数据采集与融合技术实践第四次实验作业
数据采集与融合技术实践第四次实验作业
作业①:
1.题目
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生自由选择
-
输出信息:MySQL数据库存储和输出格式如下:
![]()

2.实验思路
class Test41Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
pass
items.py中写上这次作业需要爬取的信息
def start_requests(self):
url = "http://search.dangdang.com/?"
for page in range(1, 4):
params = {"key": "python",
"act": "input",
"page_index": str(page)}
# 构造get请求
yield scrapy.FormRequest(url=url, callback=self.parse, method="GET",
headers=self.headers,formdata=params)
首先在start_requests函数中实现参数的设置来进行翻页操作,爬取3页的书本内容
def parse(self, response):
try:
data=response.body.decode("gbk")
selector = scrapy.Selector(text=data)
books = selector.xpath("//*[@id='search_nature_rg']/ul/li")
for book in books:
item = Test41Item()
item["title"] = book.xpath("./a/@title").extract_first()
item["author"] = book.xpath("./p[@class='search_book_author']/span")[0].xpath("./a/@title").extract_first()
item["publisher"] = book.xpath("./p[@class='search_book_author']/span")[2].xpath("./a/text()").extract_first()
item["date"] = book.xpath("./p[@class='search_book_author']/span")[1].xpath("./text()").extract_first()
try:
item["date"] = item["date"].split("/")[-1]
except:
item["date"] = " "
item["price"] = book.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
item["detail"] = book.xpath("./p[@class='detail']/text()").extract_first() if book.xpath("./p[@class='detail']/text()").extract_first() else ""
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
yield item
except Exception as err:
print(err)
在parse函数中进行所需数据的获取,其中date数据进行一个额外的处理,把年月日前的空格和“/”去掉
class Test41Pipeline:
db = DB()
count = 1
def __init__(self):
self.db.openDB() #创建并打开一个表
def process_item(self, item, spider):
try:
self.db.insert(self.count, item['title'], item['author'], item['publisher'], item['date'],
item['price'], item['detail'])
self.count += 1
except Exception as err:
print(err)
return item
在pipelines脚本中,链接mysql数据库并创建一个表,将之前获取到的数据存入mysql数据库中
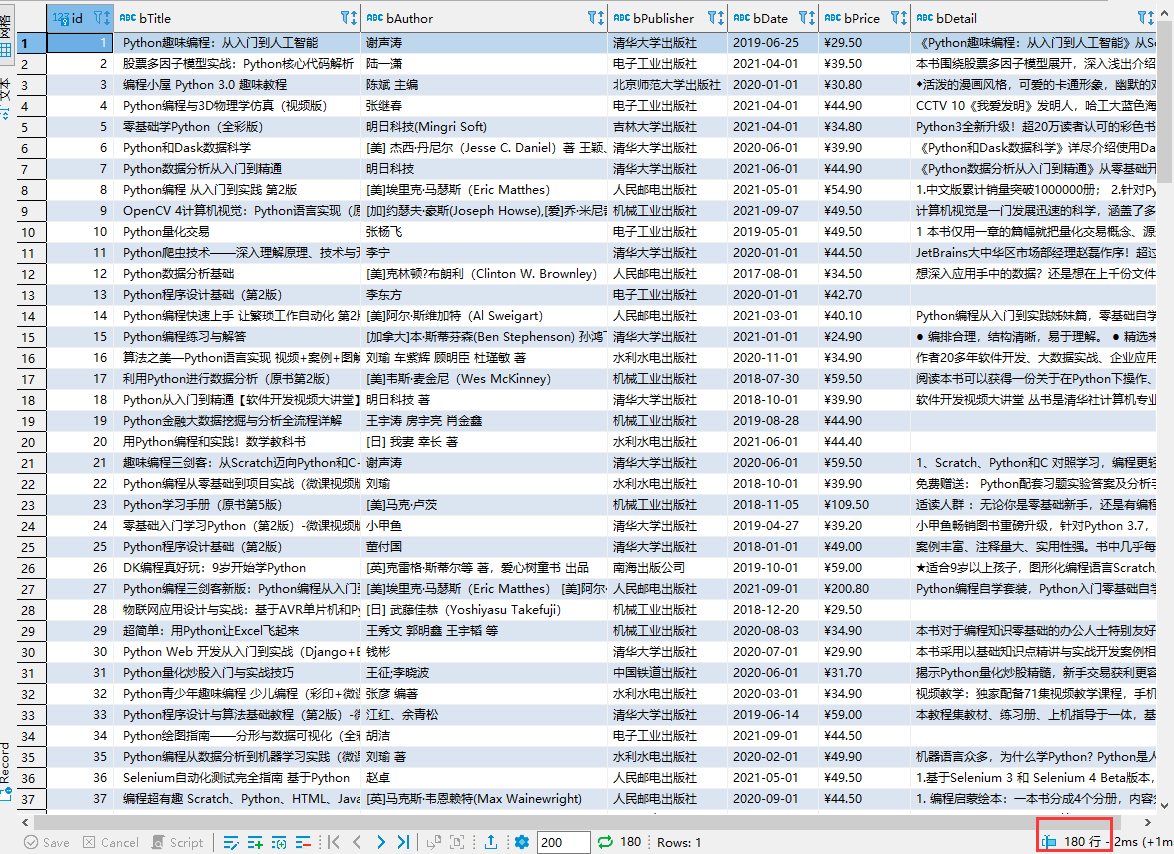
数据库中的信息如上所示,爬取每页60本书本信息共180本
3.心得体会
作业①重温了scrapy框架和xpath,使用scrapy框架爬取当当网的内容,使用xpath解析信息
作业②:
1.题目
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
-
输出信息:MYSQL数据库存储和输出格式
![]()
2.实验思路
class Test42Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
pass
items.py中写上这次作业需要爬取的信息
def start_requests(self):
url = "http://fx.cmbchina.com/hq/"
# 构造get请求
yield scrapy.FormRequest(url=url, callback=self.parse, method="GET",
headers=self.headers)
在start_requests函数中构造get请求
def parse(self, response):
try:
data=response.body.decode("utf-8")
selector = scrapy.Selector(text=data)
#print(data)
trs = selector.xpath("//*[@id='realRateInfo']/table/tr")
for tr in trs[1:]:
item = Test42Item()
item["currency"] = tr.xpath("./td[position()=1]/text()").extract_first().replace("\n","").replace(" ","")
item["tsp"] = tr.xpath("./td[position()=4]/text()").extract_first().replace("\n","").replace(" ","")
item["csp"] = tr.xpath("./td[position()=5]/text()").extract_first().replace("\n","").replace(" ","")
item["tbp"] = tr.xpath("./td[position()=6]/text()").extract_first().replace("\n","").replace(" ","")
item["cbp"] = tr.xpath("./td[position()=7]/text()").extract_first().replace("\n","").replace(" ","")
item["time"] = tr.xpath("./td[position()=8]/text()").extract_first().replace("\n","").replace(" ","")
print(item["currency"])
print(item["tsp"])
print(item["csp"])
print(item["tbp"])
print(item["cbp"])
print(item["time"])
yield item
except Exception as err:
print(err)
观察后在parse函数中使用xpath获取自己需要的数据,并将数据中的换行符和空格去除
class Test42Pipeline:
db = DB()
count = 1
def __init__(self):
self.db.openDB()
def process_item(self, item, spider):
try:
self.db.insert(self.count, item['currency'], item['tsp'], item['csp'], item['tbp'],
item['cbp'], item['time'])
self.count += 1
except Exception as err:
print(err)
return item
最后同作业①,将数据存入数据库中

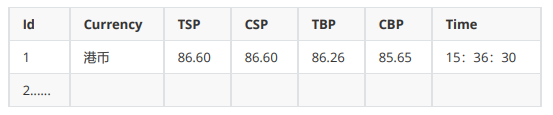
数据库的信息如图所示
3.心得体会
作业②较简单,并再次熟悉了scrapy框架和xpath方法
作业③:
1.题目
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
输出信息:MySQL数据库存储和输出格式如下
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
序号 股票代 码 股 票 名 称 最新 报价 涨跌幅 涨跌 额 成交 量 成 交 额 振幅 最高 最低 今开 昨收 1 688093 N 世 华 28.47 62.22% 10.92 26.13 万 7.6 亿 22.34 32.0 28.08 30.2 17.55 2......
2.实验思路
if __name__ == "__main__":
url='http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
#type记录需要点击的两个按钮的xpath路径
type = ['//*[@id="nav_sh_a_board"]/a','//*[@id="nav_sz_a_board"]/a']
driver = OpenDriver(url)
db = DB()
db.openDB()
#获取数据部分
for page in range(1,10):
GetInfo(page)
#翻页部分
if page==3:#翻页2次后第三次翻页改为换一个股票类型
ToNextType(type[0])
elif page==6:
ToNextType(type[1])
else:
ToNextPage()#正常翻页
db.closeDB()
driver.close()
print("爬取结束")
主函数部分,主要流程为打开浏览器、进入网页、获取数据、翻页/换股票类型继续获取数据、最后爬取结束。获取数据时将数据存入mysql数据库中
def OpenDriver(url):
chrome_options = Options()
# chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get(url) # 浏览器访问首页
return driver
OpenDriver函数为使用webdriber打开浏览器
def GetInfo(page):
time.sleep(3) #等待网页加载
print(driver.find_element(By.XPATH, '//*[@id="table_wrapper-table"]/tbody').text)
stocks = driver.find_element(By.XPATH, '//*[@id="table_wrapper-table"]/tbody').text.split("\n")
#print(stocks)
if (page-1)//3 == 0:
type = '沪深A股'
elif (page-1)//3 == 1:
type = '上证A股'
else:
type = '深证A股'
for stock in stocks:
stock = stock.split(" ")
no = int(stock[0])
StockNo = stock[1]
StockName = stock[2]
LatestQuotation =stock[4]
FluctuationRange =stock[5]
RiseAndFall =stock[6]
Turnover =stock[7]
TurnoverMoney =stock[8]
Amplitude =stock[9]
Highest =stock[10]
Minimum =stock[11]
TodayOpen =stock[12]
ReceivedYesterday =stock[13]
db.insert(no,type,StockNo,StockName,LatestQuotation,FluctuationRange,RiseAndFall,Turnover,TurnoverMoney,Amplitude,Highest,Minimum,TodayOpen,ReceivedYesterday)
GetInfo函数根据传入的page参数判断现在获取的股票的种类并记录,然后依次获取所有需要的信息并存入数据库中
def ToNextPage():
locator = (By.XPATH, '//*[@id="main-table_paginate"]/a[2]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))#等待按钮加载完毕
NextPage = driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]')
NextPage.click()
ToNextPage函数为点击按钮进入下一页,准备读取新的数据
def ToNextType(type):
locator = (By.XPATH, type)
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))#等待按钮加载完毕
NextType = driver.find_element(By.XPATH, type)
NextType.click()
ToNextType按钮通过传入的按钮的Xpath路径进行追踪按钮并点击,进入另一种类的股票页面
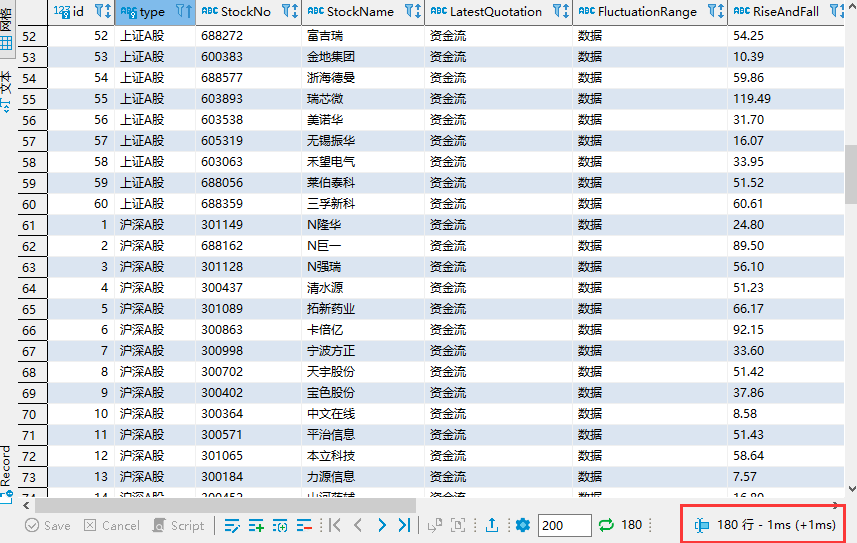
数据库中存储的信息如图,爬取了三种股票各三页内容,共180行信息
3.心得体会
作业③主要复习了Selenium框架的使用,使用Selenium框架爬取Ajax网页数据比较简单便捷

 浙公网安备 33010602011771号
浙公网安备 33010602011771号