MapReduce编程解析
wordcount
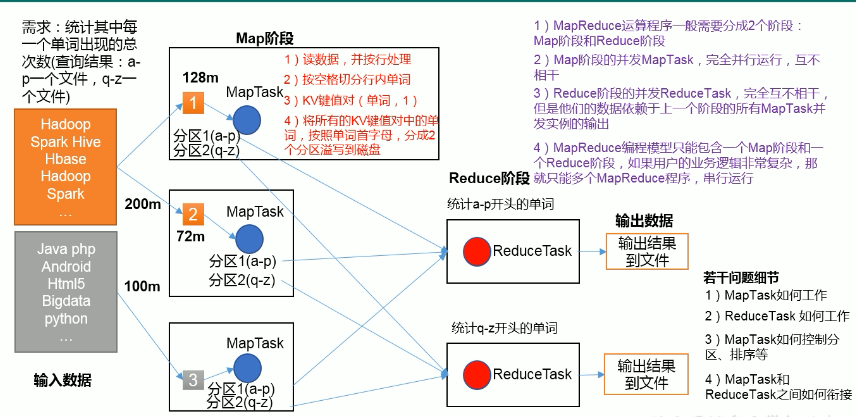
-
输入数据
atguigu atguigu
ss ss
cls cls
jiao
banzhang
xue
hadoop -
输出数据
atguigu 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1 -
Mapper
-
将MapTask传给我们的文本内容先转换成String
atguigu atguigu
-
根据空格将这一行切分成单词
atguigu
atguigu
-
将单词输出为<单词,1>
atguigu,1
atguigu,1
-
-
Reduce
-
汇总各个key的个数
atguigu,1
atguigu,1
-
输出该key的总次数
atguigu,2
-
-
Driver
-
获取配置信息,获取job对象实例
-
指定本程序的jar包所在的本地路径
-
关联Mapper/Reduce业务类
-
指定Mapper输出数据的kv类型
-
指定最终输出的数据的kv类型
-
指定job的输入原始文件所在目录
-
指定job的输出结果所在目录
-
提交作业
-
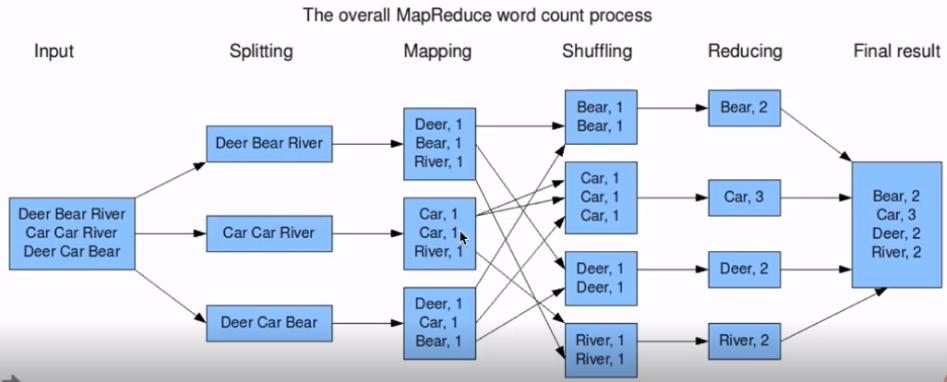
MapReduce编程模型之Map和Reduce
-
将作业拆分成Map阶段和Reduce
-
Map阶段:Map Tasks
-
Reduce阶段:Reduce Tasks
MapReduce编程模型之Map和Reduce
-
准备map处理的输入数据
-
Mapper处理
-
Shuffle
-
Reduce处理
-
结果输出
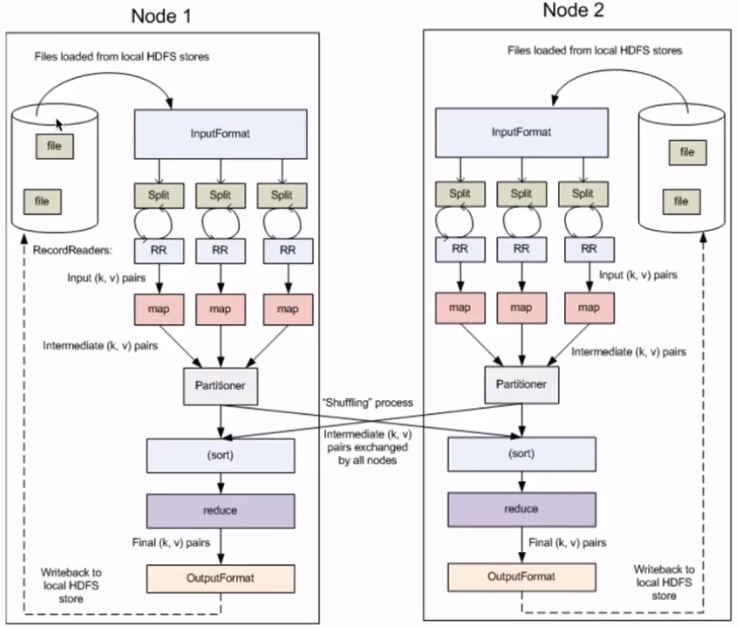
核心概念
-
Split:交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元
-
HDFS:blocksize是HDFS中最小的存储单元 128M
-
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系
-
-
InputFormat
-
OutputFormat
-
Combiner
-
Partitioner
![]()
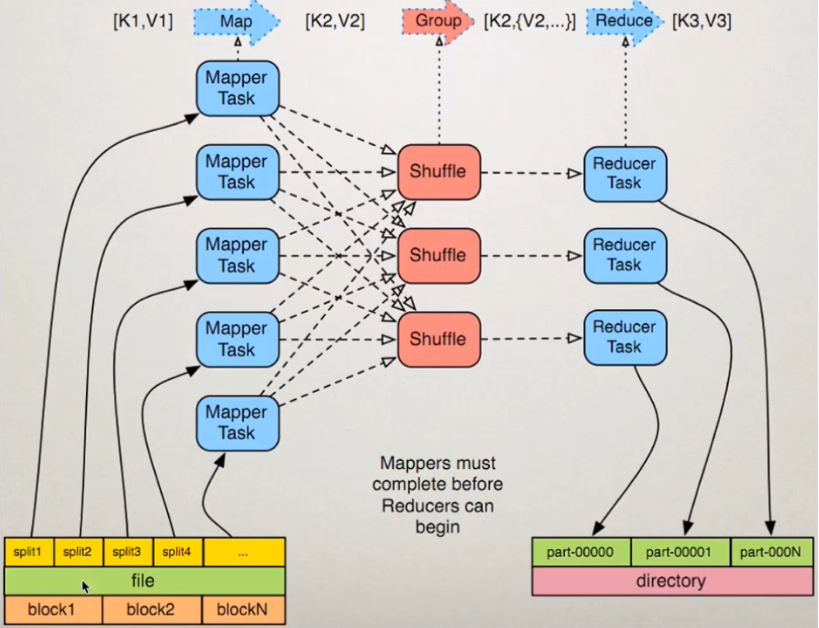
MapReduce框架原理
InputFormat数据输入
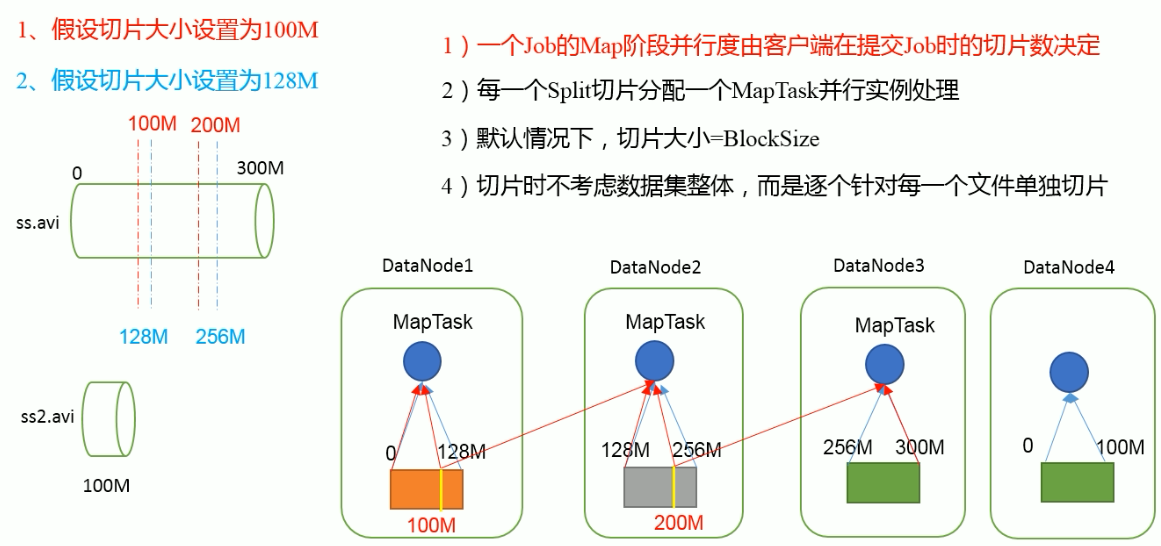
切片与MapTask并行度决定机制
-
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。
-
MapTask并行度决定机制
-
数据块:Block是HDFS物理上把数据分成一块一块
-
数据切片:数据切片只是在逻辑上对输入进行切片,并不会在磁盘上将其切分成片进行存储
![]()
-
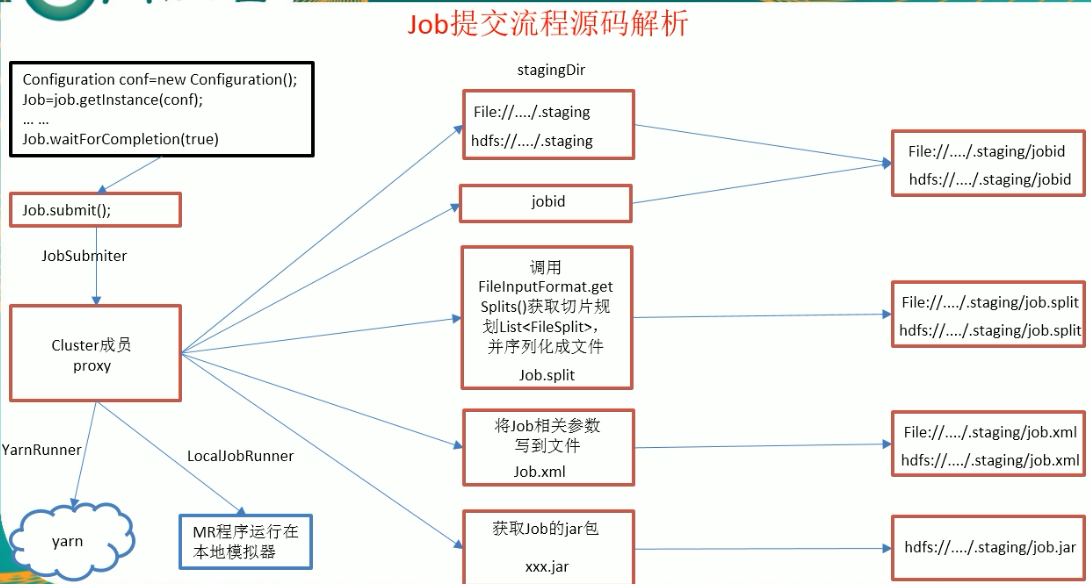
job提交流程源码解析
FileInputFormat切片源码解析(input.getSplits(job))
-
程序先找到你的数据存储的目录
-
开始遍历处理(规划切片)目录下的每一个文件
-
遍历第一个文件ss.txt(300M)
-
获取文件大小fs.sizeOf(ss.txt)
-
计算切片大小
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
-
默认情况下,切片大小=blocksize
-
开始切,形成第一个切片:ss.txt---0:128M 第二个切片ss.txt---128:256M 第三切片ss.txt---256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就切分一块切片)
-
将切片信息写到一个切片规划文件中,
-
整个切片的核心过程在getSplit()方法中完成
-
InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
-
-
提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数
FileInputFormat切片机制
-
切片机制
-
简单地按照文件的内容长度进行切片
-
切片大小,默认等于Block大小
-
切片时不考虑数据集整体,而是逐个针对每个文件单独切片
-
-
案例分析
-
输入两个文件:file1.text 320M ,file2.txt 10M
-
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.text.split1-- 0~128
file1.text.split2-- 128~256
file1.text.split3-- 256~320
file2.text.split1-- 0~10
-
-
源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blocksize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
-
切片大小设置
maxsize(切片最大值):参数如果调得比blockSize小,则会让切片变小,而且就等于配置的这个参数
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大
-
获取切片信息API
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit)context.getInputSplit();
CombineTextInputFormat切片机制
-
框架默认的TextInputFormat切片机制时对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
-
应用场景:
CombineTextInputFormat用于小分件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号