
ElasticSearch中的基本概念
1、关系型数据库 VS elasticsearch

2、索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
3、文档(Document)
- ES是面向文档的,文档是所有可搜索数据的最小单位。
- 一部电影的具体信息
- 一张唱片的详细信息
- 一篇文档的具体内容
- 文档会被序列化成JSON格式,保存在ES中。
- JSON对象由字段组成
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
- 每个文档都有一个Unique ID
- 可以通过指定ID或者通过ES自动生成。
- 一篇文档包含了一系列字段,类似数据库表的一条记录
- JSON文档,格式灵活,不需要预先定义格式
- 字段的类型可以指定或者通过ES自动推算
- 支持数组/嵌套
文档元数据
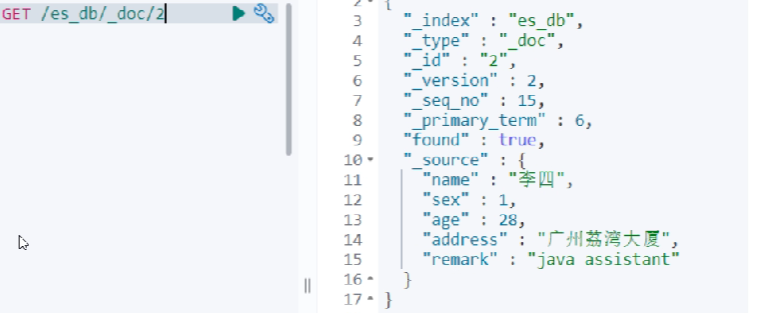
元数据,用于标注文档的相关信息
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一ID
- _source:文档的原始JSON数据
- version:文档的版本号,修改删除操作version都会自增1
- seq_no:和version一样,一旦数据发生更改,数据也是一直累计的。Shard级别严格递增,保证后写入的Doc的seq_no大于先写入的Doc的seq_no。
- primary_term:主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构