


第六次作业
作业1
1)、实验内容:
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
输出信息:
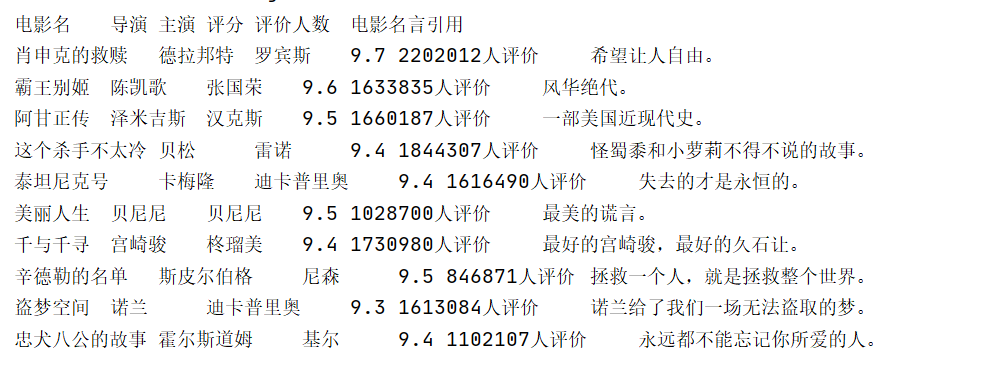
| 排名 | 电影名称 | 导演 | 主演 | 上映时间 | 国家 | 电影类型 | 评分 | 评价人数 | 引用 | 文件路径 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 1994 | 美国 | 犯罪 剧情 | 9.7 | 2192734 | 希望让人自由。 | 肖申克的救赎.jpg |
| 2...... |
照片和电影信息我是分开爬取的
电影信息代码如下:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import re
start_url="https://movie.douban.com/top250"
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
names =[]
req = urllib.request.Request(start_url ,headers=headers)
data =urllib.request.urlopen(req)
data =data.read()
dammit =UnicodeDammit(data ,["utf-8" ,"gbk"])
data =dammit.unicode_markup
soup =BeautifulSoup(data ,"lxml")
images =soup.select("img")
a_s = soup.select("a[class='']")
count =0
names=[]
info=[]
score=[]
population=[]
for a in a_s:
try:
name = a.select('span')[0].text
names.append(name)
except Exception as err:
print(err)
p_s = soup.select("div[class='bd']")
for p in p_s:
try:
da = p.select("p[class='']")[0].text
info.append(da)
except Exception as err:
print(err)
stars = soup.select("div[class='star']")
for s in stars:
try:
da = s.select("span")[1].text
score.append(da)
das=s.select("span")[3].text
population.append(das)
except Exception as err:
print(err)
quotess = []
quotes = soup.select("p[class='quote']")
for s in quotes:
try:
quote = s.select("span[class='inq']")[0].text
quotess.append(quote)
except Exception as err:
print(err)
director=[]
main_actor=[]
print("电影名"+ "\t" +"导演"+ "\t" +"主演"+ "\t" +"评分"+ "\t" +"评价人数"+ "\t"+"电影名言引用"+ "\t")
for i in range(10):
string = info[i]
pat = '[\u4e00-\u9fa5]+\s'
string1 = re.compile(pat).findall(string)
director=string1[0]
main_actor=string1[1]
#print(string1[0])
print(names[i]+"\t"+director+"\t"+main_actor+"\t"+score[i]+"\t"+population[i]+"\t"+quotess[i]+"\t")
实验结果:
爬取图片的代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req = urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
infos=soup.find_all("")
for image in images:
try:
src=image["src"]
info=image["alt"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
print(url)
#count=count+1
#infos=soup.select()
T=threading.Thread(target=download,args=(url,info))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,info):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open(r"豆瓣/"+str(info)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(info)+ext)
except Exception as err:
print(err)
start_url="https://movie.douban.com/top250"
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
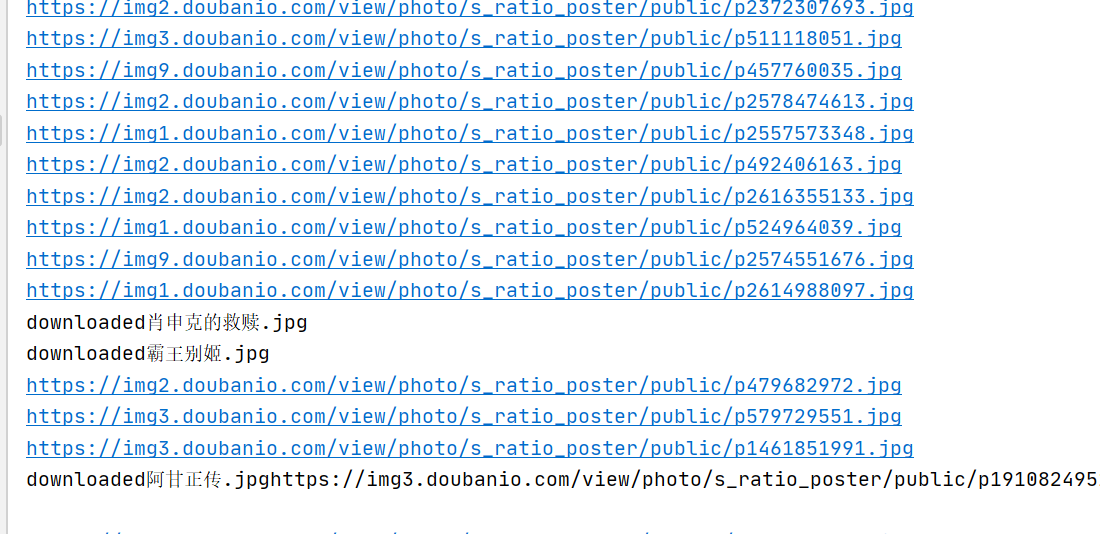
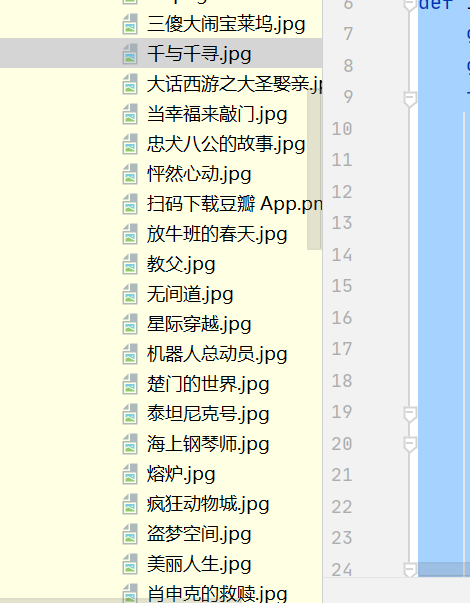
实验结果:
2)、心得体会
这一题我觉得最难的部分是正则,可能因为我正则学的最不好。。。在怎么用正则提取出相关信息的时候花了很久的时间,所以正则这部分还是要再好好多看一点。
作业2
1)、实验内容:
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下

代码如下:
MySpider:
import scrapy
from ..items import FourthItem
from bs4 import UnicodeDammit
import requests
from bs4 import BeautifulSoup
import re,os
import threading
import pymysql
import urllib
class mySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
source_url = "https://www.shanghairanking.cn/rankings/bcur/2020"
def start_requests(self):
url = mySpider.source_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
i=1
lis=selector.xpath("//tbody[@data-v-2a8fd7e4='']/tr")
for li in lis:
rank = li.xpath("./td[position()=1]/text()").extract_first().replace("\n", "").replace(" ", "")
print(rank)
name=li.xpath("./td[position()=2]/a").extract_first()
print(name)
place = li.xpath("./td[position()=3]/text()").extract_first().replace(" ", "").replace("\n", "")
print(place)
next_url = "https://www.shanghairanking.cn/" + li.xpath("./td[position()=2]/a/@href").extract_first()
print(next_url)
#yield Request(url, meta={'item': item}, callback=self.parse_detail)
html = requests.get(url=next_url)
dammit = UnicodeDammit(html.content, ['utf-8', 'gbk'])
newdata = dammit.unicode_markup
soup = BeautifulSoup(newdata, 'lxml')
url = soup.select("div[class='univ-website'] a")[0].text
# print(url)
mFileq = soup.select("td[class='univ-logo'] img")[0]["src"]
File = str(rank) + '.jpg'
logodata = requests.get(url=mFileq).content
path = r'E:\python\logo'
if not os.path.exists(path):
os.mkdir(path)
file_path = path + '/' + File
with open(file_path, 'wb') as fp:
fp.write(logodata)
fp.close()
print(File)
brief = soup.select("div[class='univ-introduce']p")
if brief!="":
brief = soup.select("div[class='univ-introduce']p")[0].text
print(brief)
# print(brief)
item=FourthItem()
item["rank"] = rank.strip() if rank else ""
item["name"]=name.strip()if name else""
item["place"] = place.strip() if place else ""
item["officalUrl"] = url.strip() if url else ""
item["info"] = brief.strip() if brief else ""
item["mFile"] = File.strip() if File else ""
yield item
except Exception as err:
print(err)
pipeline:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
import urllib
class FourthPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table if exists ruanke")
sql = """create table ruanke(
sNo varchar(32) primary key,
schoolName varchar(32),
city varchar(32),
officalUrl varchar(64),
info text,
mFile varchar(32)
)character set = utf8
"""
self.cursor.execute(sql)
except Exception as err:
print(err)
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def process_item(self, item, spider):
print(item['rank'], item['name'], item['place'], item['officalUrl'], item['info'], item['mFile'])
if self.open:
try:
self.cursor.execute(
"insert into ruanke(sNo,schoolName,city,officalUrl,info,mFile) values(%s,%s,%s,%s,%s,%s)", \
(item['rank'], item['name'], item['place'], item['officalUrl'], item['info'], item['mFile']))
self.count += 1
print("数据插入成功")
except Exception as err:
print(err)
else:
print("数据库未连接")
return item
def close_spider(self, spider):
if self.open:
self.con.commit()
self.con.close()
self.open = False
print('closed')
print(self.count)
items:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class FourthItem(scrapy.Item):
rank = scrapy.Field()
name=scrapy.Field()
place = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
实验结果:

2)、心得体会
这一题因为爬取到广西大学的时候总是会报错,怎么改都不行,所以没有数据库的截图,因为数据库没有正常存进去。。。。。后面一定会把它仔细弄清楚,再把这个bug改过来。。。
作业3
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
-
候选网站: 中国mooc网:https://www.icourse163.org
-
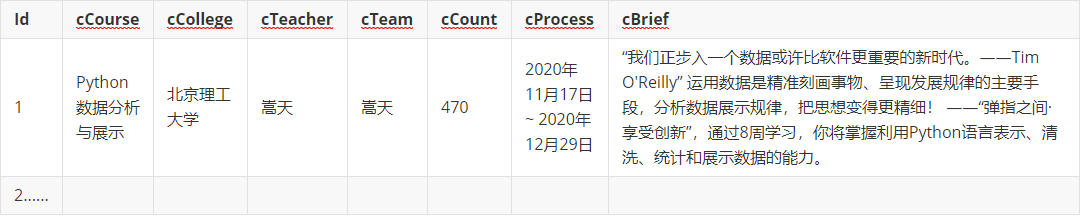
输出信息:MYSQL数据库存储和输出格式如下
代码如下:
import pymysql
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
import time
from selenium.webdriver.common.by import By
import datetime
from selenium.webdriver.common.keys import Keys
class MySpider:
def startup(self, url):
# 初始化谷歌浏览器
chrome_options = Options()
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.count=0
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table mooc")
except:
pass
try:
# 建立新的表
sql_1 = "create table mooc (Id varchar(2048) , cCourse varchar(2048), cCollege varchar(2048), cTeacher varchar(2048), cTeam varchar(2048), cProcess varchar(2048), cBrief text)"
self.cursor.execute(sql_1)
except:
pass
except Exception as err:
print(err)
self.driver.get(url)
#key="时尚"
#input = self.driver.find_element_by_xpath("//div[@class='web-nav-right-part']//div[@class='u-baseinputui']//input")
#input.send_keys(key) # 输入关键字
#input.send_keys(Keys.ENTER)
try:
self.driver.maximize_window()
l1 = self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']")
l1.click()
time.sleep(1)
l2 = self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']")
l2.click()
time.sleep(1)
l3 = self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1]
l3.click()
time.sleep(1)
iframe= self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe)
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('13855107116')
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('zxh108703')
time.sleep(1)
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(5)
self.driver.find_element_by_xpath("//div[@class='privacy-info-container']/a[@class='close']").click()
#self.driver.get(self.driver.current_url)
time.sleep(3)
key="时尚"
input = self.driver.find_element_by_xpath("//div[@class='web-nav-right-part']//div[@class='u-baseinputui']//input")
input.send_keys(key) # 输入关键字
input.send_keys(Keys.ENTER)
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='u-search-icon']/span[@class='u-icon-search2 j-searchBtn']").click()
self.driver.get(self.driver.current_url)
except Exception as err:
print(err)
def closeup(self):
try:
# 关闭数据库、断开与谷歌浏览器连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertdb(self,id, course, college, Teacher, Team, Process, Brief):
try:
sql = "insert into mooc (Id, cCourse, cCollege, cTeacher, cTeam, cProcess, cBrief) values (%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (id, course, college, Teacher, Team,Process, Brief))
print("成功插入")
except Exception as err:
print("插入失败")
print(err)
def processspider(self):
try:
search_handle = self.driver.current_window_handle
i=5
#判断当前有无元素Located
WebDriverWait(self.driver, 1000).until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='m-course-list']/div/div[@class]")))
spans = self.driver.find_elements_by_xpath("//div[@class='m-course-list']/div/div[@class]")
while i>=5:
for span in spans:
self.count=self.count+1
course = span.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']/a/span").text
college = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']/a[@class='t21 f-fc9']").text
teacher = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']/a[@class='f-fc9']").text
team = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0 margin-top0']/span[@class='hot']").text
process = span.find_element_by_xpath(".//span[@class='txt']").text
brief = span.find_element_by_xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']").text
print(self.count,course,college,teacher,team,process,brief) # 爬取之后输出到控制台
self.insertdb(self.count,course,college,teacher,team,process,brief)
i=i-1
except Exception as err:
print(err)
def executespider(self,url,key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startup(url)
print("Spider processing......")
print(1)
print()
self.processspider()
print("Spider closing......")
self.closeup()
print("Spider completed......")
endtime = datetime.datetime.now() # 计算爬虫耗时
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executespider(url,key="时尚")
continue
elif s == "2":
break
实验结果:

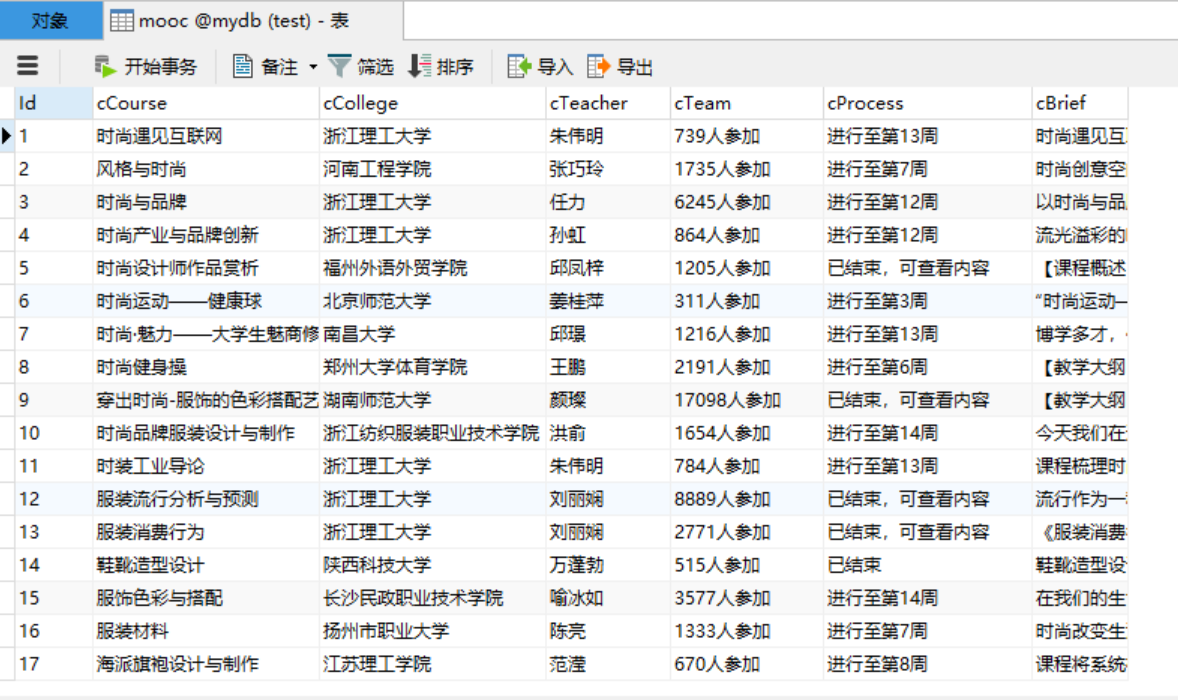
2)、心得体会
Selenium我觉得是最有意思的爬虫工具了,因为可以程序控制浏览器做你想让它做的操作,这一题并没有很难,但是我很喜欢这个工具。
