http协议分析
一、http协议介绍
http:Hyper Text Transfer Protocol 超文本传输协议,是互联网应用最为广泛的一种网络协议,主要用于Web服务。通过计算机处理文本信息,格式为HTML(Hyper Text Mark Language)超文本标记语言来实现。
二、http协议的版本
http 0.9:仅于用户传输html文档
http 1.0
1.引入了MIME(Multipurpose Internet Mail Extesions)机制:多用途互联网邮件扩展,引入这个技术之后,http可以发送多媒体(比如视频、音频等)信息。此机制让http不在单单只支持html格式,还可以支持其他格式来进行发送了。
2.引入了keep-alive机制,支持持久连接的功能(但这个keep-alive原理是在首部添加了某个字段而形成的,并非原生就支持此功能)
3.引入支持缓存功能
http 1.1
支持更多的请求方法,更加精细的缓存控制,原生直接支持持久连接功能(presistent)。
http 2.0
提供了HTTP语义优化的传输,spdy : google引入了的一个技术,能够加速http数据交互,尤其是使用ssl 加速机制,但是spdy现在用的还不多。
目前常用的版本就是http 1.0版本和http 1.1版本。
三、Web页面资源分成静态和动态两种:
静态页面,事先就编辑并定义完成的,通常是由html语言设计的页面,如:文本,图片,音频,视频等。
动态页面,通过网站的动态编程语言编写的程序,需要编译,然后再以html格式的格式输出给用户,动态语言有:php,jsp(java),asp,.net
备注:这些脚本都必须有相应的解释器,比如说 php需要有php解释器等等
静态和动态的方式
1、静态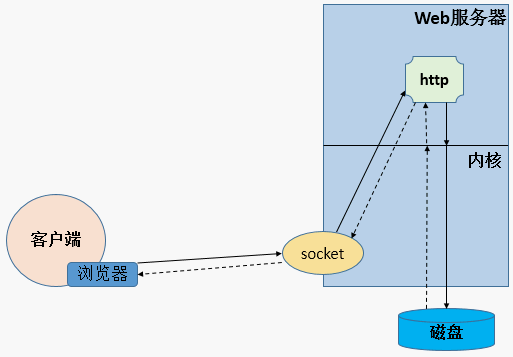
1、Web服务器向内核注册socket
2、客户端通过浏览器,向Web服务器发起request请求
3、Web服务器收到客户端的request信息
4、如果用户请求的资源在服务器本地的话,http服务会向系统内核申请调用
5、内核调用本地磁盘里的数据,并将数据发给http服务
6、http将用户请求的资源通过response报文,最终响应给客户端
2、动态
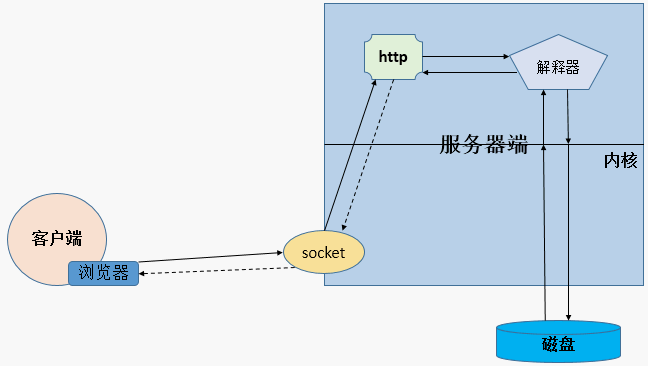 与静态不同的是,如果用户请求的是动态内容,那么此时http服务会调用后端的解析器,由动态语言去处理用户的请求,如果需要请求数据的时候,会向内核申请调用,从而向磁盘中获取用户指定的数据,通过解释器运行,运行的结果通常会生成html格式的文件。然后构建成响应报文,最终发回给客户端。
与静态不同的是,如果用户请求的是动态内容,那么此时http服务会调用后端的解析器,由动态语言去处理用户的请求,如果需要请求数据的时候,会向内核申请调用,从而向磁盘中获取用户指定的数据,通过解释器运行,运行的结果通常会生成html格式的文件。然后构建成响应报文,最终发回给客户端。
四、http协议的报文
HTTP报文中存在着很多行的内容,一般是由ASCII码串组成,各字段长度是不确定的。HTTP的报文可分为两种:请求报文与响应报文
1.request Message(请求报文)
客户端 → 服务器端
由客户端向服务器端发出请求,不同的网站用于请求不同的资源(html文档)
2.response Message(响应报文)
服务器端 → 客户端
是服务器予以响应客户端的请求
1、请求报文格式介绍
请求行 + 请求首部 + 空白行 + 请求实体
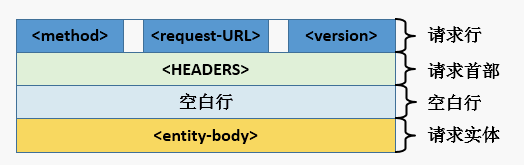
例如:
<method> <request-URL> <version>
<HEADERS>
# 这里一定要是一个空白行
<entity-body>
1.请求行
由请求方法字段<method>+请求URL字段<request-URL>+HTTP协议版本<version>组成,用来标识客户端请求的资源时使用的请求方法,请求的资源,请求的协议版本是什么,它们直接使用“空格”进行分隔!
<method> 这次请求的方式是什么,也就是请求方法
<request-URL> 请求的是哪个资源,哪个URL。可以是相对路径,如/images/log.jpg,也可以是绝对路径,如http://www.baidu.com/images.banner.jpg
<version> 请求的协议版本是什么,http协议版本,格式HTTP/<major>.<minor>,例如:HTTP/1.0,HTTP/1.1
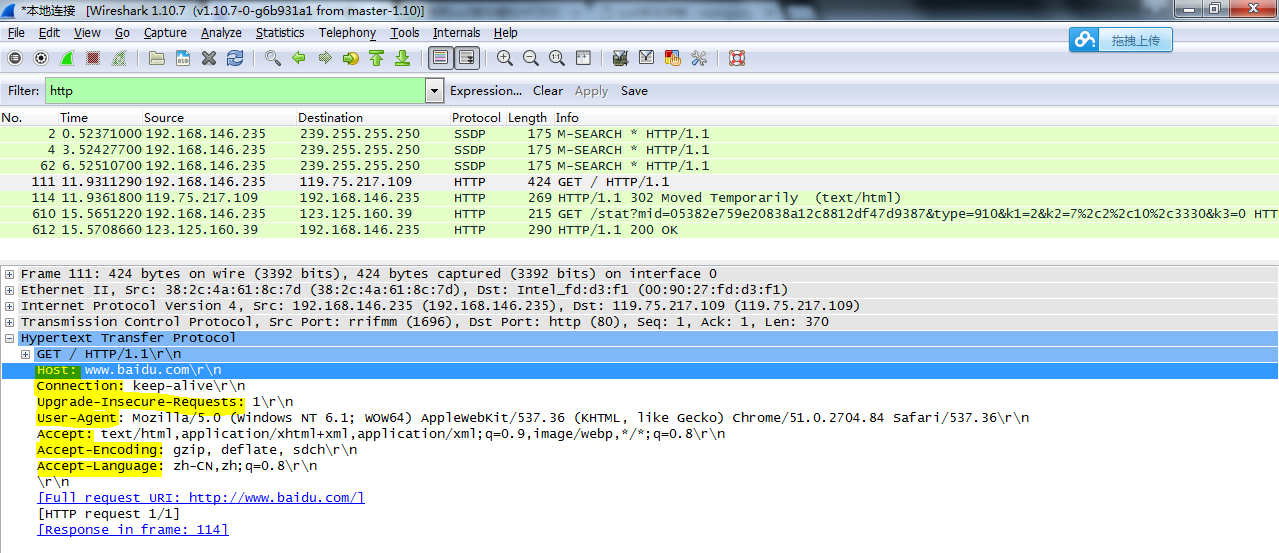
下图是通过抓包工具获得的结果,常用的抓包工具sniffer,wireshark,tcpdump(Linux下的一个命令行工具)
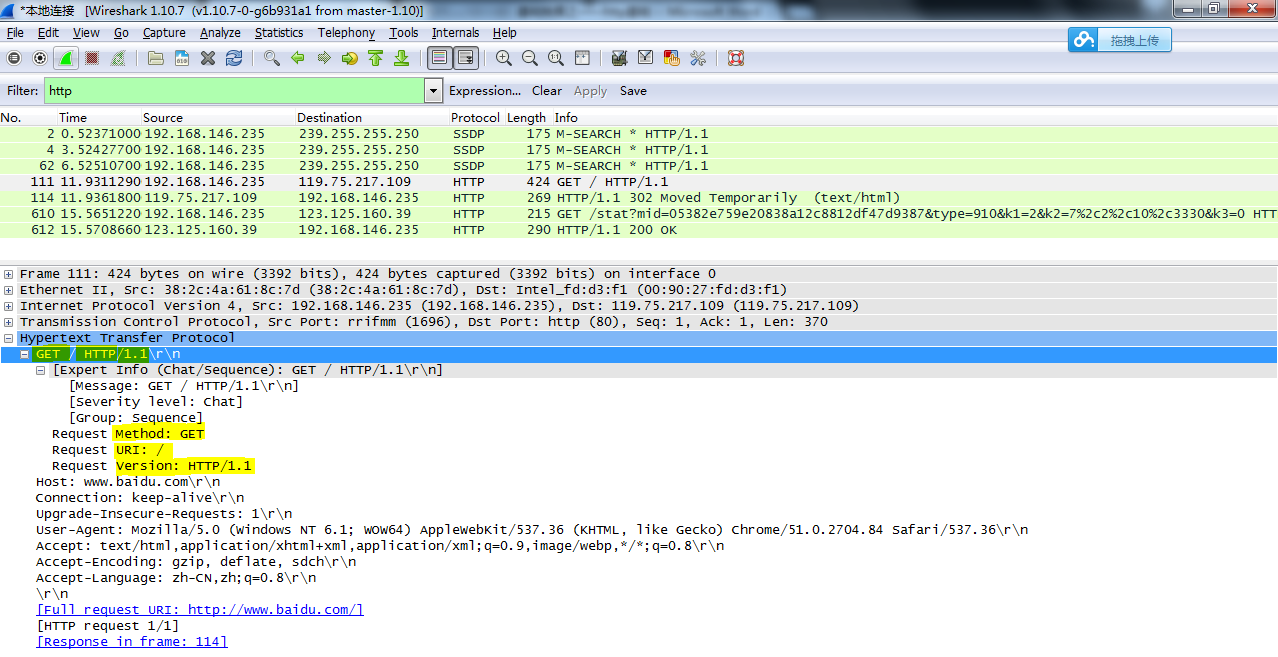
上图是用wireshark工具抓取http请求报文的显示结果。在首部后的“\r\n”表示一个回车和换行,以此将该首部与下一个首部隔开。
或者用curl命令获取http请求报文
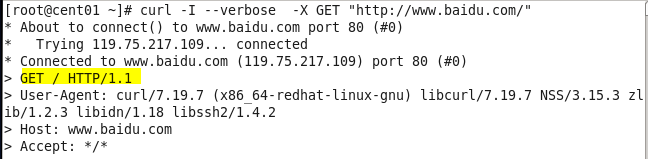
2.请求首部
由关键字+关键字的值组成,之间使用“:”进行分隔,格式Name:Value,请求首部的作用是通过客户端将请求的相关内容告知服务器端,首部可以不止一个。
<HEADERS> 首部,首部可能不止一个。各种所可以使用的首部信息
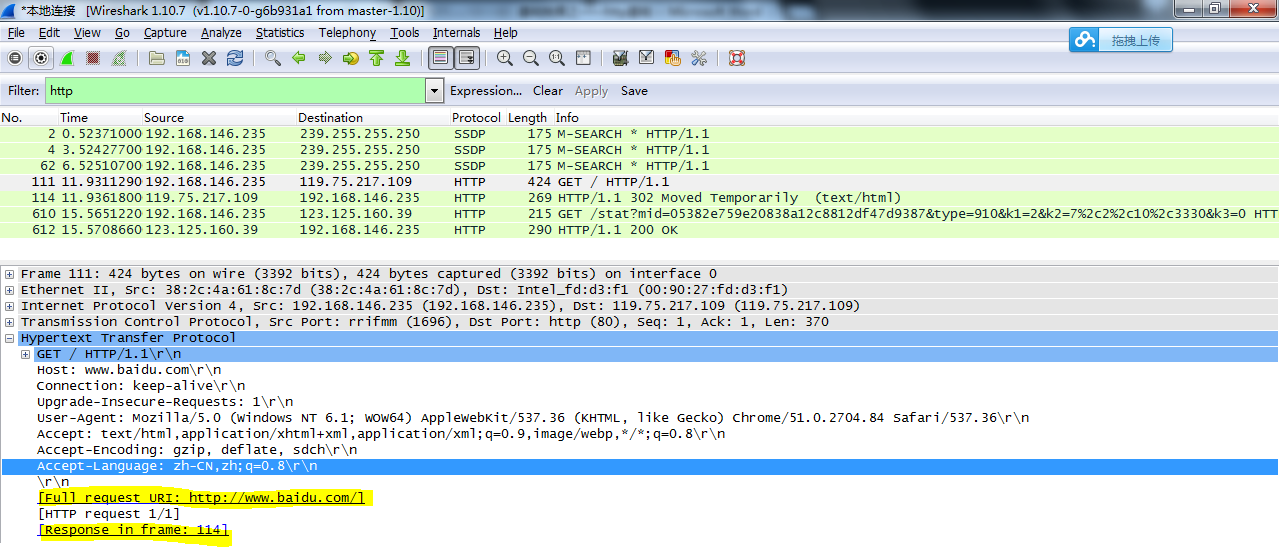
3.空白行
请求首部之后会有一个空白行,通过发送回车字符和换行符,用于通知服务器端以下的内容将不会再出现请求首部的信息。
4.请求实体
你需要请求的内容到底是什么
<entity-body> 请求实体,你到底请求的内容是什么
2、响应报文格式介绍
起始行 + 响应首部 + 空白行 + 响应实体
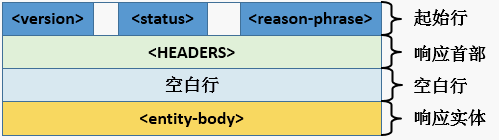
例如:
<version> <status> <reason-phrase>
<HEADERS>
# 这里一定要是一个空白行
<entity-body>
1.起始行
也称之为状态行,用于服务器端响应客户端请求的状态信息,由版本号<version> + 状态码<status> + 原因短语<reason-phrase>组成,例如“ HTTP/1.1 200 OK”
<version> 响应时客户端请求的是什么版本,服务器端就需要响应什么版本
<status> 请求的状态码是什么 202,403等
<reason-phrase> 响应的状态码的信息是什么,原因短语,这个状态码所响应的意义,易读信息
<HEADERS> 一大堆的响应首部
<entity-body> 响应体
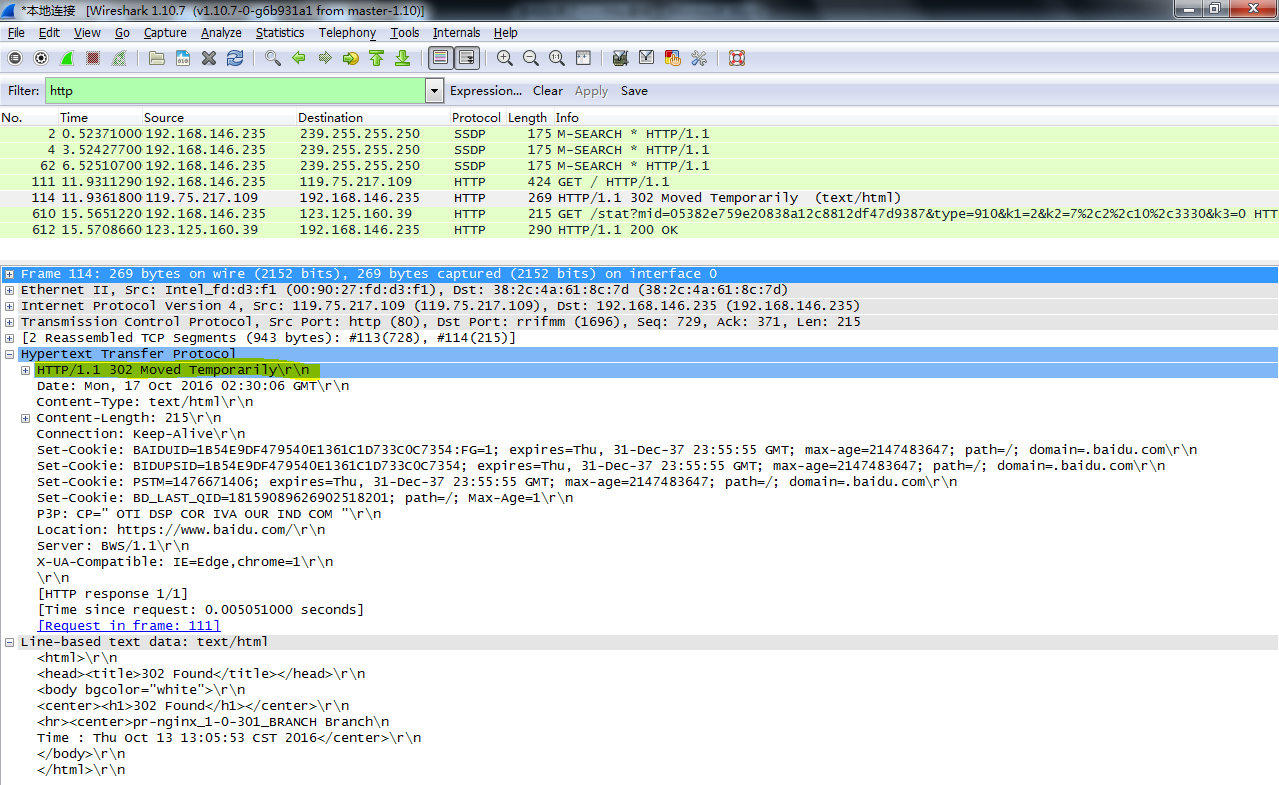
2.响应首部
<version> 响应时客户端请求的是什么版本,服务器端就需要响应什么版本
<status> 请求的状态码是什么 202,403等
<reason-phrase> 响应的状态码的信息是什么,原因短语,这个状态码所响应的意义,易读信息
<HEADERS> 一大堆的响应首部
<entity-body> 响应体
类似请求报文,起始行后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分割。格式Name:Value。
例如:
Content-Type: test/html; charset=utf-8
Content-Length: 78
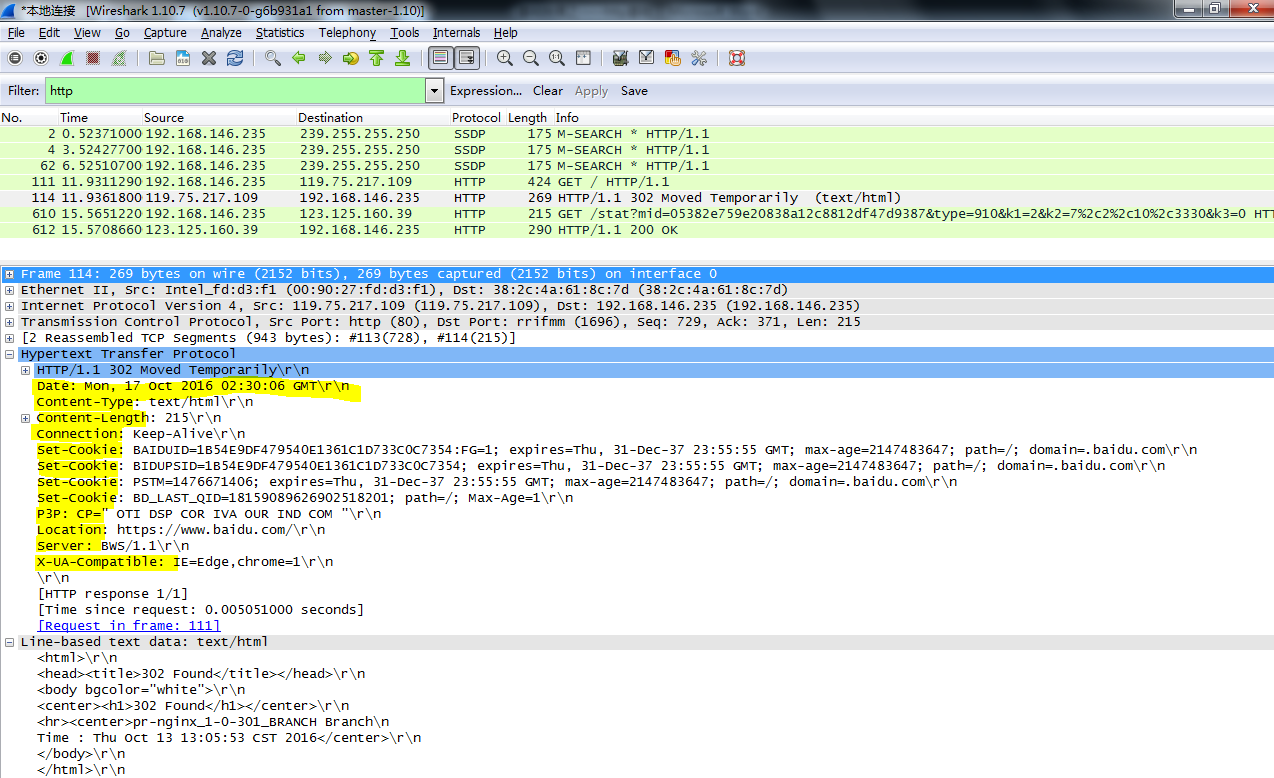
3.空白行
最后一个响应首部信息之后就是一个空行,通过发送回车符和换行符,通知客户端空行下无首部信息
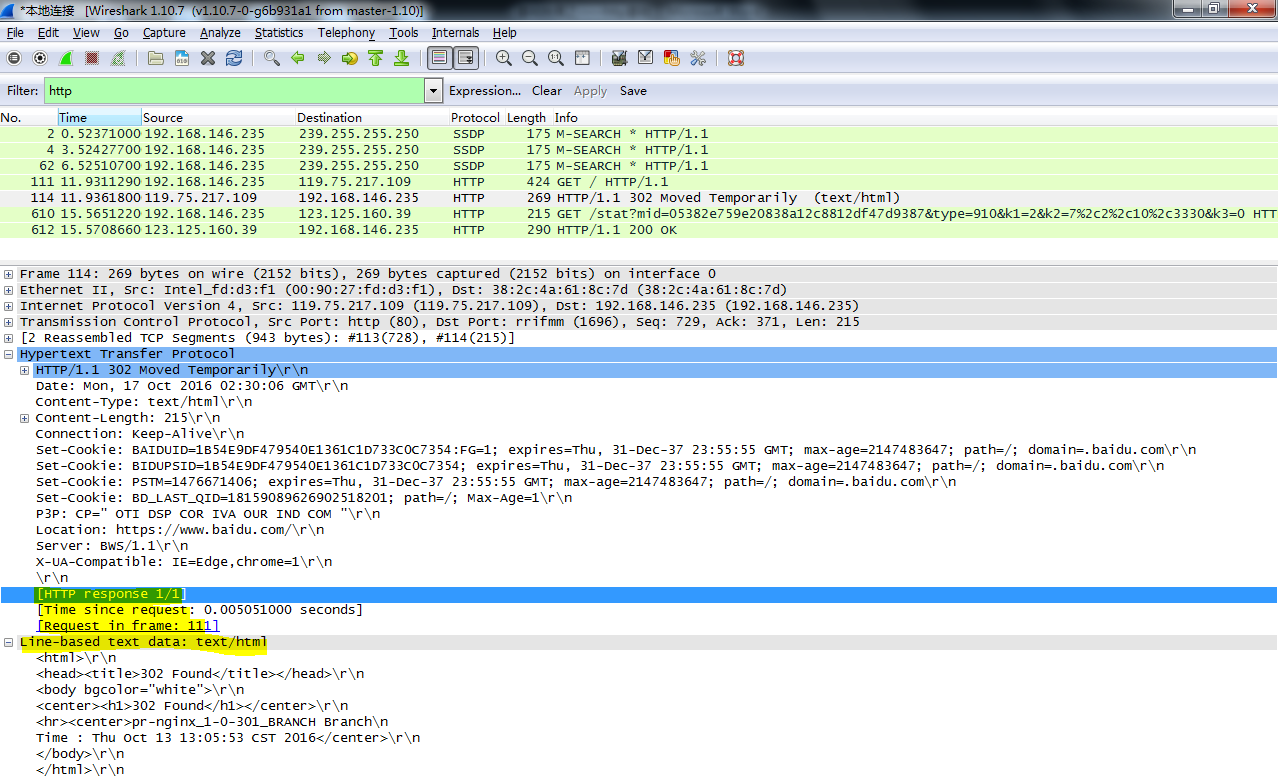
4.响应实体
响应实体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制(例如图片,视频)
<version> 响应时客户端请求的是什么版本,服务器端就需要响应什么版本
<status> 请求的状态码是什么 202,403等
<reason-phrase> 响应的状态码的信息是什么,原因短语,这个状态码所响应的意义,易读信息
<HEADERS> 一大堆的响应首部
<entity-body> 响应体
五、HTTP请求方法
在HTTP通信过程中,每个HTTP请求报文中都会包含一个HTTP请求方法,用于告知客户端向服务器端请求执行某些具体的操作,下面列举几项常用的HTTP请求方法。
HTTP请求方法 | 描述 |
|---|---|
GET | 用于客户端请求指定资源信息,并返回指定资源实体 |
HEAD | 跟GET相似,但其不需要服务器响应请求的资源,而返回响应首部(只需要响应首部即可,就是告诉我有或者没有,不需要缓存界面给我) |
POST | 基于HTML表单向服务器提交数据,服务器通常需要存储此数据,通常存放在mysql这种关系型数据库中 |
PUT | 与GET相反,是向服务器发送资源的,服务器通常需要存储此资源(存放的位置通常是文件系统) |
DELETE | 请求服务器端删除URL指定的资源 |
MOVE | 请求服务器将指定的页面移至另一个网络地址 |
OPTIONS | 探测服务器端对请求的URL所支持使用的请求方法 |
TRACE | 跟踪一次请求中间所经历的代理服务器、防火墙或网关等。 |
常用的HTTP请求方式是GET, POST, HEAD,Put,delete
六、HTTP的状态码
状态码 | 说明 |
|---|---|
1XX | 信息性状态码,用于指定客户端相应的某些操作 |
2XX | 成功状态码,我请求一个资源,这个资源在,这就表示请求成功了。 |
3XX | 重定向的状态码,有时会返回的是一个新地址,而非结果 |
4XX | 客户端类错误,你请求的资源不存在,或者你请求的时候,我们这个资源拒绝你访问,你没有权限 |
5XX | 服务器类的错误信息。向服务器发起请求,服务器发现需要运行一个脚本,从而调用解析库。如果在调用过程中出错就会出现这种情况。或者你的脚本有语法错误,也可能会导致这个问题。 |
常用状态码说明
状态码 | 说明 |
|---|---|
200 | 服务器成功返回网页,这是成功的HTTP请求返回的标准状态码 |
201 | CREATED 上传文件成功后显示 |
301 | Move Permanently,永久重定向,会返回一个新地址,并告诉我们你所请求的地址将永久挪到那个新地址去了 |
302 | Fonud,临时重定向,临时放到某个地方,会在响应报文中使用“Location:新位置”; |
304 | Not Modified,资源没有做任何修改 |
403 | Forbidden 请求被拒绝,主要是权限问题 |
404 | Not Found 请求的资源不存在 |
405 | Method Not Allowed 你使用的方法不被允许,不支持 |
500 | Internal Server Error:服务器内部错误,无法完成请求 |
502 | Bad Gateway,服务器作为网关或代理,从上游服务器收到无效响应 |
503 | Service Unavailable,服务暂时不可用,服务器目前无法使用,由于超载或停机维护。通常,这只是暂时状态 |
504 | 服务器作为网关或代理,但是没有及时从上游服务器收到响应(web网站被墙了) |
七、HTTP首部介绍
- 通用首部
- 请求首部
- 响应首部
- 实体首部:专门用来表示实体中资源内部的类型、长度、编码格式等
- 扩展首部:非标准首部,可有程序员自行创建
1、通用首部
- Connection:定义C/S之间关于请求、响应的有关选项
在http1.0 的时候,如果他想使用持久连接,那么他所设置的选项即为
例如:Connection:keep-alive
- Cache-Control:缓存控制,实现更精细的缓存控制方式。在http 1.1上比较常见
2、请求首部
- Client-IP :客户端 IP地址
- Host :请求的主机,这在实现基于主机名的虚拟主机时很有用
- Referer :指明了请求当前资源原始资源的URL,使用referer是可以防盗链
- User-Agent:用户代理,一般而言是浏览器
- Accept首部:指客户端可以接受哪些编码的类型
- Accept:服务端能够发送的媒体的类型
- Accetp-Charset:接收的字符集
- Accept-Encoding:编码格式
- Accept-Lanage:所能接受的语言编码格式
- 条件式请求首部:(在http1.1中才会用到)
当发送请求时,先问问对方是否满足条件,如果满足条件就请求,不满足就不请求 - 跟安全相关的请求:
- Authorization
- Cookie
3、响应首部
- Age:资源响应给你之后可以使用的时长
- Server:向客户端说明自己用到的程序名称和版本
- 跟安全相关:
- WWW-Authentication
- Set-Cookie
4、实体首部
- Location:指明资源的新位置,实现302响应码时通常会用到
- Allow:允许对此资源使用的请求方法
- 内容相关的首部
- Content-Encoding
- Content-Language
- Content-Length
- Content-Location:内容所在的位置
- Content-Type
- 缓存相关:
- ETag:扩展标签/标记
- Expires:过期时间
- Last-Modified:最后修改时间
ETag解释:
在网络上,有一些缓存服务器,另外,浏览器自身也有缓存功能
基于一个前提:图片不会经常改动,服务器在返回状态码200的同时,还会返回该图片的签名Etag,(可以理解为图片的指纹),当浏览器再次访问该图片时,就会去服务器校验指纹信息,如果图片没有变化,直接使用缓存里的图片,这样减轻了服务器的负担,一看到304,浏览器就知道了,要从本地缓存里面取图片,节省了图片在网络上传输的时间
附:
HTTP最常见的请求头如下:
Accept:浏览器可接受的MIME类型;
Accept-Charset:浏览器可接受的字符集;
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。
Accept-Language:浏览器所希望的语言种类
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中;
Connection:表示 是否需要持久连接。值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。
Content-Length:表示请求消息正文的长度;
5、cookie
Cookie:这是最重要的请求头信息之一;
Cookie相关的HTTP扩展头
1)Cookie:客户端将服务器设置的Cookie值返回到服务器;
2)Set-Cookie:服务器向客户端设置Cookie;
3)Cookie2 (RFC2965)):客户端指示服务器支持Cookie的版本;
4)Set-Cookie2 (RFC2965):服务器向客户端设置Cookie。
服务器在响应消息中用Set-Cookie头将Cookie的内容回送给客户端,客户端在新的请求中将相同的内容携带在Cookie头中发送给服务器。从而实现会话的保持,另外也可以通过cookie字段统计网站的访问用户数。
流程如下图所示: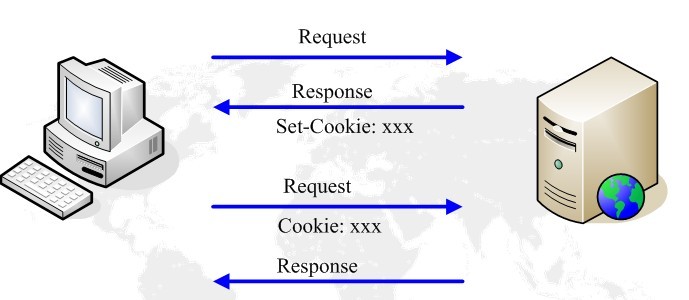
八、HTTP资源
资源就是通过HTTP协议可以让用户通过浏览器或用户代理能够通过基于http协议向服务器端请求并获取的内容,像html文档,一张图片等等。
资源类型:是通过MIME进行标记
格式:major/minor 主标记和次标记
常用的MIME类型
MIME类型 | 文件类型 |
|---|---|
test/html | html、htm文本类型 |
text/plain | text文本类型 |
image/jpeg | jpeg图像类型 |
image/gif | gif图像类型 |
vedio/mpeg4 | 音频标记类型 |
application/vnd.ms-powerpoint | 动态资源的标记方式 |
九、其他需要了解的知识
一次Web资源请求的具体过程
- 客户端在Web浏览器输入需要访问web网站的地址(网站域名)
- Web浏览器会请求DNS服务器,查询解析到指定域名和Web服务器的ip地址
- 客户端与请求的Web服务器端建立连接(TCP三次握手)
- TCP建立成功之后,发起HTTP请求
- 服务器端收到客户端HTTP请求之后,会处理该请求
- 处理客户端指定请求的资源
- 服务器构建响应报文,响应给客户端
- 服务器端将此信息记录到日志中
十、衡量一个web网站的访问量的指标:pv,uv,ip
pv:网站的点击量
uv:网站的访问用户数----COOKIE,cookie值相同的表示是一个用户。
ip:网站的访问ip数,即有多少台客户机访问web网站

 浙公网安备 33010602011771号
浙公网安备 33010602011771号