
2017-2018-1 20155202 《信息安全系统设计基础》第13周学习总结
2017-2018-1 20155202 《信息安全系统设计基础》第13周学习总结
本周任务:
- 找出全书你认为最重要的一章,深入重新学习一下,要求(期末占10分):
- 完成这一章所有习题
- 详细总结本章要点
- 给你的结对学习搭档讲解你的总结并获取反馈
教材的第六章学习:
教材学习主要内容:
- 了解常见的存储技术(RAM、ROM、磁盘、固态硬盘等)
- 理解局部性原理
- 理解缓存思想
- 理解局部性原理和缓存思想在存储层次结构中的应用
- 高速缓存的原理和应用
1.++存储器系统++
-
在简单模型中,存储器系统是一个线性的字节数组,CPU能够在一个常数访问每个存储器位置。
-
虽然是一个行之有效的模型,但没有反应现代系统实际工作方式。
-
实际上,存储器系统(memory system)是一个具有不同容量,成本和访问时间的存储设备的层次结构。
-
CPU寄存器保存着最常用的数据。(0周期)
-
靠近CPU的小的,快速的高速缓存存储器(cache memory)作为一部分存储在相对慢速的主储存器(main memory,简称主存)中的数据和指令的缓冲区。(1~30周期)
-
主存暂时存放 储存在容量较大的,慢速磁盘上的数据。(50~200周期)
-
磁盘又作为存储在通过网络连接的其他机器的磁盘或磁带上数据的缓冲区。(几千万个周期)
2.存储技术
2.1 随机访问存储器
-
随机访问存储器(Random-AccessMem)分为两类:静态的和动态的。
-
静态RAM (SRAM)比动态RAM(DRAM)更快,但也贵得多。SRAM用来作为高速缓存存储器,既可以在CPU芯片上,也可以在片下。
静态存储器
SRAM将每个位存储在一个双稳态的(bitable)存储器单元里。每个单元是用一个六晶体管电路来实现的。 -
动态RAM
DRAM将每个位存储为对一个电容的充电。这个电容非常小,通常只有大约30毫微微法拉 (femtofarad)——30*10^15法拉。不过,回想一下法拉是一个非常大的计量单位。DRAM存储 器可以制造得非常密集——每个单元由一个电容和一个访问晶体管组成。 -

-
静态RAM(SRAM)比动态RAM(DRAM)快地多,也贵得多。
-
SRAM用来作为高速缓存存储器。(一般只有几兆)
-
DRAM用来作为主存以及图形系统的帧缓冲区(显存)。(一般有几G)
具体分析
SRAM
- SRAM将每个位存储在一个双稳态(bistable)存储器单元里。
- 每个存储单元用一个六晶体管电路来实现。
有这样属性,可以无限期保持在两个不同的电压配置(configuration)或状态之一。
其他任何状态都是不稳定的。如图所示
-
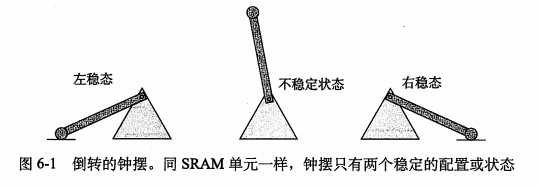
-
由于这种双稳态特性,只要有电,它就会永远保持他的值,即使有干扰。
-
例如电子噪音,来扰乱电压,当消除干扰时,电路就会恢复稳定值。
动态RAM
- DRAM将每个位存储为对一个电容充电,这个电容非常小,通常只有30*10^-15法拉。
- 因此,DRAM存储器可以造的十分密集。
- 每个单元由一个电容和一个访问晶体管组成。
- 但是,DRAM存储器对干扰非常敏感。当电容电压被扰乱后,就永远不会恢复。
- 很多原因会漏电,使得DRAM单元在10~100毫秒时间内失去电荷。幸运的是,计算机的时钟周期以纳秒衡量,这个保持时间也相当长。
- 存储器系统必须周期性地读出,然后重写来刷新存储器的每一位。
- 有些系统也使用纠错码。

两者的对比
-

-
只要有供电,SRAM就会保持不变。
-
SRAM不需要刷新
-
SRAM读取比DRAM快
-
SRAM对干扰不敏感。
-
代价是SRAM单元比DRAM单元使用更多的晶体管,因而密集度低,更贵,功耗更大。
传统的DRAM
-
DRAM芯片的单元被分为d个超单元(supell cell)
-
每一个个超单元由w个DRAM单元组成。一个d*w的DRAM总共存储了dw位信息。
-
超单元被组织成一个r行c列的长方形阵列。
-
这里rc=d,每个超单元有形如(i,j)的地址,这里i表示行,而j表示列。
-
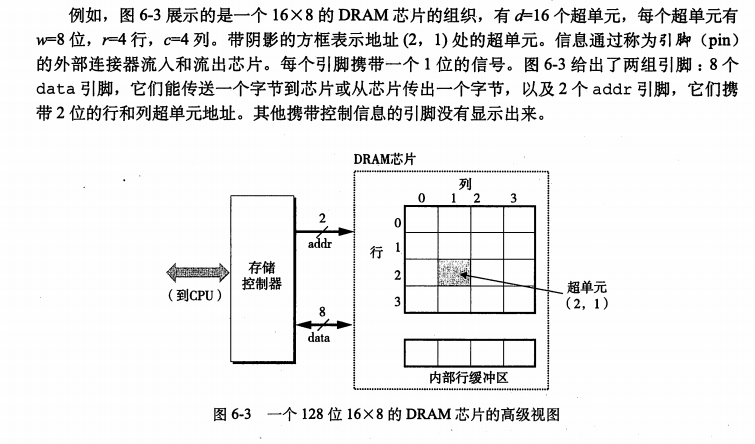
注释: 计算机构架师称为单元(cell),电路设计者称为字(word),避免混淆,取为超单元。
-每个DRAM芯片被链接到某个称为存储控制器的电路,这个电路可以一次传送w位到每个DRAM芯片或一次从每个DRAM 芯片传出w位。
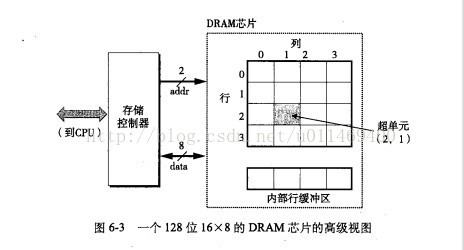
为何有16个单元,却只要2位addr?
首先发送一个行地址i给DRAM。这叫RAS(Row Acess Strobe,行访问选通脉冲)。
DRAM的响应是把第i行全部拷贝到一个内部行缓冲区。
然后发送列地址j给DRAM。这叫CAS(Column Access Strobe,列访问选通脉冲)请求。
DRAM的响应将内部行缓冲区的超单元(i,j)发送给存储控制单元。
为何设计成二维阵列,而不是线性?
一个原因是降低芯片上地址引脚的数量。原本需要2N 的引脚,只要N个就好了。
缺点是需要传输两次。增加访问时间。
- 2.2存储器模块
-
DRAM芯片包装在存储器模块(memory module)中,它是插到主板的扩展槽上。
-
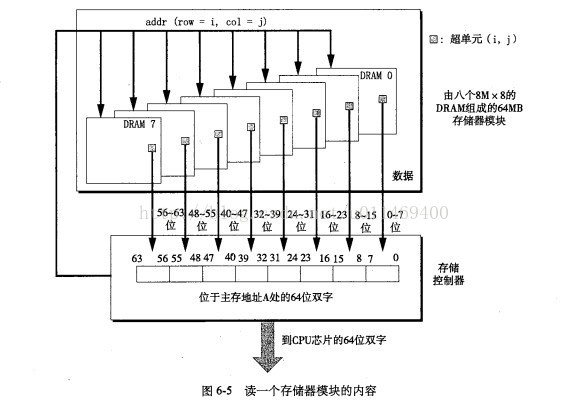
-
常见的包装包括168个引脚的双列直插存储器模块(Dual Inline Memory Module),它以64位为块传送数据到存储控制器和从存储控制器传出数据。
-
还包括72个引脚的单列直插存储器模块(Single Inline Memory Module),它以32位为块传送数据。
-
如图展示一个存储器模块的基本思想。
-
-
用对应超单元地址 (i,j)的8个超单元来表示主存字节地址A处的64位双字(此处:字=4字节)。
-
通过将多个存储器模块连接到存储控制器,能够聚合主存。在这种情况下,当控制器收到一个地址A时,控制器选择包含A的模块k,将A转换成它的(i,j)形式,并发送(i,j)到模块k
区别:
- 只要有电,SRAM就会保持不变,而DRAM需要不断刷新;
- SRAM比DRAM快;
- SRAM对光和电噪声等干扰不敏感;
增强的DRAM
- 基于传统DRAM,进行优化,改进访问速度。
- 快页模式DRAM(Fast Page Mode DRAM,FPM DRAM)。
- 传统的DRAM将超单元的一整行拷贝到它的内部缓冲区,使用一个,然后丢弃剩余的。
- FPM DRAM允许对同一行连续地访问可以直接从行缓冲区获得服务。
- 扩展输出DRAM(Extended Data Out DRAM,EDO DRAM)
- FPM DRAM的一个增强形式,它允许单独的CAS信号在时间上靠的紧密一些。
- 同步DRAM(Synchronous DRAM,SDRAM) 不懂
- 就它们与存储控制器通信使用一组显示的控制信号来说,常规的,FPM,EDO都是异步的。
- 最终效果就是SDRAM能够比那些异步的存储器更快输出超单元内容。
- 双倍数据速率同步DRAM(Double Date-rate Synchronous DRAM,DDR SDRAM)
- DDR SDRAM是对SDRAM的一种增强。
- 通过使用两个时钟沿作为控制信号,从而使DRAM 速度翻倍。

不同类型的DDR SDRAM是用提高有效带宽的很小的预取缓冲区的大小来划分的:
-
DDR(2位)
-
DDR2(4位)
-
DDR3(8位)
-
Rambus DRAM(RDRAM).这是一种私有技术,它的最大带宽比DDR SDRAMD的更高。
它用在图形系统的帧缓冲区中,VRAM的思想与FPM类似,
两个主要区别是
- VRAM的输出通过依次对内部缓冲区的整个内容进行移位得到。
- VRAM允许对存储器并行地读或写。
非易失性存储器(ROM)
-
非易失性存储器(nonvolatie memory)即使在关电后,也仍然保存他们的信息。
-
DRAM和SRAM是易失的(volatile).
-
由于历史原因,虽然ROM有的类型既可以读也可以写,但是它们整体被称为只读存储器(Read-Only Memory,ROM)。
-
ROM通过以它们能够被写的次数和对他们进行重编程的方式所用的机制区分。
-

PROM (Programmable ROM,可编程ROM)
- 只能够被编程一次。PROM的每个存储器有一个熔丝,它只能用高电流熔断一次。
- 可擦写可编程ROM(Erasable Programmable ROM,EPROM)有一个透明的石英窗口,允许光到达存储单元。
- 紫外线光照射过窗口,EPROM单元就被清除为0.
- 对EPROM编程通过使用一种把1写入EPROM的特殊设备完成。
- EPROM 可擦写次数达到1000次
电子可擦除PROM(EEPROM)
- 类似于EPROM,
- 但是它不需要一个物理上独立的编程设备,直接在印刷电路卡上编程。EEPROM能够被编程次数的数量级可以达到10^5次。
- 闪存(flash memory)也是一类非易失性存储器,基于EEPROM,已经成为一种重要的存储设备。
存储在ROM设备中的程序通常称为固件(firmware)
- 一些系统在固件中提供了少量基本的输入和输出函数。
- 例如,PC的BIOS(基本输入/输出系统)的例程。
访问主存
- 数据流通过称为总线(bus)的共享电子电路在处理器和DRAM主存之间来来回回。
- 总线事务(bus transaction):每次CPU和主存之间的数据传送都是通过一系列步骤来完成的,这些步骤称为总线事务(bus transaction).
- 读事务(read transaction): 主存把数据给CPU。
- 写事务(write transaction): CPU把数据写入主存。
- 总线是一组并行的导线,能携带地址,数据和控制信号。
- 取决于总线的设计,数据和地址信号可以使用一条,也可以使用不同的。
- 同时,两个以上的设备也能共享一根总线。
- 控制线携带的信号为同步事务,标示当前执行的事务类型。
- 示例计算机系统的配置,CPU芯片,I/O桥的芯片组,组成DRAM的存储器模块。
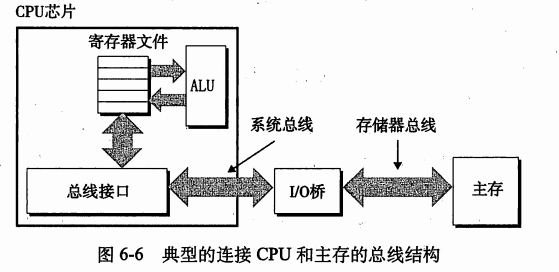
有一对总线
- 系统总线: 链接CPU和I/O桥。
- 存储器总线:链接I/O桥和主存。
I/O桥
-
将系统总线的电子信号翻译成存储器总线的电子信号。
-
I/O桥也将系统总线,存储器总线连接到I/O总线。
-
磁盘和图形卡这样I/O设备共享I/O总线。
-
关于总线设计的注释
-
总线设计是计算机系统中的一个复杂而且变化迅速的方面。不同的厂商提出了不同的总线体系结构,作为产品差异化的一种方式。
-
Intel 系统使用北桥(northbridge)和南桥(southbridge)的芯片组分别将CPU连接到存储器和I/O设备。
-
在比较老的系统,Pentium和Core 2 系统中,前端总线(Front Side Bus,FSB)将CPU连接到北桥。
-
AMD 将 FSB 替换为 超传输(HyperTransprot)互联.
-
Core i7 使用的是快速通道(QuickPath)互联。
举个例子:
movl A,%eax
这里地址A的内容被加载到寄存器%eax中,有以下步骤。
- CPU芯片上称为总线接口的电路发起总线上的读事务。
- CPU将地址A放到系统总线上。
- I/O桥将信号传递到存储器总线。
- 主存感觉到存储器总线上的地址信号,从存储器总线读地址,从DRAM取出数据字,并将数据写到存储器总线。
- I/O桥将信号翻译称系统总线信号,然后沿着系统总线传递。
- 最后,CPU感受到系统总线上的数据,从总线上读数据,拷贝到寄存器中。
如果是写事务
movl %eax,A
这里寄存器%eax的内容写入地址中中,有以下步骤。
- CPU将地址放到系统总线。存储器从存储器总线读出地址,并等待数据到达。
- CPU将数据放到系统总线。主存从存储器总线读出数据,并拷贝到DRAM中。
- 以上两个步骤是并行的。(如果数据总线和地址总线分开的话)
2.2 ++磁盘存储++
磁盘是广为应用的保存大量数据的存储设备,存储数据的数量级可以达到1TB,1PB等等,而基于RAM的 从几百到几千M字节。不过,从DRAM中读比磁盘快10万倍,从SRAM读比磁盘快100万倍。
访问磁盘:
- 在磁盘控制器接收到CPU的读命令后,它将逻辑号翻译成一个扇区地址,读该扇区的内容,然后将这些内容直接传送到主存,不需要CPU的干涉,这个过程称为直接存储器传送(Direct Memory Access, DMA),这种数据传送称为DMA传送。
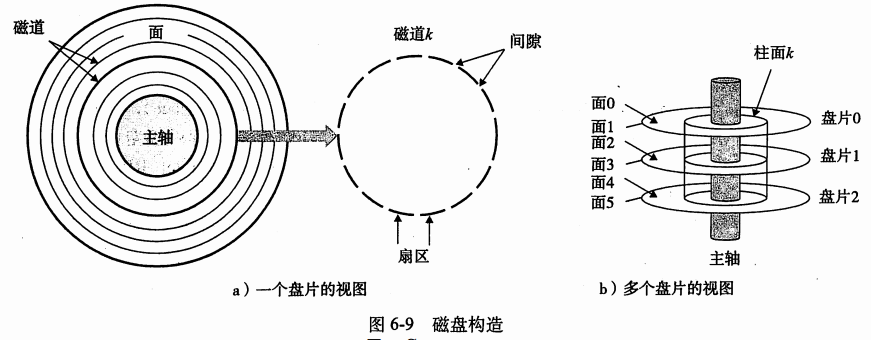
磁盘构造
- 磁盘是由盘片(platter)构成的.
- 每个盘片有两面或者称为表面(surface)。
- 盘片中央有一个可以旋转的主轴(spindle),它使得盘片以固定的旋转速率(rotational rate)旋转,通常是5400~15 000转每分钟(Revolution Per Minute,RPM)
- 磁盘通常含一个或多个这样的盘片,并封装到一个密封的容器里。
- 如图,展示了一个典型的磁盘表面的结构。

- 每个表面是由一组称为磁道(track)的同心圆组成的。
- 每个磁道被划分为一组扇区(sector)。
- 每个扇区包含相等数量的数据位(通常是512字节),这些数据编码在扇区的磁性材料中。
- 扇区之间由一些间隙(gap)分隔
- 不存储数据
- 间隙存储用来标识扇区的格式化位。
- 磁盘是由一个或多个叠放在一起的盘片组成,被封装在密封包装。
- 整个装置称为磁盘驱动器(disk drive),我们通常简称为磁盘(disk).
- 有时又叫旋转磁盘(rotating disk),使之区别基于闪存的固态硬盘(SSD)。
- SSD没有可移动的地方
- 磁盘商通常用术语柱面(cylinder)描述多个盘片。的构造 。
- 柱面是所有盘片表面上到主轴中心的距离相等的磁道集合。
例如,一个驱动器有三个盘片,六个面。那么柱面k是六个磁道k的集合。G,M, K大小依赖于上下文,磁盘和RAM中所对应的大小一般不同。
磁盘容量:
- 远古时期,磁道上的扇区是固定的,所以扇区的数目由靠内磁道能记录的扇区数决定。
- 现在通过多区记录技术。
- 在这种技术中,柱面的集合被分割为不可相交的子集合,称为记录区。
- 每个区包含一组连续的柱面。
- 一个区的每个柱面都有相同的扇区数。
- 扇区数也是由一个区最里面磁道的扇区数决定。
- 记录密度(位/英寸):磁道一英寸的段中可以放入的位数。
- 磁道密度(道/英寸):从盘片中心出发半径上一英寸的段内可以有的磁道数
- 面密度(位/平方英寸):记录密度与磁道密度的乘积。
下面给出一个容量计算公式

关于磁盘的补充讲解
- 总的来说,磁盘结构包括:盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等。一般一个磁盘就一个主轴。 一般每个扇区的大小为512B
局部性
- 一个编写良好的计算机程序常常具有良好的局部性(locality)。也就是说,它们倾向于引用 邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向性,被称为 局部性原理(principle of locality),是一个持久的概念,对硬件和软件系统的设计和性能都有着 极大的影响。
- 局部性通常有两种不同的形式:时间局部性(temporal locality)和空间局部性(spatial locality)。在一个具有良好时间局部性的程序中,被引用过一次的存储器位置很可能在不远的将来再被多次引用。在一个具有良好空间局部性的程序中,如果一个存储器位置被引用了一次,那 么程序很可能在不远的将来引用附近的一个存储器位置。
时间局部性(temporal locality)
- 被引用过一次的存储器很可能在不远的将来再被多次引用。
空间局部性(spatial locality)
一个存储位置被引用了一次,在不远的将来,很可能引用附近的位置。
现代计算机系统各个层次都利用了局部性。
- 硬件层,局部性原理允许计算机设计者引入高速缓存存储器。
- 保存最近被引用的指令和数据项,从而提高对主存的访问速度。
- 操作系统级
- 局部性原理允许使用主存作为虚拟地址空间最近被引用块的高速缓存。
- 利用主存缓存磁盘文件系统最近使用的磁盘块。
应用程序设计
- Web浏览器将最近被引用的文档放到本地磁盘上,利用的就是时间局部性。
局部性小结: 量化评价一个程序中局部性的简单原则:
- 重复引用同一个变量的程序有良好的时间局部性。
- 对于具有步长为t的引用模式的程序,步长越小,空间局部性越好。具有步长为1的引 用模式的程序有很好的空间局部性。在存储器中以大步长跳来跳去的程序空间局部性会很差。
- 对于取指令来说,循环有好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
对程序数据引用的局部性
-
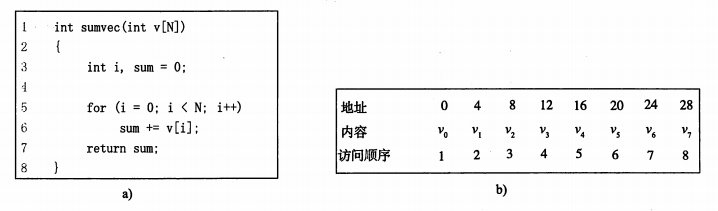
-
考虑这个简单函数的局部性。
-
sum具有良好的时间局部性
-
在一段时间内被多次访问。
-
v数组 具有良好的空间局部性。
-
一段时间内临近的元素被多次访问
-
所以该程序具有良好的局部性。
-
像sumvec这样顺序访问一个向量中每个元素的函数,称为具有步长为1的引用模式(stride-1 reference pattern)。
-
有时称步长为1的引用模式叫做顺序引用模式。
-
每隔k个访问,叫做步长为k的引用模式。
-
步长为1的引用模式是空间局部性常见和最重要的来源。
-
步长越大,空间局部性越低。
-
对于二维数组,两种不同的循环方式,空间局部性的差异十分大。
-
行优先顺序,是最好的。
取指令的局部性
- 因为程序指令被放在存储器中,CPU需要读出这些指令,所以也能取指令的局部性。
- 顺序执行:良好的空间局部性。
- for: 良好的时间局部性。
- 代码区别于数据的地方,执行后,不会被修改。
小结
- 在我们学习了高速缓存存储器以及它们是如何工作的之后,我们会介绍如何用高速缓存命中率和不命中率来量化局部性的概念。
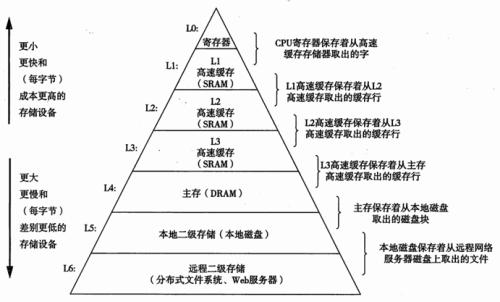
++存储器层次结构++
存储层次结构中的缓存
-
一般而言,高速缓存(cache,读作"cash")是一个小而快速的存储设备,它作为存储在更大,也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存(caching,读作"cashing")。
-
存储器层次结构的中心思想是:层次结构中的每一层都是来自较低一层的缓存。
-
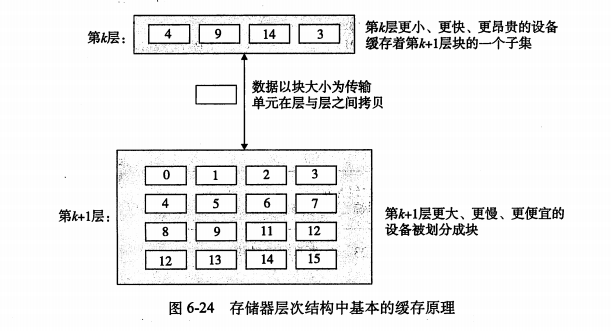
-
第k+1层被分为连续的数据对象片(chunk),称为块(block)。
-
数据总是以块作为传送单元,在存储层间。
-
传输一个字节,和传输一个块的时间上差不多
-
块使空间局部性得到发挥
-
限制性的放置策略中可能出现容量不命中
缓存管理
- 管理缓存可以是硬件,也可以是软件,可以是两者的结合。
- 寄存器文件:编译器管理.
- L1,L2,L3:内置在缓存中的硬件逻辑管理。
- DRAM,内存 由地址翻译硬件和操作系统共同管理。
- 本地磁盘: 由软件管理。
存储器层次结构概念小结
- 基于缓存的结构行之有效。
- 较慢的存储器比块的存储器便宜。
- 能很好利用局部性。
- 利用时间局部性:由于时间局部性,同一数据对象可能被多次使用,一旦一个数据对象在第一次不命中时被拷贝到缓存中,我们就会期望后面对该目标有一些的缓存命中。
- 利用空间局部性:块通常包含多个数据对象,由于空间局部性,我们希望对该块中其他对象节约的访问时间补偿不命中时的拷贝时间。
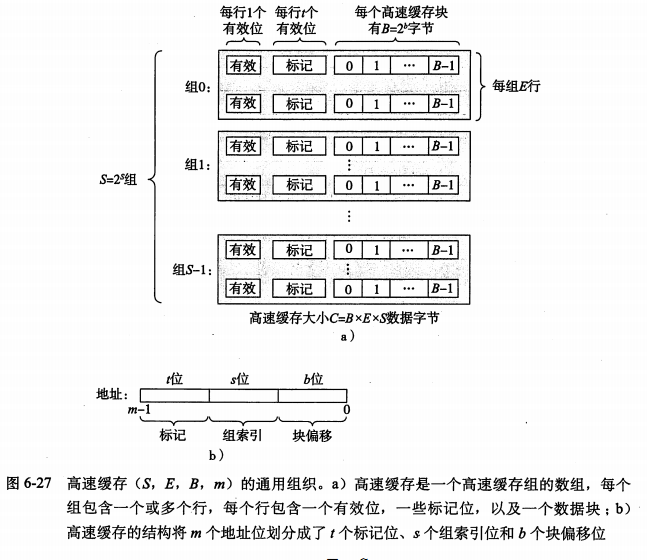
高速缓存存储器
通用的高速缓存存储器结构
- S个高速缓存组。
- 每个组有E个高速缓存行
- 每行是由一个B=2^b字节的数据块组成的,一个有效位,还有t=m-(b+s)个标记位。
- m:地址长度
- 高速缓存的结构可以用元组(S,E,B,m)描述。
- 高速缓存的大小C指所有块大小的和。标记位和有效位不包括在内。
- C=SEB;
直接映射高速缓存
根据E高速缓存分为不同的类
- E=1时叫直接映射高速缓存
- E>1时叫组相连高速缓存
- S=1时叫全相连高速缓存
抽取请求字的过程,分为三步:
- 组选择
- 行匹配
- 字抽取
不命中时
直接映射高速缓存中的冲突不命中

如果 x[i]与y[i]恰好在同一个高速缓存组。
会不停的冲突不命中。
在x和y块之间不停的抖动。
抖动描述的就是,高速缓存反复加载和驱逐相同的高速缓存块。
避免方法
- 改变x数组大小。
- 组相连高速缓存
为什么用中间的位来做索引
- 如果用高位作索引,那么组内的数据在物理地址也是相邻的。不能充分利用空间的局部性。
组相连高速缓存
- 一个1<E<C/B的高速缓存通常称为E路组相连高速缓存。
- 组相连高速缓存中的组选择
- 与之前的一样,通过组索引位。
- 组相连高速缓存中的 行匹配 和 字选`
有效位和标记位
- 组相连高速缓存中不命中时的行替换
- 随机
- 最不常用(Least-Frequently-Used,LFU)
- 频数最低
- 最近最少使用(Least-Recently-Used,LRU)
- 时间最久远
全相连高速缓存
一个全相联高速换粗(full associative cache)是由一个包含所有高速缓存行的组(即E=C/B)组成的。
全相连的组选择
只有一个组
全相连的 行匹配 和 子选择
- 和组相连一样,但是规模更大。
- 所以只适用于做小的高速缓存
- 如TLB,缓存页表项
有关写的问题
处理写命中
直写:立即将w的高速缓存块写会到紧接着的下一层。
写回:尽可能地推迟操作,只有当替换算法要驱逐时更新。
处理写不命中
-
写分配:加载相应的低一层块到高速缓存中,然后更新这个高速缓存块。
++一个真实的高速缓存层次结构的解剖++
- 高速缓存,指令,数据
- 只保存指令的高速缓存叫做i-cache
- 只保存程序数据的高速缓存叫做d-cache
- 两者都保存的高速缓存叫做unified cache
高速缓存参数的性能影响
- 不命中率(miss rate) :不命中数量/引用数量。
- 命中率(hit rate) : 1-不命中率 。
- 命中时间(hit time): 从高速缓存传送一个字到CPU的时间。
- 不命中处罚(miss penalty):由于不命中的额外时间。
- 优化高速缓存的成本和性能的折中是一项很精细的工作
高速缓存大小的影响
- 提高命中率
- 增加命中时间
- 块大小的影响
- 更好利用空间局部性,提高命中率
- 影响时间局部性
- 不命中处罚越长
- 现代系统一般在32~64字节中。
相连度影响
- 降低了高速缓存中的抖动的可能性
- 好的替换策略能大大增强效率(提高命中率)。
- 价格更昂贵,命中时间更长,不命中处罚更多。
- 所以是处罚时间((1-命中率)*不命中处罚)和命中时间的折中。
- 不命中处罚越高用这个。让处罚时间更少
- 命中率提高
- 不命中处罚增长忽略不计。
写策略影响
- 层次越往下,越用写回。
++综合++:高速缓存对程序性能的影响
存储器山
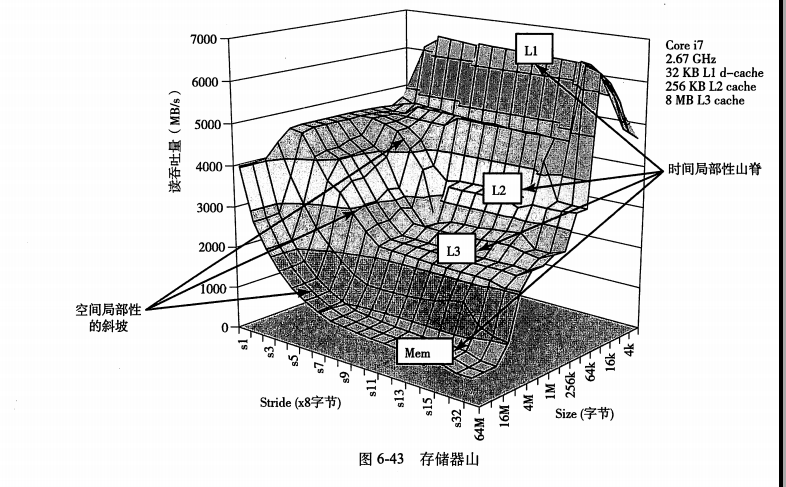
- 一个程序从存储系统中读数据的速率称为读吞吐量(read throughput),或者有时称为读带宽(rand bandwidth)。
- 通过读吞吐量来分析存储器性能。
- 存储器山是一种综合研究存储器层次结构的工具。它反映了存储器层次结构中不同层次的带宽。也反映了具有不同的时间局部性与空间局部性的程序的性能。通过分析存储器山的数据,还可以看出存储器系统的部分硬件参数。
重新排列循环以提高空间局部性

- 考虑n*n的矩阵乘法问题。
- C[i][j]+=A[i][k]*B[k][j]
- i,j,k三层循环的顺序无所谓,都能得到正确的结果。
- 但是时间差异却十分大。
代码如下:
-

-
显然能看出kij版本和ikj版本都十分优秀
-
tisp:r=A[i][k] 在i,k循环或k,i循环下,其实差不了多少,因为n次循环才调用一次。
-
也因此上图左右相邻的两个版本的复杂度都会差不多。
-
网络旁注;使用分块来提高空间局部性
-
就是类似将数据结构尽量设计成块。能提高效率,但会使得代码更难懂。它更适合优化编译器或者频繁执行的库函数。
在程序中利用局部性
- 精力注重内循环
- 步长为1,
- 一旦读入一个对象,就尽可能多使用它。
小结
- 基本存储技术包括RAM,ROM和磁盘。
RAM有两个类型
- SRAM
- DRAM
SDRAM
DDR
程序通过编写良好的局部性代码利用好缓存。
代码托管
课后习题及其解答:
有关高速缓存的说法正确的是()
A. 高速缓存的容量可以用C=SEB来计算
B. 高速缓存容量为2048,高速缓存结构为( 32 ,8,8,32)
C. 直接映射高速缓存要:组选择、行匹配、字抽取
D. 当程序访问大小为2的幂的数组时,直接映射高带缓存中常发生冲突不命中
- 错选:a,b【答案】A C D
The following table gives the parameters for a number of di erent caches. For each cache, determine the number of cache sets (S), tag bits (t), set index bits (s), and block o set bits (b)
A. 第三行S为1
B. 第一行t为24
C. 第二行b为5
D. 第三行s的值为0
-
错选:a,b 【答案】A C D
-
【解析】p427
下面说法正确的是()
A. CPU通过内存映射I/O向I/O设备发命令
B. DMA传送不需要CPU的干涉
C. SSD是一种基于闪存或Flash的存储技术
D. 逻辑磁盘块的逻辑块号可以翻译成一个(盘面,磁道,扇区 )三元组。
-
错选:a,b 【答案】A B C D
-
【解析】p413 411
有关磁盘操作,说法正确的是()
A. 对磁盘扇区的访问时间包括三个部分中,传送时间最小。
B. 磁盘以字节为单位读写数据
C. 磁盘以扇区为单位读写数据
D. 读写头总处于同一柱面
-
错选:a,b,c 【答案】A C
-
【解析】p409
计算这样一个磁盘的容量,它有2个盘片,10 000个柱面,每条磁道平均有400个扇区,而每个扇区有512个字节。





结对
- 结对学习搭档讲解你的总结并获取反馈
- 我结对的搭档:吕宇轩 20155239
他的问题很简单,是汇编的问题 :
- 我结对的搭档:吕宇轩 20155239
问题1:汇编后的文件嘈杂难懂?
问题1解决方案:
- gcc -S 产生的汇编中可以把 以”.“开始的语句都删除了再阅读
- RET指令是子程序的最后一条指令,即恢复断点,返回主程序。 没有要求RET指令非要和哪一条指令要配对使用。
RET是子程序返回指令,放在子程序的结尾,当子程序执行完后,靠该指令返回主程序。就是return, 返回. 用于子程序的返回 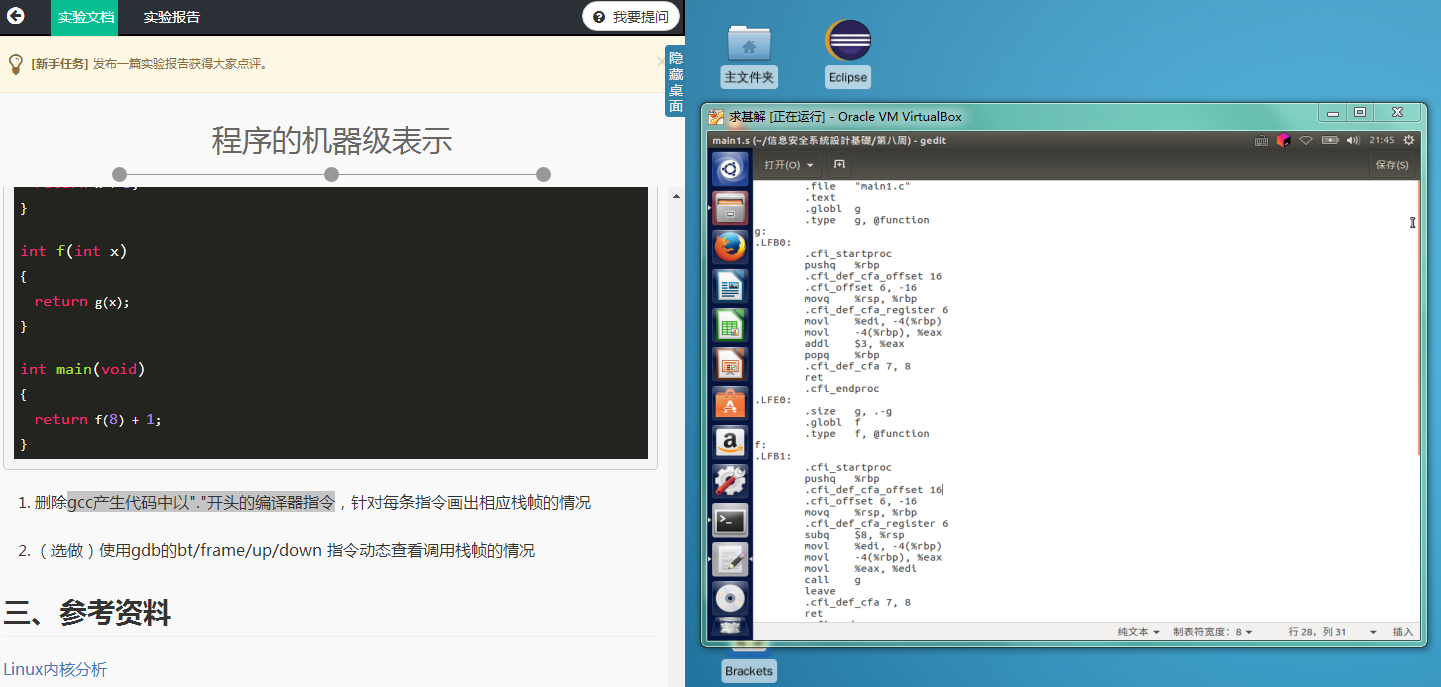
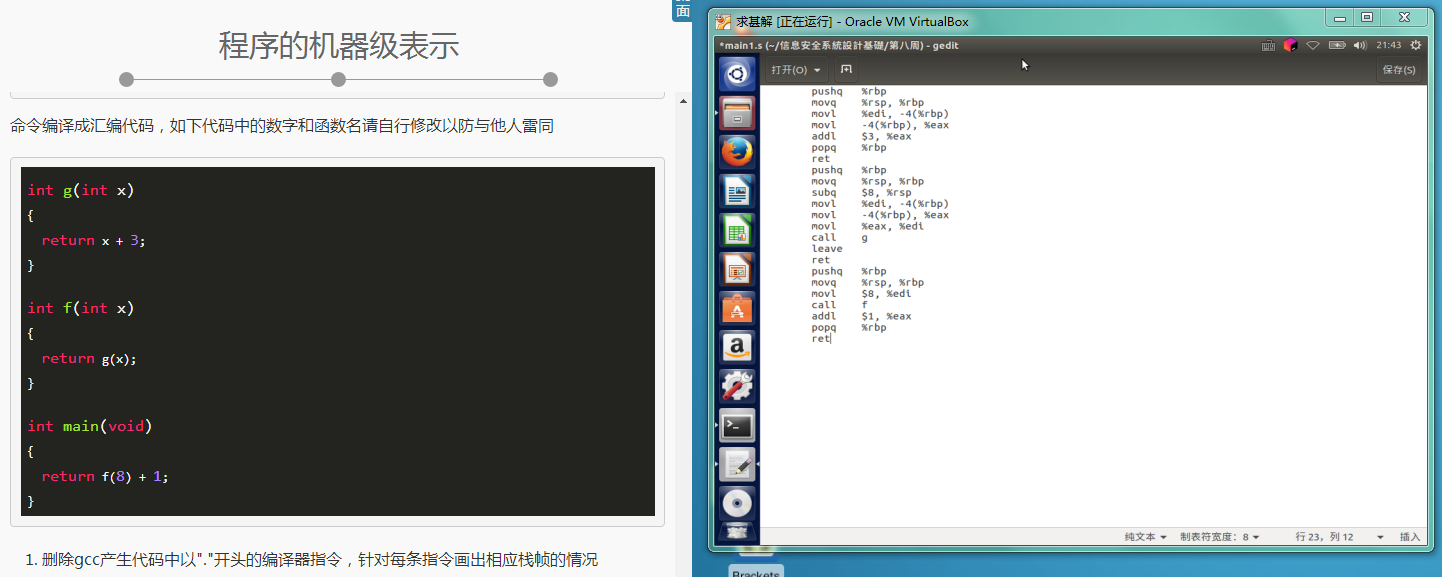
问题2:cmp与sub有什么区别?
- 问题2解决方案:查看课本练习上学期学习的汇编cmp与sub类似,都是从目的操作数减去源操作数,但sub会将运算结果送至目的操作数,而cmp不会送至目的操作数,cmp用于检测标识符
问题3: 上次实验如何在Ubuntu中实现对实验二中的“wc服务器”通过混合密码系统进行防护
解答:
-
服务器:
接收客户端发来的会话密钥密文
利用预先生成的RSA公钥解密得到会话密钥
接收客户端发来的密文
用会话密钥解密密文得到明文
将明文存入文件
调用mywc()函数计算文件中单词数
客户端:
利用c语言中的rand()函数生成32字节的伪随机数数组构成会话密钥
用预先生成的RSA私钥加密会话密钥
将会话密钥发送给服务器
用会话密钥加密指定文件
将密文发送给服务器
调用mywc()函数计算文件中单词数
- 头文件:
#include <openssl/ssl.h>
#include <openssl/err.h>
- SSL库初始化
SSL_library_init();
- 载入所有 SSL 算法
OpenSSL_add_all_algorithms();
- 载入所有 SSL 错误消息
SSL_load_error_strings();
- 产生一个 SSL_CTX
ctx = SSL_CTX_new(SSLv23_server_method());
if (ctx == NULL) {
ERR_print_errors_fp(stdout);
exit(1);}
- 载入用户的数字证书
if (SSL_CTX_use_certificate_file(ctx, argv[3], SSL_FILETYPE_PEM) <= 0) {
ERR_print_errors_fp(stdout);
exit(1);
}
- 载入用户私钥
if (SSL_CTX_use_PrivateKey_file(ctx, argv[4], SSL_FILETYPE_PEM) <= 0){
ERR_print_errors_fp(stdout);
exit(1);
}
if (!SSL_CTX_check_private_key(ctx)) {
ERR_print_errors_fp(stdout);
exit(1);
}
- 基于 ctx 产生一个新的 SSL,并将连接用户的 socket 加入到 SSL
ssl = SSL_new(ctx);
SSL_set_fd(ssl, new_server_socket_fd);
- 建立 SSL 连接
if (SSL_accept(ssl) == -1) {
perror("accept");
close(new_fd);
break;
}
- SSL数据传输
int len = SSL_read(ssl, buffer, MAXBUF);
if (len > 0)
printf("接收消息成功:'%s',共%d个字节的数据\n", buffer, len);
else
printf("消息接收失败!错误代码是%d,错误信息是'%s'\n",errno, strerror(errno));
- 客户端与服务器传输完数据后,关闭 SSL 连接,释放 SSL
SSL_shutdown(ssl);
SSL_free(ssl);
释放 CTX
SSL_CTX_free(ctx);
对telent和server 进行编译:

实验结果: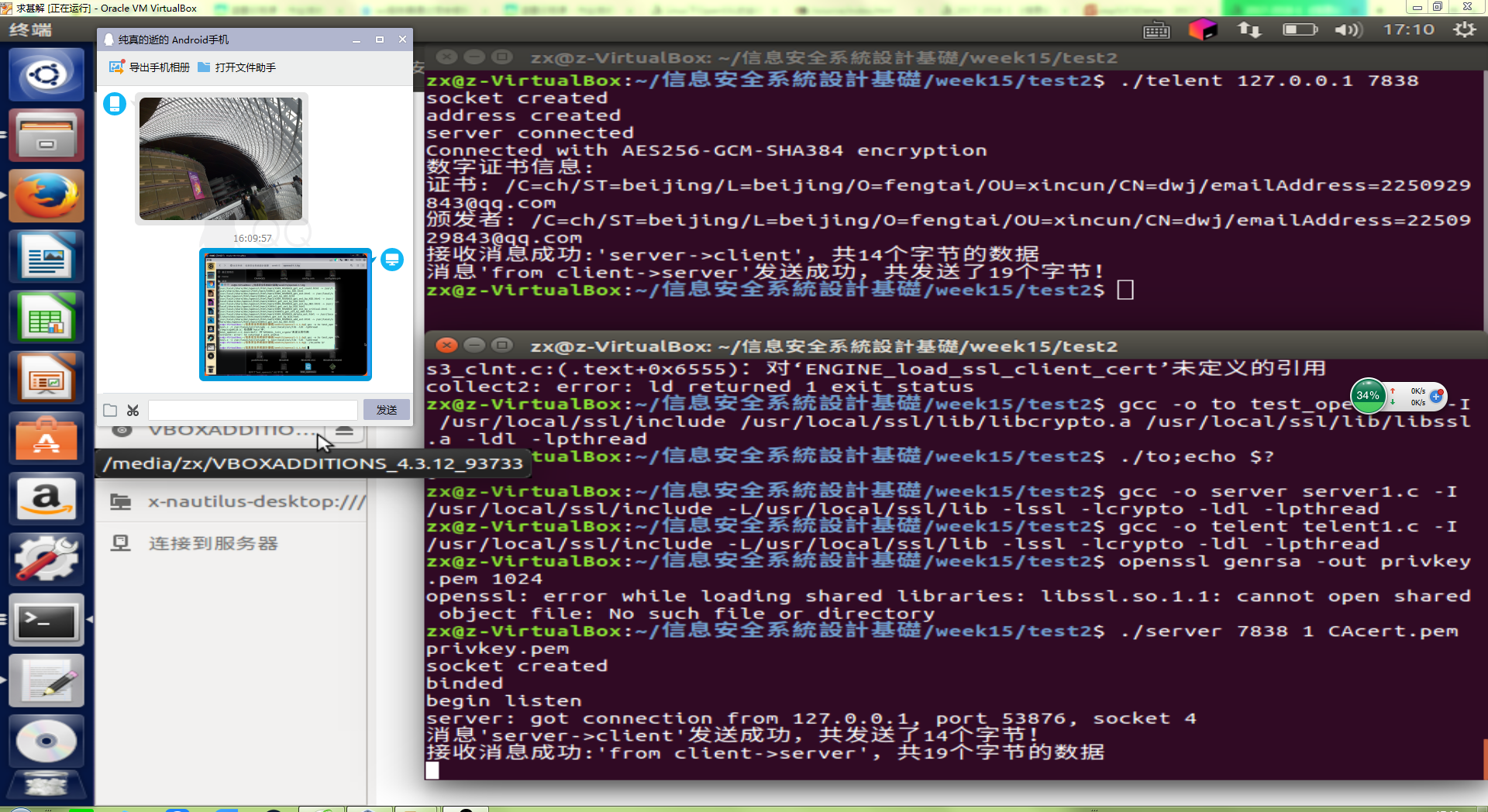
代码托管

产品代码:
- 服务器server1.c:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <openssl/evp.h>
#define MAXBUF 1024
int main(int argc, char **argv)
{
int sockfd, new_fd;
socklen_t len;
struct sockaddr_in my_addr, their_addr;
unsigned int myport, lisnum;
char buf[MAXBUF + 1];
SSL_CTX *ctx;
if (argv[1])
myport = atoi(argv[1]);
else
myport = 7838;
if (argv[2])
lisnum = atoi(argv[2]);
else
lisnum = 2;
/* SSL 库初始化 */
SSL_library_init();
/* 载入所有 SSL 算法 */
OpenSSL_add_all_algorithms();
/* 载入所有 SSL 错误消息 */
SSL_load_error_strings();
/* 以 SSL V2 和 V3 标准兼容方式产生一个 SSL_CTX ,即 SSL Content Text */
ctx = SSL_CTX_new(SSLv23_server_method());
/* 也可以用 SSLv2_server_method() 或 SSLv3_server_method() 单独表示 V2 或 V3标准 */
if (ctx == NULL) {
ERR_print_errors_fp(stdout);
exit(1);
}
/* 载入用户的数字证书, 此证书用来发送给客户端。 证书里包含有公钥 */
if (SSL_CTX_use_certificate_file(ctx, argv[3], SSL_FILETYPE_PEM) <= 0) {
ERR_print_errors_fp(stdout);
exit(1);
}
/* 载入用户私钥 */
if (SSL_CTX_use_PrivateKey_file(ctx, argv[4], SSL_FILETYPE_PEM) <= 0){
ERR_print_errors_fp(stdout);
exit(1);
}
/* 检查用户私钥是否正确 */
if (!SSL_CTX_check_private_key(ctx)) {
ERR_print_errors_fp(stdout);
exit(1);
}
/* 开启一个 socket 监听 */
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1) {
perror("socket");
exit(1);
} else
printf("socket created\n");
bzero(&my_addr, sizeof(my_addr));
my_addr.sin_family = PF_INET;
my_addr.sin_port = htons(myport);
my_addr.sin_addr.s_addr = INADDR_ANY;
if (bind(sockfd, (struct sockaddr *) &my_addr, sizeof(struct sockaddr))
== -1) {
perror("bind");
exit(1);
} else
printf("binded\n");
if (listen(sockfd, lisnum) == -1) {
perror("listen");
exit(1);
} else
printf("begin listen\n");
while (1) {
SSL *ssl;
len = sizeof(struct sockaddr);
/* 等待客户端连上来 */
if ((new_fd =
accept(sockfd, (struct sockaddr *) &their_addr,
&len)) == -1) {
perror("accept");
exit(errno);
} else
printf("server: got connection from %s, port %d, socket %d\n",
inet_ntoa(their_addr.sin_addr),
ntohs(their_addr.sin_port), new_fd);
/* 基于 ctx 产生一个新的 SSL */
ssl = SSL_new(ctx);
/* 将连接用户的 socket 加入到 SSL */
SSL_set_fd(ssl, new_fd);
/* 建立 SSL 连接 */
if (SSL_accept(ssl) == -1) {
perror("accept");
close(new_fd);
break;
}
/* 开始处理每个新连接上的数据收发 */
bzero(buf, MAXBUF + 1);
strcpy(buf, "server->client");
/* 发消息给客户端 */
len = SSL_write(ssl, buf, strlen(buf));
if (len <= 0) {
printf
("消息'%s'发送失败!错误代码是%d,错误信息是'%s'\n",
buf, errno, strerror(errno));
goto finish;
} else
printf("消息'%s'发送成功,共发送了%d个字节!\n",
buf, len);
bzero(buf, MAXBUF + 1);
/* 接收客户端的消息 */
len = SSL_read(ssl, buf, MAXBUF);
if (len > 0)
printf("接收消息成功:'%s',共%d个字节的数据\n",
buf, len);
else
printf
("消息接收失败!错误代码是%d,错误信息是'%s'\n",
errno, strerror(errno));
/* 处理每个新连接上的数据收发结束 */
finish:
/* 关闭 SSL 连接 */
SSL_shutdown(ssl);
/* 释放 SSL */
SSL_free(ssl);
/* 关闭 socket */
close(new_fd);
}
/* 关闭监听的 socket */
close(sockfd);
/* 释放 CTX */
SSL_CTX_free(ctx);
return 0;
}
-
telent1.c:
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <sys/socket.h>
#include <resolv.h>
#include <stdlib.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <openssl/evp.h>
#define MAXBUF 1024
void ShowCerts(SSL * ssl)
{
X509 *cert;
char *line;
cert = SSL_get_peer_certificate(ssl);
if (cert != NULL) {
printf("数字证书信息:\n");
line = X509_NAME_oneline(X509_get_subject_name(cert), 0, 0);
printf("证书: %s\n", line);
free(line);
line = X509_NAME_oneline(X509_get_issuer_name(cert), 0, 0);
printf("颁发者: %s\n", line);
free(line);
X509_free(cert);
} else
printf("无证书信息!\n");
}
int main(int argc, char **argv)
{
int sockfd, len;
struct sockaddr_in dest;
char buffer[MAXBUF + 1];
SSL_CTX *ctx;
SSL *ssl;
if (argc != 3) {
printf("参数格式错误!正确用法如下:\n\t\t%s IP地址 端口\n\t比如:\t%s 127.0.0.1 80\n此程序用来从某个"
"IP 地址的服务器某个端口接收最多 MAXBUF 个字节的消息",
argv[0], argv[0]);
exit(0);
}
/* SSL 库初始化,参看 ssl-server.c 代码 */
SSL_library_init();
OpenSSL_add_all_algorithms();
SSL_load_error_strings();
ctx = SSL_CTX_new(SSLv23_client_method());
if (ctx == NULL) {
ERR_print_errors_fp(stdout);
exit(1);
}
/* 创建一个 socket 用于 tcp 通信 */
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("Socket");
exit(errno);
}
printf("socket created\n");
/* 初始化服务器端(对方)的地址和端口信息 */
bzero(&dest, sizeof(dest));
dest.sin_family = AF_INET;
dest.sin_port = htons(atoi(argv[2]));
if (inet_aton(argv[1], (struct in_addr *) &dest.sin_addr.s_addr) == 0) {
perror(argv[1]);
exit(errno);
}
printf("address created\n");
/* 连接服务器 */
if (connect(sockfd, (struct sockaddr *) &dest, sizeof(dest)) != 0) {
perror("Connect ");
exit(errno);
}
printf("server connected\n");
/* 基于 ctx 产生一个新的 SSL */
ssl = SSL_new(ctx);
SSL_set_fd(ssl, sockfd);
/* 建立 SSL 连接 */
if (SSL_connect(ssl) == -1)
ERR_print_errors_fp(stderr);
else {
printf("Connected with %s encryption\n", SSL_get_cipher(ssl));
ShowCerts(ssl);
}
/* 接收对方发过来的消息,最多接收 MAXBUF 个字节 */
bzero(buffer, MAXBUF + 1);
/* 接收服务器来的消息 */
len = SSL_read(ssl, buffer, MAXBUF);
if (len > 0)
printf("接收消息成功:'%s',共%d个字节的数据\n",
buffer, len);
else {
printf
("消息接收失败!错误代码是%d,错误信息是'%s'\n",
errno, strerror(errno));
goto finish;
}
bzero(buffer, MAXBUF + 1);
strcpy(buffer, "from client->server");
/* 发消息给服务器 */
len = SSL_write(ssl, buffer, strlen(buffer));
if (len < 0)
printf
("消息'%s'发送失败!错误代码是%d,错误信息是'%s'\n",
buffer, errno, strerror(errno));
else
printf("消息'%s'发送成功,共发送了%d个字节!\n",
buffer, len);
finish:
/* 关闭连接 */
SSL_shutdown(ssl);
SSL_free(ssl);
close(sockfd);
SSL_CTX_free(ctx);
return 0;
}
其他(感悟、思考等,可选)
学习了存储器层次结构让我知道了原来硬盘是那么脆弱,结构如此复杂,怪不得电脑要轻拿轻放,cpu通过I/O总线访问主存和硬盘使我对系统内部程序和硬件之间的交互学习理解又加深了一步。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第13周 | 270/200 | 3/2 | 33/20 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:33小时
-
- 实际学习时间:20小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

