logstash的使用(ELK)
logstash
一、logstash的简介
1.1、概念
Logstash是具有实时流水线功能的开源数据收集引擎。Logstash可以动态统一来自不同来源的数据,并将数据规范化为您选择的目标。清除所有数据并使其民主化,以用于各种高级下游分析和可视化用例。
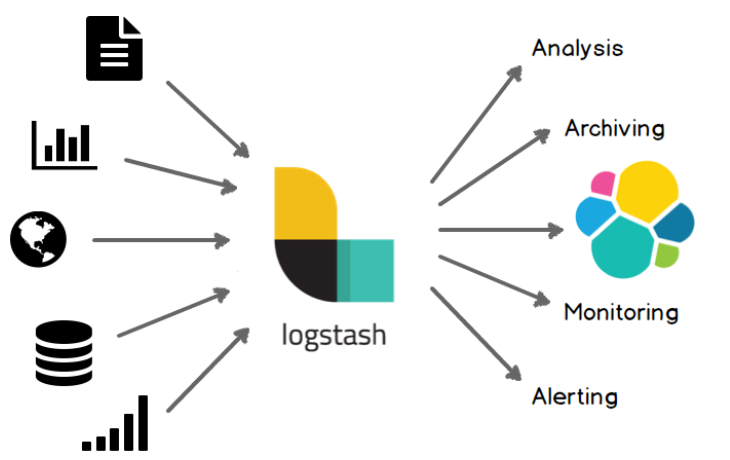
1.2、功能
Logstash能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用Grok从非结构化数据中派生出结构,从IP地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
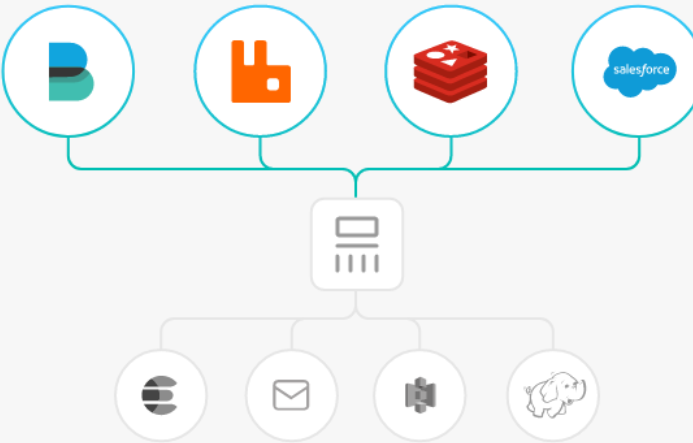
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
数据输入端从各种数据源收集到的数据可能会有很多不是我们想要的,这时我们可以给Logstash定义过滤器,过滤器可以定义多个,它们依次执行,最终把我们想要的数据过滤出来,然后把这些数据解析成目标数据库,如elasticsearch等能支持的数据格式存储数据。
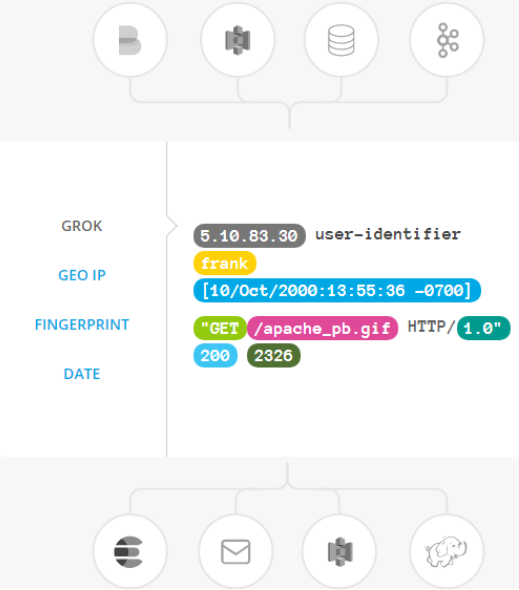
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
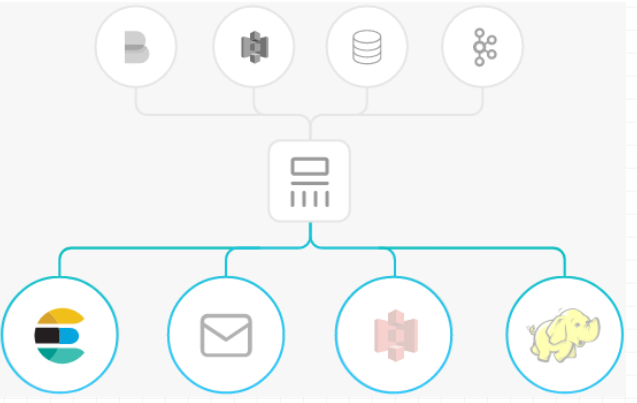
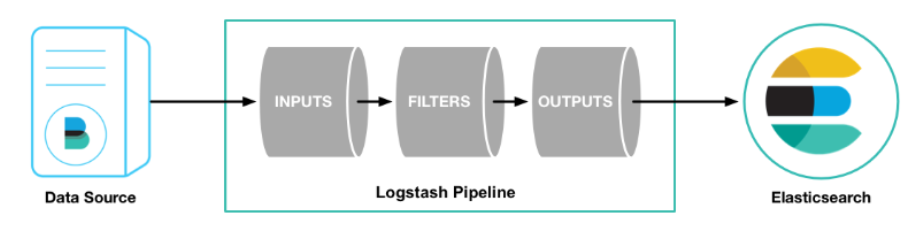
二、logstash的基本原理
logstash分为三个步骤:inputs(必须的)→ filters(可选的)→ outputs(必须的),inputs生成事件,filters对其事件进行过滤和处理,outputs输出到输出端或者决定其存储在哪些组件里。inputs和outputs支持编码和解码。
三、logstash的使用
3.1、下载
下载地址1:https://www.elastic.co/cn/downloads/logstash
下载地址2:https://elasticsearch.cn/download/
3.2、安装和基本的Logstash管道测试
3.2.1、WINDOWS系统版本
Windows版本解压之后,在bin目录下新建logstash.conf文件,内容为:
logstash.conf
input {
stdin{
}
}
output {
stdout{
}
}
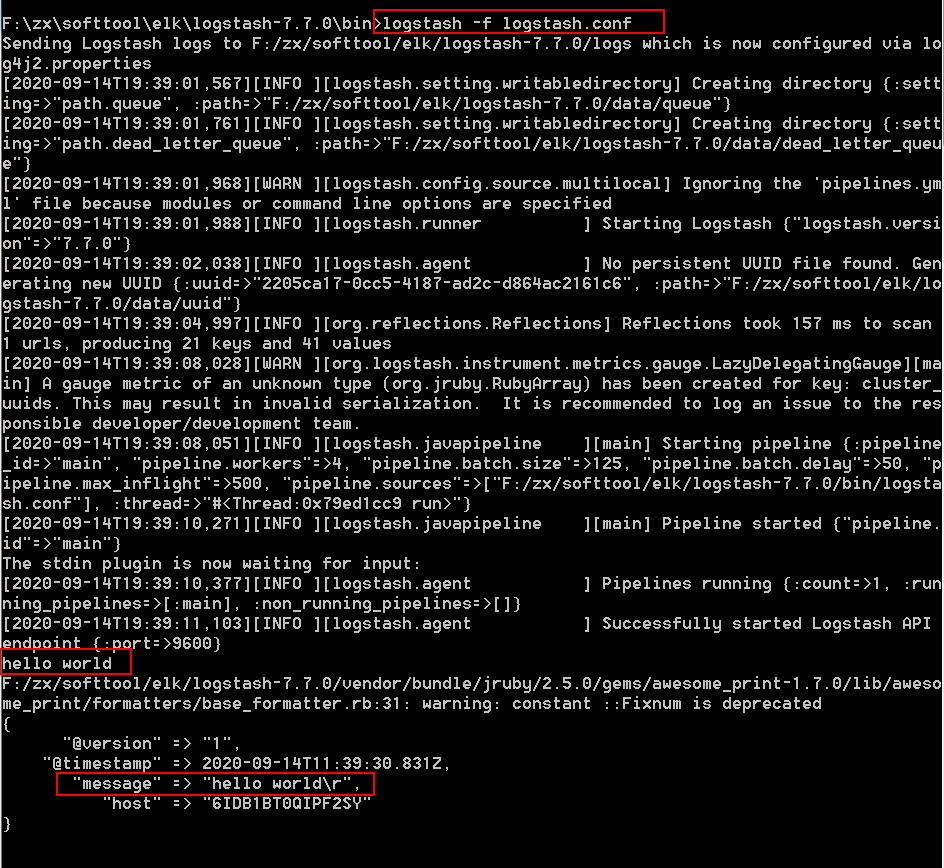
在bin的cmd下输入命令:
logstash -f logstash.conf#等待启动
hello world #输入字符串
3.2.2、LINUX系统版本
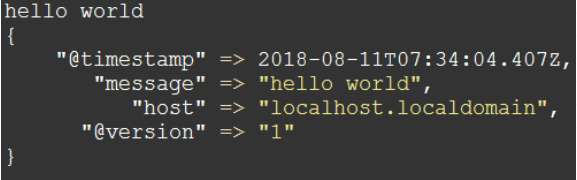
解压之后输入
bin/logstash -e 'input { stdin {} } output { stdout {} }' #input { stdin { } }表示从控制台输入
hello world #输入字符串
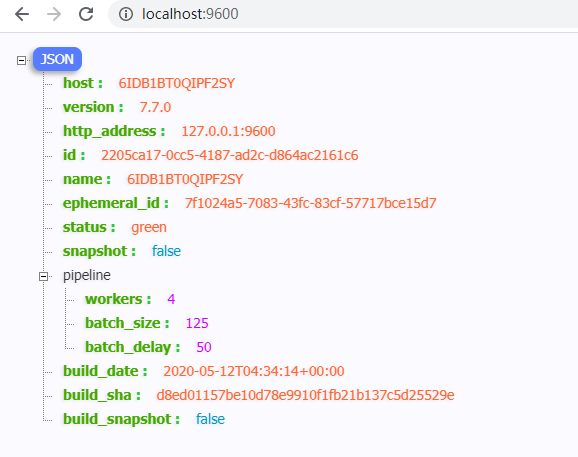
可以浏览器输入IP:9600,获取Logstash的信息。
3.3、配置Filebeat来发送日志到Logstash
3.3.1、配置配置filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
paths:
- C:\Users\Administrator\Desktop\log\apache_log.log
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
3.3.2、在logstash安装目录logstash-7.7.0\bin下新建一个文件apache-pipeline.conf
input下面beats { port => "5044" }的意思是用Beats输入插件,而stdout { codec => rubydebug }的意思是输出到控制台)
apache-pipeline.conf
input {
beats {
port => 5044
}
}
output {
stdout {
codec => rubydebug
}
}
3.3.3、检查配置并启动Logstash
config.test_and_exit选项的意思是解析配置文件并报告任何错误
config.reload.automatic选项的意思是启用自动配置加载,以至于每次你修改完配置文件以后无需停止然后重启Logstash
logstash -f apache-pipeline.conf --config.test_and_exit #选项的意思是解析配置文件并报告任何错误
logstash -f apache-pipeline.conf --config.reload.automatic #选项的意思是启用自动配置加载,以至于每次你修改完配置文件以后无需停止然后重启Logstash
3.3.4、启动filebeat
启动filebeat成功之后,就会在Logstash控制台看到的输出即是apache_log.log日志文件中的数据。在apache_log.log新增一行数据,就实时反馈到Logstash中来。
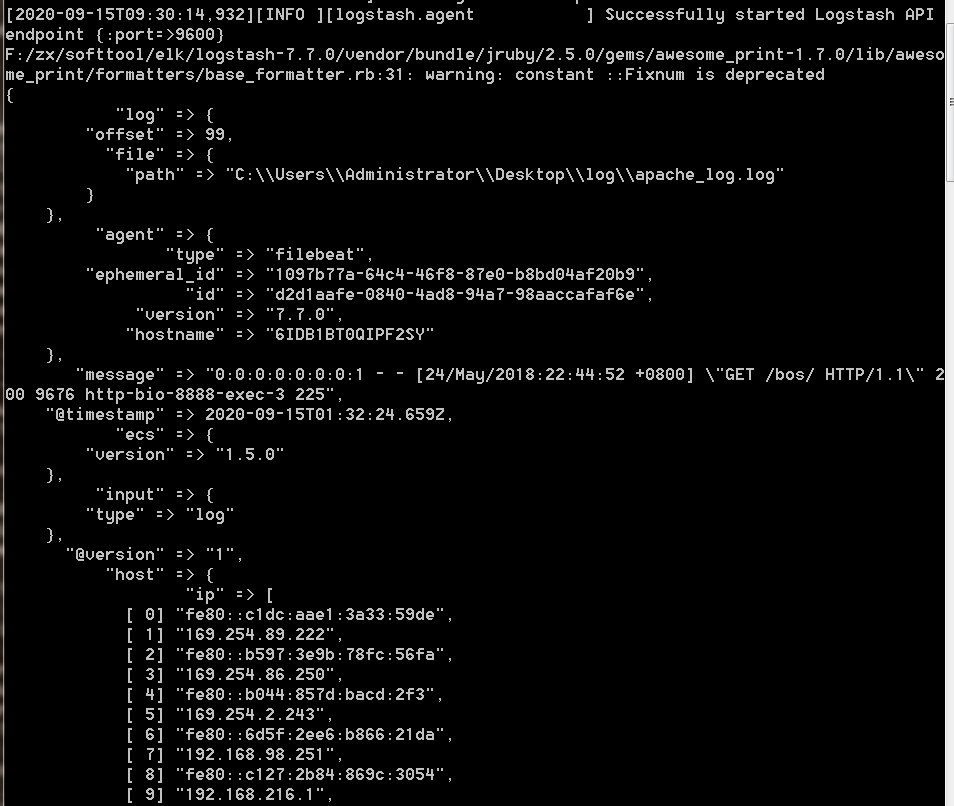
3.3.5、Grok-过滤器插件解析日志
根据上面的例子,已经存在一个工作管道,可以从Filebeat读取日志行。但是获取到的信息格式不理想。如果想要解析日志消息,以便从日志中创建特定的、命名的字段。为此,您将使用grok filter插件。
grok 过滤器插件是Logstash中默认可用的几个插件之一。
grok 过滤器插件允许你将非结构化日志数据解析为结构化和可查询的数据。
因为 grok 过滤器插件在传入的日志数据中查找模式
为了解析数据,可以用 %{COMBINEDAPACHELOG} grok pattern ,这种模式(或者说格式)的schema如下:

(1)修改apache-pipeline.conf文件,加入grok 过滤器插件
因为logstash是--config.reload.automatic启动的,就会自动加载修改之后的配置文件,无需重启。
#apache-pipeline.conf文件 内容
#logstash的输入
input {
beats {
port => 5044
}
}
#logstash的过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"} #apachelog
}
}
#logstash的输出
output {
stdout{
codec => rubydebug
}
}
(2)删除Filebeat注册文件,然后重启Filebeat
如果需要重新加载apache_log.log日志文件删除Filebeat注册文件(记录监测日志文件件的偏移量等信息)..\data\registry 文件夹。
可以看到Logstash控制台输出的信息如下:对message字段的数据进行了解析。
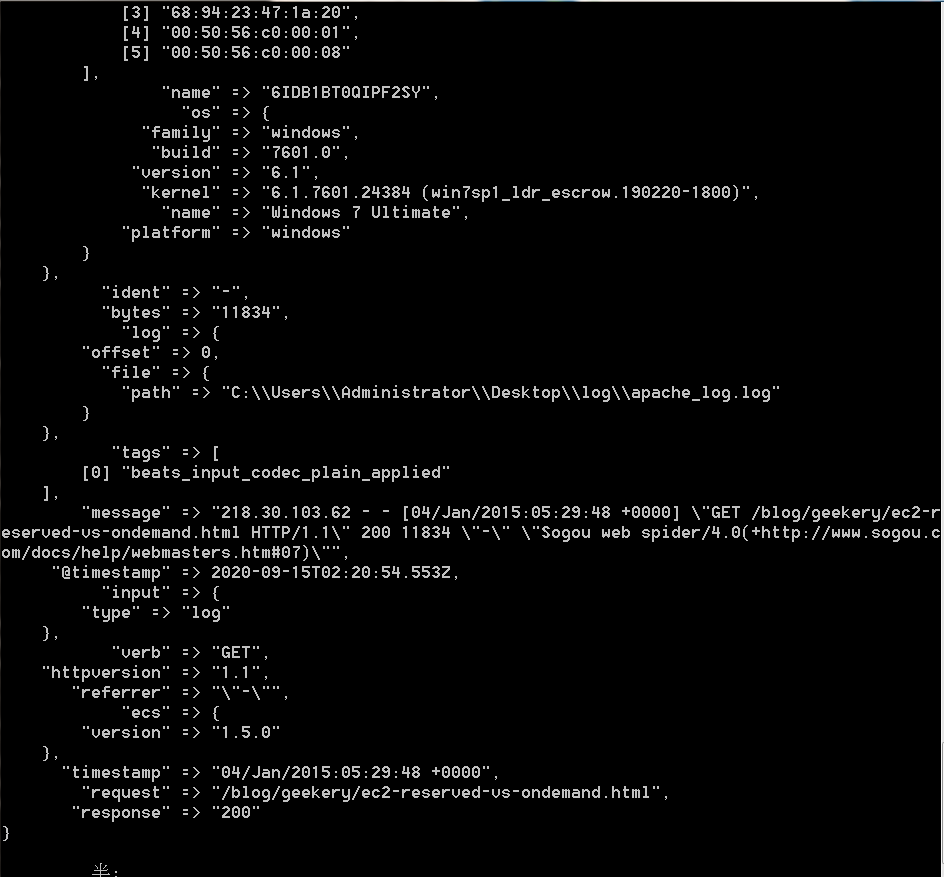
3.3.6、Geoip -过滤器插件增强你的数据
(1)修改apache-pipeline.conf文件,加入geoip过滤器插件
#apache-pipeline.conf文件 内容
#logstash的输入
input {
beats {
port => 5044
}
}
#logstash的过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
#logstash的输出
output {
stdout{
codec => rubydebug
}
}
(2)删除Filebeat注册文件,然后重启Filebeat
在Logstash控制台输出的信息由geoip信息
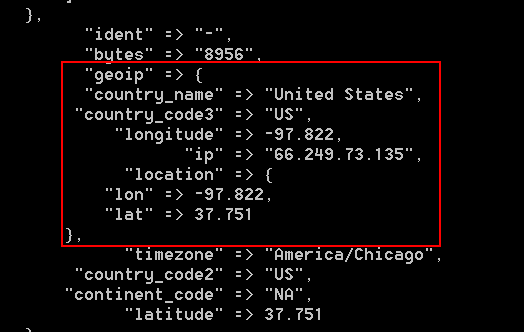
3.3、通过Logsatsh将数据输出到Elasticsearch
(1)修改apache-pipeline.conf文件,输出配置Elasticsearch
#apache-pipeline.conf文件 内容
#logstash的输入
input {
beats {
port => 5044
}
}
#logstash的过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
#logstash的输出 到elasticsearch
output {
elasticsearch {
hosts => [ "localhost:9200" ]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" 对在ES中新建的索引进行命名
}
}
(2)、启动elasticsearch
(3)、删除Filebeat注册文件,然后重启Filebeat
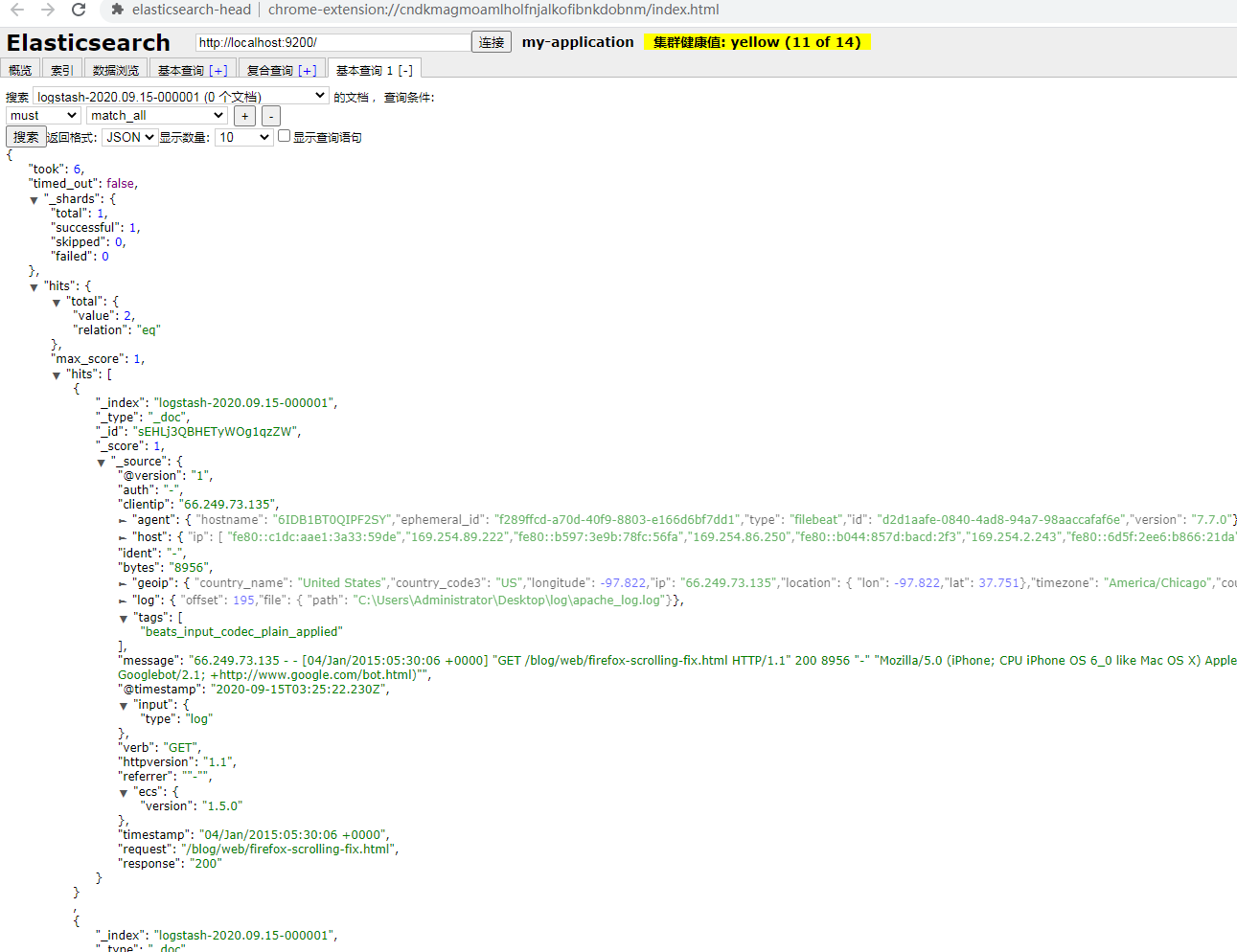
可以在Elasticsearch中新增了一个默认索引:logstash-2020.09.15-000001,在该索引下能看到log日志中的数据。如果新增log日志行,也会及时同步到ES中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号