深度学习-目标检测(Fast R-CNN)
在SPPNet中,特征提取和区域分类是分开的,只是使用了ROI池化层进行了特征的提取,对于区域分类,仍然采用了传统的SVM分类器,Fast R-CNN相比于SPPNet,采用神经网络进行分类,这样可以同时训练 特征提取网络和分类网络,从而取得比SPPNet更高的准确度。Fast R-CNN的网络结构如下图所示:

对于原始图像的候选区域,和SPPNet一样,都是将候选框映射到卷积特征的对应区域,然后用ROI池化层对该区域提取特征,然后Fast R-CNN直接使用全连接层,全连接层有两个输出:一个负责分类,一个负责框回归。
分类最终输出K+1个数,其中K个分类目标,1个背景
框回归是对Selective Search 得到的候选框进行某种程度上的校准,Selective Search得到的候选框有四个参数(x,y,w,h),x、y表示候选框左上角的坐标,w、h表示候选框的宽高,框回归的参数(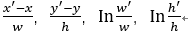 ),(
),(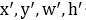 )表示真正的框位置,
)表示真正的框位置,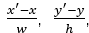 表示与尺度无关的平移量,
表示与尺度无关的平移量,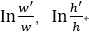 表示与尺度无关的缩放量。
表示与尺度无关的缩放量。
Fast R-CNN的主要步骤如下:
1)特征提取:以整张图片为输入利用CNN得到图片的特征层;
2)区域提名:通过Selective Search方法从原始图片提取区域候选框,并把这些候选框一 一投影到最后的特征层;
3)区域特征提取:针对特征图上的每个区域候选框进行RoI池化操作,得到固定大小的特征表示;
4)分类与回归:然后再通过两个全连接层,分别用softmax多分类做目标识别,用回归模型进行边框位置与大小微调。、
优点:相比于SPPNet,使用同一个神经网络进行特征提取、分类、框回归。

