10.23学习总结
1|010.23学习总结
目录
1|1一、常见内置函数
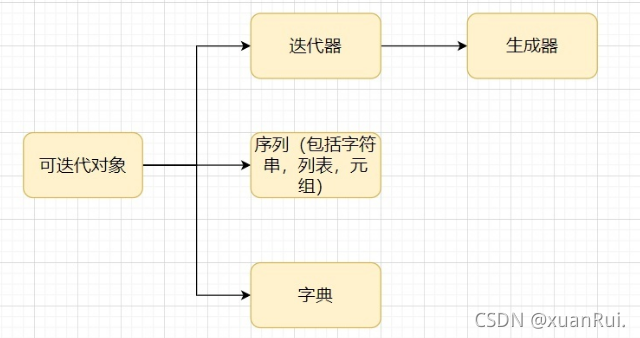
1|2二、可迭代对象
1|3三、迭代器对象
1|4四、生成器对象
1|5五、for循环的本质
1|6六、异常捕获
1|7七、异常捕获语法
1|8八、 迭代取值与索引取值的差异
索引取值: 优势:可以随意反复的获取任意数据值 劣势:针对无序的容器类型无法取值 迭代取值 优势:提供了一种通用的取值方式 劣势:取值一旦开始只能往前不能回退 ps:没有谁好谁差,按实际需求选中使用的就好
1|9九、模块
1|10十、路径
1|11十一、包
1|12十一、 软件开发目录规范
1|13十二、常见内置模块
__EOF__

本文作者:泡芙有点甜
本文链接:https://www.cnblogs.com/zx0524/p/16818970.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/zx0524/p/16818970.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义