Python爬虫(一)相关介绍
 刚开始接触爬虫,必须对一些基本的知识有一些了解,知道它的大概流程以及工作方式
刚开始接触爬虫,必须对一些基本的知识有一些了解,知道它的大概流程以及工作方式
1.Python爬虫介绍
1.1 爬虫背景
当今时代的飞速发展使得信息数据显得尤为重要,所以又称之为当今时代为 "大数据时代"。而爬虫则是数据获取的一种重要手段,像当前的淘宝以及各大主流搜索引擎,都是采用网络爬虫来采集数据,同时通过对数据进行分析来猜测用户的喜好。
1.2 用Python进行爬虫的原因
其实许多语言都可以模拟浏览器向服务器发送请求并进行数据收集。比如php,尽管php在许多方面占有很多优势,但是php对于多线程、异步的支持并不是很好,而且并发处理能力相对较弱;对于Java语言来说,java的优势很明显,生态圈足够完善,但是java语言比较笨重,代码量比较大,重构成本很高;C/C++:运行效率则是非常快的,但是学习和开发成本可能比较高,写个小爬虫程序可能要花费许多时间。通过诸多比对,python作为爬虫的工具则是我们目前的不二之选。Python语法优美、开发效率好、支持的模块多,而且Python还支持异步,对异步的网络编程也十分友好,因此它非常适合写爬虫程序。
1.3 爬虫的分类
1.3.1 通用爬虫
通用网络爬虫是搜索引擎抓取系统的一个重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。它主要分为三步。
第一步:搜索引擎取成千上万个网站抓取数据
第二步:搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中页面数据与用户浏览器得到的HTML是完全一样的。
第三步:搜素引擎将爬虫抓取回来的页面,进行各种步骤的预处理:中文分词、消除噪音、索引处理……搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。展示的时候会进行排名。
搜索引擎的局限性:
-
搜索引擎抓取的是整个网页,不是具体详细的信息。
-
搜索引擎无法提供针对某个具体客户需求的结果。
1.3.2 聚焦爬虫
针对通用爬虫的这些情况,聚焦爬虫技术得以广泛使用。聚焦爬虫,是 "面向特定主题需求"的一种网络爬虫程序,它与通过搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证之抓取与需求相关的网页数据。今后所提到的,大都是聚焦爬虫。
1.3.3 Robots协议
robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。——百度百科
Robots协议也叫爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots ExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝: https://www.taobao.com/robots.txt
百度: https://www.baidu.com/robots.txt
2.请求与响应
网络通信由两部分组成:客户端请求消息****与服务器响应消息**。
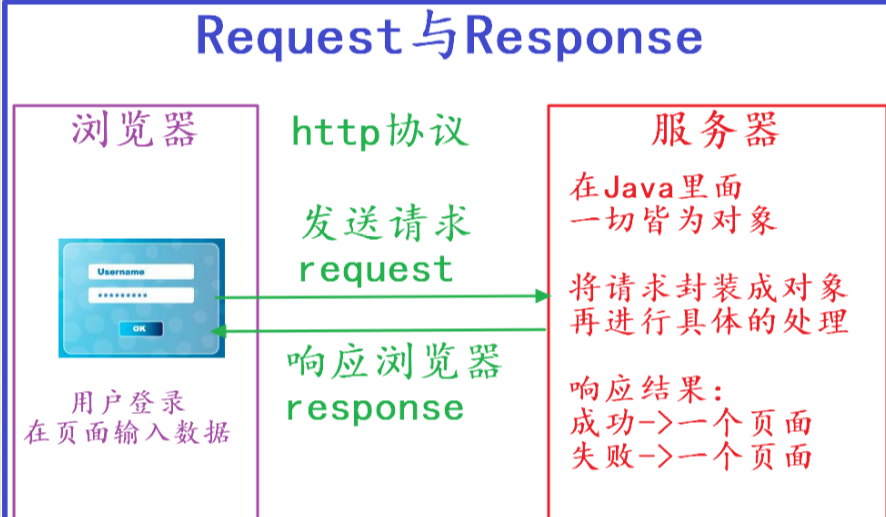
客户端就是我们常用的浏览器,而响应端则是存放文件的服务器。浏览器发送HTTP请求的过程如下:
- 当我们在浏览器输入URL https://www.baidu.com 的时候,浏览器发送一个Request请求去获取https://www.baidu.com的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
实际上我们通过学习爬虫技术爬取数据,也是向服务器发送请求,获取服务器响应数据的过程。
3. chrome开发者工具
当我们爬取不同的网站是,每个网站页面的实现方式各不相同,我们需要对每个网站都进行分析。那是否有一些通用的分析方法?我分享下自己爬取分析的“套路”。在某个网站上,分析页面以及抓取数据,我用得最多的工具是Chrome开发者工具。
Chrome开发者工具是一套内置于Google Chrome 中的 Web开发和调试工具,可用来对网站进行迭代、调试和分析。因为国内很多浏览器内核都是基于Chrome内核,所以国产浏览器也带有这个功能。例如:UC浏览器、QQ浏览器、360浏览器等。但是我们平时在日常使用时只会在搜索框中进行搜索我们想要的内容,它的许多其他功能大部分人都没用过。下面我来说明一下:
3.1 元素面板 (Elements)
通过元素(Element)面板,我们能查看到想抓取页面渲染内容所在的标签、使用什么CSS属性(例如: class="middle")等内容。例如我想要抓取我知乎主页中的动态标题,在网页页面所在处上右击鼠标,选择“检查”,或者按下键盘上的 f12 可进入Chrome开发者工具的元素面板。
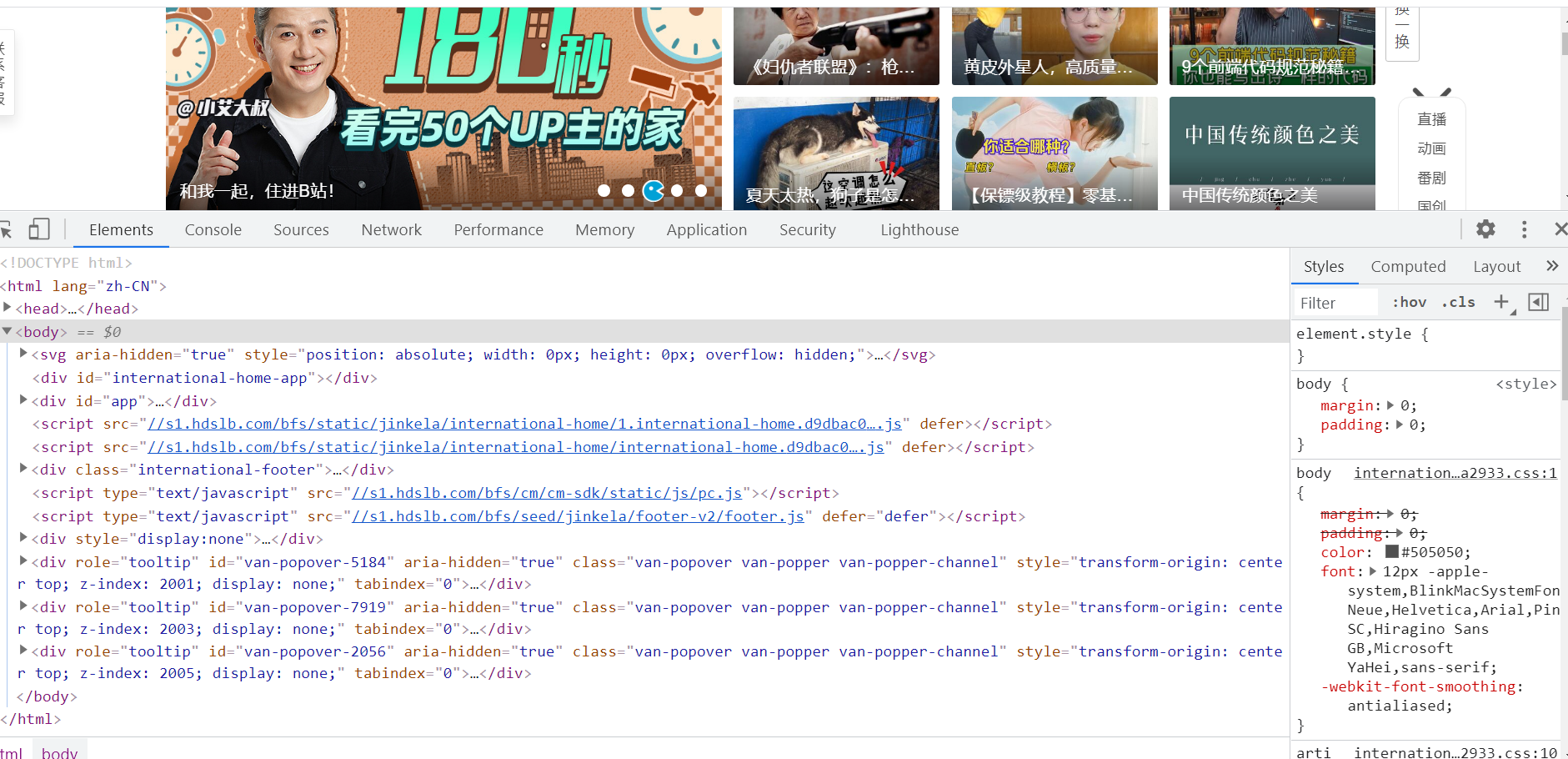
通过这种方法,我们能快速定位出页面某个DOM节点,然后可以提取出相关的解析语句。鼠标移动到节点,然后右击鼠标,选择“Copy”,能快速复制出Xpath . CSS elector 等内容解析库的解析语句。
3.1.2 控制台面板 (Console)
控制台面板(Console)是用于显示JS和DOM对象信息的单独窗口
3.1.3 资源面板 (Sourse)
在资源面板(Sourse)页面可以查看到当前网页的所有源文件
在左侧栏中可以看到源文件以树结构进行展示。
在中间栏这个地方使用来调试js代码的地方。
右侧是断点调试功能区。
3.1.4 网络面板(Network)
网络(Network)面板记录页面上每个网络操作的相关信息,包括详细的耗时数据、HTTP请求与响应标头和Cookie,等等。我们之前使用过的wireshark与这里的控制面板的功能是一样的,都是进行数据包的抓取,这就是我们通常说的抓包。在对这每个数据包打开之后还会看到,请求头、请求体、响应体以及查询参数等相关数据包的标识信息。
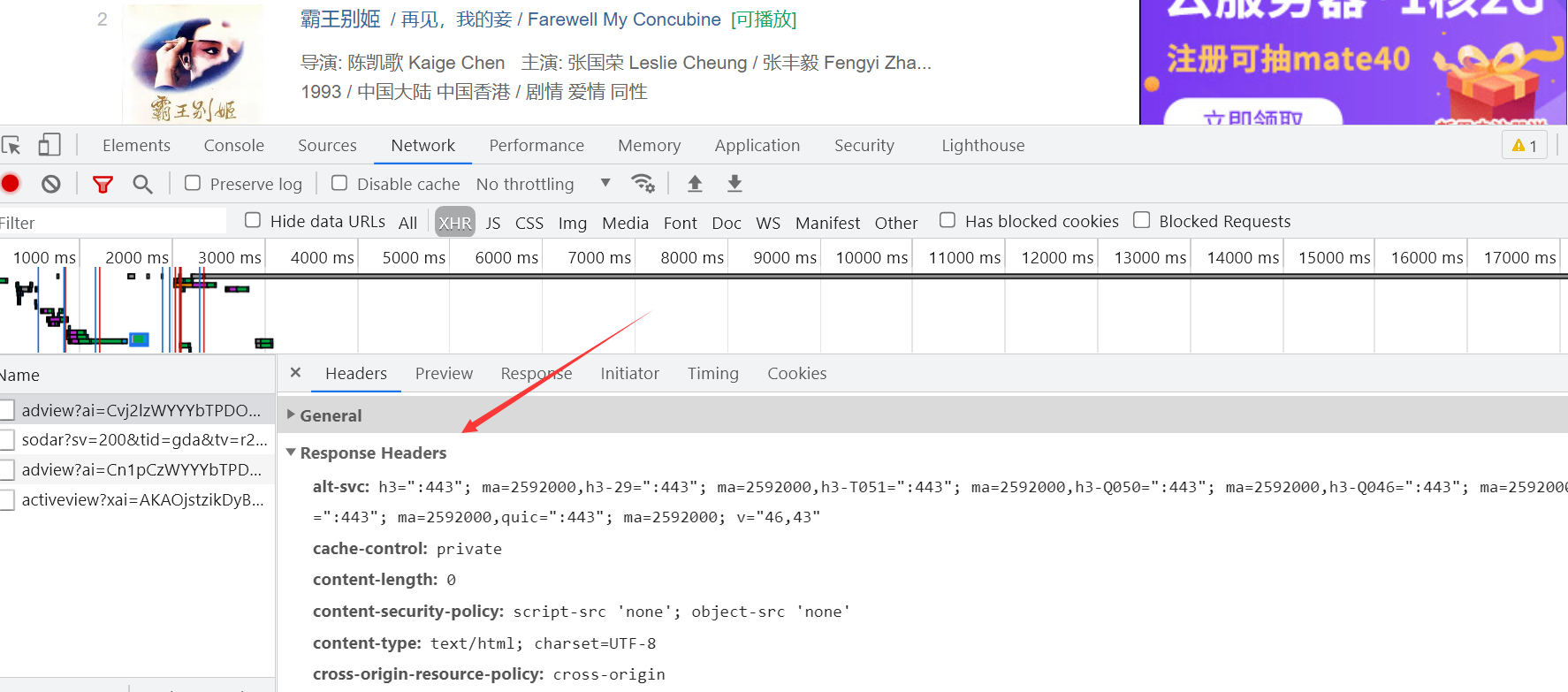
我们每次向服务器发送请求的时候,数据都会以数据包的形式发送过来,再通过前端的界面的渲染,最终以非常美观的形式展现在我们眼前。有人可能会疑惑,我们什么时候会向服务器发送请求呢?其实在我们日常使用网站时,与网站的各种数据交互大多都是在发送请求,比如说我们点击了一个视频,那么当我们点击之后起,浏览器就会向存放该视频信息的服务器发起请求,想要获得这个视频的相关资源,服务器则会将我们需要的数据信息以数据包的形式给浏览器发送过来。其他的类似于发送弹幕,刷新视频等操作都是在向服务器发送请求。如果单位时间内有大量用户向浏览器发送请求,当浏览器的带宽不足以同时响应时,则可能会发生服务器崩溃的情况,像我们平时选网课就是这种情景。
3.1.5 工具栏
工具栏的使用在日常进行数据获取时尤为重要,对处理一些常见的反爬很有效果。
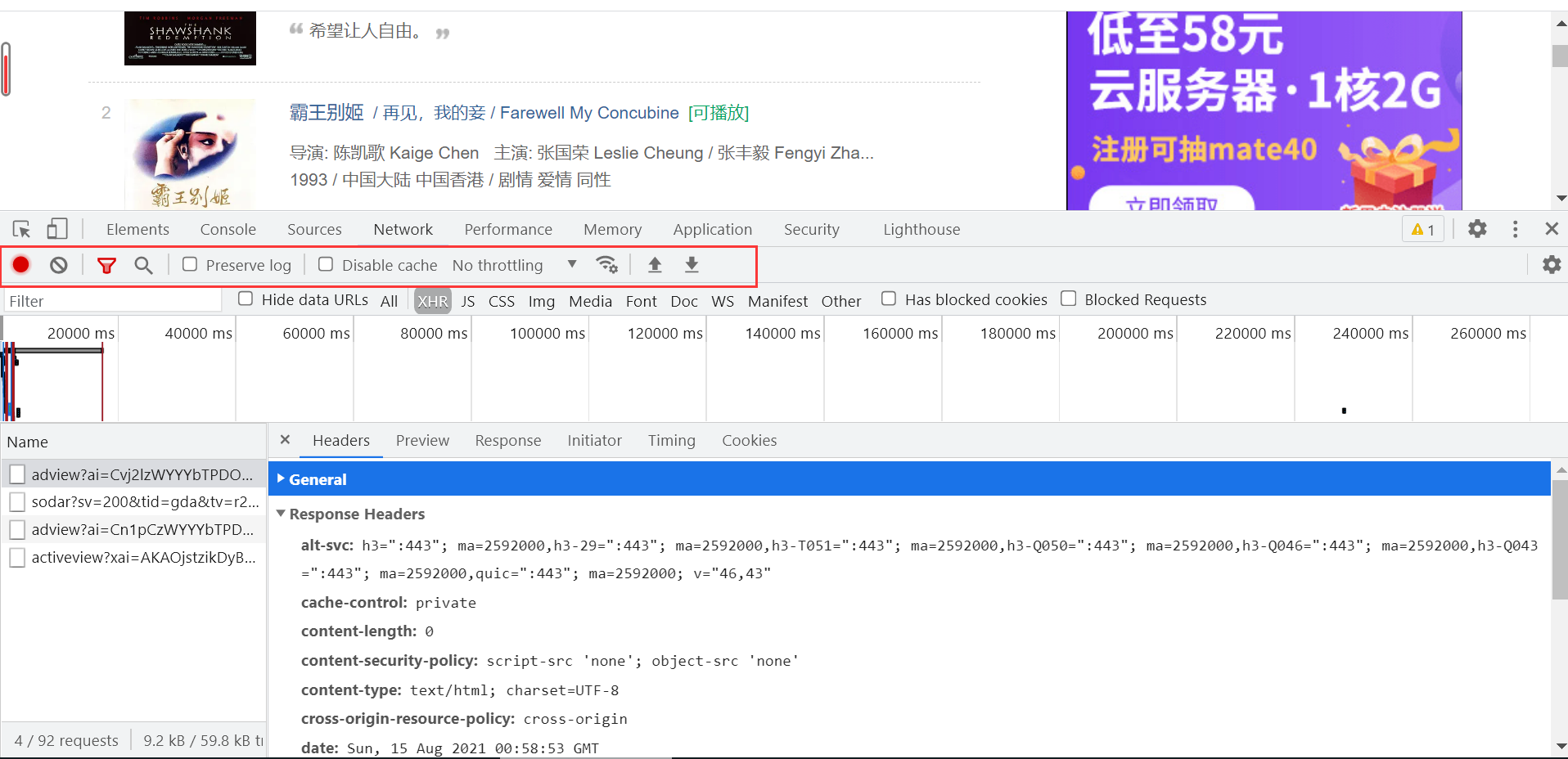
Stop recording network log

默认情况下,只要开发者工具在开启状态,会记录所有的网络请求,当然,记录都是在Network面板展示的。红色表示开启,灰色表示关闭。
clear

清空所有数据,每一次重新分析之前都要清空之前的数据
Filter

数据包过滤器。红色表示打开,蓝色表示关闭。
经常来使用它来过滤出一些HTTP请求,例如过滤出使用Ajax发起的异步请求、图片、视频等。最大的窗格叫 Requests Table,此表格会列出了检索的每一个HTTP请求。默认情况下,此表格按时间顺序排序,最早的资源在顶部。点击资源的名称可以显示更多信息。
Requests Table参数:
- all:所有请求数据(图片、视频、音频、 js代码, css代码*)
- XHR: XMLHttpRequest的缩写,是ajax技术的核心,动态加载完成经常分析的一个内容. css: css样式文件
- JS: JavaScript文件,js解密是常分析的一个页面. lmg: lmages 图片文件
- Font:字体文件(字体反扒)DoC : Document,文档内容
- ws: WebSocket,web端的socket数据通信,一般用于一些实时更新的数据
- Manifest:显示通过manifest缓存的资源。包括很多信息,如js库文件会显示文件地址、大小和
类型
Search
搜索框,只要在 ALL里面出现的过的内容,就可以被直接搜索到。常用与数据检索与JS解密
Preserve log
保留日志。当分析在多个页面跳转的内容时,一定要勾上,不然当页面发生新的跳转是,历史数据全部都会被清空。保留日志,做爬虫是一定需要勾上
Disable cache
清空JavaScript、css文件的缓存,获取最新的。
Hide data URLs
用于是否隐藏dataurl,那么什么是dataurl呢?传统的通常img标记的src属性指定了一个远程服务器的资源,浏览器针对每个外部资源需要向服务器发送一次拉取资源请求。而Data URL技术是图片数据以base64字符串格式嵌入到了页面中,和HTML融为一体。
3.2 Requests
请求头
Headers是显示HTTP请求的Headers,我们通过这个能看到请求的方式,以及携带的请求参数等。
-
General
Request url :实际请求的网址Request -
Method:请求方法,常见的有GET、POST、PUT、PATCH、DELETE。
Status Code:状态码,成功时为 200 -
Response Headers
服务器返回时设置的一些数据,例如服务器更新的cookie数据最新是在这里出现修改Requests Headers
请求体,请求不到数据的原因一般出在这里。反扒也是反扒请求体里面的数据Accept:服务器接收的数据格式(一般忽略)
Accept-Encoding:服务器接收的编码(—般忽略)Accept-Language:服务器接收的语言(─般忽略)
Connection:保持连接(一般忽略)
Cookies: cookies信息,是身份信息,爬取VIP资源是需要携带身份信息Host:请求的主机地址
User-Agent: 用户身份代理,服务器根据这个判断用户的大概信息Sec-xXx-xXx:其他信息,可能没用,可能是反扒。具体情况具体分析
**预览 **
** Preview**是请求结果的预览。一般用来查看请求到的图片,对于抓取图片网站比较给力。
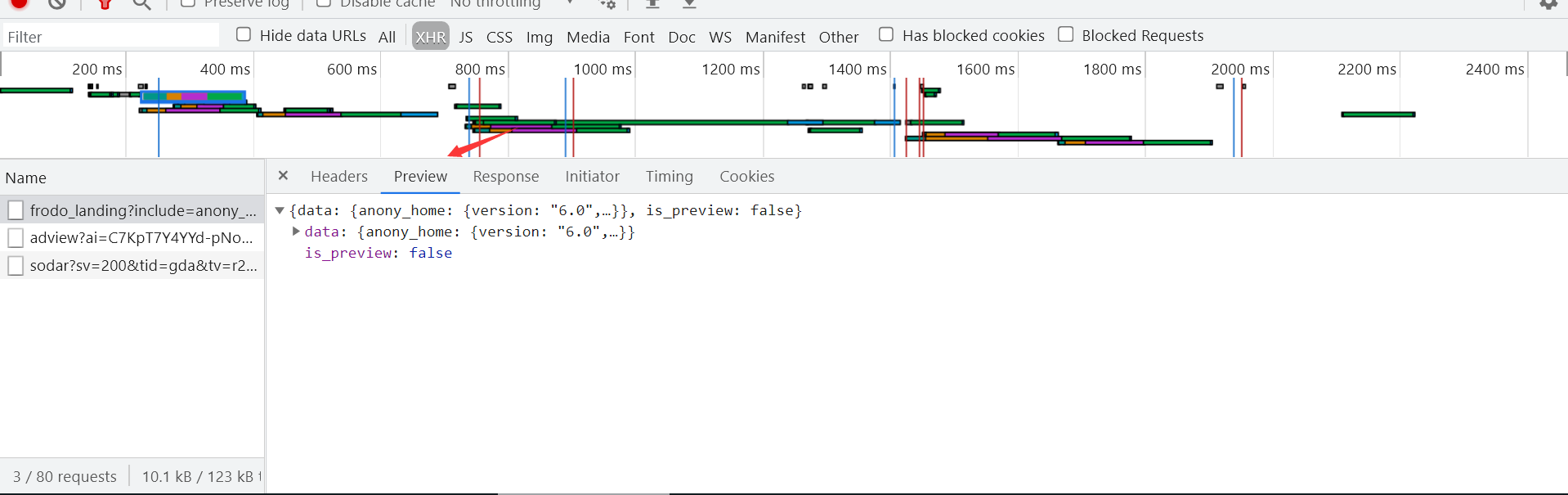
响应头
Response是请求返回的结果。一般的内容是整个网站的源代码。如果该请求是异步请求,返回的结果内容一般是Json文本数据。
此数据与浏览器展示的网页可能不一致,因为浏览器是动态加载的。
4.总结
这次我们介绍了爬虫的相关背景以及谷歌浏览器的控制面板的具体介绍,下一次我们开始正式的进行一些爬虫的相关知识点的讲解。
