
MYSQL中replace into的用法
做项目时遇到这样一个问题,把查询出的数据插入到一个新表里面,第一次可以直接插入,当第二次第三次的时候如果有新的数据直接添加,有旧数据在原有的基础上直接更新。
如果先删除再插入的话效率不高,如果对比两端的数据,相同的更新,没有的插入,这样效率也不高,在网上找了找,mysql有一个replace into可以实现,有新数据就自己新增,旧数据就直接更新,其实就是先删除数据,再新增
新建一个test表,三个字段,id,title,uid, id是自增的主键,uid是唯一索引;
插入两条数据
insert into test(title,uid) VALUES ('123465','1001'); insert into test(title,uid) VALUES ('123465','1002'); 执行单条插入数据可以看到,执行结果如下: [SQL]insert into test(title,uid) VALUES ('123465','1001'); 受影响的行: 1 时间: 0.175s
使用 replace into插入数据时:
REPLACE INTO test(title,uid) VALUES ('1234657','1003'); 执行结果: [SQL]REPLACE INTO test(title,uid) VALUES ('1234657','1003'); 受影响的行: 1 时间: 0.035s
当前数据库test表所有数据如下:
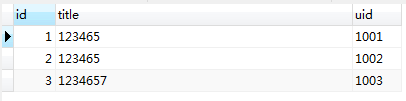
当uid存在时,使用replace into 语句
REPLACE INTO test(title,uid) VALUES ('1234657','1001'); [SQL]REPLACE INTO test(title,uid) VALUES ('1234657','1001'); 受影响的行: 2 时间: 0.140s

replace into t(id, update_time) values(1, now());
或
replace into t(id, update_time) select 1, now();
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
MySQL replace into 有三种形式:
1. replace into tbl_name(col_name, ...) values(...)
2. replace into tbl_name(col_name, ...) select ...
3. replace into tbl_name set col_name=value, ...
第一种形式类似于insert into的用法,
第二种replace select的用法也类似于insert select,这种用法并不一定要求列名匹配,事实上,MYSQL甚至不关心select返回的列名,它需要的是列的位置。例如,replace into tb1( name, title, mood) select rname, rtitle, rmood from tb2;?这个例子使用replace into从?tb2中将所有数据导入tb1中。
第三种replace set用法类似于update set用法,使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
前两种形式用的多些。其中 “into” 关键字可以省略,不过最好加上 “into”,这样意思更加直观。另外,对于那些没有给予值的列,MySQL 将自动为这些列赋上默认值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号