MapReduce编程之wordcount
实践
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 使用MapReduce开发WordCount的应用程序 */ public class WordCountApp { /** * Map:读取输入的文件 */ public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 接收到的每一行数据 String line = value.toString(); //按照指定分隔符进行拆分 String[] words = line.split(" "); for(String word : words){ // 通过上下文把map的处理结果输出 context.write(new Text(word),one); } } } /** * 归并操作 */ public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; for(LongWritable value : values){ //求key出现的次数和 sum += value.get(); } context.write(key, new LongWritable(sum)); } } /** * 定义Driver:封装lMapReduce作业的所有信息 * @param args */ public static void main(String[] args) throws Exception{ //创建configuration Configuration configuration = new Configuration(); //准备清理已存在的输出目录 Path outputPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if(fileSystem.exists(outputPath)){ fileSystem.delete(outputPath,true); System.out.println("out file exists,but is has deleted!"); } //创建job Job job = Job.getInstance(configuration,"WordCount"); //设置job的处理类 job.setJarByClass(WordCountApp.class); //设置作业处理的输入路径 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置map相关参数 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置reduce相关参数 job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //设置作业处理的输出路径 FileOutputFormat.setOutputPath(job , new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
运行
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
-
-
减少Map Tasks输出的数据量及数据网络传输量
-
combiner案例开发
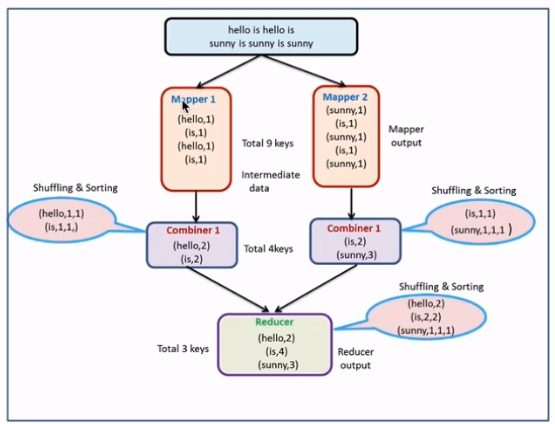
-
-
代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 使用MapReduce开发WordCount的应用程序 */ public class CombinerApp { /** * Map:读取输入的文件 */ public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 接收到的每一行数据 String line = value.toString(); //按照指定分隔符进行拆分 String[] words = line.split(" "); for(String word : words){ // 通过上下文把map的处理结果输出 context.write(new Text(word),one); } } } /** * 归并操作 */ public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; for(LongWritable value : values){ //求key出现的次数和 sum += value.get(); } context.write(key, new LongWritable(sum)); } } /** * 定义Driver:封装lMapReduce作业的所有信息 * @param args */ public static void main(String[] args) throws Exception{ //创建configuration Configuration configuration = new Configuration(); //准备清理已存在的输出目录 Path outputPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if(fileSystem.exists(outputPath)){ fileSystem.delete(outputPath,true); System.out.println("out file exists,but is has deleted!"); } //创建job Job job = Job.getInstance(configuration,"WordCount"); //设置job的处理类 job.setJarByClass(CombinerApp.class); //设置作业处理的输入路径 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置map相关参数 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置reduce相关参数 job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //通过job的设置combiner处理类,其实逻辑上和我们的reduce是一模一样的 job.setCombinerClass(MyReduce.class); //设置作业处理的输出路径 FileOutputFormat.setOutputPath(job , new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Partitioner
-
partitioner决定MapTask输出的数据交由哪个ReduceTask处理
-
默认实现:分发的key的hash值对ReduceTask个数取模
-
partitioner案例开发
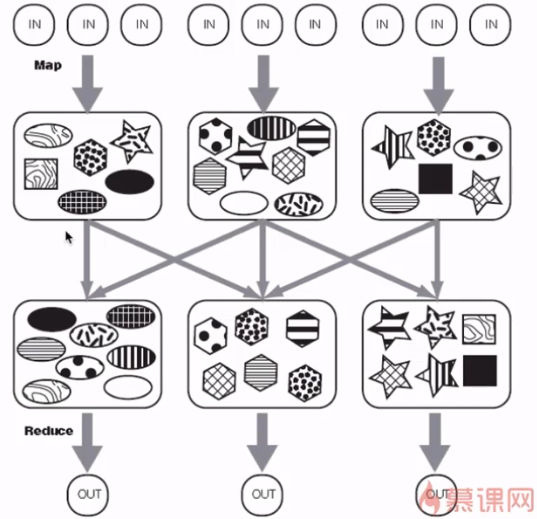
- 代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 使用MapReduce开发WordCount的应用程序 */ public class PartitionerApp { /** * Map:读取输入的文件 */ public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 接收到的每一行数据 String line = value.toString(); //按照指定分隔符进行拆分 String[] words = line.split(" "); context.write(new Text(words[0]),new LongWritable(Long.parseLong(words[1]))); } } /** * 归并操作 */ public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; for(LongWritable value : values){ //求key出现的次数和 sum += value.get(); } context.write(key, new LongWritable(sum)); } } public static class MyPartitioner extends Partitioner<Text,LongWritable>{ @Override public int getPartition(Text key, LongWritable longWritable, int i) { if(key.toString().equals("xiaomi")){ return 0; } if(key.toString().equals("huawei")){ return 1; } if(key.toString().equals("iphone")){ return 2; } return 3; } } /** * 定义Driver:封装lMapReduce作业的所有信息 * @param args */ public static void main(String[] args) throws Exception{ //创建configuration Configuration configuration = new Configuration(); //准备清理已存在的输出目录 Path outputPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if(fileSystem.exists(outputPath)){ fileSystem.delete(outputPath,true); System.out.println("out file exists,but is has deleted!"); } //创建job Job job = Job.getInstance(configuration,"WordCount"); //设置job的处理类 job.setJarByClass(PartitionerApp.class); //设置作业处理的输入路径 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置map相关参数 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置reduce相关参数 job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //通过job的设置partition job.setPartitionerClass(MyPartitioner.class); //设置4个reduce,每个分区一个 job.setNumReduceTasks(4); //设置作业处理的输出路径 FileOutputFormat.setOutputPath(job , new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar PartitionerApp /hdfsapi/test/partitioner /hdfsapi/test/outpartitioner


 浙公网安备 33010602011771号
浙公网安备 33010602011771号