厦门大学林子雨开设的《大数据技术原理与应用》第七章 MapReduce
概述
Map Reduce 分布式并行编程:借助一个集群通过多台机器同时并行处理大规模数据集

-
1、mapreduce编程思想
核心设计两个函数:Map函数和Reduce函数
策略:分而治之,把非常庞大的数据集,切分成非常多独立的小分片,然后为每一个分片单独地启动一个map任务,最终通过多个map任务,并行地在多个机器上去处理。
理念:计算向数据靠拢而不是数据向计算靠拢
选出一些相关的机器作为map机器,负责相关的数据处理分析
还有一些为reduce机器,做reduce任务处理数据不需要迁移,计算就可以在数据节点上面执行,完成运算结果
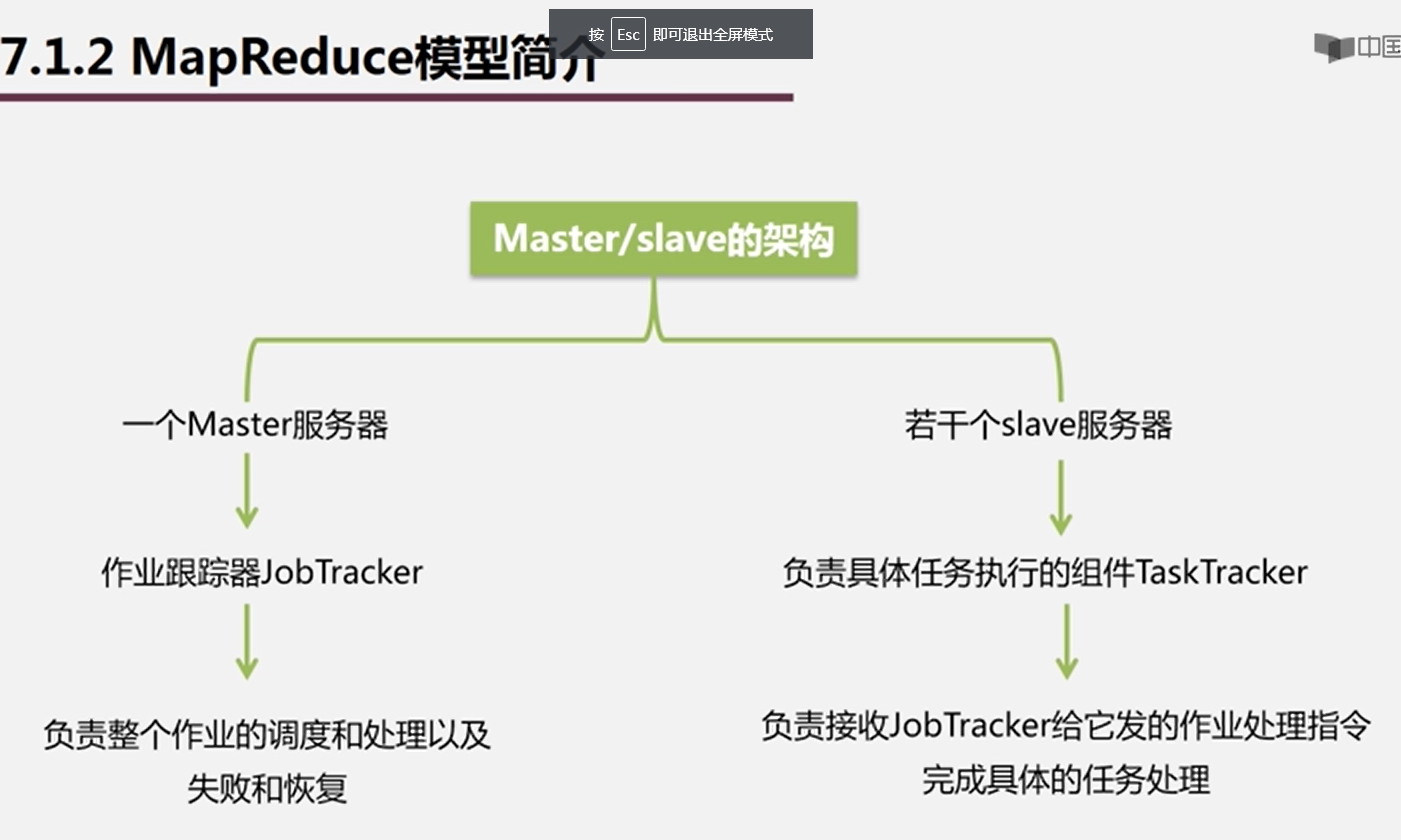
采用了Master/slave架构
Map和reduce函数简介

-
2、mapreduce体系结构

Client:通过Client可以提交用户编写的应用程序用户通过它将应用程序交到JobTracker端;也可以通过提供的接口去查看当前提交作业的运行状态.
JobTracker:
- 负责资源的监控和作业的调度
- 监控底层的其他的TaskTracker以及当前运行的Job的健康状况
- 一旦探测到失败的情况就把这个任务转移到其它节点继续执行跟踪任务执行进度和资源使用量(任务调度器--Task Scheduler 可以自己编写)TaskTracker:
- 执行具体的相关任务一般接收JobTracker发送过来的命令
- 把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是heartbeat发送给JobTracker
- slot:等分CPU资源的内存单位。分为map类型和reduce类型,两者不可以通用。(2.0已经进行了更改)
- Task 分为map任务和Reduce任务,两种可以同在一台机器上运行 -
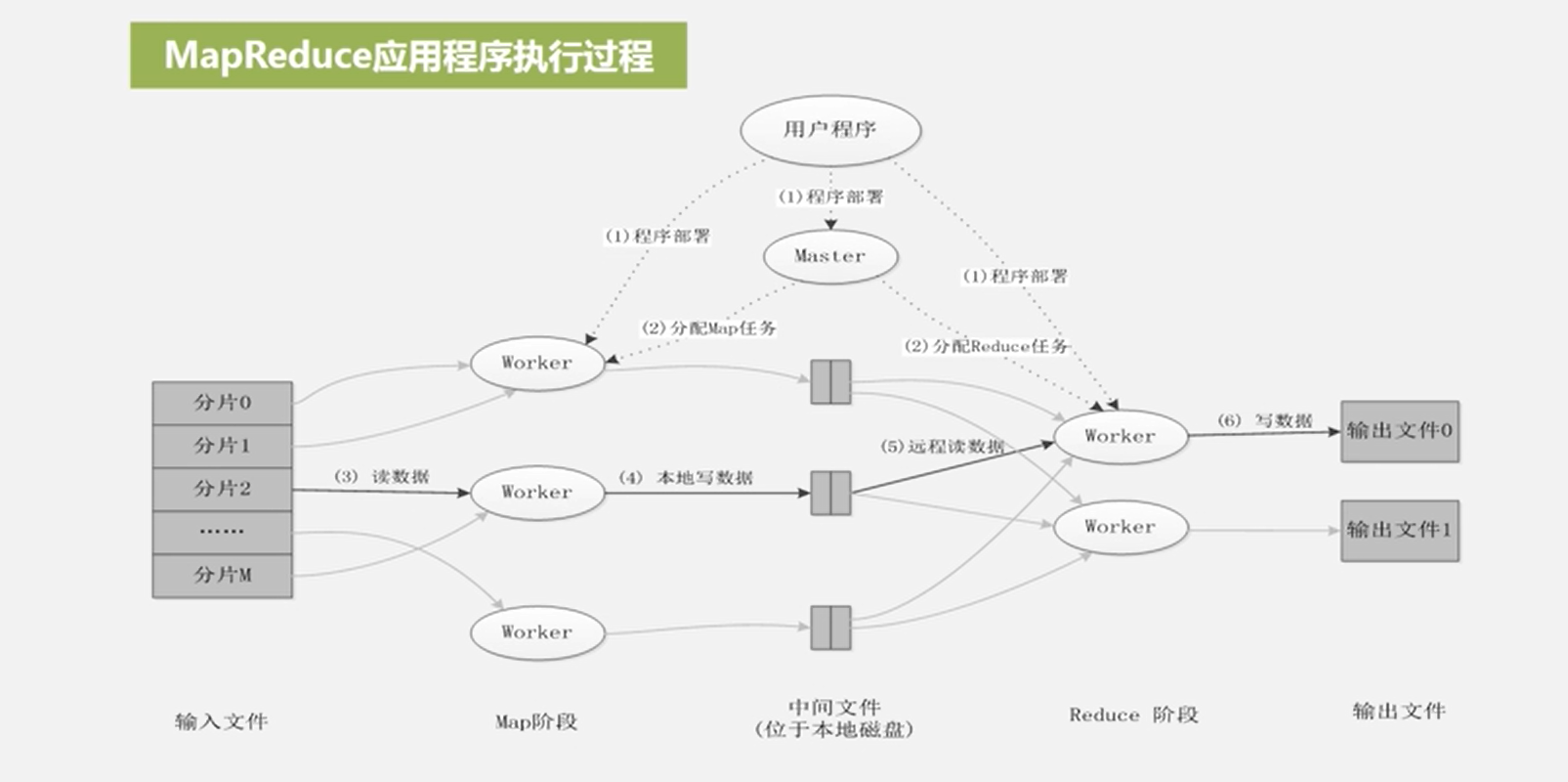
3、mapreduce工程流程
不同的map任务和reduce任务之间没有交换,且不需要用户参与

mapreduce执行的各个阶段

分片与块关系,分片由用户自定义的
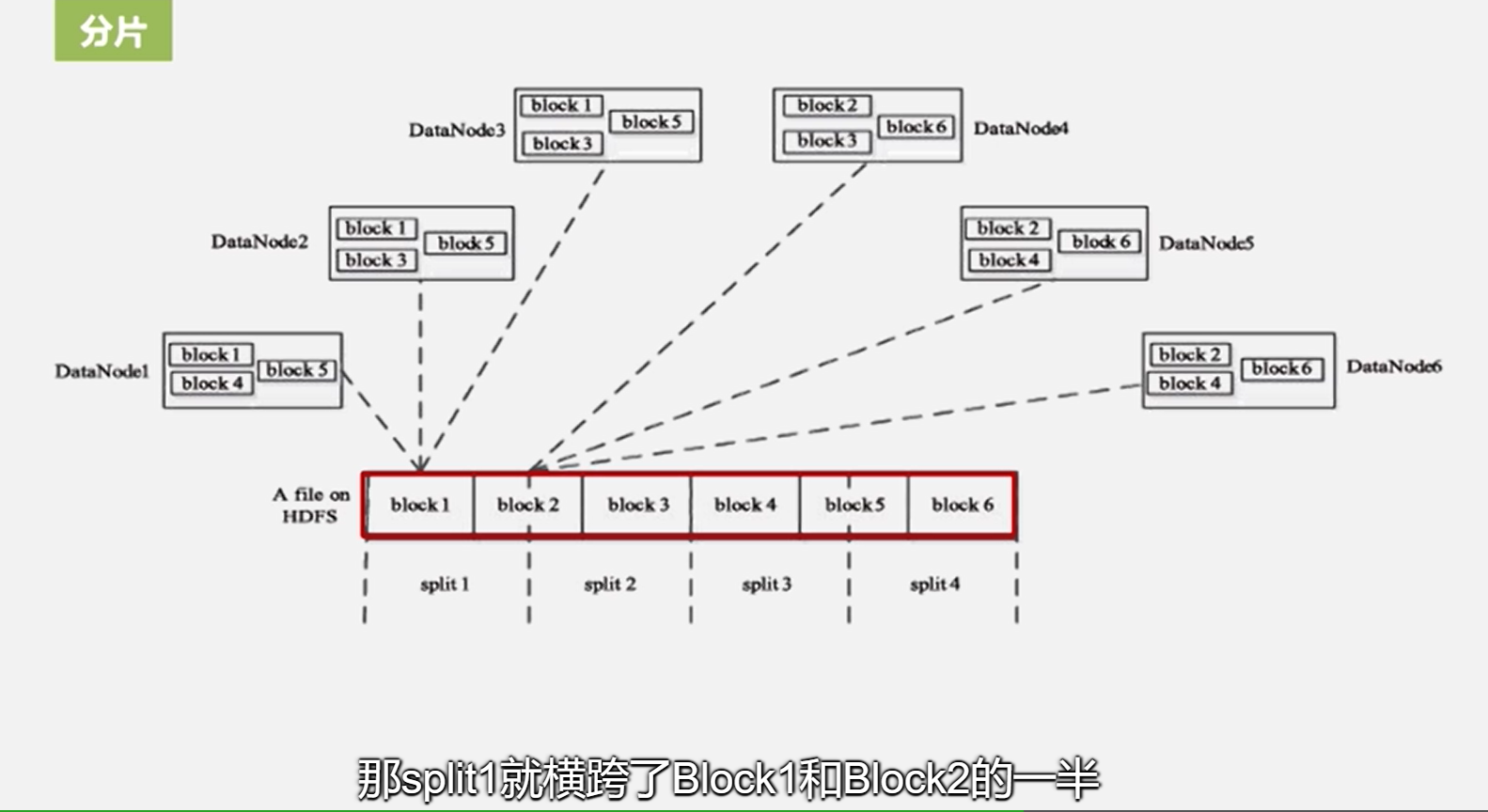
有多少个分片,就有多少个map任务
一般在实际工作中,默认就是一个块的大小就是一个片的大小
Reduce任务的数量:最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目 通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(预留一些处理错误)
-
4、shuffle过程解析
shuffle过程简介
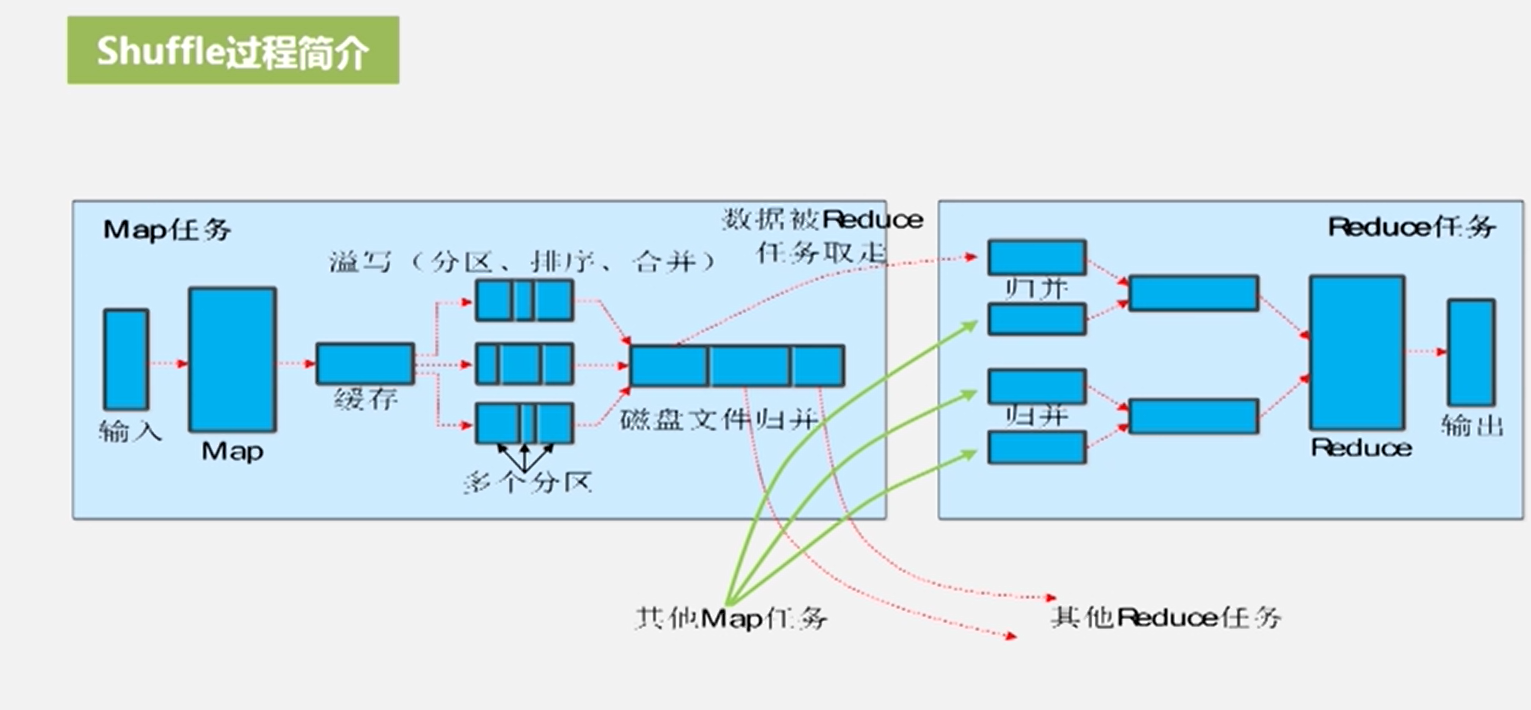
包含了map和reduce端的shuffle
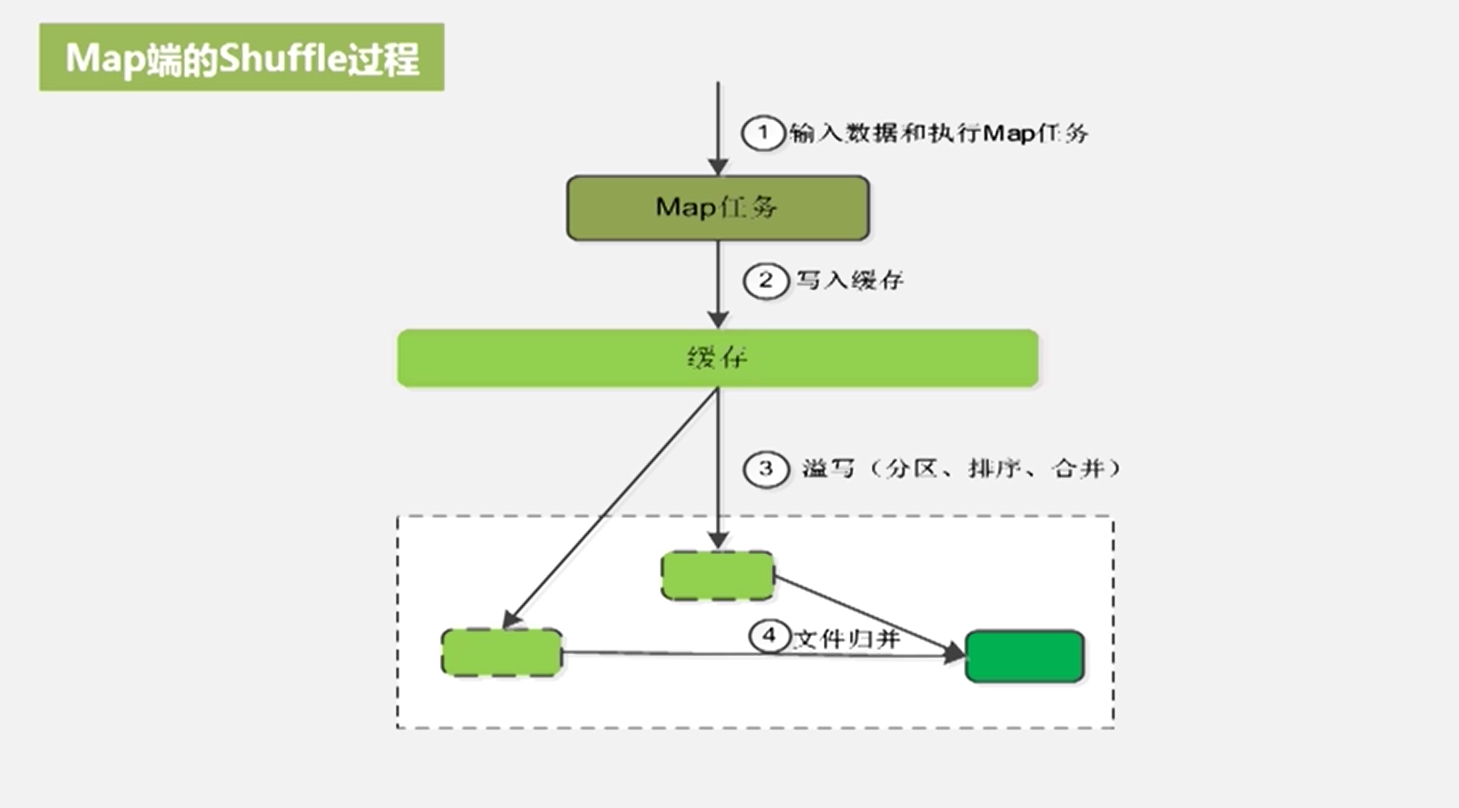
map端的shuffle,溢写有一个溢写比(分区、排序、合并(减少写入磁盘的数据量,如3个<a,1>则合并成<a,3>)),不会影响正常的map过程
分区一般分为范围分区、哈希分区
reduce端的shuffle过程(归并,把值构成一个value-list,如3个<a,1>则归并成<a,<1,1,1>>),如果拉过来了map磁盘文件很少,就直接走缓存即可
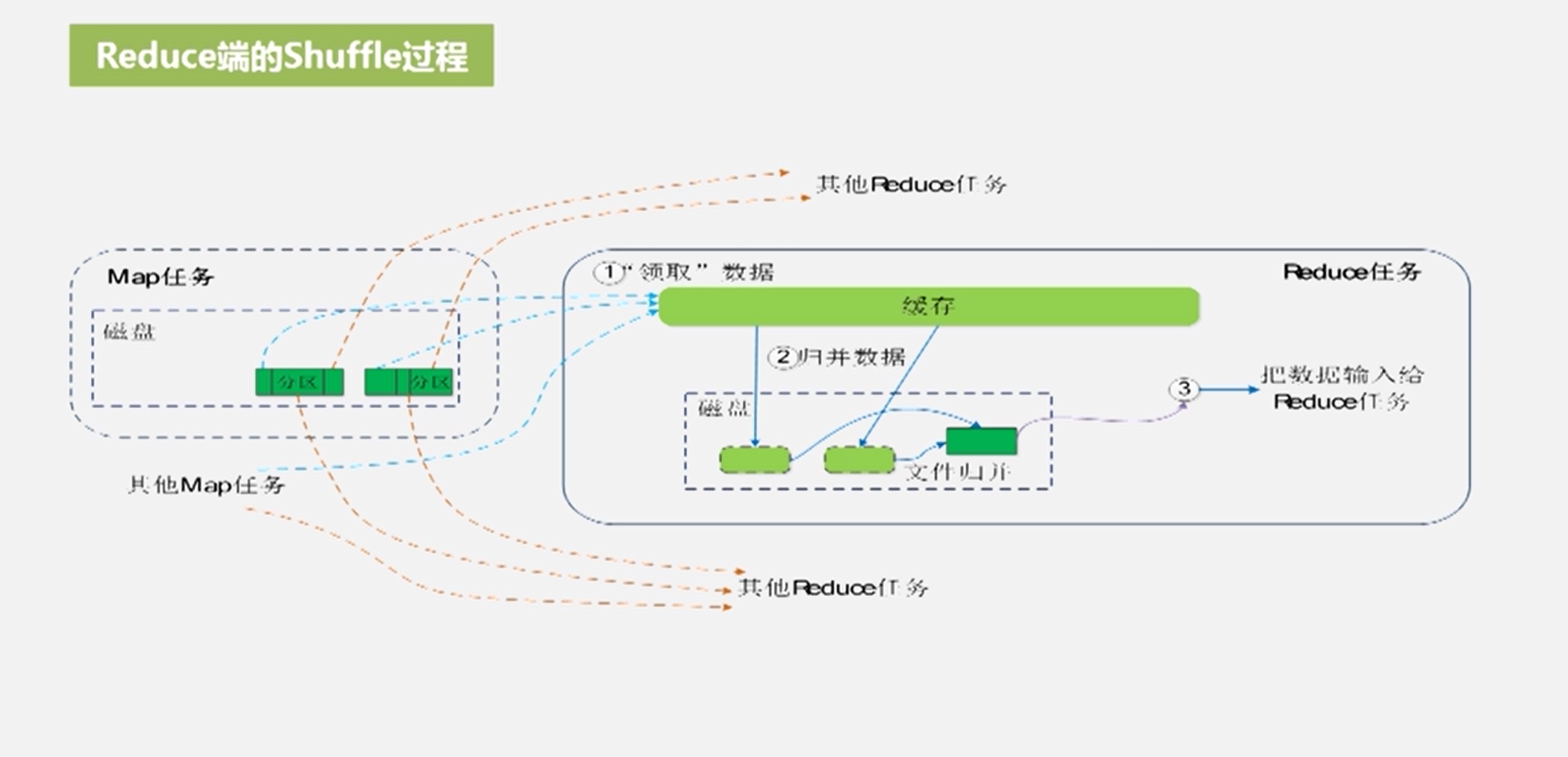
-
5、实例:WordCount
输入:一个包含大量单词的文本文件
输出:文件中每个单词及其出现次数,并按照单词字母顺序排序,每个单词和其频数占一行,单词和频数之间有间隔
具体应用:如分组聚合运算、矩阵乘法、关系代数运算(选择、投影、并、交、差、连接)、矩阵运算
-
6、Mapreduce编程实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号