后缀数组
基本概念
给你一个字符串
直接找出所有后缀,排序。
我们需要用到倍增来实现。例如这样:
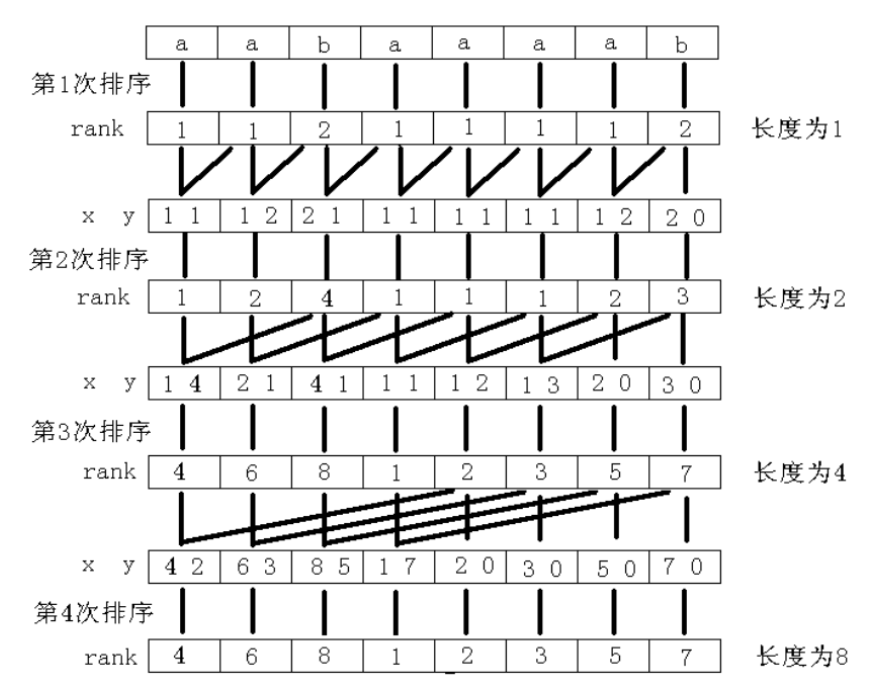
这个的思想大概是这样的:先用
然后开始倍增。每次使用长度为
于是就做完了,给个代码:
void get_sa(){
for(int i=1;i<=n;i++){
sa[i]=i;
x[i]=s[i];
}
for(int k=1;k<n;k<<=1){
sort(sa+1,sa+n+1,[&](int a,int b){
return x[a]==x[b]?x[a+k]<x[b+k]:x[a]<x[b];
});
memcpy(y,x,sizeof x);
int num=0;
for(int i=1;i<=n;i++){
x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
}
}
}
这个代码已经可以通过部分平台的测试数据,但是为了保险,我们需要继续优化。
我们思考为什么会有两个
我们考虑先做第一步,按照单个字符排序,这个是比较简单的,大概就是开个桶记录一下每个字符的数量,然后做个前缀和,最后倒着扫一遍得到
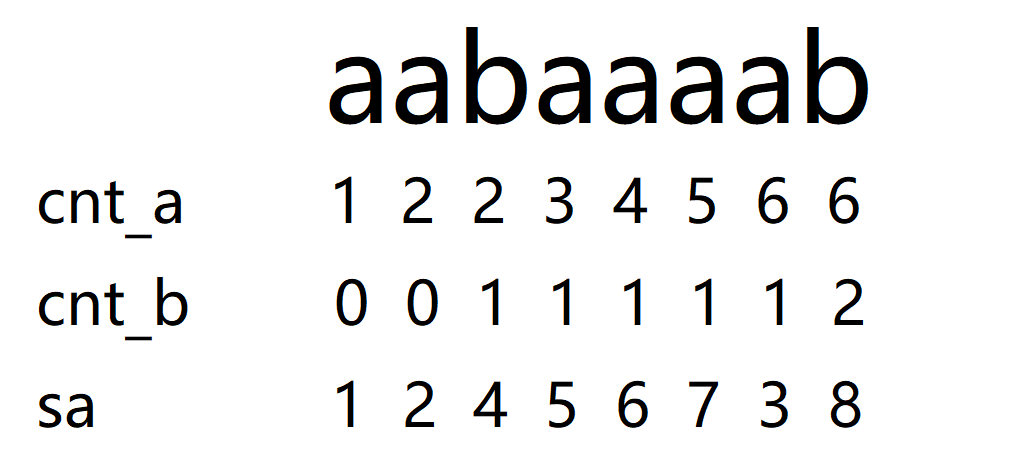
代码:
for(int i=1;i<=n;i++)c[x[i]=s[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[i]]--]=i;
为什么这样是对的。我们考虑做过前缀和的
然后我们开始倍增,考虑如何对第二关键字进行排序。因为我们会把第二关键字越界的位置的第二关键字设为
所以我们在对第二关键字排序时,把这些为
然后剩下的位置就按照原来的
代码:
int num=0;
for(int i=n-k+1;i<=n;i++)y[++num]=i;
for(int i=1;i<=n;i++){
if(sa[i]>k){
y[++num]=sa[i]-k;
}
}
这里我们
然后我们重复一下一开始统计长度为
代码:
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[y[i]]]--]=y[i],y[i]=0;
这里解释一下数组含义:
这里倒着循环的是为了在第一关键字相同的情况下保持第二关键字的原始顺序。
然后我们的
接着把
最后就是如果已经区分出来排名了,就没有必要继续循环了。
代码:
swap(x,y);
x[sa[1]]=num=1;
for(int i=2;i<=n;i++){
x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
}
if(num==n)break;
m=num;
完整代码:
void get_sa(){
for(int i=1;i<=n;i++)c[x[i]=s[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[i]]--]=i;
//其实这里的x_i可以看成x_{y_i},y_i这里就是i
for(int k=1;k<=n;k<<=1){
int num=0;
for(int i=n-k+1;i<=n;i++)y[++num]=i;
for(int i=1;i<=n;i++){
if(sa[i]>k){
y[++num]=sa[i]-k;
}
}
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y);
x[sa[1]]=num=1;
for(int i=2;i<=n;i++){
x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
}
if(num==n)break;
m=num;
}
}
但是,很多题只有
为了求出这个长度,我们还需要一个
注意这里有个结论,
然后就是循环求
void get_hei(){
int k=0;
for(int i=1;i<=n;i++)rk[sa[i]]=i;
for(int i=1;i<=n;i++){
if(rk[i]==1)continue;
if(k)k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k])k++;
hei[rk[i]]=k;
}
}
这个
题目
后缀排序
板子题,直接看上面的东西即可。
字符加密
我们首先把字符串复制一份接到原来的字符串后面。
然后我们直接对其求一个
这里说一下为什么复制一遍是对的。因为考虑如果说在前
代码:
#include<bits/stdc++.h>
#define int long long
#define N 200005
using namespace std;
char s[N];
int n,m,x[N],y[N],c[N],sa[N];
void get_sa(){
for(int i=1;i<=n;i++)c[x[i]=s[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1){
int num=0;
for(int i=n-k+1;i<=n;i++)y[++num]=i;
for(int i=1;i<=n;i++){
if(sa[i]>k){
y[++num]=sa[i]-k;
}
}
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y);
x[sa[1]]=num=1;
for(int i=2;i<=n;i++){
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+k]==y[sa[i]+k])?num:++num;
}
if(num==n)break;
m=num;
}
}
signed main(){
cin>>s+1;
n=strlen(s+1);
for(int i=n+1;i<=n<<1;i++){
s[i]=s[i-n];
}
n<<=1;
m='z';
get_sa();
for(int i=1;i<=n;i++){
if(sa[i]<=n>>1)cout<<s[sa[i]+(n>>1)-1];
}
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】