2022被问的面试题
以下面试题个人面试被问到的八股文总结,仅供参考,答案结合网上,自己筛选
面试中也会面项目经验和实际开发的问题,这里就不写了,每个人项目经验不一致。
BFC?
可以理解为创建了BF块级的元素就是一个独立的容器,
里面的子元素不会在布局上影响外面的元素。清除浮动的方法?
方法一:
使用带 clear 属性的空元素
设置clear:both;
方法二:
使用 CSS 的 overflow 属性
给浮动元素的容器添加 overflow:hidden;
或 overflow:auto;可以清除浮动,另外在
IE6 中还 需要触发 hasLayout ,例如为父
元素设置容器宽高或设置 zoom:1。在添加
overflow 属性后,浮动元素又回到了容器
层,把容器高度撑起,达到了清理浮动 的
效果。
方法三:
使用 CSS 的:after 伪元素
结合:after 伪元素(注意这不是伪类,而是伪
元素,代表一个元素之后最近的元素)和 IEhack
,可以完美兼容当前主流的各大浏览器,这里的
IEhack 指的是触发 hasLayout。 给浮动元素的容
器添加一个 clearfix 的 class,然后给这个 class
添加一个:after 伪元素实 现元素末尾添加一个看不
见的块元素清除浮动css可以继承的属性?
行高,color,关于字体的,关于文本的,
列表布局,光标属性,元素可见型new一个对象的过程?
new 实际是在堆内存开辟新的空间。
四步:
①创建一个空对象,构造函数中的this指向这个空对象;
②这个新对象被执行[ [ 原型 ] ]连接;
③执行构造函数方法,属性和方法被添加到this引用的对象中;
④如果构造函数中没有返回其它对象,那么返回this
,即创建的这个的新对象,否则,返回构造函数中返回的对象。
function _new(){
let target = {}; //创建的新对象
let [constructor,...args] = [...arguments];
//执行[[原型]]连接,target是constructor的实例
target.__proto__ = constructor.prototype;
//执行构造函数,将属性或方法添加到创建的空对象上
let result = constructor.prototype;
if(result && (typeof (result) == "object" || typeof (result) == "function")){
//如果构造函数执行的结构返回的是一个对象,那么返回这个对象
return result;
}
//如果构造函数返回的不是一个对象,返回创建的对象
return target;
}
总结:
new实际上是在堆内存中开辟一个新的空间。
首先创建一个空对象obj,然后呢,构造函数的原型(prototype)
赋值给这个空对象的原型(__proto__)
然后执行函数中的代码,就是为这个新对象添加属性和方法。
最后进行判断其返回值,如果构造函数返回的是一个对象,
,如果不是,那就返回我们创建的对象。什么是原型和原型链?
隐式原型:__ptoto__
显式原型:prototype
原型:
原型分为隐式原型和显式原型,每个对象都有一个隐式原型,
它指向自己的构造函数的显式原型。
原型链:
当访问一个对象的某个属性时,会先在这个对象本身属性上查找,
如果没有找到,则会去它的__proto__隐式原型上查找,即它的
构造函数的prototype,如果还没有找到就会再在构造函数的
prototype的__proto__中查找,这样一层一层向上查找就会
形成一个链式结构,我们称为原型链。_proto__ 与prototype区别?
1. __proto__是每个对象都有的一个属性,而prototype是函数才会有的属性。
2. __proto__指向的是当前对象的原型对象,而prototype指向的,
是以当前函数作为构造函数构造出来的对象的原型对象。什么是深拷贝浅拷贝?
浅拷贝:
浅拷贝就是只复制数组(对象)本身,而不复制其
内容(引用类型的数据内容),最终两个数组中指向
同一套数据,共享同一个内存地址。
深拷贝:
深拷贝则是既赋值本身也赋值内容。Js中对于引用类型
的数据,默认进行的都是浅拷贝,单独开辟新的内存地址。深拷贝的实现方法和浅拷贝的实现方法?
深拷贝:
JQuery中的extend()方法
JSON.parse(JSON.stringify(待拷贝对象))
递归方法实现
浅拷贝:
引用数据类型结构赋值
Object.assign
Array.prototype.slice()
Array.prototype.concat()说说你对闭包的理解?闭包使用场景?
立即执行函数就是创建一个匿名函数,然后马上调用,
它创建了一个独立的作用域,避免了全局污染,(声明全
局变量、函数等时,它们将进入全局命名空间。除了性
能/内存问题(这可能会出现),您可能会遇到不幸的名称
冲突)闭包就是能够读取其他函数内部变量的函数,在js中
只有函数内部的子函数才能读取局部变量,因此闭包是定
义在一个函数内部的函数。在本质上的话,闭包就是将函数
内部和函数外部连接起来的一座桥梁.
闭包最大的有点就是可以读取函数内部的变量和让这些变量
始终保持在内存中. 因为闭包会让函数变量保存在内存中,内
存消耗大,如果滥用的话,会让页面卡顿,内存泄漏。
当一个函数A的作用域被内部的B函数引用时,A函数的作用域就会
被B函数闭包,当A函数执行完毕时,A函数的作用域也不会释放。
闭包可以实现对象的私有属性和私有方法。
闭包可以封装变量,从简减少对全局作用域的污染
总结:
闭包并不会引起内存泄漏,只是由于IE9 之前的版本对JScript
对象和COM对象使用不同的垃圾收集,从而导致内存无法进行回收。js 数据类型?
数据类型:
Number、String、Boolean、Null、 Undefined、Symbol(ES6)
引用类型:
Object(在JS中除了基本数据类型以外的都是对象,数据是对象,
函数是对象,正则表达式是对象)es6 的新特性?
类
模块化
箭头函数
函数参数默认值
模板字符串
可以在里面做运算表达式
解构赋值
延展操作符
对象属性简写
Promise:
promise有三个状态:
pending[待定]初始状态
fulfilled[实现]操作成功
rejected[被否决]操作失败
Let与Const:
var声明的变量存在变量提升,即变量可以在声明之前调用,值为undefined
let和const不存在变量提升,即它们所声明的变量一定要在声明后使用,否则报错
var不存在暂时性死区
let和const存在暂时性死区,只有等到声明变量的那一行代码出现,才可以获取和使用该变量
var不存在块级作用域
let和const存在块级作用域
var允许重复声明变量
let和const在同一作用域不允许重复声明变量
var和let可以
const声明一个只读的常量。一旦声明,常量的值就不能改变
能用const的情况尽量使用const,其他情况下大多数使用let,避免使用var谈谈async和await?
async:
async用于声明function为异步方法,返回Promise实例
async的返回值为promise对象,那么函数本身的返回值去哪了?
熟知promise的同学都知道,promise的异步结果是通过then()或者
catch()方法来获取并进一步处理。异步函数的返回值会当成resolve
状态来处理,通过.then()来接收,而异步函数中出现的错误,则当成
reject来处理,通过.catch()来捕获。同一时刻,只能处理其中一个
状态,也就是resolve或者reject(也就是说函数要么处理成功,要么
处理失败)
await :
等待 其实就是指暂停当前 async function 内部语句的执行,等待后面的
myPromise() 处理完返回结果后,继续执行 async function 函数内部的
剩余语句;myPromise() 是一个 Promise对象。
注意:
await必须在async方法内部使用,其后如果跟随其他值,则直接返回该值,
如果其后跟着的是Promise实例,则必须等到promise返回结果(即通过resolve
或者reject处理的状态),否则后面的代码不会执行。注意:若返回reject状态
,其后代码都不会执行。箭头函数与普通函数的区别?
箭头函数内部this跟函数所在上下文this保持一致
没有arguments参数集合,可以用rest替代
不能使用call、bind、apply来改变this的指向
箭头函数,不能作为构造函数,使用new会报错。vue是单数据流还是双数据流?
vue是单项数据流。虽然vue有双向绑定“v-model”,
但是vue父子组件之间数据传递,仍然还是遵循单向数据流的,
父组件可以向子组件传递props,但是子组件不能修改父组件传
递来的props,子组件只能通过事件通知父组件进行数据更改。vue2响应式和vue3响应式原理区别?
vue2 :
vue采用数据劫持配合发布者-订阅者模式的方式,
通过Object.defineProperty()对数据进行劫持各
个属性的setter和getter,在数据变动时,发布
消息给依赖收集器,去通知观察者,做出对应的回
调函数,去更新视图。
缺点:
无法观测到删除数据和新增数据的变化,官方也给
了解决方案:this.$Set()或者this.$forceUpdate()
强制更新dom。
vue3:
vue3使用了Proxy配合Reflect拦截对象中任意属
性的变化, 代替vue2,Object.defineProperty()
方法数据的响应式(数据代理)。
优点:
支持监听对象和数组的变化,并且多达13种拦截方法,
动态属性增删都可以拦截,新增数据结构全部支持,
对象嵌套属性只代理第一层,运行时递归,用到才代理,
也不需要维护特别多的依赖关系,性能取得很大进步。
vue3的新特性?
compositionAPI(新)代替了 optionsAPI(旧) , 效果: 代码组织更方便了, 逻辑复用更方便了 非常利于维护!
vue3 源码用 ts 重构, vue3 对 ts 的支持更友好了 (ts 可以让代码更加稳定, 类型检测! )
重写虚拟DOM
新的组件:Fragment(片段)/Teleport(瞬移)/Suspense(不确定)
设计新的脚手架vite
object.defineproperty()三个参数?
Object.defineProperty 需要三个参数(object , propName , descriptor)
//第一个数是要添加或者修改属性的对象
//第二个参数是要添加或者修改的属性
//第三个参数是这个属性的配置项,以{}方式书写
vue双向绑定原理?
vue虚拟DOM的实现原理?
虚拟DOM是通过js对象的结构来记录html标签节点,
当组件数据更新需要渲染视图时,先用diff算法计算
变化前后js对象(也就是虚拟DOM树)结构的不同, 得
到最小差异, 然后针对性的更新部分真实DOM节点,
这样可以极大提高视图渲染效率, 节省内存消耗
Vue生命周期总共有几个阶段?
它可以总共分为8个阶段:创建前/后,载入前/后,更新前/后,销毁前/销毁后vue每个周期具体适合哪些场景?
beforeCreate (创建前) { 可以在加个loading事件,在加载实例是触发}
created (创建完成后) { 初始化完成时的事件写在这里,如在这结束loading事件,异步请求也适宜在这里调用}
beforeMount (挂在之前) { 虚拟DOM已经被创建了 }
mounted (挂在完成后) { 操作DOM的方法可以放在这里 }
beforeUpdate (更新前)
updated (更新后){数据统一处理,在这里写上相应函数}
beforeDestroy (实例销毁之前) { 确认停止事件的确认框 }
destroyed (实例销毁之后) {当前页面有事件监听器或者计时器时,需要在destroyed中取消或销毁 }created 获取比较复杂的对象数据,怎么更新Dom
可以使用this.$nextTick 函数 异步操作。domvue data 为什么是个函数?
我们可以采用总分的说法:
1.在Vue中根实例的data可以是对象也可以是函数,
但是在组件中的data必须要是一个函数, 组件就
是可以复用的Vue实例, 把公共的模块抽离出来,
达到复用和直接使用的效果. 接下来我会采用对比
的方式进行说明.
2.如果data是一个对象的话, 对象是一个引用类型;
它会在堆空间中开辟一片区域, 将内存地址存入.
这就使得所有的组件公共一个data, 当一个组件中修
改了data中的数据就会出现一变全变的现象.
3.如果data是一个函数的话, 且使用return返回一个
对象; 这就使得每复用一次组件就会返回一个全新的dat
a(这就相当于scoped, 每一个组件data都是私有的,
互不干扰, 各个组件维护自己的data)
总结:
data必须是一个函数, 函数的好处就是每一次组件复用
之后都会产生一个全新的data. 组件与组件之间各自维护
自己的数据, 互不干扰。
vue组件通信有几种方式?
1.props
2.$emit/$on
3.$children/$parent
4..$attrs/ $listeners
5.ref
6.eventBus
7.Vuex
8.$root
vue 3取消
$on/$children/$listeners
vue 样式怎么穿透?
stylus:
>>>
less:
/deep/
sass:
::v-deep
css:
>>>,/deep/,::v-deepvue中的指令和它的用法?
v-model:一般用在表达输入,很轻松的实现表单控件和数据的双向绑定
v-html:更新元素的innerHTML
v-show与v-if:条件渲染,注意二者区别
v-on:click:可以简写为@click,@绑定一个事件。如果事件触发了,就可以指定事件的处理函数
v-for:基于源数据多次渲染元素或模板
v-bind:当表达式的值改变时,将其产生的连带影响,响应式地作用于DOM语法
v-bind:title=”msg”简写:title="msg"v-if与v-show 的区别?
v-show原理是修改元素的css属性display:none来决定是显示还是隐藏
v-if则是通过操作DOM来进行切换显示v-if与v-for 是否能一起使用?
可以,但是不建议
原因:
v-for比v-if优先,即每一次都
需要遍历整个数组,影响速度。vue自定义指令。
两种方式:
全局自定义指令和局部自定义指令
bind:只调用一次,指令第一次绑定到元素时调用。
在这里可以进行一次性的初始化设置。
inserted:被绑定元素插入父节点时调用 (仅保证
父节点存在,但不一定已被插入文档中)。
update:所在组件的 VNode 更新时调用,但是可能
发生在其子 VNode 更新之前。指令的值可能
发生了改变,也可能没有。但是你可以通过比
较更新前后的值来忽略不必要的模板更新。
componentUpdated:指令所在组件的 VNode 及其子
VNode 全部更新后调用。
unbind:只调用一次,指令与元素解绑时调用。vue路由的钩子函数有哪些?
全局守卫
router.beforeEach:全局前置守卫,进入路由之前
router.beforeResolve:全局解析守卫,在beforeRouteEnter调用之后调用
router.afterEach:全局后置钩子,进入路由之后
路由组件内的守卫
beforeRouteEnter():进入路由前
beforeRouteUpdate():路由复用同一个组件时
beforeRouteLeave():离开当前路由时vue路由跳转方式有几种?
标签: router-link
方法:router.push('/home')vue路由 to from next 分别是什么?
to: 即将要进入的目标
from: 当前导航正要离开的路由
next() 放行vue 路由权限大概实现逻辑?
方式一:路由元信息(meta)
把所有页面都放在路由表中,只需要在访问的时候判断一下角色权限即可。
vue-router 在构建路由时提供了元信息 meta 配置接口,我们可以在元信
息中添加路由对应的权限,然后在路由守卫中检查相关权限,控制其路由跳转。
在 meta 属性里,将能访问该路由的角色添加到 roles 里。用户每次登陆后,
将用户的角色返回。然后在访问页面时,把路由的 meta 属性和用户的角色进行
对比,如果用户的角色在路由的 roles 里,那就是能访问,如果不在就拒绝访问。
方式二:动态生成路由表(addRoutes)
根据用户权限或者是用户属性去动态的添加菜单和路由表,可以实现对用户的功
能进行定制。
vue-router 提供了 addRoutes() 方法,可以动态注册路由,需要注意的是,动
态添加路由是在路由表中 push 路由,由于路由是按顺序匹配的,因此需要将诸
如404页面这样的路由放在动态添加的最后。vue.set()使用方法?
this.$set(要更新data数据,更新的位置,更新的值)
this.$set(this.items,0,{message:"ChangeTest",id:'10'})vueX是什么?怎么使用?哪种功能场景使用它?
vuex是什么:vue框架中状态管理:有五种,分别是 State、 Getter、Mutation 、Action、 Module
vuex的State特性
A、Vuex就是一个仓库,仓库里面放了很多对象。其中state就是数据源存放地,对应于一般Vue对象里面的data
B、state里面存放的数据是响应式的,Vue组件从store中读取数据,若是store中的数据发生改变,依赖这个数据的组件也会发生更新
C、它通过mapState把全局的 state 和 getters 映射到当前组件的 computed 计算属性中
vuex的Getter特性
A、getters 可以对State进行计算操作,它就是Store的计算属性
B、 虽然在组件内也可以做计算属性,但是getters 可以在多组件之间复用
C、 如果一个状态只在一个组件内使用,是可以不用getters
vuex的Mutation特性
改变store中state状态的唯一方法就是提交mutation,就很类似事件。
每个mutation都有一个字符串类型的事件类型和一个回调函数,我们需要改变state的值就要在回调函数中改变。
我们要执行这个回调函数,那么我们需要执行一个相应的调用方法:store.commit。
Action 类似于 mutation,不同在于:Action 提交的是 mutation,而不是直接变更状态;
Action 可以包含任意异步操作,Action 函数接受一个与 store 实例具有相同方法和属性的 context 对象,
因此你可以调用 context.commit 提交一个 mutation,
或者通过 context.state 和 context.getters 来获取 state 和 getters。
Action 通过 store.dispatch 方法触发:eg。
store.dispatch('increment')
vuex的module特性
Module其实只是解决了当state中很复杂臃肿的时候,module可以将store分割成模块,
每个模块中拥有自己的state、mutation、action和gettervue怎么监听vuex 值?
使用watch 监听axios 拦截器,可以做什么?
1.请求拦截器:
请求拦截器的作用是在请求发送前进行一些操作,例如在每个请求体里加上token,
统一做了处理如果以后要改也非常容易。
2.响应拦截器:
响应拦截器的作用是在接收到响应后进行一些操作,例如在服务器返回登录状态失效,
需要重新登录的时候,跳转到登录页。
3.axios的相关配置属性:
url 适用于请求的服务器URL
baseURL 将自动加url在前面,除非url是一个绝对URL,
responseType 表示浏览器将要的相应数据类型,默认值:json,还包括其他:arraybuffer、document、json、text、stream
transformRequest 允许在向服务器发送前,修改请求数据,只能用在put、post、patch这几个请求方法
headers 即将被发送的自定义请求头
params 即将于请求一起发送的url参数,必须是个无格式对象或URLSearchParams对象
auth 表示HTTP基础验证应当用于连接处理,并提供凭据,这将设置一个Authorization头,覆盖掉已有的Authorization头
proxy 定义代理服务器的主机名和端口axios 怎么实现进度条?
progressEvent.lengthComputable
//属性lengthComputable主要表明总共需要完成的工作量和已经完成的工作是否可以被测量
//如果lengthComputable为false,就获取不到progressEvent.total和progressEvent.loaded
下载: onDownloadProgress
downLoadProgress.value = progressEvent.loaded / progressEvent.total * 100 //实时获取最新下载进度
上传:onUploadProgress
upLoadProgress= progressEvent.loaded / progressEvent.total * 100 //实时获取上传进度webpack 有几个模块分别是干什么?
5个模块分别是:
entry,Output,Loader,Plugins,Mode
1.entry:
表示从哪个文件为入口起点开始打包,分析构建依赖图,
可以定义单个或者多个,对应的,可以构建出单页或者多
页应用,一般会跟output成对出现。
2.Output:
表示打包后的资源输出到哪里,以及命名规则,对应
entry多文件入口的情况写法,如果要支持CJS、UMD、
ESM、html页面直接引入,都是在这里通过配置实现的。
这里的[name].js表示出口的文件名和多入口的文件名
保持一致,这样的话可以做到不同的页面加载不同的js
页面。
3. Loader:
因为webpack只能处理js/json资源,不能处理类似css/
img等其他资源,所以需要通过loader支持来处理其他资源,
以下是常用的loader:
babel-loader:转换es6,es7的语法 --- 文件转换
css-loader:css文件的加载和解析 --- 文件转换
less-loader:将less转换成css --- 文件转换
ts-loader:TS转JS --- 文件转换
file-loader :静态资源加载 --- 文件转换
raw-loader:静态资源内联,读取文件以字符串加载进入
首屏,可用于移动端做适配时使用,比如在使用rem时,
需要计算根节点的字体大小,计算大小要优先于单页应用
的JS执行,可以把计算rem的代码以内联脚本的形式插入到
html中优先执行。
thread-loader:多进程打包提高打包速度 --- build优化
4. Plugins:
Plugins可以用于执行范围更广的任务,插件的范围包括,从打包
优化到压缩,到定义环境变量等,以下是常用的Plugins:
CommonsChunkPlugin:将chunk相同的模块代码提取成公共JS(
chunk:webpack运行时的各个文件一个状态,之后会组合成最终
产物bundle)
CleanWebpackPlugin:清理构建目录
ExtractTextWebpackPlugin:将css从bundle文件中提取成一个
独立的css文件
CopyWebpackPlugin:文件或者目录拷贝
HtmlWebpackPlugin:创建html承载bundle,最终文件无论是
JS还是css都需要html来承载展
5. Mode:
指的是webpack使用相应模式的配置,它有以下两个选项:
(1)development,开发环境,它会默认开启以下选项:
NamedChunksPlugin :当开启 HMR 的时候,显示更新包的名字。
NamedModulesPlugin:当开启 HMR 的时候,显示更新包的相对路径。
(2)production,生产环境,它会默认开启以下选项:
FlagDependencyUsagePlugin:编译时标记依赖 --- tree-shaking相关
FlagIncludedChunksPlugin:防子chunks多次加载 --- tree-shaking相关
ModuleConcatenationPlugin:作用域提升(scope hosting) --- scope hosting
NoEmitOnErrorsPlugin:在输出阶段时,遇到编译错误跳过 --- 编译优化
OccurrenceOrderPlugin:给经常使用的ids更短的值 --- 编译优化
SideEffectsFlagPlugin:识别package.json或者module.rules的sideEffects标志
(纯的ES2015模块),安全地删除未用到的export导出
--- tree-shaking相关
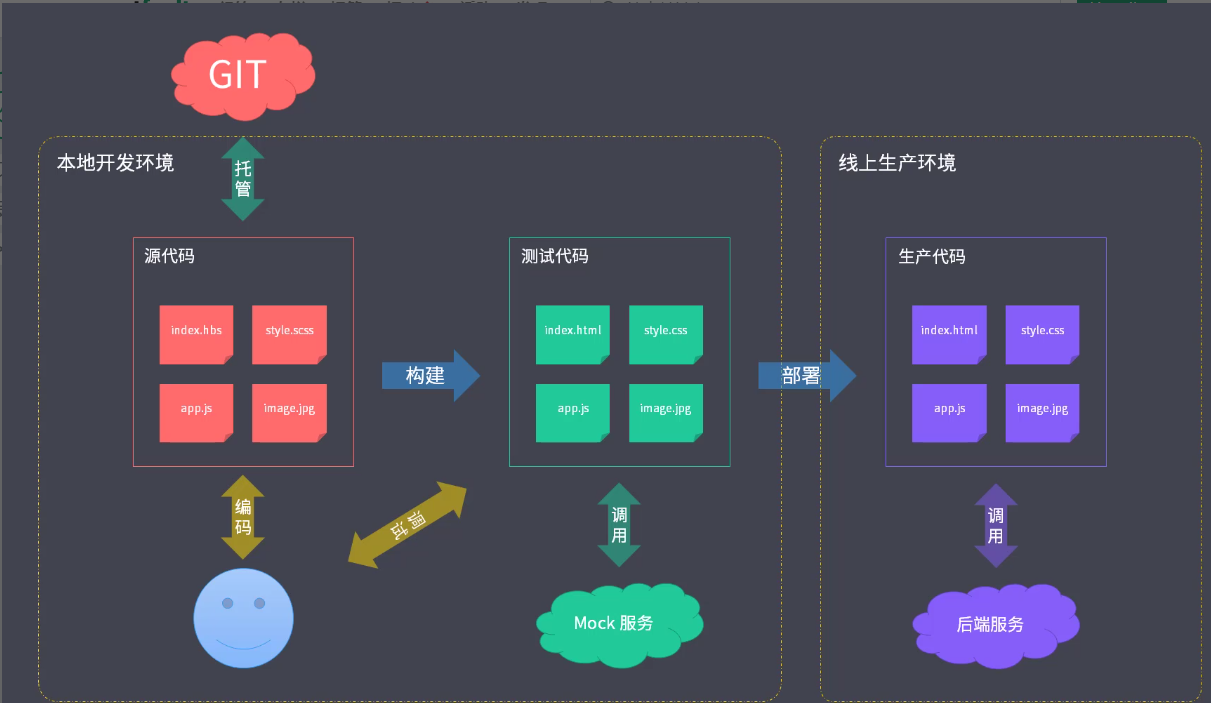
UglifyJsPlugin:删除未引用代码,并压缩 --- 代码优化什么是工程化?
前端工程可以定义为,将工程方法系统化地应用到前端开发中,
以系统、严谨、可量化的方法开发、运营、维护前端应用程序。前端工程化流程:
创建项目 => 编码 => 预览/测试 => 提交 => 部署
创建项目:
在项目开发初期,我们可以实用工具自动创建一些脚手架、
模板、通用等文件;还能够创建项目结构、创建特定类型文件。
编码 :
在正式堆代码的时候,可能会有多人协同开发的场景;这时候需
要我们制定编码规范来约束开发人员的编码风格,并使用工具来
代替人为约定。除此之外,还可以使用一些自动化工具来替我们
自动构建、自动编译打包。
预览/测试:
在开发本地调试的时候,我们可以使用一些工具来模拟服务器场
景并实现热更新、热加载;即代码修改后自动编译构建,浏览器根
据变化自动刷新同时还要方便我们查看源码。
提交:
Git Hooks:可在提交前进行代码质量和风格的检查
Lint-staged 持续集成
部署:
自动化部署:CI/CD
自动化集成:Jenkins 可以调用执行脚本,集成自动化构建、打包、
部署等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号