深度学习-目标检测(SPPNet)
SPPNet(Spatial Pyramid Pooling Convolutional),译文:空间金字塔池化神经网络。之前R-CNN中任意大小的候选框需要转换成统一大小才能将其作为输入传到AlexNet中,而SPPNet主要任务是:将卷积神经网络的输入转化为任意尺寸,实现机制是在卷积神经网络中加载了ROI (Region of interest)池化层。
在先讲SPPNet之前,首先讲一下ROI池化,ROI池化的作用是:克服R-CNN的缺点,使得输入的图像大小任意的,而输出保持不变,为什么ROI池化可以做到这一点,这里不妨设输入图像的宽度为w,高度为h,通道数为c,不管输入尺寸为多少,通道数c为常值,而w,h会随输入图像尺寸的改变而改变。ROI池化步骤如下:
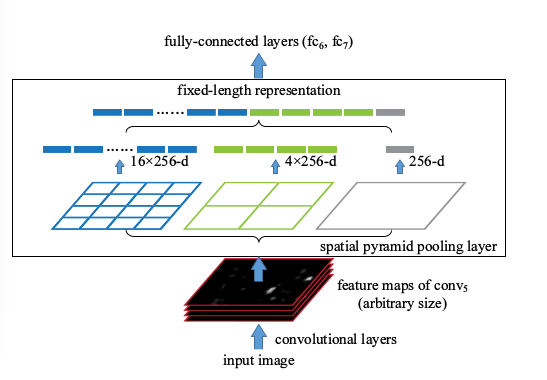
1)首先,把卷积后特征图划分为4x4的网格,每个网格的宽是W / 4、高是 h / 4、通道是c。当不能整除时,取整。然后对每个网格施加最大池化(max pooling),取每个网格的最大值,最终4x4的网格会输出16c的特征。
2)同理,把特征图划分为2x2的网格,每个网格的宽是W / 2、高是 h / 2、通道是c。当不能整除时,取整。然后对每个网格施加最大池化(max pooling),
取每个网格的最大值,最终2x2的网格会输出4c的特征。
3)最后,把特征图划分为1x1的网格,相当于对输入特征图施加最大池化(max pooling),取每个网格的最大值,最终会输出c的特征。
4)将1)2)3)中的输出特征拼接,会得到一个21c维的特征, 很显然,最后的输出与输入图像的尺寸并无关系,但输出可以得到固定维数的特征。过程见下图:
那么,如何将ROI池化用于目标检测呢?原始的输入图像,经过若干层卷积层后得到特征图,这样特征图实际上和原始图像有一定的对应关系,也就是说,原始图像中候选框,也可以对应于卷积后特征图的相应位置。利用ROI池化层可以把卷积特征中不同形状的区域对应到相同大小的特征向量中。综上所述,将原始图像中的不同大小的区域都对应于ROI池化层后的固定长度的特征,这就完成了各个区域的特征提取工作,过程图如下:

SPPNet做目标检测的主要步骤:
1)区域提名:用Selective Search从原图中生成2000个左右的候选窗口;
2)卷积操作:将输入图像进行卷积操作,得到整个图像的卷积特征,;
3)特征提取:对于原始图像的各种候选框,需要在卷积特征中找到对应的位置框,SPP-net不再做区域大小归一化,而是使用ROI池化层对位置框中的卷积提取特征;
4)分类与回归:类似R-CNN,利用SVM基于上面的特征训练分类器模型,用边框回归来微调候选框的位置。
优点:相比于R-CNN,R-CNN需要对每个区域计算卷积,而SPPNet只需要一次,也不需要再做区域大小归一化,使用ROI池化层对位置框中的卷积提取特征


