爬虫介绍,request模块介绍,request发送get请求,request携带参数,url编码解码,携带请求头,发送post请求,携带数据,自动登录,携带cookie的两种方式,requests.session的使用,补充post请求携带数据编码格式, 响应Response对象
爬虫介绍
"""本质原理"""
现在所有的软件原理大部分都是基于Http请求发送和获取数据的
模拟发送http请求,从别人的服务端获取数据
绕过反扒:不同程序反扒措施不一样,比较复杂
"""爬虫原理"""
发送http请求(requests,selenium)--->第三方服务端--->服务端响应的数据解析出想要的数据(selenium,bs4)--->入库(文件,excel,mysql,mongodb...)
"""专业的爬虫框架"""
scrapy
"""爬出是否合法"""
我们看到的数据才可以爬取下来
我们在做爬虫的时候,需要遵循爬虫协议
"""爬虫协议"""
每个网站根路径下都有robots.txt,这个文件规定了,该网站,哪些可以爬取,哪些不能爬
"""百度:大爬虫"""
百度搜索框中搜索内容,回车,返回的数据,是百度数据库中的数据
百度一刻不停的在互联网中爬取各个页面,链接地址--->爬完存到自己的数据库
当我们点击的时候跳转到真正的地址上去
核心:搜索,海量数据中搜索出想要的数据
seo:做优化,免费的搜索,排名靠前
sem:花钱买关键字
requests模块发送get请求
模拟发送http请求的模块:requests.,不仅爬虫能够用到他,他还可以做调用第三方接口
长链接转短链接:https://www.cnblogs.com/zx0524/p/16735995.html
'''安装:'''
pip install requests
'''本质:'''
本质就是封装了内置模块urlib3,requests使用起来简单一点,但是也有人会使用urlib3
'''例子'''
import requests
res = requests.get('https://www.cnblogs.com/zx0524/p/16735995.html')
print(res.text)
get请求携带参数
'''发送get请求携带数据'''
1.在地址栏后面拼接
res = requests.get('https://www.cnblogs.com/zx0524/p/16735995.html?name=wmn&age=19')
print(res.url)
2.使用params携带参数
res = requests.get('https://www.cnblogs.com/zx0524/p/16735995.html',params={
'name':'wmn',
'age':19
})
print(res.url)

3.使用URL编码和解码
from urllib.parse import quote,unquote
from urllib import parse
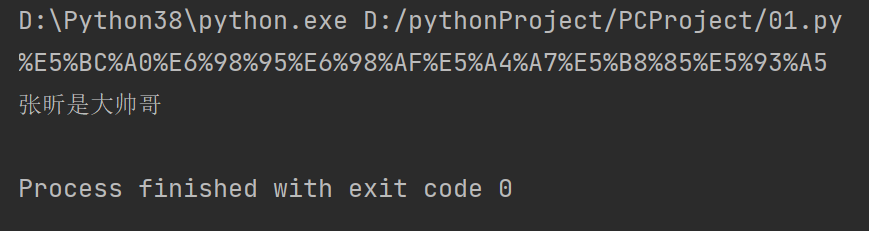
res = parse.quote('张昕是大帅哥')
print(res)
res=parse.unquote('%E5%BC%A0%E6%98%95%E6%98%AF%E5%A4%A7%E5%B8%85%E5%93%A5')
print(res)
携带请求头
# 如果没有携带请求头中的客户端类型,网站可能会做出反扒
import requests
res = requests.get('https://dig.chouti.com/')
print(res.text)
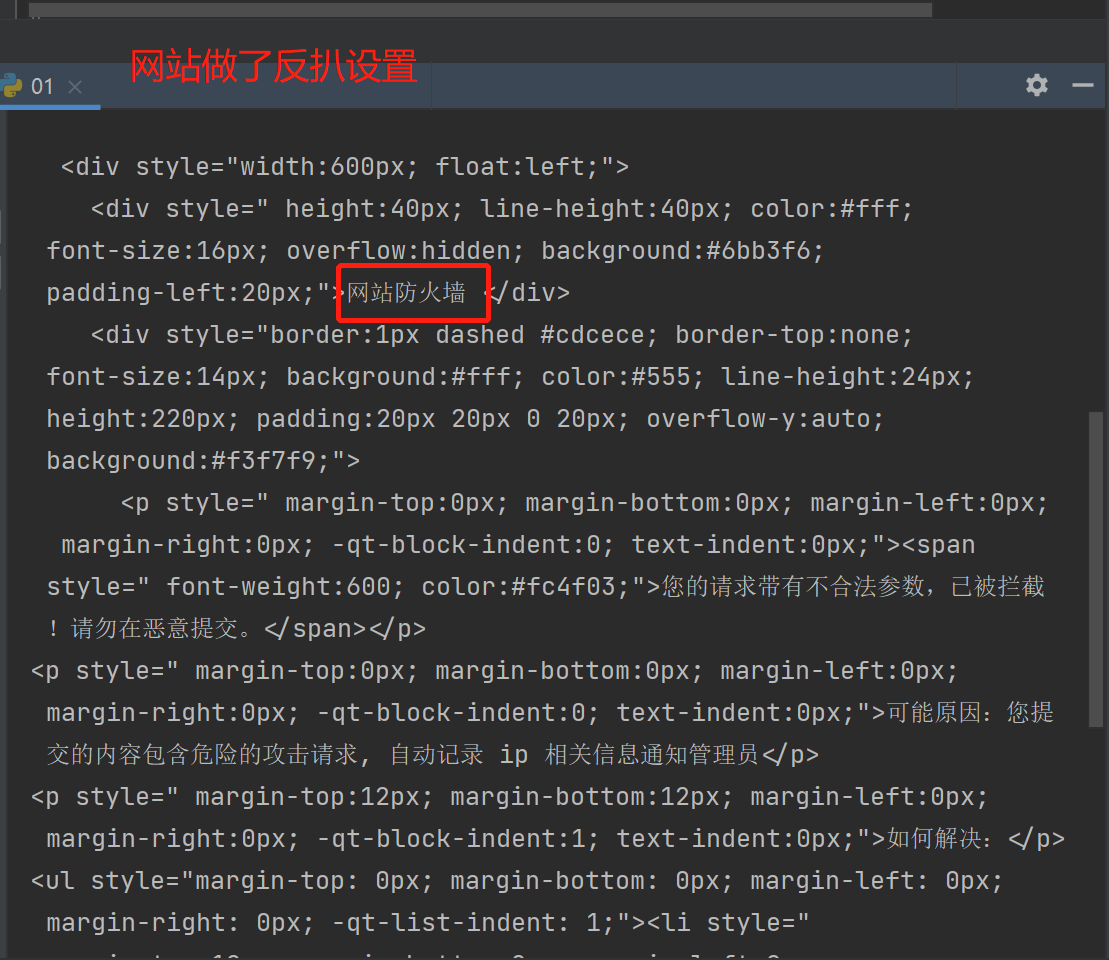
客户端类型:不允许非浏览器访问
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
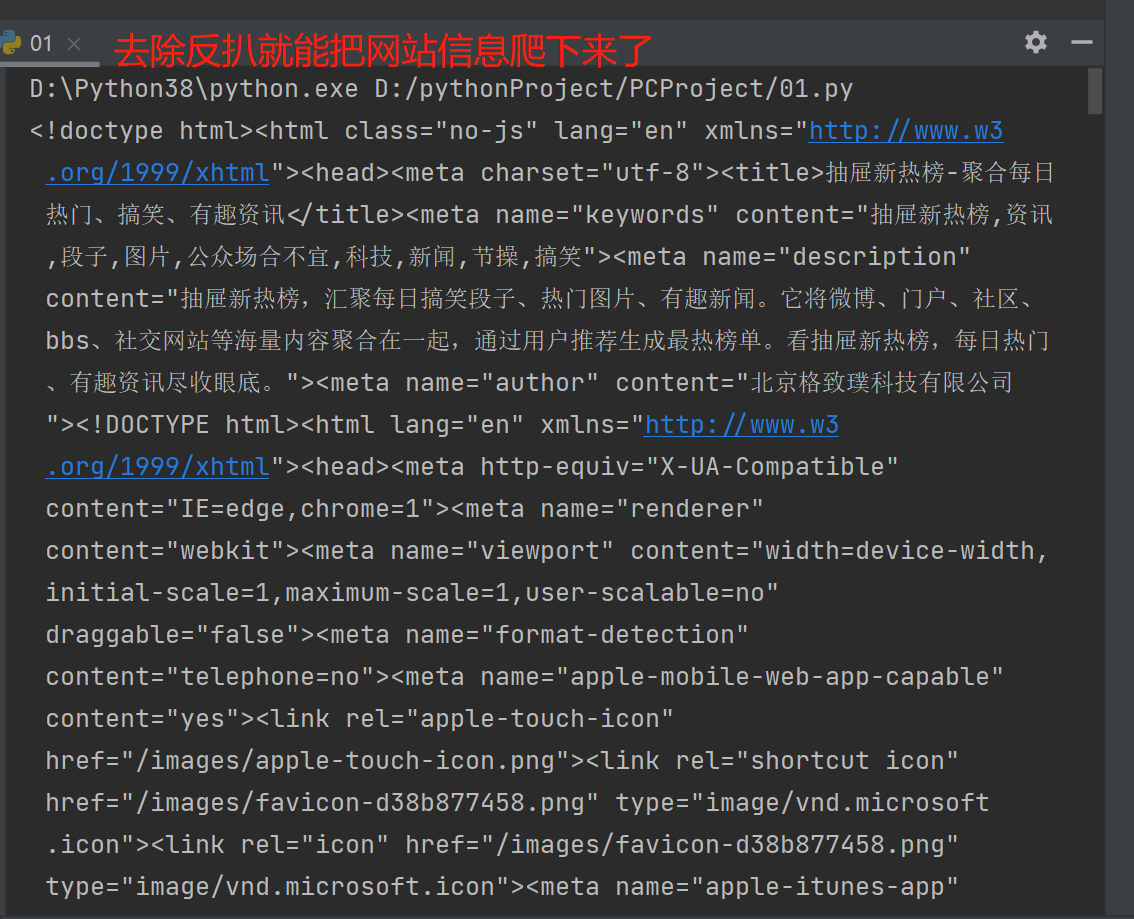
加入请求头,就可以很巧妙的解决这个问题了
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/',headers=header)
print(res.text)
发送post请求,携带数据
'''请求中携带cookie'''
方式一:
直接带在请求头中
import requests
data = {
'linkId': '36996038'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Cookie':'__gads=ID=be9a7b8ae11afd91:T=1663761765:S=ALNI_MYosiDvbNTyg-wXeCws4LgIEelBag; _ga_3Q0DVSGN10=GS1.1.1676984376.11.1.1676984419.17.0.0; _ga=GA1.2.1412057355.1663761756; .Cnblogs.AspNetCore.Cookies=CfDJ8GXQNXLgcs5PrnWvMs4xAGPXacj0zffFfkk58YITFLl0mLZ4ZhMe-ZwE-AepWZF9LMU8QOYUQpVxJynBgpFyePz2eyD-rpo0JiuBN5GcIDXIl0mdJ4Xi6Y7ydDPYYPkeOCRUo9QbyLk4VdQnEsUI7dUWn45LKVU4hSZR9AgyH_FhPwILL2V16Ge7lCAhhlD8ph6rSNbrerg5ml_bpyr3Ea---AbYYoMYyts0eSi-No_vmZvE66hXnufvkliwjLaefxsLZ7sw4NOE1xDGTXBe14V5jMnzTDSx29r7Sx3m9DTrwdAy-Sgj3CFeHtjMkETuadnTUndWXjCubBur-QJXSi3T0VE4nFndx6T3FIJAhj4eE6obxsyPrhOo8wIHVE71SyW6tlTr_1HhfKw9LsSoI6v1SMRS4SdjrsLY6rqi7GK4lvNkp3qQLSzEKYQJ9-8hlumShlF5sKJhX_ZoqxpByQO9eU7C7VL1vqcuMBLLRPzu7U6sHk__2XELFELowONNQ-hGIzd-7Rb5FAKl3Z1PoZFdttf2nQeJH4uDx92SI4T1kc5PVRhHQNdK0WAPpKBID-QwWnSOjrpxy-GXMtImwFKaK-ubJk1ZtS7pputoQ_Hd; _gid=GA1.2.389518996.1678697918; .AspNetCore.Antiforgery.b8-pDmTq1XM=CfDJ8M-opqJn5c1MsCC_BxLIULnbltIubEHSQ4s2dyY4qfxQozOyhnNtjkIi76S2LofGBgNqwjxIZwrZp9y7KLtNmfbEUahwsPv4OF3q_SuARHA2RcCDxiDGsl_qTe7wSEXMjTEaebLDwgpG55r89nwpvpY; Hm_lvt_866c9be12d4a814454792b1fd0fed295=1678542363,1678697923,1678781996,1678839977; __gpi=UID=000009d33626af1e:T=1663761765:RT=1678862699:S=ALNI_Ma1-hYSpfVGFNHRa5qRjpwDtMu8RA; Hm_lpvt_866c9be12d4a814454792b1fd0fed295=1678867009',
}
res = requests.post('https://www.cnblogs.com/',headers=header,data=data)
print(res.text)
自动登录,携带cookie的两种方式
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式 方式一是字符串,方式二是字典或CookieJar对象
方式一:
import requests
data ={
'username': '1965054405067',
'password': 'eeeeeee',
'captcha': '2222',
'remember': '1',
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
方式二:
放到cookie中
res1=requests.get('https://www.cnblogs.com/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
requests.session的使用
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/') # 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
补充post请求携带数据编码格式
data=> 字典使用默认编码格式,编码格式:urlencoded
json=> 字典是使用json编码
普遍使用:res = requests.post('http://www.aa7a.cn/user.php', json={})
响应Response对象
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
respone = requests.get('https://www.jianshu.com', params={'name': 'lqz', 'age': 19},headers=header)
# respone属性
print(respone.text) # 响应体的文本内容
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应cookie
print(respone.cookies.get_dict()) # cookieJar对象,获得到真正的字段
print(respone.cookies.items()) # 获得cookie的所有key和value值
print(respone.url) # 请求地址
print(respone.history) # 访问这个地址,可能会重定向,放了它冲定向的地址
print(respone.encoding) # 页面编码
下载图片,视频
res = requests.get('http://pic.imeitou.com/uploads/allimg/220413/5-220413091326.jpg')
print(res.content)
with open('帅哥.jpg','wb') as f:
f.write(res.content)

res=requests.get('https://vd3.bdstatic.com/mda-pcdcan8afhy74yuq/sc/cae_h264/1678783682675497768/mda-pcdcan8afhy74yuq.mp4')
with open('帅哥.mp4','wb') as f:
for line in res.iter_content():
f.write(line)
