized/subdir0/subdir0
DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟(可以配置)没有收到某个DataNode的心跳,则认为该节点不可用
NameNode启动时,将所有的元数据加载完后,等待DataNode上报数据,如果上报的数据不全就会进入安全模式
当安全模式时,无法写,只能部分读
上报了的块数(不考虑副本)/总块数<99.99 就会进入安全模式,举个例子,比如有13个块,你只上报了10个块,那么就会进入安全模式
当安全模式时,只能部分读指的是单个文件对应的所有的块都已经上报了则可以读,否则不可以读
HDFS特点
HDFS不支持对文件的随机写,只能追加不能修改
文件在HDFS上存储时,以block为基本单位存储
没有提供对文件的在线寻址(打开)功能
文件以块形式存储,修改了一个块中的内容,就会影响当前块之后所有的块,效率低
HDFS不适合存储小文件
在线归档的功能实际是一个MR程序,这个程序将HDFS已经存在的多个小文件归档为一个归档文件
HDFS存储了大量的小文件,会降低NN的服务能力
NameNode负责文件元数据(属性,块的映射)的管理,NN在运行时,必须将当前集群中存储所有文件的元数据全部加载到内存
存过多小文件会导致NN占用大量内存
默认块大小为128M,128M指的是块的最大大小,每个块最多存储128M的数据,如果当前块存储的数据不满128M,存了多少数据,就占用多少的磁盘空间
一个块只能属于一个文件
HDFS写数据原理
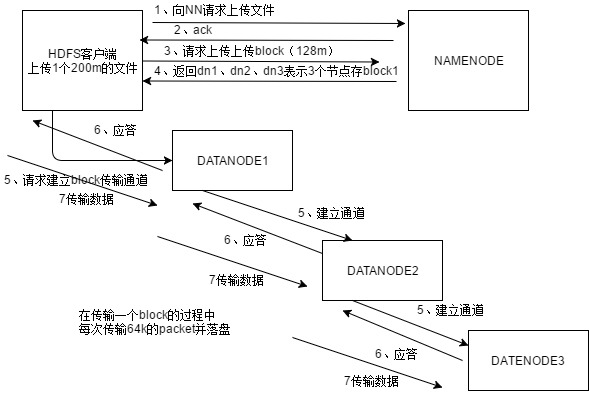
HDFS读数据流程
先从NameNode获取元数据,然后挑选DataNode,请求下载,以packet为单位接收,本地缓存后写入目标文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号