
python-scrapy介绍+ setting设置,代理设置,pipelines连接mongodb
什么是scrapy
Scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是 Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
那么scrapy是如何帮助我们抓取数据的呢?
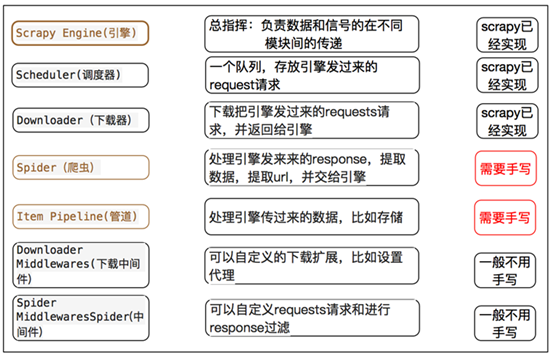
scrapy框架的工作流程:
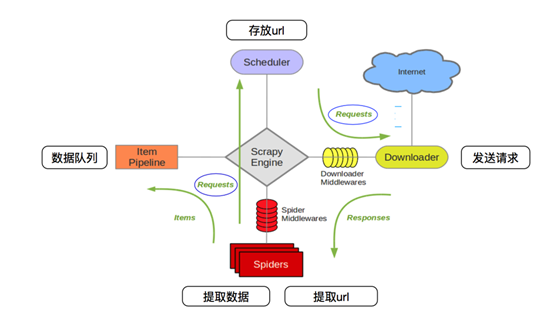
scrapy框架的工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy的setting设置:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
#将数据存储到redis数据库里
# ITEM_PIPELINES = {
# 'scrapy_redis.pipelines.RedisPipeline':300
#}
LOG_FILE='name日志.log' LOG_ENABLED=True #默认启用日志 LOG_ENCODING='UTF-8'#日志的编码,默认为’utf-8‘ LOG_LEVEL='DEBUG'#日志等级:ERROR\WARNING\INFO\DEBUG
使用scrapy_radis
#去重组件,在redis数据库里做去重操作 # DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # # #使用scrapy_redis的调度器,在redis里分配请求 # SCHEDULER = "scrapy_redis.scheduler.Scheduler" # # # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_FLUSH_ON_START = True # # # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # # # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 # SCHEDULER_PERSIST = True # # #服务器地址 # REDIS_HOST = '127.0.0.1' # # #端口 # REDIS_PORT = 6379 #将数据存储到redis数据库里 # ITEM_PIPELINES = { # 'scrapy_redis.pipelines.RedisPipeline':300 #}
在中间件中设置代理(代理需要重新获取ip地址和端口号)
import random
class proxyMiddleware(object):#代理池 def __init__(self, crawler): super(proxyMiddleware, self).__init__() @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. # s = cls() # crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) # return s return cls(crawler) def process_request(self, request, spider): # ip = 'https://50.93.200.95:1018' # 可变成随机获取 proxy_list = [ 'http://113.128.148.39:8118', 'http://101.236.57.99:8866', 'http://183.47.40.35:8088', 'http://113.128.148.39:8118', 'http://27.17.45.90:43411', 'http://60.191.201.38:45461', 'http://218.60.8.99:3129', 'http://113.200.56.13:8010', 'http://61.135.217.7:80', 'http://183.47.40.35:8088', 'http://124.235.181.175:80', ] poo = random.choice(proxy_list) print("Now checking ip is", poo) request.meta["proxy"] = poo
pipelines设置:(留坑,MySQL设置)
需要下载pymongo,windows在cmd中输入pip install pymongo
1 import pymongo 2 3 class HuxiuPipeline(object): 4 def __init__(self): 5 self.client=pymongo.MongoClient()#链接Mongodb数据库 6 self.db=self.client['数据库名']#新建数据库 7 def process_item(self, item, spider): 8 self.db['表名'].insert(dict(item))#第一种方法 #将数据存放到插入到表中 9 return item

