python学习当中回忆编码方式
在pyhton网页爬虫当中总遇到中文乱码的问题,如读取文件或消息,http参数等等,一运行,发现乱码(字符串处理,读写文件,print),通常处理用encode来调试。故打算了解一下,先了解一下字符编码
一:字符编码
计算机中存放的都是0和1的二进制值。一个字节8位(比特),常用16进制来表示。
而我们正常逻辑是:计算机把其所存储的对应的16进制的数值,转化为对应的字符,包括英文和中文等其他语言的字符,然后输出到屏幕上。
故需要编码,就是,定义了一套规则,去指定,哪些数值,对应着哪些字符
举例,如65=0x41对应的是大写字母A,97=0x61对应的是小写字母a,而这套数值和字母之间的映射关系,说白了,就是一套规则,就叫做字符编码,即我们常说的ASCII编码。
这里将列出常用的编码方式
二:常用的编码方式
最早的是ASCII(国际标准叫做ISO/IEC 646)字符编译方式:27=128个字符 = 33个控制字符 + 95个可见字符
ASCII 码,总共有 128 个,用一个字节的低 7 位表示就足够了,0~31 是控制字符如换行回车删除等;32~126 是打印字符,可以通过键盘输入并且能够显示出。
后来第八位也用上了(国际标准ISO-8859),除了ASCII外128至255用于表示表格符号、计算符号、希腊字母和特殊的拉丁符号等,这套标准支持很多欧洲的语言,包括丹麦语、荷兰语、德语、意大利语、拉丁语、挪威语、葡萄牙语、西班牙语,瑞典语(ISO-8859-1= ISO/IEC 8859-1 + ASCII + ISO/IEC 6429)
ISO/IEC 8859编码标准中的15种字符集
| ISO/IEC 8859-n | 英文别名 | 中文解释 |
|---|---|---|
| ISO/IEC 8859 -1 | Latin-1 | 西欧语言 |
| ISO/IEC 8859 -2 | Latin-2 | 中欧语言 |
| ISO/IEC 8859 -3 | Latin-3 | 南欧语言。世界语也可用此字符集显示。 |
| ISO/IEC 8859 -4 | Latin-4 | 北欧语言 |
| ISO/IEC 8859 -5 | Cyrillic | 斯拉夫语言 |
| ISO/IEC 8859 -6 | Arabic | 阿拉伯语 |
| ISO/IEC 8859 -7 | Greek | 希腊语 |
| ISO/IEC 8859 -8 | Hebrew | 希伯来语(视觉顺序);ISO 8859-8-I是 希伯来语(逻辑顺序) |
| ISO/IEC 8859 -9 | Latin-5 或 Turkish | 它把Latin-1的冰岛语字母换走,加入土耳其语字母 |
| ISO/IEC 8859 -10 | Latin-6 或 Nordic | 北日耳曼语支,用来代替Latin-4 |
| ISO/IEC 8859 -11 | Thai | 从泰国的 TIS620 标准字集演化而来 |
| ISO/IEC 8859 -13 | Latin-7 或 Baltic Rim | 波罗的语族 |
| ISO/IEC 8859 -14 | Latin-8 或 Celtic | 凯尔特语族 |
| ISO/IEC 8859 -15 | Latin-9 | 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。 |
| ISO/IEC 8859 -16 | Latin-10 | 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。 |

又称:万国码、国际码、统一码、单一码。
支持世界上几乎所有字符的字符编码。Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的Unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个Unicode中的字符,而不是分别表示三个ASCII的 字符呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode
- Unicode在很长一段时间内无法推广,直到互联网的出现
早期的Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。
UTF-8是Unicode的其中之一的实现方式,其他实现方式还包括UTF-16和UTF-32。它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
与UCS-2的比较:ASCII转换成UCS-2,在编码前插入一个0x0。用这些编码,会含括一些控制符,比如"或 '/',这在UNIX和一些C函数中,将会产生严重错误。因此可以肯定,UCS-2不适合作为Unicode的外部编码,也因此诞生了UTF-8.
UTF-8的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码
Unicode与UTF-8之间的编码映射关系
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
举例如下:
以汉字“严”为例,
已知“严”的Unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码(也称本地编码)。美国的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而中国的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。台湾系统中就是Big-5编码,统一显示为ANSI编码。
Windows识别和修改ANSI是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置...”)
Linux系统中local来修改本地ANSI编码方式
GBK包括所有的汉字,包括简体和繁体。而GB2312则只包括简体汉字。均占用两个字节
字节等单位换算
bit(比特又称位),是计算机中的存储单位
1TB = 1024GB
1GB = 1024MB
1MB = 1024KB
1KB = 1024B
1B(Byte) = 8bit
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码(不使用UTF-8是因为utf8编码的字符串长度和字符个数没有固定换算关系,导致排版,排序之类的复杂度上升。但Go语言就是内部用utf8存储,但它也提供rune类型来处理字符问题),当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图:
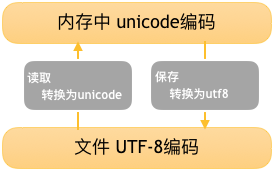
所以存到硬盘上是以何种编码存入的,再从硬盘上读出来时,就必须要以何种编码读取,可以在开头声音或者转换,不然就是乱的
Python3中字符编码执行流程:
- 解释器找到代码文件,把代码字符串按文件头定义的编码(如coding=utf-8,但python3不需要,已经默认设置为utf-8)加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释
- 所有的变量字符都会以unicode编码声明
python2与python3的字符编码区别
脚本字符编码:就是解释器解释脚本文件时使用的编码格式,可以通过 # -\*- coding: utf-8 -\*- 显式指定
解释器字符编码:解释器内部逻辑过程中对 str 类型进行处理时使用的编码格式
Python2 中默认把脚步文件使用 ASCII 来处理(历史原因请 Google)
Python2 中字符串除了 str 还有 Unicode,可以用 decode 和 encode 相互转换
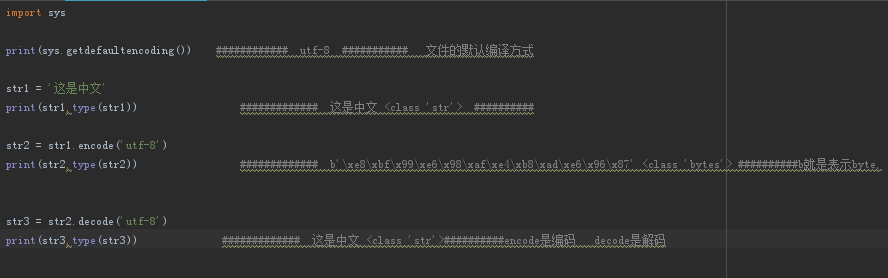
Python3 中默认把脚步文件使用 UTF-8 来处理,文件默认编码是utf-8,字符串编码是unicode
Python3 中文本字符和二进制分别使用 str 和 bytes 进行区分(str的对象都是unicode),使用 encode 进行相互转换
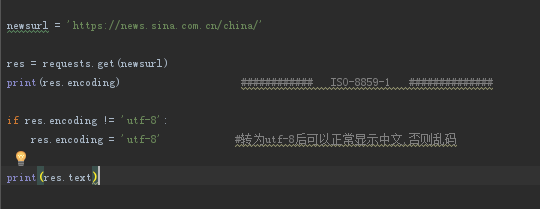
网页爬虫中的编码问题
举例如下:当我在爬取新浪新闻时,请求所获取的编码居然是ISO-8859-1(查看网页head中提示charset=utf-8)