redis之列表,redis之hash,redis其他操作,redis 管道,django中使用redis
1|0redis之列表,redis之hash,redis其他操作,redis 管道,django中使用redis
1|1redis之列表
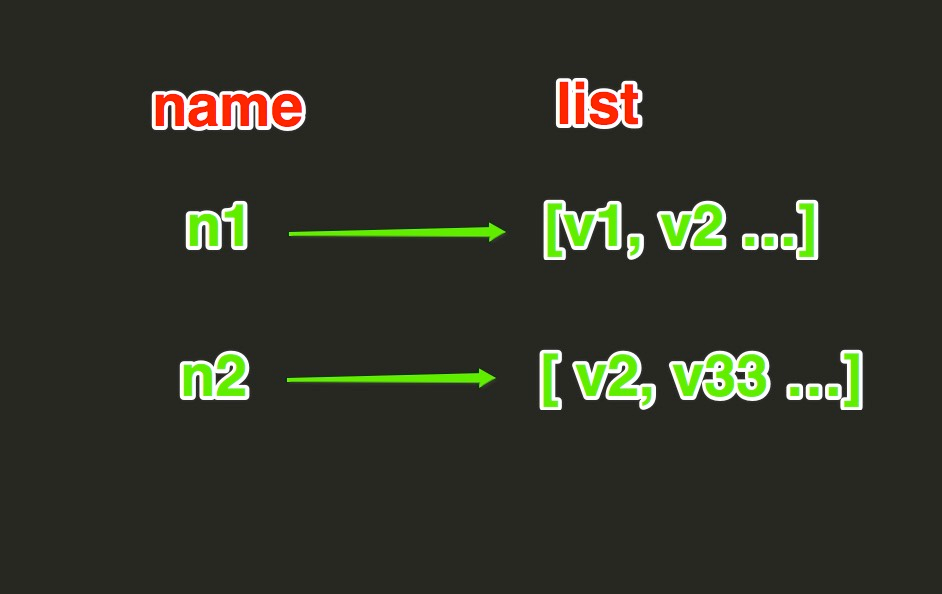
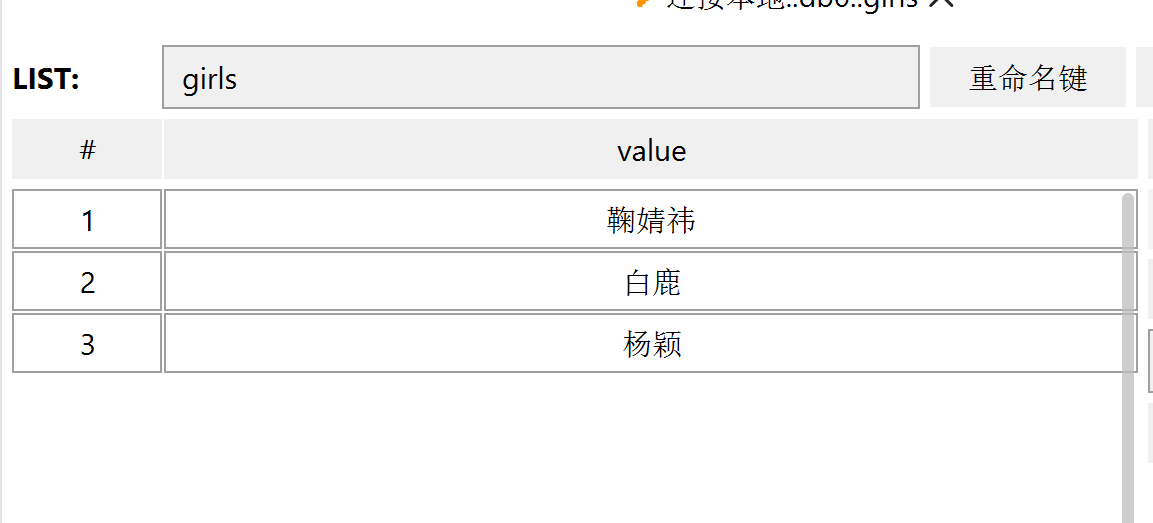
lpush(name,values)
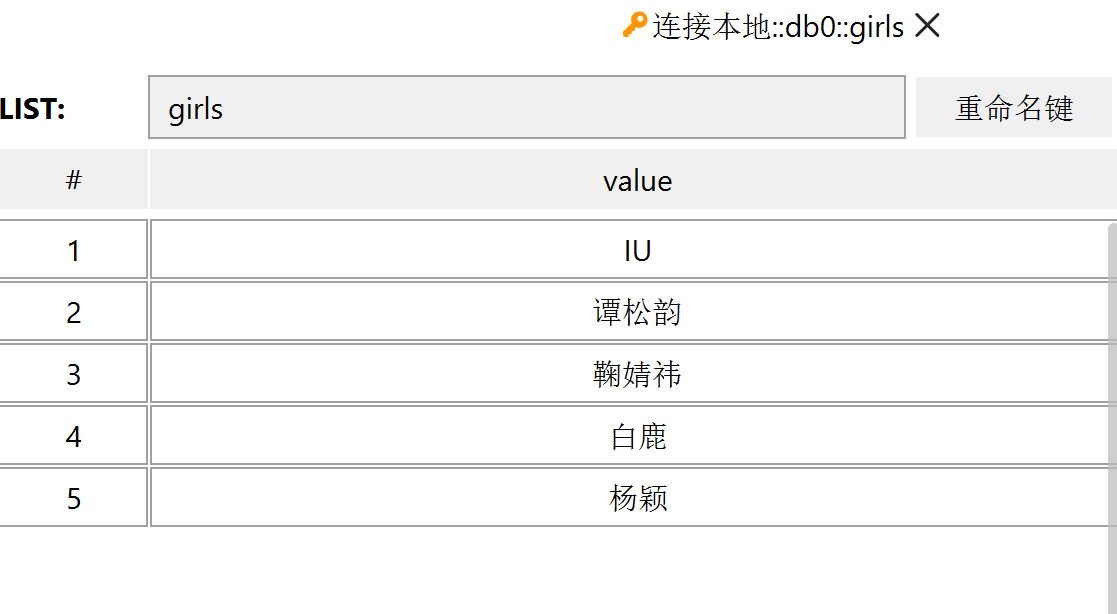
lpushx(name,value)
rpushx(name, value) 表示从右向左操作
llen(name)
linsert(name, where, refvalue, value))
lset(name, index, value)
lrem(name, value, num)
lpop(name)
lindex(name, index)
lrange(name, start, end)
ltrim(name, start, end)
rpoplpush(src, dst)
blpop(keys, timeout)
brpoplpush(src, dst, timeout=0)
1|2redis之hash
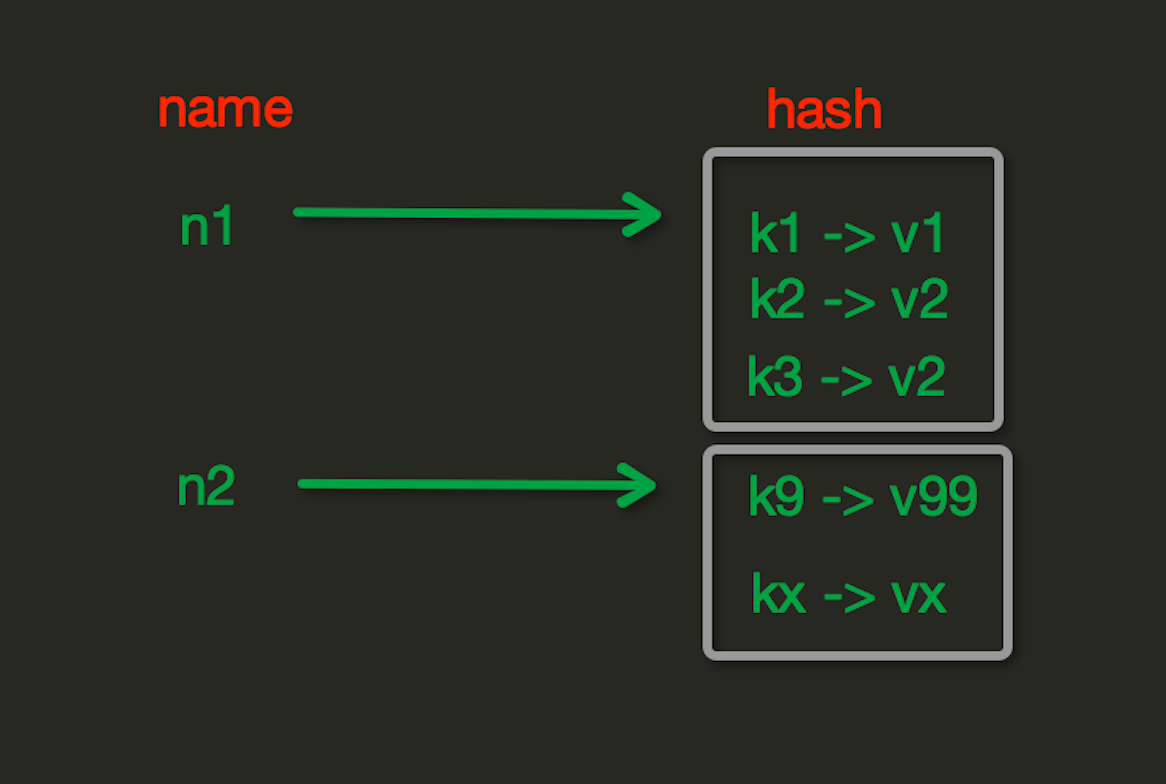
hset(name, key, value)
hmset(name, mapping) 弃用了
hget(name,key)
hmget(name, keys, *args)
hgetall(name) 慎用,可能会造成 阻塞 尽量不要在生产代码中执行它
hlen(name)
hkeys(name)
hvals(name)
hexists(name, key)
hdel(name,*keys)
hincrby(name, key, amount=1)
hincrbyfloat(name, key, amount=1.0)
hscan(name, cursor=0, match=None, count=None)
hscan_iter(name, match=None, count=None) 获取所有hash的数据
1|3redis其他操作
1|4redis 管道
1|5django中集成redis
方式一:直接使用
1|6方式二:使用第三方模块:django-redis
1|7方式三:借助于django的缓存使用redis
__EOF__

本文作者:泡芙有点甜
本文链接:https://www.cnblogs.com/zx0524/p/17195836.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/zx0524/p/17195836.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
分类:
浅学redis


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现