
第二周作业
1. 权限管理及文本编辑工具
1.1. 默认权限管理
1.1.1. umask 值用来保留在创建文件或目录的权限
-
新建文件和目录默认权限
-
新建文件默认权限:666-umask,如果所得结果某位存在执行(奇数)权限,则将其权限+1,偶数不变。
-
新建目录的默认权限: 777-umask
-
-
用户默认权限
- 非特权用户umask默认是 002
- root的umask 默认是 022
-
选项
umask #模式方式显示 umask –S #输出可被调用 umask –p -
用法
#查询umask的值 [root@localhost umask]# umask 0022 [root@localhost umask]# umask -p umask 0044 [root@localhost umask]# umask -S u=rwx,g=wx,o=wx #umask值022新建文件和目录默认权限 [root@localhost umask]# umask 0022 [root@localhost umask]# ls [root@localhost umask]# touch file [root@localhost umask]# mkdir dir [root@localhost umask]# ll 总用量 0 drwxr-xr-x. 2 root root 6 8月 4 09:42 dir -rw-r--r--. 1 root root 0 8月 4 09:42 file #修改 umask的值 [root@localhost umask]# umask -S 044 u=rwx,g=wx,o=wx #umask值044新建文件和目录默认权限 [root@localhost umask]# umask 0044 [root@localhost umask]# touch file02 [root@localhost umask]# mkdir dir02 [root@localhost umask]# ll 总用量 0 drwxr-xr-x. 2 root root 6 8月 4 09:42 dir drwx-wx-wx. 2 root root 6 8月 4 09:43 dir02 -rw-r--r--. 1 root root 0 8月 4 09:42 file -rw--w--w-. 1 root root 0 8月 4 09:43 file02 #umask一次性临时修改值,新建文件默认权限 [10:47:06 root@localhost umask]#umask 0044 [10:47:19 root@localhost umask]#(umask 066;touch file03 ; mkdir dir03) [10:48:01 root@localhost umask]#umask 0044 [10:48:18 root@localhost umask]#ll 总用量 0 drwx--x--x. 2 root root 6 8月 4 10:48 dir03 -rw-------. 1 root root 0 8月 4 10:48 file03 -
永久保存umask
-
全局设置: /etc/bashrc
-
用户设置:~/.bashrc
-
1.2. 特殊权限和属性及ACL
- 特殊权限:SUID, SGID, Sticky
- 特殊权限
- SUID 作用于二进制可执行文件上,用户将继承此程序所有者的权限
- SGID
- 作用于二进制可执行文件上,用户将继承此程序所有组的权限
- 作于于目录上, 此目录中新建的文件的所属组将自动从此目录继承
- STICKY 作用于目录上,此目录中的文件只能由所有者自已来删除
1.2.1. 特殊权限SUID
-
前提:进程有属主和属组;文件有属主和属组
- 任何一个可执行程序文件能不能启动为进程,取决发起者对程序文件是否拥有执行权限
- 启动为进程之后,其进程的属主为发起者,进程的属组为发起者所属的组
- 进程访问文件时的权限,取决于进程的发起者
-
二进制的可执行文件上SUID权限功能:
- 任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
- 启动为进程之后,其进程的属主为原程序文件的属主
- SUID只对二进制可执行程序有效
- SUID设置在目录上无意义
-
SUID权限设定:
chmod u+s FILE... chmod 4xxx FILE chmod u-s FILE... -
用法
[11:14:29 root@localhost umask]#ll 总用量 36 -rwxr-xr-x. 1 root root 33600 8月 4 11:11 passwd [11:14:33 root@localhost umask]#chmod u+s passwd [11:15:00 root@localhost umask]#ll 总用量 36 -rwsr-xr-x. 1 root root 33600 8月 4 11:11 passwd [11:15:02 root@localhost umask]#chmod u-s passwd [11:15:37 root@localhost umask]#ll 总用量 36 -rwxr-xr-x. 1 root root 33600 8月 4 11:11 passwd [11:15:40 root@localhost umask]#chmod 4777 passwd [11:16:04 root@localhost umask]#ll 总用量 36 -rwsrwxrwx. 1 root root 33600 8月 4 11:11 passwd [11:16:28 root@localhost umask]#chmod 0755 passwd [11:16:35 root@localhost umask]#ll 总用量 36 -rwxr-xr-x. 1 root root 33600 8月 4 11:11 passwd
1.2.2. 特殊权限SGID
-
二进制的可执行文件上SGID权限功能:
- 任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
- 启动为进程之后,其进程的属组为原程序文件的属组
-
SGID权限设定:
chmod g+s FILE... chmod 2xxx FILE chmod g-s FILE... -
目录上的SGID权限功能
默认情况下,用户创建文件时,其属组为此用户所属的主组,一旦某目录被设定了SGID,则对此目录有写权限的用户在此目录中创建的文件所属的组为此目录的属组,通常用于创建一个协作目录
-
SGID权限设定:
chmod g+s DIR... chmod 2xxx DIR chmod g-s DIR...
1.2.3. 特殊权限 Sticky 位
-
权限说明:具有写权限的目录通常用户可以删除该目录中的任何文件,无论该文件的权限或拥有权
在目录设置Sticky 位,只有文件的所有者或root可以删除该文件
sticky 设置在文件上无意义。 -
Sticky权限设定:
chmod o+t DIR... chmod 1xxx DIR chmod o-t DIR... -
用法
[11:32:54 root@localhost umask]#touch dir/file [11:33:53 root@localhost umask]#ll dir/file -rw-r--r--. 1 root root 0 8月 4 11:33 dir/file [11:34:00 root@localhost umask]#chmod 777 dir/file [11:34:48 root@localhost umask]#ll dir/file -rwxrwxrwx. 1 root root 0 8月 4 11:33 dir/file [11:34:58 root@localhost umask]#su zxl [zxl@localhost umask]$ rm -fr dir/file rm: 无法删除'dir/file': 不允许的操作 [zxl@localhost umask]$ touch dir/file_zxl [zxl@localhost umask]$ ll dir/* -rwxrwxrwx. 1 root root 0 8月 4 11:33 dir/file -rw-rw-r--. 1 zxl zxl 0 8月 4 11:35 dir/file_zxl [zxl@localhost umask]$ exit exit [11:37:57 root@localhost umask]#rm rf dir/filez_zxl rm: 无法删除'rf': 没有那个文件或目录 rm: 无法删除'dir/filez_zxl': 没有那个文件或目录 [11:38:32 root@localhost umask]#ls dir/ file file_zxl [11:38:47 root@localhost umask]#rm dir/file_zxl rm:是否删除普通空文件 'dir/file_zxl'?y [11:39:53 root@localhost umask]#ll dir/file -rwxrwxrwx. 1 root root 0 8月 4 11:33 dir/file [11:40:32 root@localhost umask]#su zxl [zxl@localhost umask]$ rm -fr dir/file rm: 无法删除'dir/file': 不允许的操作 [zxl@localhost umask]$ echo "写入文件内容" > dir/file [zxl@localhost umask]$ cat dir/file 写入文件内容
1.3. 文本编辑工具vim
vim是Linux或者类unix系统下非常实用的文本编辑处理工具。
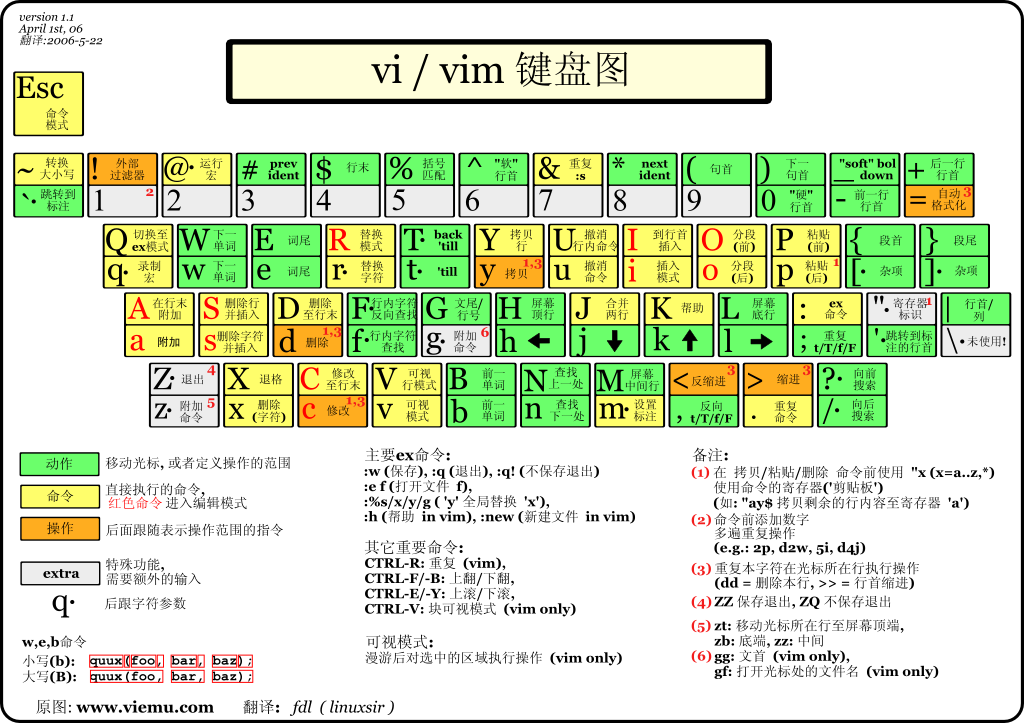
-
参考链接
https://www.w3cschool.cn/vim/
1.3.1. vim 命令格式
vim [OPTION]... FILE...
-
常用选项
+# 打开文件后,让光标处于第#行的行首,+默认行尾 +/PATTERN 让光标处于第一个被PATTERN匹配到的行行首 -b file 二进制方式打开文件 -d file1 file2… 比较多个文件,相当于 vimdiff -m file 只读打开文件 -e file 直接进入ex模式,相当于执行ex file -y file Easy mode (like "evim", modeless),直接可以操作文件,ctrl+o:wq|q! 保存和不 保存退出 -
说明
- 如果该文件存在,文件被打开并显示内容
- 如果该文件不存在,当编辑后第一次存盘时创建它
1.3.2. 三种主要模式和转换
vim 是 一个模式编辑器,击键行为是依赖于 vim的 的“模式”
-
VIM四种常见模式:
- 命令或普通(Normal)模式:默认模式,可以实现移动光标,剪切/粘贴文本
- 插入(Insert)或编辑模式:用于修改文本
- 扩展命令(extended command )或命令(末)行模式:保存,退出等
- 可视模式:在正常模式按下
v, V, <Ctrl>+v,可以进入可视模式
-
模式转换

-
命令模式 --> 插入模式
i insert, 在光标所在处输入 I 在当前光标所在行的行首输入 a append, 在光标所在处后面输入 A 在当前光标所在行的行尾输入 o 在当前光标所在行的下方打开一个新行 O 在当前光标所在行的上方打开一个新行 -
插入模式 --- ESC-----> 命令模式
命令模式 ---- : ----> 扩展命令模式
扩展命令模式 ----ESC,enter----> 命令模式 -
案例: 插入颜色字符
1 切换至插入模式 2 按ctrl+v+[ 三个键,显示^[ 3 后续输入颜色信息,如:^[[32mhello^[[0m 4 切换至扩展命令模式,保存退出 5 cat 文件可以看到下面显示
1.3.3. 扩展命令模式
按“:”进入Ex模式 ,创建一个命令提示符: 处于底部的屏幕左侧
-
扩展命令模式基本命令
w 写(存)磁盘文件 wq 写入并退出 x 写入并退出 X 加密 q 退出 q! 不存盘退出,即使更改都将丢失 r filename 读文件内容到当前文件中 w filename 将当前文件内容写入另一个文件 !command 执行命令 r!command 读入命令的输出 -
地址定界
:start_pos,end_pos CMD -
地址定界格式
# #具体第#行,例如2表示第2行 #,# #从左侧#表示起始行,到右侧#表示结尾行 #,+# #从左侧#表示的起始行,加上右侧#表示的行数,范例:2,+3 表示2到5行 . #当前行 $ #最后一行 .,$-1 #当前行到倒数第二行 % #全文, 相当于1,$ /pattern/ #从当前行向下查找,直到匹配pattern的第一行,即:正则表达式 /pat1/,/pat2/ #从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束 #,/pat/ #从指定行开始,一直找到第一个匹配pattern的行结束 /pat/,$ #向下找到第一个匹配patttern的行到整个文件的结尾的所有行 -
地址定界后跟一个编辑命令
d #删除 y #复制 w file #将范围内的行另存至指定文件中 r file #在指定位置插入指定文件中的所有内容 t#行号 将前面指定的行复制到#行后 m#行号 将前面指定的行移动到#行后
-
-
查找并替换
-
格式
%s/要查找的内容/替换为的内容/修饰符 -
说明
要查找的内容:可使用基本正则表达式模式 替换为的内容:不能使用模式,但可以使用\1, \2, ...等后向引用符号;还可以使用“&”引用前面查找时查找到的整个内容 -
修饰符
i #忽略大小写 g #全局替换,默认情况下,每一行只替换第一次出现 gc #全局替换,每次替换前询问 -
案例
[12:33:09 root@localhost ~]#cat f1 abc 123 qqq ccc [12:33:16 root@localhost ~]#vim f1 :%s#123#6#g [12:40:22 root@localhost ~]#cat f1 abc 6 qqq ccc
-
-
定制vim的工作特性
扩展命令模式的配置只是对当前vim进程有效,可将配置存放在文件中持久保存
-
配置文件
/etc/vimrc #全局 ~/.vimrc #个人 -
行号
显示:set number,简写 set nu 取消显示:set nonumber, 简写 set nonu -
忽略字符的大小写
启用:set ignorecase,简写 set ic 不忽略:set noic -
自动缩进
启用:set autoindent,简写 set ai 禁用:set noai -
复制保留格式
启用:set paste 禁用:set nopaste -
显示Tab ^I和换行符 和$显示
启用:set list 禁用:set nolist -
高亮搜索
启用:set hlsearch 禁用:set nohlsearch 简写:nohl -
语法高亮
启用:syntax on 禁用:syntax off -
文件格式
启用windows格式:set fileformat=dos 启用unix格式:set fileformat=unix 简写 set ff=dos|unix -
Tab 用空格代替
启用:set expandtab 默认为8个空格代替Tab 禁用:set noexpandtab 简写:set et -
Tab用指定空格的个数代替
启用:set tabstop=# 指定#个空格代替Tab 简写:set ts=4 -
设置缩进宽度
#向右缩进 命令模式>> #向左缩进 命令模式<< #设置缩进为4个字符 set shiftwidth=4 -
设置文本宽度
set textwidth=65 (vim only) #从左向右计数 set wrapmargin=15 #从右到左计数 -
设置光标所在行的标识线
启用:set cursorline,简写 set cul 禁用:set nocursorline -
加密
启用: set key=password 禁用: set key= -
set 帮助
:help option-list :set or :set all
-
1.3.4. 命令模式
命令模式,又称为Normal模式,功能强大,只是此模式输入指令并在屏幕上显示,所以需要记忆大量
的快捷按键才能更好的使用
-
退出VIM
ZZ 保存退出 ZQ 不保存退出 -
光标跳转
-
字符间跳转
h: 左 L: 右 j: 下 k: 上 #COMMAND:跳转由#指定的个数的字符 -
单词间跳转
w:下一个单词的词首 e:当前或下一单词的词尾 b:当前或前一个单词的词首 #COMMAND:由#指定一次跳转的单词数 -
当前页跳转
H:页首 M:页中间行 L:页底 zt:将光标所在当前行移到屏幕顶端 zz:将光标所在当前行移到屏幕中间 zb:将光标所在当前行移到屏幕底端 -
行首行尾跳转
^ 跳转至行首的第一个非空白字符 0 跳转至行首 $ 跳转至行尾 -
行间移动
#G 或者扩展命令模式下 :# 跳转至由第#行 G 最后一行 1G, gg 第一行 -
句间移动
) 下一句 ( 上一句 -
命令模式翻屏操作
Ctrl+f 向文件尾部翻一屏,相当于Pagedown Ctrl+b 向文件首部翻一屏,相当于Pageup Ctrl+d 向文件尾部翻半屏 Ctrl+u 向文件首部翻半屏
-
-
字符编辑
x 剪切光标处的字符 #x 剪切光标处起始的#个字符 xp 交换光标所在处的字符及其后面字符的位置 ~ 转换大小写 J 删除当前行后的换行符 -
替换命令(replace)
r 只替换光标所在处的一个字符 R 切换成REPLACE模式(在末行出现-- REPLACE -- 提示),按ESC回到命令模式 -
删除命令(delete)
d 删除命令,可结合光标跳转字符,实现范围删除 d$ 删除到行尾 d^ 删除到非空行首 d0 删除到行首 dw de db #COMMAND dd: 剪切光标所在的行 #dd 多行删除 D:从当前光标位置一直删除到行尾,等同于d$ -
复制命令(yank)
y 复制,行为相似于d命令 y$ y0 y^ ye yw yb #COMMAND yy:复制行 #yy 复制多行 Y:复制整行 -
粘贴命令(paste)
c$ c^ c0 cb ce cw #COMMAND cc #删除当前行并输入新内容,相当于S #cc C #删除当前光标到行尾,并切换成插入模式,相当于c$ -
查找
/PATTERN:从当前光标所在处向文件尾部查找 ?PATTERN:从当前光标所在处向文件首部查找 n:与命令同方向 N:与命令反方向 -
案例
[12:55:28 root@localhost ~]#vim f1 abc 6 qqq ccc :/qqq
-
-
撤消更改
u 撤销最近的更改,相当于windows中ctrl+z #u 撤销之前多次更改 U 撤消光标落在这行后所有此行的更改 Ctrl-r 重做最后的“撤消”更改,相当于windows中crtl+y . 重复前一个操作 #. 重复前一个操作#次 -
高级用法
-
常见Command:y 复制、d 删除、gU 变大写、gu 变小写
-
范例
0y$ 命令 0 → 先到行头 y → 从这里开始拷贝 $ → 拷贝到本行最后一个字符 di" 光标在” “之间,则删除” “之间的内容 yi( 光标在()之间,则复制()之间的内容 vi[ 光标在[]之间,则选中[]之间的内容 dtx 删除字符直到遇见光标之后的第一个 x 字符 ytx 复制字符直到遇见光标之后的第一个 x 字符
-
1.3.5. 可视化模式
-
说明
- 在末行有”-- VISUAL -- “指示,表示在可视化模式
- 可视化键可用于与移动键结合使用
- w ) } 箭头等突出显示的文字可被删除,复制,变更,过滤,搜索,替换等
-
允许选择的文本块
- v 面向字符,-- VISUAL --
- V 面向整行,-- VISUAL LINE --
- ctrl-v 面向块,-- VISUAL BLOCK --
-
案例1:在文件指定行的行首插入#
1、先将光标移动到指定的第一行的行首 2、输入ctrl+v 进入可视化模式 3、向下移动光标,选中希望操作的每一行的第一个字符 4、输入大写字母 I 切换至插入模式 5、输入 # 6、按 ESC 键 -
案例2:在指定的块位置插入相同的内容
1、光标定位到要操作的地方 2、CTRL+v 进入“可视块”模式,选取这一列操作多少行 3、SHIFT+i(I) 4、输入要插入的内容 5、按 ESC 键
1.3.6. 多文件模式
vim FILE1 FILE2 FILE3 ... :next 下一个 :prev 前一个 :first 第一个 :last 最后一个 :wall 保存所有 :qall 不保存退出所有 :wqall保存退出所有
1.3.7. 多窗口模式
-
多文件分割
vim -o|-O FILE1 FILE2 ... -o: 水平或上下分割 -O: 垂直或左右分割(vim only) 在窗口间切换:Ctrl+w, Arrow -
单文件窗口分割
Ctrl+w,s:split, 水平分割,上下分屏 Ctrl+w,v:vertical, 垂直分割,左右分屏 ctrl+w,q:取消相邻窗口 ctrl+w,o:取消全部窗口 :wqall 退出
1.3.8. 帮助
:help :help topic Use :q to exit help #vimtutor
1.4. 文本处理工具
1.4.1. 文件内容查看命令
1.4.1.1. cat:可以查看文本内容
-
格式
cat [OPTION]... [FILE]... -
常见选项
-E:显示行结束符$ -A:显示所有控制符,等价于 -vET -n:对显示出的每一行进行编号 -b:非空行编号 -s:压缩连续的空行成一行 -T 或 --show-tabs: 将 TAB 字符显示为 ^I。 -
案例
[13:16:35 root@localhost ~]#cat -A cat.txt dadsad $ adsddasd ddd a $ 22323 $ [13:16:44 root@localhost ~]#cat cat.txt dadsad adsddasd ddd a 22323
1.4.1.2. nl:显示行号,相当于cat -b
-
案例
[13:16:44 root@localhost ~]#cat cat.txt dadsad adsddasd ddd a 22323 [13:16:49 root@localhost ~]#nl cat.txt 1 dadsad 2 adsddasd ddd a 3 22323
1.4.1.3. tac:逆向显示文本内容
-
案例
[13:19:55 root@localhost ~]#cat cat.txt dadsad adsddasd ddd a 22323 [13:20:48 root@localhost ~]#tac cat.txt 22323 adsddasd ddd a dadsad
1.4.1.4. rev:将同一行的内容逆向显示
-
案例
[13:19:55 root@localhost ~]#cat cat.txt dadsad adsddasd ddd a 22323 [13:21:59 root@localhost ~]#rev cat.txt dasdad a ddd dsaddsda 32322
1.4.1.5. hexdump:查看非文本文件内容
hexdump -C -n 512 /dev/sda 00000000 eb 63 90 10 8e d0 bc 00 b0 b8 00 00 8e d8 8e c0 |.c..............| echo {a..z} | tr -d ' '|hexdump -C 00000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 |abcdefghijklmnop| 00000010 71 72 73 74 75 76 77 78 79 7a 0a |qrstuvwxyz.| 0000001b
1.4.2. 分页查看文件内容
1.4.2.1. more:可以实现分页查看文件,可以配合管道实现输出信息的分页
-
格式
more [OPTIONS...] FILE... -
选项:
-d: 显示翻页及退出提示
1.4.2.2. less:实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
-
查看时有用的命令包括
/文本 搜索 文本 n/N 跳到下一个 或 上一个匹配 -
案例1
[13:33:03 root@localhost ~]#tree -d /etc |less /etc ├── accountsservice │ └── user-templates ├── alsa │ └── conf.d ├── alternatives │ ├── jre -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64/jre │ ├── jre_1.8.0 -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64/jre │ ├── jre_1.8.0_openjdk -> /usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64 │ └── jre_openjdk -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64/jre ├── anaconda │ ├── conf.d │ └── product.d ├── audit │ ├── plugins.d │ └── rules.d ├── authselect │ └── custom ├── avahi │ ├── etc │ └── services ├── bash_completion.d ├── binfmt.d ├── bluetooth ├── brltty │ ├── Attributes │ ├── Contraction │ ├── Input │ │ ├── al │ │ ├── at │ │ ├── ba │ │ ├── bd │ │ ├── bg │ │ ├── bl │ │ ├── bm :
1.4.3. 显示文本前面或后面的行内容
1.4.3.1. head:显示文件或标准输入的前面行
-
格式:
head [OPTION]... [FILE]... -
选项
-c # 指定获取前#字节 -n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前,默认显示文件前10行 -v 显示文件名,默认不显示文件名 -
案例
[13:37:21 root@localhost ~]#head -n 3 passwd ROOT:x:0:0:ROOT:/ROOT:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [13:38:48 root@localhost ~]#head -n 3 -v passwd ==> passwd <== ROOT:x:0:0:ROOT:/ROOT:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin
1.4.3.2. tail:tail 和head 相反,查看文件或标准输入的倒数行
-
格式:
tail [OPTION]... [FILE]... -
常用选项:
-c # 指定获取后#字节 -n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束 -# 同上 -f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新 建同名文件,将无法继续跟踪文件 -F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文 件 tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8已经无此工具 -v 显示详细的处理信息 -
案例
[13:42:15 root@localhost ~]#tail -n 3 passwd mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false jira:x:1001:1001:Atlassian Jira:/home/jira:/bin/bash apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin [13:39:39 root@localhost ~]#tail -n 3 -v passwd ==> passwd <== mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false jira:x:1001:1001:Atlassian Jira:/home/jira:/bin/bash apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
1.4.4. 按列抽取文本 cut
-
说明:cut 命令可以提取文本文件或STDIN数据的指定列
-
格式
cut [OPTION]... [FILE]... -
常用选项
-d DELIMITER: 指明分隔符,默认tab -f FILEDS: #: 第#个字段,例如:3 #,#[,#]:离散的多个字段,例如:1,3,6 #-#:连续的多个字段, 例如:1-6 混合使用:1-3,7 -c 按字符切割 --output-delimiter=STRING指定输出分隔符 -
案例1
[13:47:56 root@localhost ~]#head -n 3 passwd ROOT:x:0:0:ROOT:/ROOT:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [13:48:12 root@localhost ~]#cut -d: -f1,3-4,7 passwd|head -n 3 ROOT:0:0:/bin/bash bin:1:1:/sbin/nologin daemon:2:2:/sbin/nologin -
案例2:获取IP地址
[13:50:52 root@localhost ~]#ifconfig|sed -n '2p' |tr -s " "|cut -d" " -f3 192.168.100.30 -
案例3:获取内存信息大小
#获取内存大小 [13:52:27 root@localhost ~]#free -h|grep '^Mem'|tr -s " "|cut -d" " -f2 3.6Gi #获取已使用内存 [13:58:36 root@localhost ~]#free -h|grep '^Mem'|tr -s " "|cut -d" " -f3 2.9Gi -
案例4:获取CPU核数
[13:55:02 root@localhost ~]#lscpu|sed -n '4p'|tr -s " "|cut -d" " -f2 4 -
案例5:获取硬盘大小
[13:56:20 root@localhost ~]#lsblk |grep '^sd'|tr -s " "|cut -d" " -f4 200G
1.4.5. paste:合并多个文件
-
说明:paste 合并多个文件同行号的列到一行
-
格式:
paste [OPTION]... [FILE]... -
常用选项
-d #分隔符:指定分隔符,默认用TAB -s #所有行合成一行显示 -
案例1:多文件输出合并显示
#默认多文件内容合并为同一列 [14:19:03 root@localhost ~]#cat f1 1 2 3 4 [14:19:19 root@localhost ~]#cat f2 a b c d [14:19:20 root@localhost ~]#paste f1 f2 1 a 2 b 3 c 4 d #文件内容合并为同一行 [14:19:31 root@localhost ~]#paste -s f1 f2 1 2 3 4 a b c d #指定分隔符 [14:26:36 root@localhost ~]#paste -s -d"+" f1 1+2+3+4 -
案例2:批量修改密码
[14:28:32 root@localhost ~]#paste -d":" user pass wang1:123456 wang2:654321 wang3:123654 [14:28:39 root@localhost ~]#useradd wang1 [14:29:07 root@localhost ~]#useradd wang2 [14:29:09 root@localhost ~]#useradd wang3 [14:29:13 root@localhost ~]#paste -d":" user pass |chpasswd
1.4.6. 分析文本的工具
- 文本数据统计:wc
- 整理文本:sort
- 比较文件:diff和patch
1.4.6.1. wc:收集文本统计数据
-
说明:wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数
可以对文件或STDIN中的数据统计 -
常用选项
-l 只计数行数 -w 只计数单词总数 -c 只计数字节总数 -m 只计数字符总数 -L 显示文件中最长行的长度 -
案例
[14:29:23 root@localhost ~]#wc /etc/passwd 52 113 2827 /etc/passwd [14:32:10 root@localhost ~]#wc -l /etc/passwd 52 /etc/passwd [14:32:28 root@localhost ~]#wc -w /etc/passwd 113 /etc/passwd [14:32:37 root@localhost ~]#wc -c /etc/passwd 2827 /etc/passwd [14:32:48 root@localhost ~]#wc -m /etc/passwd 2827 /etc/passwd #通过管道符传递文件内容,可不显示文件名称 [14:32:58 root@localhost ~]#cat /etc/passwd|wc -l 52
1.4.6.2. sort:文本排序
-
说明:把整理过的文本显示在STDOUT,不改变原始文件
-
格式
sort [options] file(s) -
常用选项
-r 执行反方向(由上至下)整理 -R 随机排序 -n 执行按数字大小整理 -h 人类可读排序,如: 2K 1G -f 选项忽略(fold)字符串中的字符大小写 -u 选项(独特,unique),合并重复项,即去重 -t c 选项使用c做为字段界定符 -k # 选项按照使用c字符分隔的 # 列来整理能够使用多次 -
案例1:根据用户id进行大小排序
[14:34:29 root@localhost ~]#cut -d: -f1,3 /etc/passwd|sort -t: -k2 -nr |head -n3 nobody:65534 wang3:1004 wang2:1003 -
案例2:
[14:37:06 root@localhost ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -nr|head -n1 100 -
案例3:统计日志访问量
[root@centos8 data]#cut -d" " -f1 /var/log/nginx/access_log |sort -u|wc -l 201
1.4.6.3. 去重 uniq
-
说明:uniq命令从输入中删除前后相接的重复的行
-
格式
uniq [OPTION]... [FILE]... -
常见选项
-c: 显示每行重复出现的次数 -d: 仅显示重复过的行 -u: 仅显示不曾重复的行 -
案例1:uniq常和sort 命令一起配合使用:
[14:55:09 root@localhost ~]#cat f 192.168.100.1 192.168.100.2 192.168.100.10 10.55.66.20 10.66.77.50 192.168.100.1 192.168.100.2 192.168.100.2 [14:55:48 root@localhost ~]#sort f|uniq -c 1 10.55.66.20 1 10.66.77.50 2 192.168.100.1 1 192.168.100.10 3 192.168.100.2 -
案例2:并发连接最多的远程主机IP
[15:09:16 root@localhost ~]#ss -nt|tail -n+2 |tr -s ' ' : |cut -d: -f6|sort|cut -d"]" -f1 |uniq -c|sort -nr |head -n2 74 127.0.0.1 12 192.168.100.30 -
案例3:取两个文件的相同和不同的行
[root@centos8 data]#cat test1.txt a b 1 c [root@centos8 data]#cat test2.txt b e f c 1 2 #取文件的共同行 [root@centos8 data]#cat test1.txt test2.txt | sort |uniq -d 1 b c #取文件的不同行 [root@centos8 data]#cat test1.txt test2.txt | sort |uniq -u 2 a e f
1.4.7. 比较文件
1.4.7.1. diff:比较两个文件之间的区别
-
-u 选项来输出“统一的(unified)”diff格式文件,最适用于补丁文件 -
案例
[21:08:22 root@localhost ~]#paste a1 a2 zhang li wang tian li wang tian wang [21:09:02 root@localhost ~]#diff a1 a2 1,2d0 < zhang < wang 4a3,4 > wang > wang [21:09:10 root@localhost ~]#diff -u a1 a2 --- a1 2022-08-07 21:07:15.551024796 +0800 +++ a2 2022-08-07 21:07:30.452025537 +0800 @@ -1,4 +1,4 @@ -zhang -wang li tian +wang +wang
1.4.7.2. patch:复制在其它文件中进行的改变(要谨慎使用)
-
选项
-b 选项来自动备份改变了的文件 -
案例
[21:20:16 root@localhost ~]#paste a1 a2 zhang li wang tian li wang tian wang li [21:21:02 root@localhost ~]#diff -u a1 a2 > a3 [21:21:11 root@localhost ~]#cat a3 --- a1 2022-08-07 21:20:16.801063657 +0800 +++ a2 2022-08-07 21:07:30.452025537 +0800 @@ -1,5 +1,4 @@ -zhang -wang li tian -li +wang +wang [21:21:13 root@localhost ~]#patch -b a1 a3 patching file a1 [21:21:35 root@localhost ~]#paste a1 a2 li li tian tian wang wang wang wang
1.4.7.3. vimdiff:相当于 vim -d
-
案例
[21:24:02 root@localhost ~]#paste f1 f2 1 a 2 b 3 c 4 d [21:24:20 root@localhost ~]#which vimdiff /usr/bin/vimdiff [21:25:26 root@localhost ~]#ll /usr/bin/vimdiff lrwxrwxrwx. 1 root root 3 9月 22 2021 /usr/bin/vimdiff -> vim [21:25:47 root@localhost ~]#vimdiff f1 f2 还有 2 个文件等待编辑 1 | a 2 | b 3 | c 4 | d
1.4.7.4. cmp:查看二进制文件的不同
-
案例
[21:28:22 root@localhost ~]#ll /usr/bin/dir /usr/bin/ls -rwxr-xr-x. 1 root root 143224 7月 14 2021 /usr/bin/dir -rwxr-xr-x. 1 root root 143224 7月 14 2021 /usr/bin/ls [21:29:01 root@localhost ~]#ll /usr/bin/dir /usr/bin/ls -i 625637 -rwxr-xr-x. 1 root root 143224 7月 14 2021 /usr/bin/dir 625658 -rwxr-xr-x. 1 root root 143224 7月 14 2021 /usr/bin/ls [21:29:32 root@localhost ~]#diff /usr/bin/dir /usr/bin/ls 二进制文件 /usr/bin/dir 和 /usr/bin/ls 不同 [21:30:20 root@localhost ~]#cmp /usr/bin/dir /usr/bin/ls /usr/bin/dir /usr/bin/ls 不同:第 793 字节,第 1 行 [21:30:33 root@localhost ~]#hexdump -s 790 -Cn 30 //usr/bin/dir 00000316 55 00 4a af b0 1d 71 42 b6 e7 e0 fe 2e e5 7d fa |U.J...qB......}.| 00000326 e7 5a 3c f5 86 8e 00 00 00 00 03 00 00 00 |.Z<...........| 00000334 [21:32:05 root@localhost ~]#hexdump -s 790 -Cn 30 //usr/bin/ls 00000316 55 00 bc cb 4c 17 51 6c 6a 9a d5 9c 3e c1 9b 34 |U...L.Qlj...>..4| 00000326 7c 83 23 6c 04 c2 00 00 00 00 03 00 00 00 ||.#l..........| 00000334
2. 正则表达式和相关工具及文件查找压缩
2.1. 文本处理三剑客之grep
-
说明:
-
grep: Global search REgular expression and Print out the line
-
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
-
模式:由正则表达式字符及文本字符所编写的过滤条件
帮助https://man7.org/linux/man-pages/man1/grep.1.html
-
-
格式:
grep [OPTIONS] PATTERN [FILE...] -
常见选项:
--color=auto 对匹配到的文本着色显示 -m # 匹配#次后停止 -v 显示不被pattern匹配到的行,即取反 -i 忽略字符大小写 -n 显示匹配的行号 -c 统计匹配的行数 -o 仅显示匹配到的字符串 -q 静默模式,不输出任何信息 -A # after, 后#行 -B # before, 前#行 -C # context, 前后各#行 -e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file -w 匹配整个单词 -E 使用ERE,相当于egrep -F 不支持正则表达式,相当于fgrep -P 支持Perl格式的正则表达式 -f file 根据模式文件处理 -r 递归目录,但不处理软链接 -R 递归目录,但处理软链接 -
案例1
[22:54:45 root@localhost data]#cat /etc/passwd|grep root root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [22:55:26 root@localhost data]#cat /etc/passwd|grep zxl zxl:x:1000:1000:zxl:/home/zxl:/bin/bash [22:55:30 root@localhost data]#cat /etc/passwd|grep "root" root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin -
案例2:统计CPU核数
[22:59:58 root@localhost data]#cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 140 model name : 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz stepping : 1 microcode : 0xffffffff cpu MHz : 2419.201 cache size : 8192 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 4 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 27 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xsaves arat flush_l1d arch_capabilities bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs bogomips : 4838.40 clflush size : 64 cache_alignment : 64 address sizes : 43 bits physical, 48 bits virtual power management: [23:01:41 root@localhost data]#grep -c processor /proc/cpuinfo 4 -
案例3:取两个文件相同行
[23:04:03 root@localhost ~]#paste f2 f4 a d b f c a d c [23:04:10 root@localhost ~]#grep -f f2 f4 d a c [23:06:45 root@localhost ~]#cat f2 f4|sort |uniq -d a c d -
案例4:取磁盘分区最大利用率
[23:28:50 root@localhost ~]#df |grep '^/dev/sd' |grep -Eow "100|([0-9]{1,2})%"|cut -d"%" -f1|sort -nr|head -n 1 26 -
案例5:连接状态的统计
[23:37:22 root@localhost ~]#ss -nta|grep -v "^State"|tr -s " "|cut -d" " -f1|sort|uniq -c|sort -t 1 -nr 84 ESTAB 11 LISTEN 4 CLOSE-WAIT
2.2. 基本正则表达式和扩展正则表达式
-
说明
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符) 不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配 符功能是用来处理文件名,而正则表达式是处理文本内容中字符 正则表达式被很多程序和开发语言所广泛支持:vim, less,grep,sed,awk, nginx,mysql 等 -
正则表达式分两类:
- 基本正则表达式:BRE Basic Regular Expressions
- 扩展正则表达式:ERE Extended Regular Expressions
-
正则表达式引擎
- 采用不同算法,检查处理正则表达式的软件模块,如:PCRE
- 正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组
-
帮助:man 7 regex
2.2.1. 正则表达式
2.2.1.1. 基本正则表达式元字符
2.2.1.1.1. 字符匹配
. 匹配任意单个字符(除了\n),可以是一个汉字或其它国家的文字 [] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z] [^] 匹配指定范围外的任意单个字符,示例:[^wang] [:alnum:] 字母和数字 [:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] 小写字母,示例:[[:lower:]],相当于[a-z] [:upper:] 大写字母 [:blank:] 空白字符(空格和制表符) [:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围 广 [:cntrl:] 不可打印的控制字符(退格、删除、警铃...) [:digit:] 十进制数字 [:xdigit:]十六进制数字 [:graph:] 可打印的非空白字符 [:print:] 可打印字符 [:punct:] 标点符号 ----------------- \s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符 \S #匹配任何非空白字符。等价于 [^\f\r\t\v] \w #匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[_[:alnum:]字] \W #匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[^_[:alnum:]字]
-
案例
[21:42:33 root@localhost ~]#ls /etc/ |grep rc[0-6.] rc0.d rc1.d rc2.d rc3.d rc4.d rc5.d rc6.d rc.d rc.local [21:51:39 root@localhost data]#ls 1.txt 3.txt 5.txt 7.txt a.txt b.txt c.txt d.txt e.txt f.txt g.txt 2.txt 4.txt 6.txt 8.txt A.txt B.txt C.txt D.txt E.txt F.txt G.txt [21:51:40 root@localhost data]#ls | grep "[1-10].txt" 1.txt [21:51:49 root@localhost data]#ls | grep "[0-9].txt" 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt [21:52:18 root@localhost data]#ls | grep "[a-z].txt" a.txt b.txt c.txt d.txt e.txt f.txt g.txt [21:52:40 root@localhost data]#ls | grep "[A-Z].txt" A.txt B.txt C.txt D.txt E.txt F.txt G.txt [21:53:19 root@localhost data]#ls | grep "[[:alnum:]].txt" 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt a.txt A.txt b.txt B.txt c.txt C.txt d.txt D.txt e.txt E.txt f.txt F.txt g.txt G.txt
2.2.1.1.2. 匹配次数
-
说明:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 .* #任意长度的任意字符 \? #匹配其前面的字符出现0次或1次,即:可有可无 \+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 \{n\} #匹配前面的字符n次 \{m,n\} #匹配前面的字符至少m次,至多n次 \{,n\} #匹配前面的字符至多n次,<=n \{n,\} #匹配前面的字符至少n次 -
案例
[21:58:20 root@localhost data]#cat test google gooogle gooooogle gogle gggoogle gogooogle [21:59:20 root@localhost data]#cat test |grep "goo0*gle" google gggoogle [22:00:28 root@localhost data]#cat test |grep "go\{1,2\}gle" google gogle gggoogle [22:00:48 root@localhost data]#cat test |grep "go\{3,\}gle" gooogle gooooogle gogooogle [22:02:58 root@localhost data]#cat test |grep "gooo\+gle" gooogle gooooogle gogooogle [22:03:17 root@localhost data]#cat test |grep "gooo\?gle" google gooogle gggoogle gogooogle -
案例2:匹配正负数
[22:12:41 root@localhost data]#cat t1.txt abc 123 -1 -22 23 a12 -1a4 -f123 35 #方法1 [22:12:52 root@localhost data]#cat t1.txt | grep '^\-\?[0-9]\+$' 123 -1 -22 23 35 #方法2 [22:12:58 root@localhost data]#cat t1.txt | grep -E '^-?[0-9]+$' 123 -1 -22 23 35
2.2.1.1.3. 位置锚定
-
s说明:位置锚定可以用于定位出现的位置
-
选项
^ #行首锚定, 用于模式的最左侧 $ #行尾锚定,用于模式的最右侧 ^PATTERN$ #用于模式匹配整行 ^$ #空行 ^[[:space:]]*$ #空白行 \< 或 \b #词首锚定,用于单词模式的左侧 \> 或 \b #词尾锚定,用于单词模式的右侧 \<PATTERN\> #匹配整个单词 #注意: 单词是由字母,数字,下划线组成 -
案例1:匹配设备挂载,排除注释和空行
[22:13:55 root@localhost data]#grep '^[^#]' /etc/fstab UUID=23a498b0-3783-46e4-b55f-fdb1e1c699bb / xfs defaults 0 0 UUID=39c438a4-ad8d-4c9c-a001-7794dc13131a /boot xfs defaults 0 0 UUID=6c74e5a8-ebc9-4329-8454-b838f5833073 /data xfs defaults 0 0 UUID=b65aa78c-be4d-4c68-a276-c31aee04579a none swap defaults 0 0
2.2.1.1.4. 分组其它
2.2.1.1.4.1. 分组
-
说明
- 分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
- 后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
- 方式为: \1, \2, \3, ...
- \1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
- 注意: \0 表示正则表达式匹配的所有字符
-
示例
\(string1\(string2\)\) \1 :string1\(string2\) \2 :string2 -
注意: 后向引用引用前面的分组括号中的模式所匹配字符,而非模式本身
2.2.1.1.4.2. 或者
-
或者:|
-
示例:
a\|b #a或b C\|cat #C或cat \(C\|c\)at #Cat或cat
2.2.2. 扩展正则表达式元字符
2.2.2.1. 字符匹配
-
选项
. 任意单个字符 [wang] 指定范围的字符 [^wang] 不在指定范围的字符 [:alnum:] 字母和数字 [:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] 小写字母,示例:[[:lower:]],相当于[a-z] [:upper:] 大写字母 [:blank:] 空白字符(空格和制表符) [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广) [:cntrl:] 不可打印的控制字符(退格、删除、警铃...) [:digit:] 十进制数字 [:xdigit:]十六进制数字 [:graph:] 可打印的非空白字符 [:print:] 可打印字符 [:punct:] 标点符号
2.2.2.2. 次数匹配
-
选项
* 匹配前面字符任意次 ? 0或1次 + 1次或多次 {n} 匹配n次 {m,n} 至少m,至多n次
2.2.2.3. 位置锚定
-
选项
^ 行首 $ 行尾 \<, \b 语首 \>, \b 语尾
2.2.2.4. 分组其它
-
选项
() 分组 后向引用:\1, \2, ... 注意: \0 表示正则表达式匹配的所有字符 | 或者 a|b #a或b C|cat #C或cat (C|c)at #Cat或cat -
案例1:ifconfig查找IP地址
[22:36:34 root@localhost data]#ifconfig | grep -Ewo "(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])"|head -n1 192.168.100.30 [23:55:42 root@localhost ~]#ifconfig |grep -Eow "([0-9]{1,3}\.){3}[0-9]{1,3}" 192.168.100.30 255.255.255.0 192.168.100.255 127.0.0.1 255.0.0.0 192.168.122.1 255.255.255.0 192.168.122.255 [23:55:49 root@localhost ~]#echo "([0-9]{1,3}\.){3}[0-9]{1,3}" > regex.txt [23:57:27 root@localhost ~]#ifconfig |grep -Eowf regex.txt 192.168.100.30 255.255.255.0 192.168.100.255 127.0.0.1 255.0.0.0 192.168.122.1 255.255.255.0 192.168.122.255 -
案例2:查找多个匹配行
[23:57:44 root@localhost ~]#cat /etc/passwd|grep -E "root|zxl|mysql|jira" root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin zxl:x:1000:1000:zxl:/home/zxl:/bin/bash mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false jira:x:1001:1001:Atlassian Jira:/home/jira:/bin/bash [00:33:17 root@localhost ~]#cat /etc/passwd|grep -e "root" -e "mysql" root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false #匹配单词的开始和结束为统一匹配单词 [00:39:01 root@localhost ~]#grep -E "^(.*)\>.*\<\1$" /etc/passwd sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt -
案例3:过滤掉文件的注释(包括#号的行)和空行
[00:50:40 root@localhost ~]#grep -Ev '^$|#' /etc/fstab UUID=23a498b0-3783-46e4-b55f-fdb1e1c699bb / xfs defaults 0 0 UUID=39c438a4-ad8d-4c9c-a001-7794dc13131a /boot xfs defaults 0 0 UUID=6c74e5a8-ebc9-4329-8454-b838f5833073 /data xfs defaults 0 0 UUID=b65aa78c-be4d-4c68-a276-c31aee04579a none swap defaults 0 0 -
案例4:算出所有人的年龄总和
[00:51:46 root@localhost ~]#cat p xiaoming=20 xiaohong=18 xiaoqiang=22 [00:57:34 root@localhost ~]#cat p|grep -Eo "[0-9]+"|paste -s -d"+"|bc 60
2.3. 文件查找工具
- 说明:在文件系统上查找符合条件的文件
- 文件查找
- 非实时查找(数据库查找):locate
- 实时查找:find
2.3.1. locate
-
说明:
- locate 查询系统上预建的文件索引数据库 /var/lib/mlocate/mlocate.db
- 索引的构建是在系统较为空闲时自动进行(周期性任务),执行updatedb可以更新数据库
- 索引构建过程需要遍历整个根文件系统,很消耗资源
- locate和updatedb命令来自于mlocate包
-
工作特点
- 查找速度快
- 模糊查找
- 非实时查找
- 搜索的是文件的全路径,不仅仅是文件名
- 可能只搜索用户具备读取和执行权限的目录
-
格式
locate [OPTION]... [PATTERN]... -
常用选项
-i 不区分大小写的搜索 -n N 只列举前N个匹配项目 -r 使用基本正则表达式 -
案例:
[01:09:23 root@localhost ~]#locate -r "passwd$" /etc/passwd /etc/pam.d/passwd /etc/security/opasswd /root/passwd /usr/bin/gpasswd /usr/bin/htpasswd /usr/bin/passwd /usr/bin/vncpasswd /usr/sbin/chgpasswd /usr/sbin/chpasswd /usr/sbin/lpasswd /usr/share/bash-completion/completions/chpasswd /usr/share/bash-completion/completions/gpasswd /usr/share/bash-completion/completions/htpasswd /usr/share/bash-completion/completions/ldappasswd /usr/share/bash-completion/completions/passwd /usr/share/bash-completion/completions/smbpasswd /usr/share/doc/passwd /usr/share/licenses/passwd /var/lib/sss/mc/passwd -
案例2:文件新创建和删除,无法马上更新locate数据库
[01:11:03 root@localhost ~]#touch abc.log [01:11:10 root@localhost ~]#locate "abc.log" [01:11:21 root@localhost ~]#updatedb [01:11:32 root@localhost ~]#locate "abc.log" /root/abc.log [01:11:35 root@localhost ~]#rm abc.log rm:是否删除普通空文件 'abc.log'?y [01:12:00 root@localhost ~]#locate "abc.log" /root/abc.log [01:12:22 root@localhost ~]#updatedb [01:12:27 root@localhost ~]#locate "abc.log" [01:12:29 root@localhost ~]#
2.3.2. find
-
说明:find 是实时查找工具,通过遍历指定路径完成文件查找
-
工作特点:
- 查找速度略慢
- 精确查找
- 实时查找
- 查找条件丰富
- 可能只搜索用户具备读取和执行权限的目录
-
格式:
find [OPTION]... [查找路径] [查找条件] [处理动作] -
查找路径:指定具体目标路径;默认为当前目录
-
查找条件:指定的查找标准,可以文件名、大小、类型、权限等标准进行;默认为找出指定路径下的所有文件
-
处理动作:对符合条件的文件做操作,默认输出至屏幕
2.3.2.1. 指定搜索目录层级
-
选项
-maxdepth level 最大搜索目录深度,指定目录下的文件为第1级 -mindepth level 最小搜索目录深度 -
案例1:
[01:16:37 root@localhost ~]#find /etc -maxdepth 2 -mindepth 2 |head -n 5 /etc/dnf/modules.d /etc/dnf/aliases.d /etc/dnf/dnf.conf /etc/dnf/modules.defaults.d /etc/dnf/plugins
2.3.2.2. 对每个目录先处理目录内的文件,再处理目录本身
-
选项
-depth -d #warning: the -d option is deprecated; please use -depth instead, because the latter is a POSIX-compliant feature -
案例:
[01:20:18 root@localhost ~]#tree /data/ /data/ ├── 1.txt ├── 2.txt ├── 3.txt ├── 4.txt ├── 5.txt ├── 6.txt ├── 7.txt ├── 8.txt ├── a.txt ├── dir1 │ └── dir ├── dir2 │ └── dir ├── dir3 │ └── dir ├── t1.txt └── test 6 directories, 11 files [01:20:22 root@localhost ~]#find /data/ /data/ /data/a.txt /data/1.txt /data/2.txt /data/3.txt /data/4.txt /data/5.txt /data/6.txt /data/7.txt /data/8.txt /data/test /data/t1.txt /data/dir1 /data/dir1/dir /data/dir2 /data/dir2/dir /data/dir3 /data/dir3/dir
2.3.2.3. 根据文件名和inode查找
-
选项
-name "文件名称" #支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来 -iname "文件名称" #不区分字母大小写 -inum n #按inode号查找 -samefile name #相同inode号的文件 -links n #链接数为n的文件 -regex “PATTERN" #以PATTERN匹配整个文件路径,而非文件名称 -
案例
[01:24:43 root@localhost ~]#find /data/ -name "*.txt" /data/a.txt /data/1.txt /data/2.txt /data/3.txt /data/4.txt /data/5.txt /data/6.txt /data/7.txt /data/8.txt /data/t1.txt
2.3.2.4. 根据属主、属组查找
-
选项
-user USERNAME #查找属主为指定用户(UID)的文件 -group GRPNAME #查找属组为指定组(GID)的文件 -uid UserID #查找属主为指定的UID号的文件 -gid GroupID #查找属组为指定的GID号的文件 -nouser #查找没有属主的文件 -nogroup #查找没有属组的文件 -
案例:
[01:27:08 root@localhost ~]#find / -user "zxl" |head -n 3 find: ‘/proc/20986/task/20986/fd/6’: 没有那个文件或目录 find: ‘/proc/20986/task/20986/fdinfo/6’: 没有那个文件或目录 find: ‘/proc/20986/fd/7’: 没有那个文件或目录 find: ‘/proc/20986/fdinfo/7’: 没有那个文件或目录 /var/spool/mail/zxl /home/zxl /home/zxl/.mozilla
2.3.2.5. 根据文件类型查找
-
选项
-type TYPE TYPE可以是以下形式: f: 普通文件 d: 目录文件 l: 符号链接文件 s:套接字文件 b: 块设备文件 c: 字符设备文件 p: 管道文件 -
案例:查找磁盘文件
[01:29:44 root@localhost ~]#find /dev/ -type "b" /dev/sr0 /dev/sda5 /dev/sda4 /dev/sda3 /dev/sda2 /dev/sda1 /dev/sda
2.3.2.6. 空文件或目录
-
选项
-empty -
案例:查找空目录
[01:30:00 root@localhost ~]#find /data/ -type "d" -empty /data/dir1/dir /data/dir2/dir /data/dir3/dir
2.3.2.7. 组合条件
-
选项
与:-a ,默认多个条件是与关系,所以可以省略-a 或:-o 非:-not ! -
案例
[01:31:33 root@localhost ~]#find /etc/ -type d -o -type l |wc -l 705 [01:33:20 root@localhost ~]#find /etc/ -type d -o -type l -ls |wc -l 286 [01:33:49 root@localhost ~]#find /etc/ \( -type d -o -type l \) -ls |wc -l 705 -
德·摩根定律
!A -a !B = !(A -o B) !A -o !B = !(A -a B) -
案例2
find -user joe -group joe find -user joe -not -group joe find -user joe -o -user jane find -not \( -user joe -o -user jane \) find / -user joe -o -uid 500 -
案例3:
[01:34:12 root@localhost ~]#find ! \( -type d -a -empty \)| wc -l 1027 [01:36:13 root@localhost ~]#find ! -type d -o ! -empty |wc -l 1027 [01:39:35 root@localhost ~]#find /home/ ! -user root ! -user zxl ! -user wang1 ! -user wang2 ! -user wang3 /home/jira /home/jira/.mozilla /home/jira/.mozilla/extensions /home/jira/.mozilla/plugins /home/jira/.bash_logout /home/jira/.bash_profile /home/jira/.bashrc /home/jira/.java /home/jira/.java/fonts /home/jira/.java/fonts/11.0.13 /home/jira/.java/fonts/11.0.13/fcinfo-1-localhost.localdomain-RedHat-8.5.2111-zh.properties [10:48:35 root@localhost ~]#find /home/ ! \( -user root -o -user zxl -o -user wang1 -o -user wang1 -o -user wang2 -o -user wang3 \)
/home/jira
/home/jira/.mozilla
/home/jira/.mozilla/extensions
/home/jira/.mozilla/plugins
/home/jira/.bash_logout
/home/jira/.bash_profile
/home/jira/.bashrc
/home/jira/.java
/home/jira/.java/fonts
/home/jira/.java/fonts/11.0.13
/home/jira/.java/fonts/11.0.13/fcinfo-1-localhost.localdomain-RedHat-8.5.2111-zh.properties
#### 2.3.2.8. 排除目录 - 案例 ```sh #查找/data/下,除data/dir1目录的其它所有.txt后缀的文件 [11:43:21 root@localhost ~]#find /data/ /data/ /data/a.txt /data/1.txt /data/2.txt /data/3.txt /data/4.txt /data/5.txt /data/6.txt /data/7.txt /data/8.txt /data/test /data/t1.txt /data/dir1 /data/dir1/dir /data/dir1/a.txt /data/dir1/b.txt /data/dir1/c.txt /data/dir1/d.txt /data/dir1/e.txt /data/dir1/f.txt /data/dir1/g.txt /data/dir2 /data/dir2/dir /data/dir3 /data/dir3/dir [11:43:15 root@localhost ~]#find /data -path "/data/dir1" -prune -o -name "*.txt" /data/a.txt /data/1.txt /data/2.txt /data/3.txt /data/4.txt /data/5.txt /data/6.txt /data/7.txt /data/8.txt /data/t1.txt /data/dir1 #统计查找/etc/下,除/etc/security和/etc/systemd,/etc/dbus-1三个目录的所有.conf后缀的文件 [11:50:23 root@localhost ~]#find /etc -name "*.conf"|wc -l 433 [11:49:32 root@localhost ~]#find /etc \( -path "/etc/security" -o -path "/etc/systemd" -o -path "/etc/dbus-1" \) -prune -o -name "*.conf"|wc -l 386 [11:49:41 root@localhost ~]#find /etc \( -path "/etc/security" -o -path "/etc/systemd" -o -path "/etc/dbus-1" \) -a -prune -o -name "*.conf"|wc -l 386 #排除/proc和/sys目录 [11:51:01 root@localhost ~]#find / \( -path "/sys" -o -path "/proc" \) -a -prune -o -type f -a -mmin -1 /proc /sys /var/lib/mysql/ibdata1 /var/lib/mysql/mysql/innodb_table_stats.ibd /var/lib/mysql/mysql/innodb_index_stats.ibd /var/lib/mysql/jira/clusteredjob.ibd /var/lib/mysql/jira/rundetails.ibd /var/lib/mysql/jira/SEQUENCE_VALUE_ITEM.ibd /var/lib/mysql/ib_logfile0 /var/lib/mysql/ibtmp1 /var/atlassian/application-data/jira/log/atlassian-jira-perf.log /var/atlassian/application-data/jira/log/atlassian-jira-outgoing-mail.log /var/atlassian/application-data/jira/log/atlassian-jira.log /var/atlassian/application-data/jira/analytics-logs/68491876c23d7650370b5d3c4b6d778c.atlassian-analytics.log /var/atlassian/application-data/jira/monitor/ConnectionPoolGraph.rrd4j /var/atlassian/application-data/jira/monitor/DatabaseReadWritesGraph.rrd4j /opt/atlassian/jira/temp/2022_08_05_15_38_24_1215/2022_08_08_11_50_00.part /tmp/hsperfdata_jira/1215
2.3.2.9. 根据文件大小来查找
2.4. xargs动态生成命令参数
-
说明
由于很多命令不支持管道|来传递参数,xargs用于产生某个命令的参数,xargs 可以读入 stdin 的数 据,并且以空格符或回车符将 stdin 的数据分隔成为参数另外,许多命令不能接受过多参数,命令执行可能会失败,xargs 可以解决 -
注意:文件名或者是其他意义的名词内含有空格符的情况
-
find 经常和 xargs 命令进行组合,形式如下:
find | xargs COMMAND -
案例
#显示10个数字 [root@centos8 ~]#seq 10 | xargs 1 2 3 4 5 6 7 8 9 10 #删除当前目录下的大量文件 ls | xargs rm # find -name "*.sh" | xargs ls -Sl [root@centos8 data]#echo {1..10} |xargs 1 2 3 4 5 6 7 8 9 10 [root@centos8 data]#echo {1..10} |xargs -n1 1 2 3 4 5 6 7 8 9 10 [root@centos8 data]#echo {1..10} |xargs -n2 1 2 3 4 5 6 7 8 9 10 #批量创建和删除用户 echo user{1..10} |xargs -n1 useradd echo user{1..100} | xargs -n1 userdel -r #这个命令是错误的 find /sbin/ -perm /700 | ls -l #查找有特殊权限的文件,并排序 find /bin/ -perm /7000 | xargs ls -Sl #此命令和上面有何区别? find /bin/ -perm -7000 | xargs ls -Sl #以字符nul分隔 find -type f -name "*.txt" -print0 | xargs -0 rm #并发执行多个进程 seq 100 |xargs -i -P10 wget -P /data http://10.0.0.8/{}.html #并行下载bilibili视频 yum install python3-pip -y pip3 install you-get seq 60 | xargs -i -P3 you-get https://www.bilibili.com/video/BV14K411W7UF?p={}
2.5. 文件压缩和打包
主要针对单个文件压缩,而非目录
2.5.1. compress 和 uncompress
-
说明:此工具来自于ncompress包,此工具目前已经很少使用,对应的文件是 .Z 后缀
-
选项
-d 解压缩,相当于uncompress -c 结果输出至标准输出,不删除原文件 -v 显示详情
2.5.2. zip和gunzip
-
说明:来自于 gzip 包,对应的文件是 .gz 后缀
-
格式
gzip [OPTION]... FILE ... -
选项
-k keep, 保留原文件,CentOS 8 新特性 -d 解压缩,相当于gunzip -c 结果输出至标准输出,保留原文件不改变 -# 指定压缩比,#取值为1-9,值越大压缩比越大 -
案例
#文件压缩 [12:22:42 root@localhost data]#gzip -c 1.txt > /data/dir1/1.txt.gz [12:23:37 root@localhost data]#ls /data/dir1/1.txt.gz /data/dir1/1.txt.gz #文件解压 [12:26:28 root@localhost data]#gzip -c -d /data/dir1/1.txt.gz > /data/dir1/1.txt [12:26:37 root@localhost data]#ls /data/dir1/1.txt /data/dir1/1.txt
2.5.3. bzip2和bunzip2
-
说明:来自于 bzip2 包,对应的文件是 .bz2 后缀
-
格式
bzip2 [OPTION]... FILE ... -
常用选项
-k keep, 保留原文件 -d 解压缩 -c 结果输出至标准输出,保留原文件不改变 -# 1-9,压缩比,默认为9 -
案例
#文件压缩 [12:33:19 root@localhost data]#bzip2 -c 3.txt > /data/dir2/2.txt.bz2 [12:33:36 root@localhost data]#ls /data/dir2/2.txt.bz2 /data/dir2/2.txt.bz2 #文件解压 [12:33:42 root@localhost data]#bzip2 -c -d /data/dir2/2.txt.bz2 > /data/dir1/2.txt [12:35:17 root@localhost data]#ls /data/dir1/2.txt /data/dir1/2.txt
2.5.4. xz 和 unxz
-
说明:来自于 xz 包,对应的文件是 .xz 后缀
-
格式
xz [OPTION]... FILE ... -
常用选项
-k keep, 保留原文件 -d 解压缩 -c 结果输出至标准输出,保留原文件不改变 -# 压缩比,取值1-9,默认为6 -
案例
#文件压缩 [12:41:32 root@localhost data]#xz -c 4.txt > /data/dir1/4.txt.xz [12:42:17 root@localhost data]#ls /data/dir1/4.txt.xz /data/dir1/4.txt.xz #文件解压 [12:42:24 root@localhost data]#xz -c -d /data/dir1/4.txt.xz > /data/dir1/4.txt [12:44:28 root@localhost data]#ls /data/dir1/4.txt /data/dir1/4.txt
2.5.5. zip 和 unzip
-
说明:zip 可以实现打包目录和多个文件成一个文件并压缩,但可能会丢失文件属性信息,如:所有者和组信
息,一般建议使用 tar 代替,分别来自于 zip 和 unzip 包对应的文件是 .zip 后缀 -
常用选项
-A 调整可执行的自动解压缩文件。 -b<工作目录> 指定暂时存放文件的目录。 -c 替每个被压缩的文件加上注释。 -d 从压缩文件内删除指定的文件。 -D 压缩文件内不建立目录名称。 -f 更新现有的文件。 -F 尝试修复已损坏的压缩文件。 -g 将文件压缩后附加在既有的压缩文件之后,而非另行建立新的压缩文件。 -h 在线帮助。 -i<范本样式> 只压缩符合条件的文件。 -j 只保存文件名称及其内容,而不存放任何目录名称。 -J 删除压缩文件前面不必要的数据。 -k 使用MS-DOS兼容格式的文件名称。 -l 压缩文件时,把LF字符置换成LF+CR字符。 -ll 压缩文件时,把LF+CR字符置换成LF字符。 -L 显示版权信息。 -m 将文件压缩并加入压缩文件后,删除原始文件,即把文件移到压缩文件中。 -n<字尾字符串> 不压缩具有特定字尾字符串的文件。 -o 以压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同。 -q 不显示指令执行过程。 -r 递归处理,将指定目录下的所有文件和子目录一并处理。 -S 包含系统和隐藏文件。 -t<日期时间> 把压缩文件的日期设成指定的日期。 -T 检查备份文件内的每个文件是否正确无误。 -u 与 -f 参数类似,但是除了更新现有的文件外,也会将压缩文件中的其他文件解压缩到目录中。 -v 显示指令执行过程或显示版本信息。 -V 保存VMS操作系统的文件属性。 -w 在文件名称里假如版本编号,本参数仅在VMS操作系统下有效。 -x<范本样式> 压缩时排除符合条件的文件。 -X 不保存额外的文件属性。 -y 直接保存符号连接,而非该连接所指向的文件,本参数仅在UNIX之类的系统下有效。 -z 替压缩文件加上注释。 -$ 保存第一个被压缩文件所在磁盘的卷册名称。 -<压缩效率> 压缩效率是一个介于1-9的数值。 -
案例
#打包文件并压缩 [12:51:26 root@localhost data]#zip -r /data/etc.zip /etc/ [12:52:14 root@localhost data]#ll /data/etc.zip -rw-r--r--. 1 root root 219634037 8月 8 12:50 /data/etc.zip #文件解压 [12:56:29 root@localhost data]#unzip /data/etc.zip [12:57:09 root@localhost data]#ll /data/ 总用量 214500 drwxr-xr-x. 156 root root 8192 8月 8 10:40 etc -rw-r--r--. 1 root root 219634037 8月 8 12:50 etc.zip
2.5.6. 打包和解包
2.5.6.1. tar
-
说明:tar 即 Tape ARchive 磁带归档,可以对目录和多个文件打包一个文件,并且可以压缩,保留文件属性不丢失,常用于备份功能,推荐使用对应的文件是 .tar 后缀
-
格式
tar [-ABcdgGhiklmMoOpPrRsStuUvwWxzZ][-b <区块数目>][-C <目的目录>][-f <备份文件>][-F <Script文件>][-K <文件>][-L <媒体容量>][-N <日期时间>][-T <范本文件>][-V <卷册名称>][-X <范本文件>][-<设备编号><存储密度>][--after-date=<日期时间>][--atime-preserve][--backuup=<备份方式>][--checkpoint][--concatenate][--confirmation][--delete][--exclude=<范本样式>][--force-local][--group=<群组名称>][--help][--ignore-failed-read][--new-volume-script=<Script文件>][--newer-mtime][--no-recursion][--null][--numeric-owner][--owner=<用户名称>][--posix][--erve][--preserve-order][--preserve-permissions][--record-size=<区块数目>][--recursive-unlink][--remove-files][--rsh-command=<执行指令>][--same-owner][--suffix=<备份字尾字符串>][--totals][--use-compress-program=<执行指令>][--version][--volno-file=<编号文件>][文件或目录...] -
常用选项
-A或--catenate 新增文件到已存在的备份文件。 -b<区块数目>或--blocking-factor=<区块数目> 设置每笔记录的区块数目,每个区块大小为12Bytes。 -B或--read-full-records 读取数据时重设区块大小。 -c或--create 建立新的备份文件。 -C<目的目录>或--directory=<目的目录> 切换到指定的目录。 -d或--diff或--compare 对比备份文件内和文件系统上的文件的差异。 -f<备份文件>或--file=<备份文件> 指定备份文件。 -F<Script文件>或--info-script=<Script文件> 每次更换磁带时,就执行指定的Script文件。 -g或--listed-incremental 处理GNU格式的大量备份。 -G或--incremental 处理旧的GNU格式的大量备份。 -h或--dereference 不建立符号连接,直接复制该连接所指向的原始文件。 -i或--ignore-zeros 忽略备份文件中的0 Byte区块,也就是EOF。 -k或--keep-old-files 解开备份文件时,不覆盖已有的文件。 -K<文件>或--starting-file=<文件> 从指定的文件开始还原。 -l或--one-file-system 复制的文件或目录存放的文件系统,必须与tar指令执行时所处的文件系统相同,否则不予复制。 -L<媒体容量>或-tape-length=<媒体容量> 设置存放每体的容量,单位以1024 Bytes计算。 -m或--modification-time 还原文件时,不变更文件的更改时间。 -M或--multi-volume 在建立,还原备份文件或列出其中的内容时,采用多卷册模式。 -N<日期格式>或--newer=<日期时间> 只将较指定日期更新的文件保存到备份文件里。 -o或--old-archive或--portability 将资料写入备份文件时使用V7格式。 -O或--stdout 把从备份文件里还原的文件输出到标准输出设备。 -p或--same-permissions 用原来的文件权限还原文件。 -P或--absolute-names 文件名使用绝对名称,不移除文件名称前的"/"号。 -r或--append 新增文件到已存在的备份文件的结尾部分。 -R或--block-number 列出每个信息在备份文件中的区块编号。 -s或--same-order 还原文件的顺序和备份文件内的存放顺序相同。 -S或--sparse 倘若一个文件内含大量的连续0字节,则将此文件存成稀疏文件。 -t或--list 列出备份文件的内容。 -T<范本文件>或--files-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让tar解开或建立符合设置条件的文件。 -u或--update 仅置换较备份文件内的文件更新的文件。 -U或--unlink-first 解开压缩文件还原文件之前,先解除文件的连接。 -v或--verbose 显示指令执行过程。 -V<卷册名称>或--label=<卷册名称> 建立使用指定的卷册名称的备份文件。 -w或--interactive 遭遇问题时先询问用户。 -W或--verify 写入备份文件后,确认文件正确无误。 -x或--extract或--get 从备份文件中还原文件。 -X<范本文件>或--exclude-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让ar排除符合设置条件的文件。 -z或--gzip或--ungzip 通过gzip指令处理备份文件。 -Z或--compress或--uncompress 通过compress指令处理备份文件。 -<设备编号><存储密度> 设置备份用的外围设备编号及存放数据的密度。 --after-date=<日期时间> 此参数的效果和指定"-N"参数相同。 --atime-preserve 不变更文件的存取时间。 --backup=<备份方式>或--backup 移除文件前先进行备份。 --checkpoint 读取备份文件时列出目录名称。 --concatenate 此参数的效果和指定"-A"参数相同。 --confirmation 此参数的效果和指定"-w"参数相同。 --delete 从备份文件中删除指定的文件。 --exclude=<范本样式> 排除符合范本样式的文件。 --group=<群组名称> 把加入设备文件中的文件的所属群组设成指定的群组。 --help 在线帮助。 --ignore-failed-read 忽略数据读取错误,不中断程序的执行。 --new-volume-script=<Script文件> 此参数的效果和指定"-F"参数相同。 --newer-mtime 只保存更改过的文件。 --no-recursion 不做递归处理,也就是指定目录下的所有文件及子目录不予处理。 --null 从null设备读取文件名称。 --numeric-owner 以用户识别码及群组识别码取代用户名称和群组名称。 --owner=<用户名称> 把加入备份文件中的文件的拥有者设成指定的用户。 --posix 将数据写入备份文件时使用POSIX格式。 --preserve 此参数的效果和指定"-ps"参数相同。 --preserve-order 此参数的效果和指定"-A"参数相同。 --preserve-permissions 此参数的效果和指定"-p"参数相同。 --record-size=<区块数目> 此参数的效果和指定"-b"参数相同。 --recursive-unlink 解开压缩文件还原目录之前,先解除整个目录下所有文件的连接。 --remove-files 文件加入备份文件后,就将其删除。 --rsh-command=<执行指令> 设置要在远端主机上执行的指令,以取代rsh指令。 --same-owner 尝试以相同的文件拥有者还原文件。 --suffix=<备份字尾字符串> 移除文件前先行备份。 --totals 备份文件建立后,列出文件大小。 --use-compress-program=<执行指令> 通过指定的指令处理备份文件。 --version 显示版本信息。 --volno-file=<编号文件> 使用指定文件内的编号取代预设的卷册编号。 -
创建归档,保留权限
tar -cpvf /PATH/FILE.tar FILE... -
追加文件至归档: 注:不支持对压缩文件追加
tar -rf /PATH/FILE.tar FILE...
- 查看归档文件中的文件列表
tar -t -f /PATH/FILE.tar
-
(4) 展开归档
tar xf /PATH/FILE.tar tar xf /PATH/FILE.tar -C /PATH/ -
(5) 结合压缩工具实现:归档并压缩
-z 相当于gzip压缩工具 -j 相当于bzip2压缩工具 -J 相当于xz压缩工具 -
案例1: 文件打包并压缩
[13:05:01 root@localhost data]#tar zcvf etc.tar.gz /etc/ [13:05:28 root@localhost data]#ll /data/etc.tar.gz -rw-r--r--. 1 root root 6568976 8月 8 13:04 /data/etc.tar.gz [13:07:35 root@localhost data]#tar jcvf etc.tar.bz2 /etc/ [13:08:01 root@localhost data]#ll etc.tar.bz2 -rw-r--r--. 1 root root 4821812 8月 8 13:08 etc.tar.bz2 [13:08:20 root@localhost data]#tar Jcvf etc.tar.xz /etc/ [13:13:52 root@localhost data]#ll /data/etc.tar.bz2 -rw-r--r--. 1 root root 4821812 8月 8 13:08 /data/etc.tar.bz2 -
案例2:解压
[13:23:53 root@localhost data]#tar xf etc.tar.gz -C ./ [13:24:24 root@localhost data]#ls etc etc.tar.bz2 etc.tar.gz etc.tar.xz etc.zip [13:24:28 root@localhost data]#ll 总用量 229620 drwxr-xr-x. 148 root root 8192 8月 8 10:40 etc -rw-r--r--. 1 root root 4821812 8月 8 13:08 etc.tar.bz2 -rw-r--r--. 1 root root 6568976 8月 8 13:04 etc.tar.gz -rw-r--r--. 1 root root 4086148 8月 8 13:09 etc.tar.xz -rw-r--r--. 1 root root 219634037 8月 8 12:50 etc.zip -
案例3:只打包目录内的文件,不所括目录本身
#方法1 [root@centos8 ~]#cd /etc [root@centos8 etc]#tar zcvf /root/etc.tar.gz ./ #方法2 [root@centos8 ~]#tar -C /etc -zcf etc.tar.gz ./ -
案例4:排除打包目录的文件并压缩
tar zcvf /root/a.tgz --exclude=/app/host1 --exclude=/app/host2 /app -
案例5:
- -T 选项指定输入文件
- -X 选项指定包含要排除的文件列表
tar zcvf mybackup.tgz -T /root/includefilelist -X /root/excludefilelist
2.5.6.2. split
-
说明:split 命令可以分割一个文件为多个文件
-
案例
#分割大的 tar 文件为多份小文件 split -b Size –d tar-file-name prefix-name 示例: split -b 1M mybackup.tgz mybackup-parts #切换成的多个小分文件使用数字后缀 split -b 1M –d mybackup.tgz mybackup-parts -
将多个切割的小文件合并成一个大文件
cat mybackup-parts* > mybackup.tar.gz
2.6. 文本处理三剑客之sed

-
说明:
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到 最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(Pattern Space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下 一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时 不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为 vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理, 打开速度非常快,执行速度也很快
2.6.1. sed 基本用法
-
格式
sed [option]... 'script;script;...' [inputfile...] -
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印 -e 多点编辑 -f FILE 从指定文件中读取编辑脚本 -r, -E 使用扩展正则表达式 -i.bak 备份文件并原处编辑 -s 将多个文件视为独立文件,而不是单个连续的长文件流 #说明: -ir 不支持 -i -r 支持 -ri 支持 -ni 危险选项,会清空文件 -
script 格式:
'地址命令' -
地址格式:
1. 不给地址:对全文进行处理 2. 单地址: #:指定的行,$:最后一行 /pattern/:被此处模式所能够匹配到的每一行 3. 地址范围: #,# #从#行到第#行,3,6 从第3行到第6行 #,+# #从#行到+#行,3,+4 表示从3行到第7行 /pat1/,/pat2/ #,/pat/ /pat/,# 4. 步进:~ 1~2 奇数行 2~2 偶数行 -
命令
p 打印当前模式空间内容,追加到默认输出之后 Ip 忽略大小写输出 d 删除模式空间匹配的行,并立即启用下一轮循环 a [\]text 在指定行后面追加文本,支持使用\n实现多行追加 i [\]text 在行前面插入文本 c [\]text 替换行为单行或多行文本 w file 保存模式匹配的行至指定文件 r file 读取指定文件的文本至模式空间中匹配到的行后 = 为模式空间中的行打印行号 ! 模式空间中匹配行取反处理 q 结束或退出sed -
查找替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s### 替换修饰符: g 行内全局替换 p 显示替换成功的行 w /PATH/FILE 将替换成功的行保存至文件中 I,i 忽略大小写
2.7. 文本处理三剑客之sed高有用法
3. shell编程基础
3.1. shell编程基础
3.1.1. shell脚本编程
是基于过程式、解释执行的语言
3.1.2. 编程语言的基本结构
-
各种系统命令的组合
-
数据存储:变量、数组
-
表达式:a + b
-
控制语句:if
-
shell脚本:包含一些命令或声明,并符合一定格式的文本文件
-
格式要求:首行shebang机制
#!/bin/bash #!/usr/bin/python #!/usr/bin/perl #!/usr/bin/ruby #!/usr/bin/lua
3.1.3. shell脚本的创建
-
第一步:使用文本编辑器来创建文本文件,第一行必须包括shell声明序列:注释开头#!
#!/bin/bash -
第二步:加执行权限,给予执行权限,在命令行上指定脚本的绝对或相对路径
-
第三步:运行脚本,直接运行解释器,将脚本作为解释器程序的参数运行
3.1.4. shell脚本注释规范
- 第一行一般为调用使用的语言
- 程序名称,避免更改文件名为无法找到正确的文件
- 版本号
- 更改后的时间
- 作者相关信息
- 该程序的作用,及注意事项
- 最后是各版本的更新简要说明
3.1.5. 第一个shell脚本
-
第一步:使用文本编辑器来创建文本文件,第一行必须包括shell声明序列:注释开头#!
#!/bin/bash
3.1.6. shell脚本注释规范
- 第一行一般为调用使用的语言
- 程序名称,避免更改文件名为无法找到正确的文件
- 版本号
- 更改后的时间
- 作者相关信息
- 该程序的作用,及注意事项
- 最后是各版本的更新简要说明
3.1.7. 第一个shell脚本
[01:34:44 root@localhost ~]#vim hello.sh 1 #!/bin/bash 2 #Author:张雪龙 3 #2022-08-06 01:37:12 4 # mail: 1024320609@qq.com 5 ############################# 6 7 #经典写法 8 echo "hello, world" 9 #流行写法 10 echo 'Hello, world!'
3.1.8. shell执行方法种类
-
bash + 脚本文件名
[01:43:24 root@localhost ~]#bash hello.sh hello, world Hello, world! -
cat + 脚本文件名 |bash
[01:47:26 root@localhost ~]#cat hello.sh |bash hello, world Hello, world! -
bash < 脚本文件名
[01:47:51 root@localhost ~]#bash < hello.sh hello, world Hello, world! -
chmod +x 脚本文件 ——》./脚本文件名
[01:48:20 root@localhost ~]#ll hello.sh -rw-r--r--. 1 root root 177 8月 6 01:39 hello.sh [01:48:53 root@localhost ~]#chmod +x hello.sh [01:49:19 root@localhost ~]#./hello.sh hello, world
3.2. shell编程使用变量
3.2.1. 变量
表示命名的内存空间,将数据放在内存空间中,通过变量名引用,获取数据。
3.2.2. 变量类型:
-
内置变量,如:PS1,PATH,UID,HOSTNAME,$$,BASHPID,PPID,$?,HISTSIZE
-
用户自定义变量
-
不同的变量存放的数据不同,决定了以下
- 数据存储方式
- 参与的运算
- 表示的数据范围
-
变量数据类型:
- 字符
- 数值:整型、浮点型, bash 不支持浮点数
3.2.3. Shell中变量命名法则
- 命名要求
- 区分大小写
- 不能使程序中的保留字和内置变量:如:if, for
- 只能使用数字、字母及下划线,且不能以数字开头,注意:不支持短横线 “ - ”,和主机名相反
3.2.4. 命名习惯
- 见名知义,用英文单词命名,并体现出实际作用,不要用简写,如:ATM
- 变量名大写
- 局部变量小写
- 函数名小写
- 大驼峰StudentFirstName,由多个单词组成,且每个单词的首字母是大写,其它小写
- 小驼峰studentFirstName ,由多个单词组成,第一个单词的首字母小写,后续每个单词的首字母是大写,其它小写
- 下划线: student_name
3.2.5. 变量定义和引用
变量的生效范围等标准划分变量类型
- 普通变量:生效范围为当前shell进程;对当前shell之外的其它shell进程,包括当前shell的子shell进程均无效
- 环境变量:生效范围为当前shell进程及其子进程
- 本地变量:生效范围为当前shell进程中某代码片断,通常指函数
3.2.6. 变量赋值
-
name='value' -
value 可以是以下多种形式
直接字串:name='root' 变量引用:name="$USER" 命令引用:name=`COMMAND` 或者 name=$(COMMAND) -
注意:变量赋值是临时生效,当退出终端后,变量会自动删除,无法持久保存,脚本中的变量会随着脚本结束,也会自动删除
-
变量引用
$name ${name} -
弱引用和强引用
- "$name" 弱引用,其中的变量引用会被替换为变量值
- '$name' 强引用,其中的变量引用不会被替换为变量值,而保持原字符串
-
范例:变量的各种赋值方式和引用
[02:54:02 root@localhost data]#name='zhang' [03:22:57 root@localhost data]#echo $name zhang [03:23:03 root@localhost data]#echo I am $name I am zhang [03:23:25 root@localhost data]#echo "I am $name" I am zhang [03:23:42 root@localhost data]#echo 'I am $name' I am $name [03:23:50 root@localhost data]#echo $USER root [03:25:40 root@localhost data]#name=$USER [03:26:08 root@localhost data]#echo $name root [03:27:11 root@localhost data]#USER=`whoami` [03:27:37 root@localhost data]#echo $USER root
-
3.3. shell各种位置变量和状态变量
3.3.1. 位置变量
-
位置变量:在bash shell中内置的变量, 在脚本代码中调用通过命令行传递给脚本的参数
$1, $2, ... 对应第1个、第2个等参数,shift [n]换位置 $0 命令本身,包括路径 $* 传递给脚本的所有参数,全部参数合为一个字符串 $@ 传递给脚本的所有参数,每个参数为独立字符串 $# 传递给脚本的参数的个数 注意:$@ $* 只在被双引号包起来的时候才会有差异 -
案例1
[01:48:53 root@localhost ~]#bash /root/postion.sh 1 2 3 4 5 6 7 8 9 10 11 12 0st arg is /root/postion.sh 1st arg is 1 2st arg is 2 3st arg is 3 10st arg is 10 11st arg is 11 The number of arg is 12 All args are 1 2 3 4 5 6 7 8 9 10 11 12 All args are 1 2 3 4 5 6 7 8 9 10 11 12 The scriptname is postion.sh [01:49:07 root@localhost ~]#cat postion.sh #!/bin/bash # ********************************************************** # # * Author : 张雪龙 # * Email : 1024320609@qq.com # * Create time : 2022-08-07 01:43 # * Filename : postion.sh # * Description : # # ********************************************************** echo "0st arg is $0" echo "1st arg is $1" echo "2st arg is $2" echo "3st arg is $3" echo "10st arg is ${10}" echo "11st arg is ${11}" echo "The number of arg is $#" echo "All args are $*" echo "All args are $@" echo "The scriptname is `basename $0`" -
$*和$@的区别
-
当$*和$@没有被引用的时候,它们确实没有什么区别,都会把位置参数当成一个个体。(我们最好不要使用,因为如果位置参数中带有空格或者通配符的情况下,可能结果会和我们想要的不一样)
-
"$" 会把所有位置参数当成一个整体(或者说当成一个单词),如果没有位置参数,则"$"为空,如果有两个位置参数并且IFS为空格时,"$*"相当于"$1 $2"
-
"$@" 会把所有位置参数当成一个单独的字段,如果没有位置参数($#为0),则"$@"展开为空(不是空字符串,而是空列表),如果存在一个位置参数,则"$@"相当于"$1",如果有两个参数,则"$@"相当于"$1" "$2"等等
-
案例
[root@centos8 scripts]#cat f1.sh #!/bin/bash echo "f1.sh:all args are $@" echo "f1.sh:all args are $*" ./file.sh "$*" [root@centos8 scripts]#cat f2.sh #!/bin/bash echo "f2.sh:all args are $@" echo "f2.sh:all args are $*" ./file.sh "$@" [root@centos8 scripts]#cat file.sh #!/bin/bash echo "file.sh:1st arg is $1" [root@centos8 scripts]#./f1.sh a b c f1.sh:all args are a b c f1.sh:all args are a b c file.sh:1st arg is a b c [root@centos8 scripts]#./f2.sh a b c f2.sh:all args are a b c f2.sh:all args are a b c file.sh:1st arg is a
-
3.3.2. 退出状态码变量
-
$? 变量 保存状态码的相关数字,不同的值反应成功或失败,$?取值范例 0-255
$?的值为0 #代表成功 $?的值是1到255 #代表失败 -
案例
[02:04:25 root@localhost ~]#ping 114.114.114.114 -c1 >/dev/null [02:05:16 root@localhost ~]#echo $? 0 -
用户可以在脚本中使用以下命令自定义退出状态码
exit [n] - 注意:
- 脚本中一旦遇到exit命令,脚本会立即终止;终止退出状态取决于exit命令后面的数字
- 如果exit后面无数字,终止退出状态取决于exit命令前面命令执行结果
- 如果没有exit命令, 即未给脚本指定退出状态码,整个脚本的退出状态码取决于脚本中执行的最后
一条命令的状态码
- 注意:
3.4. shell编程算术和逻辑运算
3.4.1. 算数运算
-
说明
Shell允许在某些情况下对算术表达式进行求值,比如:let和declare 内置命令,(( ))复合命令和算术扩展。求值以固定宽度的整数进行,不检查溢出,尽管除以0 被困并标记为错误。运算符及其优先级,关联性和值与C语言相同。以下运算符列表分组为等优先级运算符级别。级别按降序排列优先 - 注意:bash 只支持整数,不支持小数
-
选项
+ - addition, subtraction * / % multiplication, division, remainder, %表示取模,即取余数,示例:9%4=1,5%3=2 i++ i-- variable post-increment and post-decrement ++i --i variable pre-increment and pre-decrement = *= /= %= += -= <<= >>= &= ^= |= assignment - + unary minus and plus ! ~ logical and bitwise negation ** exponentiation 乘方,即指数运算 << >> left and right bitwise shifts <= >= < > comparison == != equality and inequality & bitwise AND | bitwise OR ^ bitwise exclusive OR && logical AND || logical OR expr?expr:expr conditional operator expr1 , expr2 comma 乘法符号有些场景中需要转
-
算术运算:
(1) let var=算术表达式 (2) ((var=算术表达式)) 和上面等价 (3) var=$[算术表达式] (4) var=$((算术表达式)) (5) var=$(expr arg1 arg2 arg3 ...) (6) declare -i var = 数值 (7) echo '算术表达式' | bc -
内建的随机数生成器变量
$RANDOM 取值范围:0-32767 -
案例
#生成 0 - 49 之间随机数 echo $[$RANDOM%50] #随机字体颜色 [root@centos8 ~]#echo -e "\033[1;$[RANDOM%7+31]mhello\033[0m" magedu -
增强型赋值
+= i+=10 相当于 i=i+10 -= i-=j 相当于 i=i-j *= /= %= ++ i++,++i 相当于 i=i+1 -- i--,--i 相当于 i=i-1 -
格式
[root@centos8 ~]#let i=10*2 [root@centos8 ~]#echo $i 20 [root@centos8 ~]#((j=i+10)) [root@centos8 ~]#echo $j 30 -
案例2
#自加3后自赋值 let count+=3 [root@centos8 ~]#i=10 [root@centos8 ~]#let i+=20 #相当于let i=i+20 [root@centos8 ~]#echo $i 30 [root@centos8 ~]#j=20 [root@centos8 ~]#let i*=j [root@centos8 ~]#echo $i 600 -
案例3
#自增,自减 let var+=1 let var++ let var-=1 let var-- [root@centos8 ~]#unset i j ; i=1; let j=i++; echo "i=$i,j=$j" i=2,j=1 [root@centos8 ~]#unset i j ; i=1; let j=++i; echo "i=$i,j=$j" i=2,j=2 -
案例4
[root@centos8 ~]#expr 2 * 3 expr: syntax error: unexpected argument ‘anaconda-ks.cfg’ [root@centos8 ~]#ls anaconda-ks.cfg [root@centos8 ~]#expr 2 \* 3 6 -
案例5
[root@centos8 ~]#i=10 [root@centos8 ~]#j=20 [root@centos8 ~]#declare -i result=i*j [root@centos8 ~]#echo $result 200
3.4.2. 逻辑运行
3.4.2.1. 与或非

-
true, false
1,真 0,假 #注意,以上为二进制 -
与:& 和0相与结果为0,和1相与结果保留原值, 一假则假,全真才真为0
0 与 0 = 0 0 与 1 = 0 1 与 0 = 0 1 与 1 = 1 -
案例
[root@ubuntu1804 ~]#x=$[2&6] [root@ubuntu1804 ~]#echo $x 2 [root@ubuntu1804 ~]#x=$[7&3] [root@ubuntu1804 ~]#echo $x 3 -
或:| 和1相或结果为1,和0相或结果保留原值,一真则真,全假才假
0 或 0 = 0 0 或 1 = 1 1 或 0 = 1 1 或 1 = 1 -
范例
[root@ubuntu1804 ~]#x=$[7|3] [root@ubuntu1804 ~]#echo $x 7 [root@ubuntu1804 ~]#x=$[2|5] [root@ubuntu1804 ~]#echo $x 7 -
非:!
! 1 = 0 ! true ! 0 = 1 ! false -
异或:^
- 异或的两个值,相同为假,不同为真。两个数字X,Y异或得到结果Z,Z再和任意两者之一X异或,将得出另一个值Y
0 ^ 0 = 0 0 ^ 1 = 1 1 ^ 0 = 1 1 ^ 1 = 0 -
案例
[root@centos8 ~]#true [root@centos8 ~]#echo $? 0 [root@centos8 ~]#false [root@centos8 ~]#echo $? 1 [root@centos8 ~]#! true [root@centos8 ~]#echo $? 1 [root@centos8 ~]#! false [root@centos8 ~]#echo $?
3.5. shell编程的条件组合
3.5.1. 第一种方式
-
格式
[ EXPRESSION1 -a EXPRESSION2 ] #并且,EXPRESSION1和EXPRESSION2都是真,结果才为真 [ EXPRESSION1 -o EXPRESSION2 ] #或者,EXPRESSION1和EXPRESSION2只要有一个真,结果就为真 [ ! EXPRESSION ] #取反 -
说明: -a 和 -o 需要使用测试命令进行,[[ ]] 不支持
-
案例
[root@centos8 ~]#FILE="/data/scrips/test.sh" [root@centos8 ~]#ll /data/scrips/test.sh -rw-r--r-- 1 root root 382 Dec 23 09:32 /data/scripts/test.sh [root@centos8 ~]#[ -f $FILE -a -x $FILE ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#chmod +x /data/scripts/test.sh [root@centos8 ~]#ll /data/scripts/test.sh -rwxr-xr-x 1 root root 382 Dec 23 09:32 /data/script40/test.sh #并且 [root@centos8 ~]#[ -f $FILE -a -x $FILE ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#chmod -x /data/scripts/test.sh [root@centos8 ~]#ll /data/scripts/test.sh -rw-r--r-- 1 root root 382 Dec 23 09:32 /data/scripts/test.sh #或者 [root@centos8 ~]#[ -f $FILE -o -x $FILE ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ -x $FILE ] [root@centos8 ~]#echo $? 1 #取反 [root@centos8 ~]#[ ! -x $FILE ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#! [ -x $FILE ] 0
3.5.2. 第二种方式
-
格式
COMMAND1 && COMMAND2 #并且,短路与,代表条件性的AND THEN 如果COMMAND1 成功,将执行COMMAND2,否则,将不执行COMMAND2 COMMAND1 || COMMAND2 #或者,短路或,代表条件性的OR ELSE 如果COMMAND1 成功,将不执行COMMAND2,否则,将执行COMMAND2 ! COMMAND #非,取反 [root@centos7 ~]#[ $[RANDOM%6] -eq 0 ] && rm -rf /* || echo "click" -
案例1
[root@centos8 ~]#test "A" = "B" && echo "Strings are equal" [root@centos8 ~]#test "A"-eq "B" && echo "Integers are equal" [root@centos8 ~]#[ "A" = "B" ] && echo "Strings are equal" [root@centos8 ~]#[ "$A" -eq "$B" ] && echo "Integers are equal" [root@centos8 ~]#[ -f /bin/cat -a -x /bin/cat ] && cat /etc/fstab [root@centos8 ~]#[ -z "$HOSTNAME" -o "$HOSTNAME" = "localhost.localdomain" ]&& hostname www.magedu.com [root@centos8 ~]#id wang &> /dev/null || useradd wang [root@centos8 ~]#id zhang &> /dev/null || useradd zhang [root@centos8 ~]#getent passwd zhang zhang:x:1002:1002::/home/zhang:/bin/bash [root@centos8 ~]#grep -q no_such_user /etc/passwd || echo 'No such user' No such user -
案例2
[root@centos8 ~]#[ -f “$FILE” ] && [[ “$FILE”=~ .*\.sh$ ]] && chmod +x $FILE [root@centos8 ~]#ping -c1 -W1 172.16.0.1 &> /dev/null && echo '172.16.0.1 is up' || (echo '172.16.0.1 is unreachable'; exit 1) 172.16.0.1 is up [root@centos8 ~]#IP=10.0.0.111;ping -c1 -W1 $IP &> /dev/null && echo $IP is up || echo $IP is down 10.0.0.111 is down [root@centos8 ~]#IP=10.0.0.1;ping -c1 -W1 $IP &> /dev/null && echo $IP is up || echo $IP is down 10.0.0.1 is up -
案例3::&& 和 || 组合使用
[root@centos8 ~]#NAME=wang; id $NAME &> /dev/null && echo "$NAME is exist" wang is exist [root@centos8 ~]#NAME=wange; id $NAME &> /dev/null || echo "$NAME is not exist" wange is not exist [root@centos8 ~]#NAME=wange; id $NAME &> /dev/null && echo "$NAME is exist" || echo "$NAME is not exist" wange is not exist [root@centos8 ~]#NAME=wang; id $NAME &> /dev/null && echo "$NAME is exist" || echo "$NAME is not exist" wang is exist [root@centos8 ~]#NAME=wang; id $NAME &> /dev/null && echo "$NAME is exist" || echo "$NAME is not exist" wang is exist [root@centos8 ~]#NAME=wang; id $NAME &> /dev/null || echo "$NAME is not exist" && echo "$NAME is exist" wang is exist [root@centos8 ~]#NAME=wange; id $NAME &> /dev/null || echo "$NAME is not exist" && echo "$NAME is exist" wange is not exist wange is exist #结论:如果&& 和 || 混合使用,&& 要在前,|| 放在后 [root@centos8 ~]#NAME=wange; id $NAME &> /dev/null && echo "$NAME is exist" || useradd $NAME [root@centos8 ~]#id wange uid=1002(wange) gid=1002(wange) groups=1002(wange) [root@centos8 ~]#NAME=wangge; id $NAME &> /dev/null && echo "$NAME is exist" || ( useradd $NAME; echo $NAME is created ) wangge is created [root@centos8 ~]#id wangge uid=1003(wangge) gid=1003(wangge) groups=1003(wangge) [root@centos8 ~]#NAME=wanggege; id $NAME &> /dev/null && echo "$NAME is exist" || { useradd $NAME; echo $NAME is created; } wanggege is created -
案例4:网络状态判断
[root@centos8 ~]#cat /data/scripts/ping.sh IP=172.16.0.1 ping -c1 -W1 $IP &> /dev/null && echo "$IP is up" || { echo "$IP is unreachable"; exit; } echo "Script is finished" [root@centos8 ~]#bash /data/scripts/ping.sh 172.16.0.1 is up Script is finished -
案例5
[root@centos8 ~]#. /etc/os-release; [[ $ID == "rocky" ]] && [[ $VERSION_ID == 8* ]] && echo Rocky8 || echo CentOS8 [root@rocky8 ~]#. /etc/os-release; [[ $ID == "rocky" ]] && [[ $VERSION_ID == 8* ]] && echo Rocky8 || echo CentOS8 Rocky8 -
案例6:磁盘空间的判断
[root@centos8 ~]#cat /data/script/disk_check.sh #!/bin/bash WARNING=80 SPACE_USED=`df|grep '^/dev/sd'|tr -s ' ' %|cut -d% -f5|sort -nr|head -1` [ "$SPACE_USED" -ge $WARNING ] && echo "disk used is $SPACE_USED,will be full" | mail -s diskwaring root -
案例7:磁盘空间和Inode号的检查脚本
[root@centos8 scripts]#cat disk_check.sh WARNING=80 SPACE_USED=`df | grep '^/dev/sd'|grep -oE '[0-9]+%'|tr -d %| sort -nr|head -1` INODE_USED=`df -i | grep '^/dev/sd'|grep -oE '[0-9]+%'|tr -d %| sort -nr|head -1` [ "$SPACE_USED" -gt $WARNING -o "$INODE_USED" -gt $WARNING ] && echo "DISK USED:$SPACE_USED%, INODE_USED:$INODE_USED,will be full" | mail -s "DISK Warning" root@wangxiaochun.com
3.6. shell编程条件测试
-
测试:判断某需求是否满足,需要由测试机制来实现,专用的测试表达式需要由测试命令辅助完成测试过程,实现评估布尔声明,以便用在条件性环境下进行执行
- 若真,则状态码变量 $? 返回0
- 若假,则状态码变量 $? 返回1
-
条件测试命令
- test EXPRESSION
- [ EXPRESSION ] #和test 等价,建议使用 [ ]
- [[ EXPRESSION ]] 相关于增强版的 [ ], 支持[]的用法,且支持扩展正则表达式和通配符
-
注意:EXPRESSION前后必须有空白字符
-
帮助
[root@centos8 ~]#type [ [ is a shell builtin [root@centos8 ~]#help [ [: [ arg... ]
3.6.1. 变量测试
-
格式
#判断 NAME 变量是否定义 [ -v NAME ] -
案例
[root@centos8 ~]#unset x [root@centos8 ~]#test -v x [root@centos8 ~]#echo $? 1 [root@centos8 ~]#x=10 [root@centos8 ~]#test -v x [root@centos8 ~]#echo $? 0 [root@centos8 ~]#y= [root@centos8 ~]#test -v y [root@centos8 ~]#echo $? 0 #注意 [ ] 中需要空格,否则会报下面错误 [root@centos8 ~]#[-v name] -bash: [-v: command not found
3.6.2. 数值测试
-
格式
-eq 是否等于 -ne 是否不等于 -gt 是否大于 -ge 是否大于等于 -lt 是否小于 -le 是否小于等于 -
案例
[root@centos8 ~]#i=10 [root@centos8 ~]#j=8 [root@centos8 ~]#[ $i -lt $j ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ $i -gt $j ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ i -gt j ] -bash: [: i: integer expression expected -
算术表达式比较
== 相等 != 不相等 <= >= < > -
案例1
[root@centos8 ~]#x=10;y=10;(( x == y ));echo $? 0 [root@centos8 ~]#x=10;y=20;(( x == y ));echo $? 1 [root@centos8 ~]#x=10;y=20;(( x != y ));echo $? 0 [root@centos8 ~]#x=10;y=10;(( x != y ));echo $? 1 -
案例2
[root@centos8 ~]#x=10;y=20;(( x > y ));echo $? 1 [root@centos8 ~]#x=10;y=20;(( x < y ));echo $? 0
3.6.3. 字符串测试
-
test和 [ ] 字符串测试用法
-z STRING 字符串是否为空,没定义或空为真,不空为假, -n STRING 字符串是否不空,不空为真,空为假 STRING 同上 STRING1 = STRING2 是否等于,注意 = 前后有空格 STRING1 != STRING2 是否不等于 > ascii码是否大于ascii码 < 是否小于 -
[[]] 字符串测试用法
[[ expression ]] 用法 == 左侧字符串是否和右侧的PATTERN相同 注意:此表达式用于[[ ]]中,PATTERN为通配符 =~ 左侧字符串是否能够被右侧的正则表达式的PATTERN所匹配 注意: 此表达式用于[[ ]]中为扩展的正则表达式 -
建议:当使用正则表达式或通配符使用[[ ]],其它情况一般使用 [ ]
-
案例:使用 [ ]
[root@centos8 ~]#unset str [root@centos8 ~]#[ -z "$str" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#str="" [root@centos8 ~]#[ -z "$str" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#str=" " [root@centos8 ~]#[ -z "$str" ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ -n "$str" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#unset str [root@centos8 ~]#[ -n "$str" ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ "$str" ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#str=magedu [root@centos8 ~]#[ "$str" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#str=magedu [root@centos8 ~]#[ "$str" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#str1=magedu [root@centos8 ~]#str2=mage [root@centos8 ~]#[ $str1 = $str2 ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#str2=magedu [root@centos8 ~]#[ $str1 = $str2 ] [root@centos8 ~]#echo $? 0 -
案例2:在比较字符串时,建议变量放在“ ”中
[root@centos8 ~]#[ "$NAME" ] [root@centos8 ~]#NAME="I love linux" [root@centos8 ~]#[ $NAME ] -bash: [: love: binary operator expected [root@centos8 ~]#[ "$NAME" ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ I love linux ] -bash: [: love: binary operator expected -
案例3:[[ ]] 和通配符
[root@centos8 ~]#FILE="a*" [root@centos8 ~]#echo $FILE a* [root@centos8 ~]#[[ $FILE == a* ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#FILE="ab" [root@centos8 ~]#[[ $FILE == a* ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#FILE="a*" #[[]]中如果不想使用通配符*,只想表达*本身,可以用" "引起来 [root@centos8 ~]#[[ $FILE == a"*" ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#FILE="ab" [root@centos8 ~]#[[ $FILE == a"*" ]] [root@centos8 ~]#echo $? 1 #[[]]中如果不想使用通配符*,只想表达*本身,也可以使用转义符 [root@centos8 ~]#[[ $FILE == a\* ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#FILE="a\b" [root@centos8 ~t]#[[ $FILE == a\* ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#FILE="a*" [root@centos8 ~]#[[ $FILE == a\* ]] [root@centos8 ~]#echo $? 0 #通配符? [root@centos8 script]#FILE=abc [root@centos8 script]#[[ $FILE == ??? ]] [root@centos8 script]#echo $? 0 [root@centos8 script]#FILE=abcd [root@centos8 script]#[[ $FILE == ??? ]] [root@centos8 script]#echo $? 1 #通配符 [root@centos8 ~]#NAME="linux1" [root@centos8 ~]#[[ "$NAME" == linux* ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[[ "$NAME" == "linux*" ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#NAME="linux*" [root@centos8 ~]#[[ "$NAME" == "linux*" ]] [root@centos8 ~]#echo $? 0 #结论:[[ == ]] == 右侧的 * 做为通配符,不要加“”,只想做为*符号使用时, 需要加 “” 或转义 -
案例4:判断合理的考试成绩
[root@centos8 script]#SCORE=101 [root@centos8 script]#[[ $SCORE =~ 100|[0-9]{1,2} ]] [root@centos8 script]#echo $? 0 [root@centos8 script]#[[ $SCORE =~ ^(100|[0-9]{1,2})$ ]] [root@centos8 script]#echo $? 1 [root@centos8 script]#SCORE=10 [root@centos8 script]#[[ $SCORE =~ ^(100|[0-9]{1,2})$ ]] [root@centos8 script]#echo $? 0 [root@centos8 script]#SCORE=abc [root@centos8 script]#[[ $SCORE =~ ^(100|[0-9]{1,2})$ ]] [root@centos8 script]#echo $? 1 -
案例5:使用 [[ ]] 判断文件后缀
#通配符 [root@centos8 ~]#FILE=test.log [root@centos8 ~]#[[ "$FILE" == *.log ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#FILE=test.txt [root@centos8 ~]#[[ "$FILE" == *.log ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[[ "$FILE" != *.log ]] [root@centos8 ~]#echo $? 0 #正则表达式 [root@centos8 ~]#[[ "$FILE" =~ \.log$ ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#FILE=test.log [root@centos8 ~]#[[ "$FILE" =~ \.log$ ]] [root@centos8 ~]#echo $? 0 -
案例6:判断合法的非负整数
[root@centos8 ~]#N=100 [root@centos8 ~]#[[ "$N" =~ ^[0-9]+$ ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#N=Magedu10 [root@centos8 ~]#[[ "$N" =~ ^[0-9]+$ ]] [root@centos8 ~]#echo $? 1 -
案例7:判断合法IP
[root@centos8 ~]#IP=1.2.3.4 [root@centos8 ~]#[[ "$IP" =~ ^([0-9]{1,3}\.){3}[0-9]{1,3}$ ]] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#IP=1.2.3.4567 [root@centos8 ~]#[[ "$IP" =~ ^([0-9]{1,3}.){3}[0-9]{1,3}$ ]] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[[ $IP =~ ^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3} ([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$ ]] [root@centos8 ~]#echo $? 1 -
案例8
[root@centos7 ~]#cat check_ip.sh IP=$1 [[ $IP =~ ^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9] {2}|2[0-4][0-9]|25[0-5])$ ]] && echo $IP is valid || echo $IP is invalid
3.6.4. 文件测试
-
存在性测试
-a FILE:同 -e -e FILE: 文件存在性测试,存在为真,否则为假 -b FILE:是否存在且为块设备文件 -c FILE:是否存在且为字符设备文件 -d FILE:是否存在且为目录文件 -f FILE:是否存在且为普通文件 -h FILE 或 -L FILE:存在且为符号链接文件 -p FILE:是否存在且为命名管道文件 -S FILE:是否存在且为套接字文件 -
案例:-e和-a 表示判断文件的存在性,建议使用-e
#文件是否不存在 [root@centos8 ~]#[ -a /etc/nologin ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#! [ -a /etc/nologin ] [root@centos8 ~]#echo $? 0 #文件是否存在 [root@centos8 ~]# [ -a /etc/issue ] [root@centos8 ~]#echo $? 0 #取反后结果却没有变化 [root@centos8 ~]# [ ! -a /etc/issue ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#! [ -a /etc/issue ] [root@centos8 ~]#echo $? 1 #文件是否存在 [root@centos8 ~]#! [ -e /etc/issue ] [root@centos8 ~]#echo $? 1 #此为推荐写法 [root@centos8 ~]#[ ! -e /etc/issue ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ -d /etc ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ -d /etc/issue ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ -L /bin ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ -L /bin/ ] [root@centos8 ~]#echo $? 1 -
文件权限测试
-r FILE:是否存在且可读 -w FILE: 是否存在且可写 -x FILE: 是否存在且可执行 -u FILE:是否存在且拥有suid权限 -g FILE:是否存在且拥有sgid权限 -k FILE:是否存在且拥有sticky权限 -
注意:最终结果由用户对文件的实际权限决定,而非文件属性决定
-
案例
[root@centos8 ~]#[ -w /etc/shadow ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#[ -x /etc/shadow ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#[ -w test.txt ] [root@centos8 ~]#echo $? 0 [root@centos8 ~]#chattr +i test.txt [root@centos8 ~]#lsattr test.txt ----i-------------- nianling.txt [root@centos8 ~]#[ -w test.txt ] [root@centos8 ~]#echo $? 1 [root@centos8 ~]#chattr -i test.txt [root@centos8 ~]#[ -w test.txt ] [root@centos8 ~]#echo $? 0 -
文件属性测试
-s FILE #是否存在且非空 -t fd #fd 文件描述符是否在某终端已经打开 -N FILE #文件自从上一次被读取之后是否被修改过 -O FILE #当前有效用户是否为文件属主 -G FILE #当前有效用户是否为文件属组 FILE1 -ef FILE2 #FILE1是否是FILE2的硬链接 FILE1 -nt FILE2 #FILE1是否新于FILE2(mtime) FILE1 -ot FILE2 #FILE1是否旧于FILE2
3.7. shell编程for循环
- 说明:将某代码段重复运行多次,通常有进入循环的条件和退出循环的条件
重复运行次数- 次数事先已知
- 循环次数事先未知
- 常见的循环的命令:for, while, until

3.7.1. 循环 for
-
帮助
#CentOS7的for帮助比CentOS8全面 [root@centos7 ~]#help for for: for NAME [in WORDS ... ] ; do COMMANDS; done Execute commands for each member in a list. The `for' loop executes a sequence of commands for each member in a list of items. If `in WORDS ...;' is not present, then `in "$@"' is assumed. For each element in WORDS, NAME is set to that element, and the COMMANDS are executed. Exit Status: Returns the status of the last command executed. for ((: for (( exp1; exp2; exp3 )); do COMMANDS; done Arithmetic for loop. Equivalent to (( EXP1 )) while (( EXP2 )); do COMMANDS (( EXP3 )) done EXP1, EXP2, and EXP3 are arithmetic expressions. If any expression is omitted, it behaves as if it evaluates to 1. Exit Status: Returns the status of the last command executed. [root@centos7 ~]# -
格式
for NAME [in WORDS ... ] ; do COMMANDS; done #方式1 for 变量名 in 列表;do 循环体 done #方式2 for 变量名 in 列表 do 循环体 done -
执行机制:
- 依次将列表中的元素赋值给“变量名”; 每次赋值后即执行一次循环体; 直到列表中的元素耗尽,循环结束
- 如果省略 [in WORDS ... ] ,此时使用位置参数变量 in "$@"
-
for 循环列表生成方式:
- 直接给出列表
- 整数列表
{start..end} $(seq [start [step]] end) -
返回列表的命令
$(COMMAND) -
使用glob,如:.sh
-
变量引用,如:$@,$*,$#
-
案例1:计算1+2+3+...+100 的结果
[root@centos8 ~]#sum=0;for i in {1..100};do let sum+=i;done ;echo sum=$sum sum=5050 [root@centos8 ~]#seq -s+ 100|bc5050 5050 [root@centos8 ~]#echo {1..100}|tr ' ' +|bc 5050 [root@centos8 ~]#seq 100|paste -sd +|bc 5050 -
案例2:100以内的奇数之和
[root@centos8 ~]#sum=0;for i in {1..100..2};do let sum+=i;done;echo sum=$sum sum=2500 [root@centos8 ~]#seq -s+ 1 2 100| bc 2500 [root@centos8 ~]#echo {1..100..2}|tr ' ' + | bc 2500 -
案例3
[root@centos8 ~]#cat /data/scripts/for_sum.sh sum=0 for i in $* ; do let sum+=i done echo sum=$sum [root@centos8 ~]#bash /data/scripts/for_sum.sh 1 2 3 4 5 6 sum=21 -
案例4:批量创建用户
[root@centos8 ~]#cat createuser.sh [ $# -eq 0 ] && { echo "Usage: createuser.sh USERNAME ..." ;exit 1 ; } for user ;do id $user &> /dev/null && echo $user is exist || { useradd $user ; echo $user is created; } done -
案例5:批量创建用户和并设置随机密码
[root@centos8 script]#cat user_for.sh for i in {1..10};do useradd user$i PASS=`cat /dev/urandom | tr -dc '[:alnum:]' |head -c12` echo $PASS | passwd --stdin user$i &> /dev/null echo user$i:$PASS >> /data/user.log echo "user$i is created" done -
案例6:九九乘法表
[root@centos8 script]#cat 9x9_for.sh for i in {1..9};do for j in `seq $i`;do echo -e "${j}x${i}=$[j*i]\t\c" done echo done -
案例7:实现九九乘法表
[root@centos8 ~]#vim 9x9.sh for j in {1..9};do for i in `seq $j`;do echo -e "\E[1;$[RANDOM%7+31]m${i}x${j}=$[i*j]\E[0m\t\c" done echo done echo for((i=1;i<=9;i++));do for((j=1;j<=i;j++));do printf "\E[1;$[RANDOM%7+31]m${i}x${j}=$[i*j]\E[0m\t" done printf "\n" done -
案例8:倒状的九九乘法表
[root@ubuntu1804 ~]#cat 9x9_v2.sh for i in {1..9};do for j in $(seq `echo $[10-$i]`);do echo -ne "${j}x`echo $[10-i]`=$(((10-i)*j))\t" done echo done [root@ubuntu1804 ~]#bash 9x9_v2.sh 1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81 1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64 1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49 1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36 1x5=5 2x5=10 3x5=15 4x5=20 5x5=25 1x4=4 2x4=8 3x4=12 4x4=16 1x3=3 2x3=6 3x3=9 1x2=2 2x2=4 1x1=1 -
案例9::将指定目录下的文件所有文件的后缀改名为 bak 后缀
[root@centos8 ~]#cat /data/scripts/for_rename.sh #!/bin/bash DIR=/data/test cd $DIR || { echo 无法进入 $DIR;exit 1; } for FILE in * ;do PRE=`echo $FILE|grep -Eo ".*\."` mv $FILE ${PRE}bak # PRE=`echo $FILE|rev|cut -d. -f 2-|rev` # PRE=`echo $FILE | sed -nr 's/(.*)\.([^.]+)$/\1/p' # SUFFIX=`echo $FILE | sed -nr 's/(.*)\.([^.]+)$/\2/p'` # mv $FILE $PRE.bak done -
案例9:要求将目录YYYY-MM-DD/中所有文件,移动到YYYY-MM/DD/下
[root@centos8 ~]#cat for_dir.sh #!/bin/bash PDIR=/data/test for i in {1..365};do DIR=`date -d "-$i day" +%F` mkdir -pv $PDIR/$DIR cd $PDIR/$DIR for j in {1..10};do touch $RANDOM.log done done #2.将上面的目录移动到YYYY-MM/DD/下 #!/bin/bash # DIR=/data/test cd $DIR || { echo 无法进入 $DIR;exit 1; } for subdir in * ;do YYYY_MM=`echo $subdir |cut -d"-" -f1,2` DD=`echo $subdir |cut -d"-" -f3` [ -d $YYYY_MM/$DD ] || mkdir -p $YYYY_MM/$DD &> /dev/null mv $subdir/* $YYYY_MM/$DD done rm -rf $DIR/*-*-* -
案例10:扫描一个网段:10.0.0.0/24,判断此网段中主机在线状态,将在线的主机的IP打印出来
[root@centos8 ~]#cat /data/scripts/for_scan_host.sh #!/bin/bash NET=10.0.0 for ID in {1..254};do { ping -c1 -W1 $NET.$ID &> /dev/null && echo $NET.$ID is up| tee -a host_list.log || echo $NET.$ID is down }& done wait -
格式2
双小括号方法,即((…))格式,也可以用于算术运算,双小括号方法也可以使bash Shell实现C语言风格 的变量操作 I=10;((I++)) for ((: for (( exp1; exp2; exp3 )); do COMMANDS; done for ((控制变量初始化;条件判断表达式;控制变量的修正表达式)) do 循环体 done 
-
控制变量初始化:仅在运行到循环代码段时执行一次
-
控制变量的修正表达式:每轮循环结束会先进行控制变量修正运算,而后再做条件判断
-
案例1
[root@ubuntu1804 ~]#cat sum.sh #!/bin/bash for((sum=0,i=1;i<=100;i++));do let sum+=i done echo sum=$sum for((sum=0,i=1;i<=100;sum+=i,i++));do true done echo sum=$sum [root@ubuntu1804 ~]#bash sum.sh sum=5050 sum=5050 -
案例2九九乘法表
#!/bin/bash #语法1实现 for i in {1..9};do for j in `seq $i`;do echo -e "${j}x$i=$((j*i))\t\c" done echo done #语法2实现 for((i=1;i<10;i++));do for((j=1;j<=i;j++));do echo -e "${j}x$i=$((j*i))\t\c" done echo done -
案例3:等腰三角形
[root@centos8 scripts]#cat for_triangle.sh #!/bin/bash read -p "请输入三角形的行数: " line for((i=1;i<=line;i++));do for((k=0;k<=line-i;k++));do echo -e ' \c' done for((j=1;j<=2*i-1;j++));do echo -e '*\c' done echo done [root@centos8 scripts]#bash for_triangle.sh 请输入三角形的行数: 10 * *** ***** ******* ********* *********** ************* *************** ***************** ******************* [root@centos8 scripts]# -
案例4:生成进度
[root@centos8 ~]#for ((i = 0; i <= 100; ++i)); do printf "\e[4D%3d%%" $i;sleep 0.1s; done 100%[root@centos8 ~]# -
案例5:
[root@centos8 ~]#for((;;));do echo for;sleep 1;done for for for for for for for
4. 磁盘和存储管理
4.1. 磁盘类型和结构
4.1.1. 硬盘类型
-
硬盘接口类型
-
IDE:133MB/s,并行接口,早期家用电脑
-
SCSI:640MB/s,并行接口,早期服务器
-
SATA:6Gbps,SATA数据端口与电源端口是分开的,即需要两条线,一条数
据线,一条电源线
-
SAS:6Gbps,SAS是一整条线,数据端口与电源端口是一体化的,SAS中是包含供电线的,而SATA中不包含供电线。SATA标准其实是SAS标准的一个子集,二者可兼容,SATA硬盘可以插入SAS主板上,反之不行
-
USB:480MB/s
-
M.2:
-
-
注意:速度不是由单纯的接口类型决定,支持Nvme协议硬盘速度是最快的
-
服务器硬盘大小
- LFF:3.5寸,一般见到的那种台式机硬盘的大小
- SFF:Small Form Factor 小形状因数,2.5寸,注意不同于2.5寸的笔记本硬盘
-
L、S分别是大、小的意思,目前服务器或者盘柜采用sff规格的硬盘主要是考内虑增大单位密度内的磁盘容量、增强散热、减小功耗
4.1.2. 磁盘结构
-
盘片

-
磁道、扇区:每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区

-
柱面

4.1.2.1. 机械硬盘(HDD)
即是传统普通硬盘,主要由:盘片,磁头,盘片转轴及控制电机,磁头控制器,数据转换器,接口,缓存等几个部分组成。机械硬盘中所有的盘片都装在一个旋转轴上,每张盘片之间是平行的,在每个盘片的存储面上有一个磁头,磁头与盘片之间的距离比头发丝的直径还小,所有的磁头联在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径 方向运动,加上盘片每分钟几千转的高速旋转,磁头就可以定位在盘片的指定位置上进行数据的读写操作。数据通过磁头由电磁流来改变极性方式被电磁流写到磁盘上,也可以通过相反方式读取。硬盘为精密设备,进入硬盘的空气必须过滤
4.1.2.2. 固态硬盘(SSD)
用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单 元(FLASH芯片、DRAM芯片)组成。固态硬盘在接口的规范和定义、功能及使用方法上与普通硬盘的完全相同,在产品外形和尺寸上也与普通硬盘一致 相较于HDD,SSD在防震抗摔、传输速率、功耗、重量、噪音上有明显优势,SSD传输速率性能是HDD的2倍,相较于SSD,HDD在价格、容量占有绝对优势 硬盘有价,数据无价,目前SSD不能完全取代HHD
4.1.2.3. 硬盘存储术语 CHS
- head:磁头 磁头数=盘面数
- track:磁道 磁道=柱面数
- sector:扇区,512bytes
- cylinder:柱面 1柱面=512 * sector数/trackhead数=51263*255=7.84M
CentOS 5 之前版本 Linux 以柱面的整数倍划分分区,CentOS 6之后可以支持以扇区划分分区
4.2. 分区类型MBR和GPT
4.2.1. MBR分区
-
说明MBR:Master Boot Record,1982年,使用32位表示扇区数,分区不超过2
-
T划分分区的单位:
-
CentOS 5 之前按整柱面划分
-
CentOS 6 版本后可以按Sector划分
-
-
0磁道0扇区:512bytes
- 446bytes: boot loader 启动相关
- 64bytes:分区表,其中每16bytes标识一个分区
- 2bytes: 55AA,标识位
-
MBR分区中一块硬盘最多有4个主分区,也可以3主分区+1扩展(N个逻辑分区)
-
MBR分区:主和扩展分区对应的1--4,/dev/sda3,逻辑分区从5开始,/dev/sda5
-
MBR分区结构

4.2.2. GPT分区
-
说明
GPT:GUID(Globals Unique Identifiers) partition table 支持128个分区,使用64位,支持8Z(512Byte/block )64Z ( 4096Byte/block) 使用128位UUID(Universally Unique Identifier) 表示磁盘和分区 GPT分区表自动备份在头和尾两份,并有CRC校验位 UEFI (Unified Extensible Firmware Interface 统一可扩展固件接口)硬件支持GPT,使得操作系统可以 启动 -
GPT分区结构

-
GPT分区结构分为4个区域:
- GPT头
- 分区表
- GPT分区
- 备份区域
4.3. 分区管理和文件系统类型
4.3.1. 分区管理
-
列出块设备
lsblk -
创建分区命令
fdisk 管理MBR分区 gdisk 管理GPT分区 parted 高级分区操作,可以是交互或非交互方式 -
注意:重新设置内存中的内核分区表版本,适合于除了CentOS 6 以外的其它版本 5,7,8
partprobe
4.3.1.1. parted 命令
-
说明
parted的操作都是实时生效的,小心使用 -
格式
parted [选项]... [设备 [命令 [参数]...]...] -
案例1:
parted /dev/sdb mklabel gpt|msdos parted /dev/sdb print parted /dev/sdb mkpart primary 1 200 (默认M) parted /dev/sdb rm 1 parted -l 列出所有硬盘分区信息 -
案例2:
[root@centos8 ~]#parted /dev/sdb print Error: /dev/sdb: unrecognised disk label Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: unknown Disk Flags: [root@centos8 ~]#parted /dev/sdb mklabel gpt Information: You may need to update /etc/fstab. [root@centos8 ~]#parted /dev/sdb print Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags [root@centos8 ~]#parted /dev/sdb mkpart primary 1 1001 Information: You may need to update /etc/fstab. [root@centos8 ~]#parted /dev/sdb print Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 1001MB 1000MB primary [root@centos8 ~]#parted /dev/sdb mkpart primary 1002 1102 Information: You may need to update /etc/fstab. [root@centos8 ~]#parted /dev/sdb print Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 1001MB 1000MB primary 2 1002MB 1102MB 99.6MB primary [root@centos8 ~]#parted /dev/sdb rm 2 Information: You may need to update /etc/fstab. [root@centos8 ~]#parted /dev/sdb print Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 1001MB 1000MB primary [root@centos8 ~]#parted /dev/sdb mklabel msdos Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue? Yes/No? Y Information: You may need to update /etc/fstab. [root@centos8 ~]#parted /dev/sdb print Model: VMware, VMware Virtual S (scsi) Disk /dev/sdb: 21.5GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags [root@centos8 ~]#parted /dev/sdb GNU Parted 3.2 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) help align-check TYPE N check partition N for TYPE(min|opt) alignment help [COMMAND] print general help, or help on COMMAND mklabel,mktable LABEL-TYPE create a new disklabel (partition table) mkpart PART-TYPE [FS-TYPE] START END make a partition name NUMBER NAME name partition NUMBER as NAME print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition quit exit program rescue START END rescue a lost partition near START and END resizepart NUMBER END resize partition NUMBER rm NUMBER delete partition NUMBER select DEVICE choose the device to edit disk_set FLAG STATE change the FLAG on selected device disk_toggle [FLAG] toggle the state of FLAG on selected device set NUMBER FLAG STATE change the FLAG on partition NUMBER toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER unit UNIT set the default unit to UNIT version display the version number and copyright information of GNU Parted (parted)
4.3.1.2. 分区工具fdisk和gdisk
-
格式
fdisk -l [-u] [device...] 查看分区 fdisk [device...] 管理MBR分区 gdisk [device...] 类fdisk 的GPT分区工具 -
选项
p 分区列表 t 更改分区类型 n 创建新分区 d 删除分区 v 校验分区 u 转换单位 w 保存并退出 q 不保存并退出 -
查看内核是否已经识别新的分区
cat /proc/partitions -
CentOS 7,8 同步分区表:
partprobe -
CentOS6 通知内核重新读取硬盘分区表
新增分区用
partx -a /dev/DEVICE kpartx -a /dev/DEVICE -f: force #示例[root@centos6 ~]#partx -a /dev/sda -
删除分区用
partx -d --nr M-N /dev/DEVICE #示例: [root@centos6 ~]#partx -d --nr 6-8 /dev/sda -
案例:非交互式创建分区
echo -e 'n\np\n\n\n+2G\nw\n' | fdisk /dev/sdc -
范例
#增加了6,7分区 [root@centos6 ~]#fdisk /dev/sda Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8) Syncing disks. #分区表不同步 [root@centos6 ~]#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3.7G 0 rom sda 8:0 0 200G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 97.7G 0 part / ├─sda3 8:3 0 48.8G 0 part /data ├─sda4 8:4 0 1K 0 part └─sda5 8:5 0 2G 0 part [SWAP] #同步分区表 [root@centos6 ~]#partx -a /dev/sda BLKPG: Device or resource busy error adding partition 1 BLKPG: Device or resource busy error adding partition 2 BLKPG: Device or resource busy error adding partition 3 BLKPG: Device or resource busy error adding partition 4 BLKPG: Device or resource busy error adding partition 5 [root@centos6 ~]#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3.7G 0 rom sda 8:0 0 200G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 97.7G 0 part / ├─sda3 8:3 0 48.8G 0 part /data ├─sda4 8:4 0 1K 0 part ├─sda5 8:5 0 2G 0 part [SWAP] ├─sda6 8:6 0 2G 0 part └─sda7 8:7 0 3G 0 part #删除了6,7分区 [root@centos6 ~]#fdisk /dev/sda Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8) Syncing disks. [root@centos6 ~]# [root@centos6 ~]#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3.7G 0 rom sda 8:0 0 200G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 97.7G 0 part / ├─sda3 8:3 0 48.8G 0 part /data ├─sda4 8:4 0 1K 0 part ├─sda5 8:5 0 2G 0 part [SWAP] ├─sda6 8:6 0 2G 0 part └─sda7 8:7 0 3G 0 part #同步分区表 [root@centos6 ~]#partx -d --nr 6-7 /dev/sda [root@centos6 ~]#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3.7G 0 rom sda 8:0 0 200G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 97.7G 0 part / ├─sda3 8:3 0 48.8G 0 part /data ├─sda4 8:4 0 1K 0 part └─sda5 8:5 0 2G 0 part [SWAP] -
范例: 批量创建分区
[root@centos8 ~]#echo -e 'n\np\n\n\n+1G\nw' | fdisk /dev/sdb [root@centos8 ~]#fdisk /dev/sdb <<EOF n p +1G w EOF [root@centos8 ~]#lsblk /dev/sdb NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 20G 0 disk ├─sdb1 8:17 0 1G 0 part └─sdb2 8:18 0 1G 0 part
4.3.2. 文件系统类型
-
说明
文件系统是操作系统用于明确存储设备或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件结构称为文件管理系统,简称文件系统。 从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,安全控制,日志,压缩,加密等 -
支持的文件系统:
/lib/modules/`uname -r`/kernel/fs
4.3.2.1. Linux 常用文件系统
- ext2:Extended file system 适用于那些分区容量不是太大,更新也不频繁的情况,例如 /boot 分区
- ext3:是 ext2 的改进版本,其支持日志功能,能够帮助系统从非正常关机导致的异常中恢复
ext4:是 ext 文件系统的最新版。提供了很多新的特性,包括纳秒级时间戳、创建和使用巨型文件(16TB)、最大1EB的文件系统,以及速度的提升 - xfs:SGI,支持最大8EB的文件系统
swap - iso9660 光盘
- btrfs(Oracle)
- reiserfs
4.3.2.2. Windows 常用文件系统
- FAT32
- NTFS
- exFAT
4.3.2.3. Unix:
- FFS(fast)
- UFS(unix)
- JFS2
4.3.2.4. 网络文件系统:
- NFS
- CIFS
4.3.2.5. 集群文件系统:
- GFS2
- OCFS2(oracle)
4.3.2.6. 分布式文件系统:
- fastdfs
- ceph
moosefs - mogilefs
- glusterfs
Lustre
4.3.2.7. RAW:
4.3.2.8. 裸文件系统,未经处理或者未经格式化产生的文件系统
4.3.2.9. 常用的文件系统特性:
-
FAT32
- 最多只能支持16TB的文件系统和4GB的文件
-
NTFS
- 最多只能支持16EB的文件系统和16EB的文件
-
EXT3
- 最多只能支持32TB的文件系统和2TB的文件,实际只能容纳2TB的文件系统和16GB的文件
- Ext3目前只支持32000个子目录
- Ext3文件系统使用32位空间记录块数量和 inode数量
- 当数据写入到Ext3文件系统中时,Ext3的数据块分配器每次只能分配一个4KB的块
-
EXT4:
- EXT4是Linux系统下的日志文件系统,是EXT3文件系统的后继版本
- Ext4的文件系统容量达到1EB,而支持单个文件则达到16TB
- 理论上支持无限数量的子目录
- Ext4文件系统使用64位空间记录块数量
- 和 inode数量
Ext4的多块分配器支持一次调用分配多个数据块 - 修复速度更快
-
XFS
- 根据所记录的日志在很短的时间内迅速恢复磁盘文件内容
- 用优化算法,日志记录对整体文件操作影响非常小
- 是一个全64-bit的文件系统,最大可以支持8EB的文件系统,而支持单个文件则达到8EB
- 能以接近裸设备I/O的性能存储数据
-
查前支持的文件系统:
cat /proc/filesystems
4.4. 创建文件系统和挂载
4.4.1. 创建文件系统
-
mkfs命令:
- (1) mkfs.FS_TYPE /dev/DEVICE
- ext4
- xfs
- btrfs
- vfat
- (2) mkfs -t FS_TYPE /dev/DEVICE
- -L 'LABEL' 设定卷标
- mke2fs:ext系列文件系统专用管理工具
-
常用选项
-t {ext2|ext3|ext4|xfs} 指定文件系统类型 -b {1024|2048|4096} 指定块 block 大小 -L ‘LABEL’ 设置卷标 -j 相当于 -t ext3, mkfs.ext3 = mkfs -t ext3 = mke2fs -j = mke2fs -t ext3 -i # 为数据空间中每多少个字节创建一个inode;不应该小于block大 小 -N # 指定分区中创建多少个inode -I 一个inode记录占用的磁盘空间大小,128---4096 -m # 默认5%,为管理人员预留空间占总空间的百分比 -O FEATURE[,...] 启用指定特性 -O ^FEATURE
4.4.2. 挂载文件系统 mount
-
格式
mount [-fnrsvw] [-t vfstype] [-o options] device mountpoint -
device:指明要挂载的设备
- 设备文件:例如:/dev/sda5
- 卷标:-L 'LABEL', 例如 -L 'MYDATA'
- UUID: -U 'UUID':例如 -U '0c50523c-43f1-45e7-85c0-a126711d406e'
- 伪文件系统名称:proc, sysfs, devtmpfs, configfs
-
mountpoint:挂载点目录必须事先存在,建议使用空目录
-
mount 常用命令选项
-t fstype 指定要挂载的设备上的文件系统类型,如:ext4,xfs -r readonly,只读挂载 -w read and write, 读写挂载,此为默认设置,可省略 -n 不更新/etc/mtab,mount不可见 -a 自动挂载所有支持自动挂载的设备(定义在了/etc/fstab文件中,且挂载选项中有 auto功能) -L 'LABEL' 以卷标指定挂载设备 -U 'UUID' 以UUID指定要挂载的设备 -B, --bind 绑定目录到另一个目录上 -o options:(挂载文件系统的选项),多个选项使用逗号分隔 async 异步模式,内存更改时,写入缓存区buffer,过一段时间再写到磁盘中,效率高,但不安全 sync 同步模式,内存更改时,同时写磁盘,安全,但效率低下 atime/noatime 包含目录和文件 diratime/nodiratime 目录的访问时间戳 auto/noauto 是否支持开机自动挂载,是否支持-a选项 exec/noexec 是否支持将文件系统上运行应用程序 dev/nodev 是否支持在此文件系统上使用设备文件 suid/nosuid 是否支持suid和sgid权限 remount 重新挂载 ro/rw 只读、读写 user/nouser 是否允许普通用户挂载此设备,/etc/fstab使用 acl/noacl 启用此文件系统上的acl功能 loop 使用loop设备 _netdev 当网络可用时才对网络资源进行挂载,如:NFS文件系统 defaults 相当于rw, suid, dev, exec, auto, nouser, async -
挂载规则:
- 一个挂载点同一时间只能挂载一个设备
- 一个挂载点同一时间挂载了多个设备,只能看到最后一个设备的数据,其它设
- 备上的数据将被隐藏
- 一个设备可以同时挂载到多个挂载点
- 通常挂载点一般是已存在空的目录
4.5. 永久挂载和swap管理
4.5.1. 持久挂载
-
说明:将挂载保存到 /etc/fstab 中可以下次开机时,自动启用挂载:
-
格式:
man 5 fstab /etc/fstab -
每行定义一个要挂载的文件系统,,其中包括共 6 项
- 要挂载的设备或伪文件系统
- 设备文件
- LABEL:LABEL=""
- UUID:UUID=""
- 伪文件系统名称:proc, sysfs
- 挂载点:必须是事先存在的目录
- 文件系统类型:ext4,xfs,iso9660,nfs,none
- 挂载选项:defaults ,acl,bind
- 转储频率:0:不做备份 1:每天转储 2:每隔一天转储
- fsck检查的文件系统的顺序:允许的数字是0 1 2
- 0:不自检 ,1:首先自检;一般只有rootfs才用 2:非rootfs使用
- 要挂载的设备或伪文件系统
-
添加新的挂载项,需要执行下面命令生效
mount -a -
案例::centos7, 8 /etc/fstab 的分区UUID错误,无法启动
自动进入emergency mode,输入root 密码 #cat /proc/mounts 可以查看到/ 以rw方式挂载 #vim /etc/fstab #reboot -
案例2:centos 6 /etc/fstab 的分区UUID错误,无法启动
如果/etc/fstab 的挂载设备出错,比如文件系统故障,并且文件系统检测项(即第6项为非0),将导致无 法启动 自动进入emergency mode,输入root 密码 #cat /proc/mounts 可以查看到/ 以ro方式挂载,无法直接修改配置文件 #mount -o remount,rw / #vim /etc/fstab 将故障行的最后1项,即第6项修改为0,开机不检测此项挂载设备的健康性,从而忽略错误,能实现启动 -
案例3:/etc/fstab格式
[root@centos8 ~]#cat /etc/fstab UUID=cb7cae1e-d227-4f64-872b-cd6cce20c911 /data/mysql ext4 noatime 0 0 /disk.img /data/disk xfs loop 0 0 /etc /mnt/etc none bind 0 0 [root@centos6 ~]#cat /etc/fstab /disk.img /mnt/disk ext4 loop 0 0
4.5.2. swap管理
-
swap 介绍
swap交换分区是系统RAM的补充,swap 分区支持虚拟内存。当没有足够的 RAM 保存系统处理的数据 时会将数据写入 swap 分区,当系统缺乏 swap 空间时,内核会因 RAM 内存耗尽而终止进程。配置过多 swap 空间会造成存储设备处于分配状态但闲置,造成浪费,过多 swap 空间还会掩盖内存泄露 注意:为优化性能,可以将swap 分布存放,或高性能磁盘存放 -
Redhat 官方推荐推荐系统 swap 空间
https://access.redhat.com/documentation/zhcn/ red_hat_enterprise_linux/7/html/installation_guide/sect-disk-partitioningsetup- ppc#sect-recommended-partitioning-scheme-ppc 
4.5.2.1. 交换分区实现过程
- 创建交换分区或者文件
- 使用mkswap写入特殊签名
- 在/etc/fstab文件中添加适当的条目
- 使用swapon -a 激活交换空间
-
启用swap分区
swapon [OPTION]... [DEVICE] -
选项
-a #激活所有的交换分区 -p PRIORITY #指定优先级(-1到32767之间),值越大,优先级越高.也可在/etc/fstab文件中的第4列指 定:pri=value -
案例1:创建swap分区
[root@centos8 ~]#echo -e 'n\np\n\n\n+2G\nt\n82\nw\n' | fdisk /dev/sdc [root@centos8 ~]#mkswap /dev/sdc1 Setting up swapspace version 1, size = 2 GiB (2147479552 bytes) no label, UUID=d3140a7a-65b7-4cb7-8a2b-12d38aa98c6f [root@centos8 ~]#blkid /dev/sdc1 /dev/sdc1: UUID="d3140a7a-65b7-4cb7-8a2b-12d38aa98c6f" TYPE="swap" PARTUUID="b094d43d-01 [root@centos8 ~]#vim /etc/fstab UUID=d3140a7a-65b7-4cb7-8a2b-12d38aa98c6f swap swap defaults 0 0 [root@centos8 ~]#swapon -a [root@centos8 ~]#free -h total used free shared buff/cache available Mem: 3.7Gi 264Mi 3.2Gi 9.0Mi 261Mi 3.2Gi Swap: 4.0Gi 0B 4.0Gi [root@centos8 ~]#cat /proc/swaps Filename Type Size Used Priority /dev/sda5 partition 2097148 0 -2 /dev/sdc1 partition 2097148 0 -3 -
禁用swap分区
swapoff [OPTION]... [DEVICE] -
案例2:禁用swap分区
[root@centos8 ~]#sed -i.bak '/swap/d' /etc/fstab [root@centos8 ~]#swapoff -a -
SWAP的优先级
可以指定swap分区0到32767的优先级,值越大优先级越高 如果用户没有指定,那么核心会自动给swap指定一个优先级,这个优先级从-1开始,每加入一个新的 没有用户指定优先级的swap,会给这个优先级减一 先添加的swap的缺省优先级比较高,除非用户自己指定一个优先级,而用户指定的优先级(是正数)永远 高于核心缺省指定的优先级(是负数) -
案例3:修改swap分区的优先级
[root@centos8 ~]#cat /etc/fstab # UUID=acf9bd1f-caae-4e28-87be-e53afec61347 / xfs defaults 0 0 UUID=1770b87e-db5a-445e-bff1-1653ac64b3d6 /boot ext4 defaults 1 2 UUID=ffffd919-d674-44d9-a4e7-402874f0a1f0 /data xfs defaults 0 0 UUID=409e36d2-ac5e-423f-ad78-9b12db4576bd swap swap defaults 0 0 UUID=509ee336-6aec-48b0-b390-12c1f9889520 swap swap pri=100 0 0 -
案例4:以文件实现swap功能
[root@centos8 ~]#dd if=/dev/zero of=/swapfile bs=1M count=1024 [root@centos8 ~]#mkswap /swapfile [root@centos8 ~]#blkid /swapfile >> /etc/fstab [root@centos8 ~]#/etc/fstab /swapfile swap swap defaults 0 0 #不要用 UUID,使用文件的路径 [root@centos8 ~]#chmod 600 /swapfile [root@centos8 ~]#swapon -a [root@centos8 ~]#swapon -s Filename Type Size Used Priority /dev/sda5 partition 2097148 0 -2 /swapfile file 1048572 0 -3
4.5.2.2. swap的使用策略
-
说明:/proc/sys/vm/swappiness 的值决定了当内存占用达到一定的百分比时,会启用swap分区的空间
-
使用规则
当内存使用率达到100-swappiness时,会启用交换分区 简单地说这个参数定义了系统对swap的使用倾向,此值越大表示越倾向于使用swap。 可以设为0,这样做并不会禁止对swap的使用,只是最大限度地降低了使用swap的可能性 -
案例
#说明:CentOS7和8默认值为30,内存在使用到100-30=70%的时候,就开始出现有交换分区的使用。 [root@centos8 ~]# cat /proc/sys/vm/swappiness 30 [root@centos7 ~]# cat /proc/sys/vm/swappiness 30 [root@centos6 ~]# cat /proc/sys/vm/swappiness 60 [root@rhel5 ~]# cat /proc/sys/vm/swappiness 60 root@ubuntu2004:~# cat /proc/sys/vm/swappiness 60 [root@ubuntu1804 ~]# cat /proc/sys/vm/swappiness 60
4.6. RAID磁盘冗余技术各种级别和实现
4.6.1. 什么是RAID
-
"RAID"一词是由David Patterson, Garth A. Gibson, Randy Katz 于1987年在加州大学伯克利分校发明的.当时性能最好的大型机不断增长的个人电脑市场开发的一系列廉价驱动器的性能所击败。尽管故障与驱动器数量的比例会上升,但通过配置冗余,阵列的可靠性可能远远超过任何大型单个驱动器的可靠性。
-
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),简称磁盘阵列。利用虚拟化存储技术把多个硬盘组合起来,成为一个或多个硬盘阵列组,目的为提升性能或数据冗余,或是两者同时提升.
-
RAID 层级不同,数据会以多种模式分散于各个硬盘,RAID 层级的命名会以 RAID 开头并带数字,例如:RAID 0、RAID 1、RAID 5、RAID 6、RAID 7、RAID 01、RAID 10、RAID 50、RAID 60。每种等级都有其理论上的优缺点,不同的等级在两个目标间获取平衡,分别是增加数据可靠性以及增加存储器(群)读写性能。
-
RAID功能实现
- 提高IO能力,磁盘并行读写
- 提高耐用性,磁盘冗余算法来实现
-
RAID实现的方式
- 外接式磁盘阵列:通过扩展卡提供适配能力
- 内接式RAID:主板集成RAID控制器,安装OS前在BIOS里配置
- 软件RAID:通过OS实现,比如:群晖的NAS
4.6.2. RAID级别
-
说明
RAID-0:条带卷,strip RAID-1:镜像卷,mirror RAID-2 ...... RAID-5 RAID-6 RAID-7 RAID-10 RAID-01 RAID-50
4.6.2.1. RAID-0
-
说明
以 chunk 单位,读写数据,因为读写时都可以并行处理,所以在所有的级别中,RAID 0的速度是最快的。但是RAID 0既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失读、写性能提升可用空间:N*min(S1,S2,...)无容错能力最少磁盘数:1+ -
结构

RAID-1
-
说明
也称为镜像, 两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与RAID 0相同。另外写入速度有微小的降低。读性能提升、写性能略有下降可用空间:1*min(S1,S2,...)、磁盘利用率、50%有冗余能力、最少磁盘数:2+ -
结构

4.6.2.2. RAID-4
-
说明
多块数据盘异或运算值存于专用校验盘 磁盘利用率 (N-1)/N 有冗余能力 至少3块硬盘才可以实现 -
结构

4.6.2.3. RAID-5
-
说明
读、写性能提升 可用空间:(N-1)*min(S1,S2,...) 有容错能力:允许最多1块磁盘损坏 最少磁盘数:3, 3+ -
结构

4.6.2.4. RAID-6
-
说明
双份校验位,算法更复杂 读、写性能提升 可用空间:(N-2)*min(S1,S2,...) 有容错能力:允许最多2块磁盘损坏 最少磁盘数:4, 4+ -
结构

4.6.2.5. RAID-10
-
说明
读、写性能提升 可用空间:N*min(S1,S2,...)/2 有容错能力:每组镜像最多只能坏一块 最少磁盘数:4, 4+ -
结构

4.6.2.6. RAID-01
-
说明
多块磁盘先实现RAID0,再组合成RAID1 -
结构

4.6.2.7. RAID-50
-
说明
多块磁盘先实现RAID5,再组合成RAID0 -
结构

4.6.2.8. RAID-60
-
结构

4.6.3. RAID 总结
-
常用级别:RAID-0, RAID-1, RAID-5, RAID-10, RAID-50,RAID-60

-
磁盘阵列比较表

4.7. 逻辑卷快照管理
4.7.1. 逻辑卷快照原理
-
说明
快照是特殊的逻辑卷,它是在生成快照时存在的逻辑卷的准确拷贝,对于需要备份或者复制的现有数据临时拷贝以及其它操作来说,快照是最合适的选择,快照只有在它们和原来的逻辑卷不同时才会消耗空间,建立快照的卷大小小于等于原始逻辑卷,也可以使用lvextend扩展快照 逻辑卷管理器快照 快照就是将当时的系统信息记录下来,就好像照相一般,若将来有任何数据改动了,则原始数据会被移动到快照区,没有改动的区域则由快照区和文件系统共享 -
逻辑卷快照工作原理
- 在生成快照时会分配给它一定的空间,但只有在原来的逻辑卷或者快照有所改变才会使用这些空间
- 当原来的逻辑卷中有所改变时,会将旧的数据复制到快照中
- 快照中只含有原来的逻辑卷中更改的数据或者自生成快照后的快照中更改的数据
-
快照特点
- 备份速度快,瞬间完
- 应用场景是测试环境,不能完成代替备份
- 快照后,逻辑卷的修改速度会一定有影响
4.7.2. 实现逻辑卷快照
-
范例:
mkfs.xfs /dev/vg0/data mount /dev/vg0/data/ /mnt/data #为现有逻辑卷创建快照,注意ext4建议使用-p r 实现只读 lvcreate -l 64 -s -n data-snapshot /dev/vg0/data #挂载快照,xfs注意要使用-o ro实现只读,防止快照被修改 mkdir -p /mnt/snap mount -o ro,nouuid /dev/vg0/data-snapshot /mnt/snap #恢复快照 umount /dev/vg0/data-snapshot umount /dev/vg0/data lvconvert --merge /dev/vg0/data-snapshot #删除快照 umount /mnt/snap lvremove /dev/vg0/data-snapshot
本文作者:zxl1024320609
本文链接:https://www.cnblogs.com/zxl1024320609/p/16564233.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步