


第四次作业
作业4
1)、实验内容:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
这个代码在书上有,我们只是做了一个复现。
代码如下:
MySpider:
import scrapy
from bs4 import BeautifulSoup
from sql.items import BookItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
source_url = "http://search.dangdang.com/"
def start_requests(self):
url = MySpider.source_url+"?key="+MySpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis=selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
price=li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author=li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date=li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher=li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item=BookItem()
item["title"]=title.strip()if title else""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
#连续爬取不同的网页
#将网址提取出,用response.urljoin整理成新的url,即可连续爬取不同的page,再次产生一个request请求,而回调函数仍是parse。当爬取到最后一页是,下一页的链接为空,link=None,则不再调用
link=selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url=response.urljoin(link)
yield scrapy.Request(url=url,callback=self.parse)
except Exception as err:
print(err)
pipelines:
from itemadapter import ItemAdapter
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
except Exception as err:
print(err)
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count+=1
except Exception as err:
print(err)
return item
items:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pass
settings:
BOT_NAME = 'sql'
SPIDER_MODULES = ['sql.spiders']
NEWSPIDER_MODULE = 'sql.spiders'
ITEM_PIPELINES={
'sql.pipelines.BookPipeline':300,
}
实验结果:
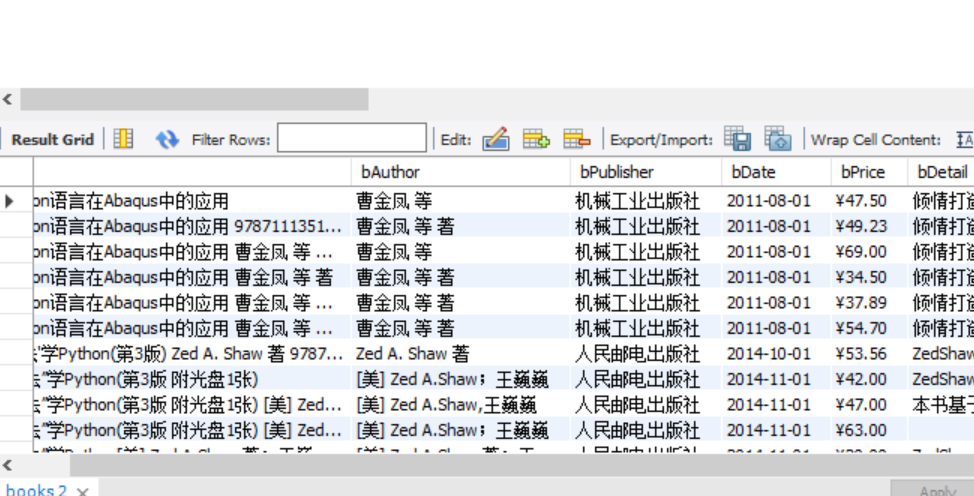
2)、心得体会
这次实验是书上原封不动的实验的复现,通过这个复现,我了解到了如何将scrapy爬取到的内容输入到数据库中的内容,收获很大。
作业2
1)、实验内容:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
scrapy各部分框架代码如下:
MySpider代码:
import scrapy
import json
from ..items import StockItem
class stockSpider(scrapy.Spider):
name = 'stock'
start_urls = ['http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240918880626239239_1602070531441&pn=1&pz=20&po=1&np=3&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602070531442']
#start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
# 调用body_as_unicode()是为了能处理unicode编码的数据
jsons = response.text[41:][:-2] # 将前后用不着的字符排除
text_json = json.loads(jsons)
for f in text_json['data']['diff']:
item = StockItem()
item["f12"] = f['f12']
item["f14"] = f['f14']
item["f2"] = f['f2']
item["f3"] = f['f3']
item["f4"] = f['f4']
item["f5"] = f['f5']
item["f6"] = f['f6']
item["f7"] = f['f7']
yield item
print("ok")
items的代码:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class StockItem(scrapy.Item):
f12 = scrapy.Field()
f14 = scrapy.Field()
f2 = scrapy.Field()
f3 = scrapy.Field()
f4 = scrapy.Field()
f5 = scrapy.Field()
f6 = scrapy.Field()
f7 = scrapy.Field()
pass
pipelines的代码:
from itemadapter import ItemAdapter
import pymysql
class stockPipeline(object):
print("序号\t", "代码\t", "名称\t", "最新价(元)\t ", "涨跌幅 (%)\t", "跌涨额(元)\t", "成交量\t", "成交额(元)\t", "涨幅(%)\t")
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened=True
self.count=0
except Exception as err:
print(err)
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"支股票")
def process_item(self, item, spider):
try:
if self.opened:
self.count += 1
self.cursor.execute("insert into stocks(序号,股票代码,股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,涨幅)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)",(str(self.count),item['f12'],item['f14'],str(item['f2']),str(item['f3']),str(item['f4']), str(item['f5']),str(item['f6']), str(item['f7'])))
print(str(self.count) + "\t", item['f12'] + "\t", item['f14'] + "\t", str(item['f2']) + "\t",
str(item['f3']) + "%\t", str(item['f4']) + "\t", str(item['f5']) + "\t", str(item['f6']) + "\t",
str(item['f7']) + "%")
except Exception as err:
print(err)
return item
settings的代码:
BOT_NAME = 'stock'
SPIDER_MODULES = ['stock.spiders']
NEWSPIDER_MODULE = 'stock.spiders'
ITEM_PIPELINES = {
'stock.pipelines.stockPipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'stock (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
实验结果:
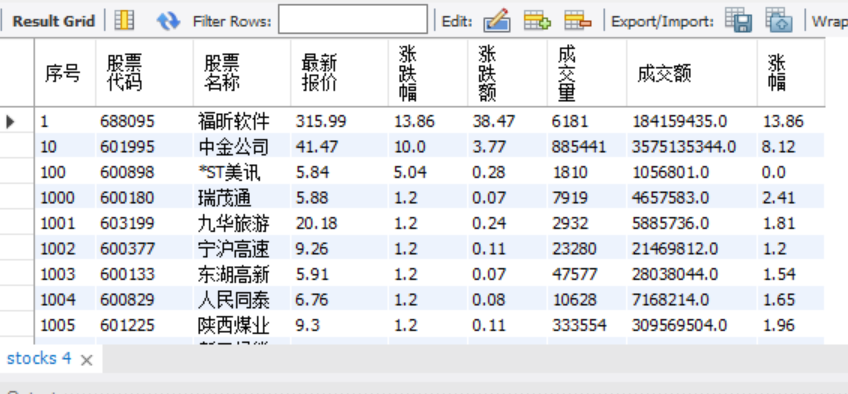
2)、心得体会
这个代码就是将上次的爬取股票的代码中最后结果的部分传到数据库中,只要学会了作业一中的方法,这题就很简单。
作业3
1)、实验内容:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
各部分代码如下:
MySpider代码:
import scrapy
from bs4 import BeautifulSoup
from cash.items import CashItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
source_url = "http://fx.cmbchina.com/hq/"
def start_requests(self):
url = MySpider.source_url
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
trs=selector.xpath("//div[@class='contentshow fontsmall']/div[@id='realRateInfo']/table[@class='data']/tbody/tr")
for tr in trs:
Currency=tr.xpath("./td[position()=1][@class='fontbold']/text()").extract_first()
Currency=str(Currency)
TSP=tr.xpath("./td[position()=4][@class='numberright']/text()").extract_first()
CSP=tr.xpath("./td[position()=5][@class='numberright']/text()").extract_first()
TBP=tr.xpath("./td[position()=6][@class='numberright']/text()").extract_first()
CBP =tr.xpath("./td[position()=7][@class='numberright']/text()").extract_first()
shijian=tr.xpath("./td[position()=8][@align='center']/text()").extract_first()
item=CashItem()
item["Currency"]=Currency.strip()if Currency else""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["shijian"] = shijian.strip() if shijian else ""
yield item
except Exception as err:
print(err)
items的代码:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CashItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
shijian =scrapy.Field()
pass
pipelines的代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class CashPipeline:
print("一\t", "二\t", "三\t", "四\t ", "五\t", "六\t", "七\t")
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from cash")
self.opened = True
self.count = -1
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "个")
def process_item(self, item, spider):
try:
if self.opened:
self.count += 1
self.cursor.execute(
"insert into cash(id,Currency,TSP,CSP,TBP,CBP,shijian)values(%s,%s,%s,%s,%s,%s,%s)",
(str(self.count), item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"],item["shijian"]))
print(str(self.count) + "\t", item["Currency"] + "\t", item["TSP"] + "\t", item["CSP"] + "\t",
item["TBP"] + "%\t", item["CBP"] + "\t", item["shijian"])
except Exception as err:
print(err)
return item
settings的代码:
BOT_NAME = 'cash'
SPIDER_MODULES = ['cash.spiders']
NEWSPIDER_MODULE = 'cash.spiders'
ITEM_PIPELINES={
'cash.pipelines.CashPipeline':300,
}
实验结果:
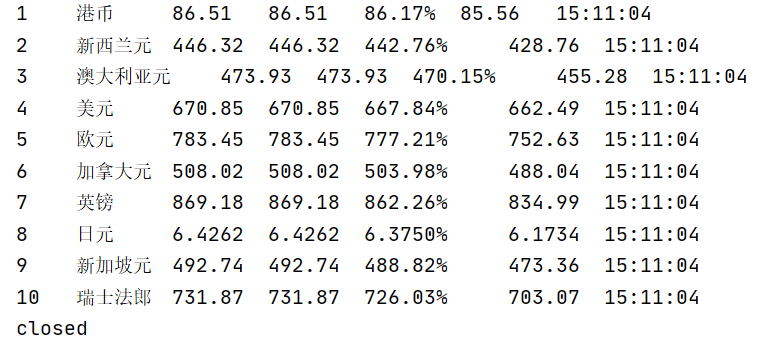
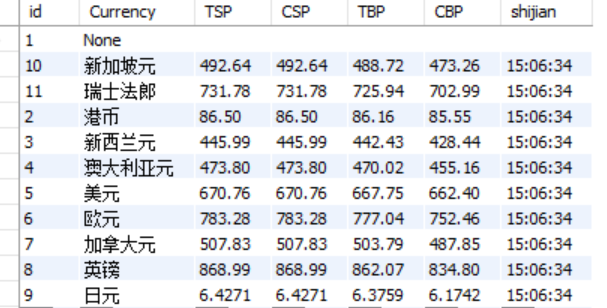
2)、心得体会
这个作业的代码我其实就是在第一题的基础上做了改动,就很顺利的得到结果了。
