luajit开发文档wiki中文版(四) LuaJIT 内部结构
2022年6月10日15:15:22
luajit开发文档中文版(一)下载和安装
luajit开发文档中文版(二)LuaJIT扩展
luajit开发文档中文版(三)FAQ 常见问题
luajit开发文档wiki中文版(二) LuaJIT 扩展
luajit开发文档wiki中文版(三)性能调优和测试
luajit开发文档wiki中文版(四) LuaJIT 内部结构
luajit开发文档wiki中文版(五) 系统集成
luajit开发文档wiki中文版(六) LuaJIT 开发
介绍
以下文档描述了 LuaJIT 2.0 字节码指令。有关详细信息,请参阅src/lj_bc.hLuaJIT 源代码。字节码可以用 列出luajit -bl,参见 -b 选项。
单个字节码指令为 32 位宽,具有 8 位操作码字段和多个 8 位或 16 位操作数字段。指令采用以下两种格式之一:
| B | C | A | OP |
| A | OP | ||
该图显示了右侧的最低有效位。内存指令始终按主机字节顺序存储。例如,0xbbccaa1e 是操作码为 0x1e ( ADDVV) 的指令,操作数 A = 0xaa、B = 0xbb 和 C = 0xcc。
指令名称的后缀区分同一基本指令的变体:
- V可变槽
- S 字符串常量
- N数常数
- P 原始类型
- B 无符号字节文字
- M 多个参数/结果
以下是可能的操作数类型:
- (无):未使用的操作数
- var: 可变槽号
- dst:可变槽号,用作目的地
- base:基本槽号,可读写
- rbase:基本槽号,只读
- uv:上值数
- 点燃:字面意思
- lits:带符号的文字
- pri:原始类型(0 = nil,1 = false,2 = true)
- num:数字常量,索引到常量表
- str:字符串常量,常量表的否定索引
- tab:模板表,否定索引到常量表
- func:函数原型,常量表的否定索引
- cdata:cdata 常量,常量表的否定索引
- jump:分支目标,相对于下一条指令,偏置为 0x8000
比较操作
所有比较和测试操作都紧跟在一条JMP 指令之后,该指令包含条件跳转的目标。如果比较或测试为真,则所有比较和测试都会跳转到目标。否则,他们将通过JMP.
| Description | ||||
|---|---|---|---|---|
| ISLT | var | var | Jump if A < D | |
| ISGE | var | var | Jump if A ≥ D | |
| ISLE | var | var | Jump if A ≤ D | |
| ISGT | var | var | Jump if A > D | |
| ISEQV | var | var | Jump if A = D | |
| ISNEV | var | var | Jump if A ≠ D | |
| ISEQS | var | str | Jump if A = D | |
| ISNES | var | str | Jump if A ≠ D | |
| ISEQN | var | num | Jump if A = D | |
| ISNEN | var | num | Jump if A ≠ D | |
| ISEQP | var | pri | Jump if A = D | |
| ISNEP | var | pri | Jump if A ≠ D | |
问:为什么我们需要四种不同的有序比较?适当交换的操作数还不够<吗 ?<=
答:不,因为浮点比较(x < y)与存在NaN 的情况不同。not (x >= y)
LuaJIT 解析器保留源代码的有序比较语义,如下所示:
| Source code | Bytecode |
|---|---|
| if x < y then | ISGE x y |
| if x <= y then | ISGT x y |
| if x > y then | ISGE y x |
| if x >= y then | ISGT y x |
| if not (x < y) then | ISLT x y |
| if not (x <= y) then | ISLE x y |
| if not (x > y) then | ISLT y x |
| if not (x >= y) then | ISLE y x |
根据需要交换(不)等式比较以将常量移到右侧。
一元测试和复制操作
这些指令测试一个变量在布尔上下文中的计算结果是真还是假。仅在 Lua中nil并被false认为是假的,所有其他值都是真。这些指令是为简单的真实性测试而生成的,例如if x then在评估andandor 运算符时。
| Description | ||||
|---|---|---|---|---|
| ISTC | dst | var | Copy D to A and jump, if D is true | |
| ISFC | dst | var | Copy D to A and jump, if D is false | |
| IST | var | Jump if D is true | ||
| ISF | var | Jump if D is false | ||
问:我们需要测试和复制操作做什么?
答:在 Lua 中,andandor运算符返回其操作数之一的原始值。通常只有在解析完整表达式后才知道结果是否未被使用。在这种情况下,测试和复制操作可以很容易地转换为先前发出的字节码中的测试操作。
一元操作
| Description | ||||
|---|---|---|---|---|
| MOV | dst | var | Copy D to A | |
| NOT | dst | var | Set A to boolean not of D | |
| UNM | dst | var | Set A to -D (unary minus) | |
| LEN | dst | var | Set A to #D (object length) | |
Binary ops
| Description | ||||
|---|---|---|---|---|
| ADDVN | dst | var | num | A = B + C |
| SUBVN | dst | var | num | A = B - C |
| MULVN | dst | var | num | A = B * C |
| DIVVN | dst | var | num | A = B / C |
| MODVN | dst | var | num | A = B % C |
| ADDNV | dst | var | num | A = C + B |
| SUBNV | dst | var | num | A = C - B |
| MULNV | dst | var | num | A = C * B |
| DIVNV | dst | var | num | A = C / B |
| MODNV | dst | var | num | A = C % B |
| ADDVV | dst | var | var | A = B + C |
| SUBVV | dst | var | var | A = B - C |
| MULVV | dst | var | var | A = B * C |
| DIVVV | dst | var | var | A = B / C |
| MODVV | dst | var | var | A = B % C |
| POW | dst | var | var | A = B ^ C |
| CAT | dst | rbase | rbase | A = B .. ~ .. C |
注意:该CAT指令将变量槽 B 到 C 中的所有值连接起来。
Constant ops
| Description | ||||
|---|---|---|---|---|
| KSTR | dst | str | Set A to string constant D | |
| KCDATA | dst | cdata | Set A to cdata constant D | |
| KSHORT | dst | lits | Set A to 16 bit signed integer D | |
| KNUM | dst | num | Set A to number constant D | |
| KPRI | dst | pri | Set A to primitive D | |
| KNIL | base | base | Set slots A to D to nil | |
注意:使用 设置单个nil值KPRI。KNIL仅在需要将多个值设置为 时使用nil。
Upvalue and Function ops
| Description | ||||
|---|---|---|---|---|
| UGET | dst | uv | Set A to upvalue D | |
| USETV | uv | var | Set upvalue A to D | |
| USETS | uv | str | Set upvalue A to string constant D | |
| USETN | uv | num | Set upvalue A to number constant D | |
| USETP | uv | pri | Set upvalue A to primitive D | |
| UCLO | rbase | jump | Close upvalues for slots ≥ rbase and jump to target D | |
| FNEW | dst | func | Create new closure from prototype D and store it in A | |
问:为什么UCLO会有跳跃目标?
A :UCLO通常是块中的最后一条指令,通常后面跟一个JMP. 将跳转合并到UCLO加速执行并简化一些字节码修复步骤(参见 参考资料fs_fixup_ret()) src/lj_parse.c。非分支UCLO只是跳转到下一条指令。
Table ops
| Description | ||||
|---|---|---|---|---|
| TNEW | dst | lit | Set A to new table with size D (see below) | |
| TDUP | dst | tab | Set A to duplicated template table D | |
| GGET | dst | str | A = _G[D] | |
| GSET | var | str | _G[D] = A | |
| TGETV | dst | var | var | A = B[C] |
| TGETS | dst | var | str | A = B[C] |
| TGETB | dst | var | lit | A = B[C] |
| TSETV | var | var | var | B[C] = A |
| TSETS | var | var | str | B[C] = A |
| TSETB | var | var | lit | B[C] = A |
| TSETM | base | num* | (A-1)[D], (A-1)[D+1], ... = A, A+1, ... |
备注:
- 16 位文字 D 操作数
TNEW分为两个字段:最低 11 位给出数组大小(分配插槽 0..asize-1,如果为零,则不分配)。高 5 位将哈希大小作为 2 的幂(分配 2^hsize 哈希槽,如果为零,则不分配)。 GGET并被GSET命名为“全局”获取和设置,但实际上索引当前函数环境getfenv(1)(通常与 相同_G)。TGETB并将TSETB8 位文字 C 操作数解释为表 B 中的无符号整数索引 (0..255)。- 操作数 D
TSETM指向常量表中的偏置浮点数。只有尾数的最低 32 位用作起始表索引。来自前一个字节码的 MULTRES 给出了要填充的表槽数。
调用和可变参数处理
所有调用指令都需要一个特殊的设置:要调用的函数(或对象)位于插槽 A 中,后面是连续插槽中的参数。操作数 C 是固定参数数量的加一。操作数 B 是返回值数量的一加,或者对于返回所有结果的调用为零(并相应地设置 MULTRES)。
带有多个参数(CALLM或CALLMT)的调用的操作数 C 设置为固定参数的数量。MULTRES 添加到其中以获取要传递的实际参数数量。
为了保持一致性,专用调用指令ITERC和ITERN可变参数指令VARG共享相同的操作数格式。ITERCand的操作数 CITERN始终为 3 = 1+2,即两个参数被传递给迭代器函数。操作数 C ofVARG重新用于保存封闭函数的固定参数的数量。这加快了对下面 vararg 伪帧的可变参数部分的访问。
MULTRES 是一个内部变量,用于跟踪上一次调用或VARG具有多个结果的指令返回的结果数量。它被多个参数的调用(CALLM或CALLMT)或返回(RETM)以及表初始化程序(TSETM)使用。
| Description | ||||
|---|---|---|---|---|
| CALLM | base | lit | lit | Call: A, ..., A+B-2 = A(A+1, ..., A+C+MULTRES) |
| CALL | base | lit | lit | Call: A, ..., A+B-2 = A(A+1, ..., A+C-1) |
| CALLMT | base | lit | Tailcall: return A(A+1, ..., A+D+MULTRES) | |
| CALLT | base | lit | Tailcall: return A(A+1, ..., A+D-1) | |
| ITERC | base | lit | lit | Call iterator: A, A+1, A+2 = A-3, A-2, A-1; A, ..., A+B-2 = A(A+1, A+2) |
| ITERN | base | lit | lit | Specialized ITERC, if iterator function A-3 is next() |
| VARG | base | lit | lit | Vararg: A, ..., A+B-2 = ... |
| ISNEXT | base | jump | Verify ITERN specialization and jump |
注意:Lua 解析器启发式地确定是否pairs()或 next()可能在循环中使用。在这种情况下,JMP和 迭代器调用ITERC被替换为专用版本 ISNEXT和ITERN。
ISNEXT在运行时验证迭代器实际上是next() 函数,参数是表,控制变量是 nil. 然后它将控制变量的槽的最低 32 位设置为零并跳转到迭代器调用,它使用这个数字有效地逐步遍历表的键。
如果任何假设被证明是错误的,则字节码在运行时将被反专门化为JMPand ITERC。
Returns
所有返回指令都将从槽 A 开始的结果复制到从基本槽(保存帧链接和当前执行函数的槽)下一个开始的槽。
和RET0指令RET1只是RET. 操作数 D 是要返回的结果数的一加。
对于RETM,操作数 D 保存要返回的固定结果的数量。将 MULTRES 添加到其中以获取要返回的实际结果数。
| Description | ||||
|---|---|---|---|---|
| RETM | base | lit | return A, ..., A+D+MULTRES-1 | |
| RET | rbase | lit | return A, ..., A+D-2 | |
| RET0 | rbase | lit | return | |
| RET1 | rbase | lit | return A | |
循环和分支
Lua 语言提供了四种循环类型,它们被翻译成不同的字节码指令:
- 数字“for”循环:
for i=start,stop,step do body end=> 设置开始、停止、步骤FORI主体FORL - 迭代器'for'循环:
for vars... in iter,state,ctl do body end=> set iter,state,ctlJMPbodyITERCITERL - 'while' 循环:
while cond do body end=> inverse-cond-JMPLOOPbodyJMP - “重复”循环:
repeat body until cond=>LOOP身体条件-JMP
breakandgoto语句被翻译成无条件的 orJMP指令UCLO。
| Description | ||||
|---|---|---|---|---|
| FORI | base | jump | Numeric 'for' loop init | |
| JFORI | base | jump | Numeric 'for' loop init, JIT-compiled | |
| FORL | base | jump | Numeric 'for' loop | |
| IFORL | base | jump | Numeric 'for' loop, force interpreter | |
| JFORL | base | lit | Numeric 'for' loop, JIT-compiled | |
| ITERL | base | jump | Iterator 'for' loop | |
| IITERL | base | jump | Iterator 'for' loop, force interpreter | |
| JITERL | base | lit | Iterator 'for' loop, JIT-compiled | |
| LOOP | rbase | jump | Generic loop | |
| ILOOP | rbase | jump | Generic loop, force interpreter | |
| JLOOP | rbase | lit | Generic loop, JIT-compiled | |
| JMP | rbase | jump | Jump | |
操作数 A 保存指令的第一个未使用的槽、JMP指令的循环控制变量的基本槽*FOR*(idx、stop、step、ext idx)或指令迭代器返回结果的基*ITERL(存储在下面是 func、state和ctl)。
JFORL和指令将跟踪JITERL号JLOOP存储在操作数 D 中(JFORI从对应的 中检索JFORL)。否则,操作数 D 指向循环后的第一条指令。
和指令FORL进行热点检测。如果循环执行得足够频繁,就会触发跟踪记录。ITERLLOOP
IFORLJIT 编译器使用IITERL和ILOOP指令将无法编译的循环列入黑名单。他们不在解释器中进行热点检测和强制执行。
如果循环进入条件为真JFORI,则JFORL、JITERL和指令进入 JIT 编译的跟踪。JLOOP
*FORL指令idx = idx + step先做。所有*FOR* 指令都会检查idx <= stop(if step >= 0) 或idx >= stop (if step < 0)。如果为真,idx则复制到ext idx槽(循环体中可见的循环变量)。然后输入循环体或 JIT 编译的跟踪。否则,通过继续执行 . 之后的下一条指令来离开循环*FORL。
*ITERL指令检查槽 A 中迭代器返回的第一个结果是否为非nil. 如果为真,则将此值复制到插槽 A-1 并输入循环体或 JIT 编译的跟踪。
这些*LOOP指令实际上是无操作的(热点检测除外)并且不分支。操作数 A 和 D 仅由 JIT 编译器用于加速数据流和控制流分析。字节码指令本身是必需的,因此 JIT 编译器可以对其进行修补以输入循环的 JIT 编译跟踪。
Function headers
| Description | ||||
|---|---|---|---|---|
| FUNCF | rbase | Fixed-arg Lua function | ||
| IFUNCF | rbase | Fixed-arg Lua function, force interpreter | ||
| JFUNCF | rbase | lit | Fixed-arg Lua function, JIT-compiled | |
| FUNCV | rbase | Vararg Lua function | ||
| IFUNCV | rbase | Vararg Lua function, force interpreter | ||
| JFUNCV | rbase | lit | Vararg Lua function, JIT-compiled | |
| FUNCC | rbase | Pseudo-header for C functions | ||
| FUNCCW | rbase | Pseudo-header for wrapped C functions | ||
| FUNC* | rbase | Pseudo-header for fast functions | ||
操作数 A 保存函数的帧大小。操作数 D 保存 和 的跟踪JFUNCF号JFUNCV。
对于 Lua 函数,省略的固定参数被设置为nil,多余的参数被忽略。Vararg 函数设置涉及创建一个特殊的 vararg 框架,该框架包含固定参数之外的参数。固定的参数被复制到一个常规的 Lua 函数框架,并且它们在可变参数框架中的槽被设置为nil.
和指令为固定参数或可变参数 Lua 函数设置框架并进行热点检测FUNCF。FUNCV如果函数执行得足够频繁,就会触发跟踪记录。
JIT 编译器使用IFUNCF和IFUNCV指令将无法编译的函数列入黑名单。他们不在解释器中进行热点检测和强制执行。
JFUNCF和指令在JFUNCV初始设置后进入 JIT 编译的跟踪。
FUNCCand指令是C 闭包字段FUNCCW指向的伪头文件。pc它们从不发出,仅用于分派到 C 函数调用的设置代码。
所有较高编号的字节码指令都用作快速函数的伪标头。它们从不发出,仅用于为相应的快速功能分派到机器代码。
LuaJIT 2.0 Bytecode Dump Format
LuaJIT 字节码转储格式是使用luajit -bor string.dump函数生成的。它可以保存到文件并稍后加载,而不是存储普通的 Lua 源,占用更多空间并花费更长的时间加载。
字节码转储格式的详细信息可以src/lj_bcdump.h 在 LuaJIT 源代码中找到。这是简洁的格式说明:
dump = header proto+ 0U
header = ESC 'L' 'J' versionB flagsU [namelenU nameB*]
proto = lengthU pdata
pdata = phead bcinsW* uvdataH* kgc* knum* [debugB*]
phead = flagsB numparamsB framesizeB numuvB numkgcU numknU numbcU
[debuglenU [firstlineU numlineU]]
kgc = kgctypeU { ktab | (loU hiU) | (rloU rhiU iloU ihiU) | strB* }
knum = intU0 | (loU1 hiU)
ktab = narrayU nhashU karray* khash*
karray = ktabk
khash = ktabk ktabk
ktabk = ktabtypeU { intU | (loU hiU) | strB* }
B = 8 bit, H = 16 bit, W = 32 bit, U = ULEB128 of W, U0/U1 = ULEB128 of W+1TODO : 将描述转换为人类可读的文本 :-)
转储以魔法开始\x1bLJ。神奇的是版本号,它表示字节码的版本。不同版本不兼容。在撰写本文时,当前版本号1由. 接下来, 使用 ULEB128对位标志(在 中找到)进行编码。如果未设置标志,则接下来是 ULEB128 编码的块名称的长度,并且它本身紧跟在长度之后,否则跳过此步骤。BCDUMP_VERSIONsrc/lj_dump.hBCDUMP_F_{STRIP, BE, FFI}src/lj_dump.hBCDUMP_F_STRIP
TODO:具体lj_bcwrite.c:370 ctx->status = ctx->wfunc(ctx->L, ctx->sb.buf, ctx->sb.n, ctx->wdata);做什么?
TODO : 更多信息GCproto
接下来,GCproto写入携带字节码的对象。注意复数对象,每个函数有一个对象。对象写得最深,首先在前,即:
function a()
function b()
print(1)
end
return b
end
a()()首先b,然后a再编写范围的其余部分。
最后有一个\0字节,表示bcread_proto.
BCDUMP_F_* 标志
todo
GCProto
todo
LuaJIT 2.0 SSA IR
介绍
以下文档描述了LuaJIT 2.0 的 JIT 编译器使用的中间表示 ( IR )。跟踪编译器按照控制流记录字节码指令,并即时发出相应的 IR 指令。
IR具有以下特点:
-
IR 采用 SSA(静态单一分配)形式。每条指令(节点)都代表一个值的单一定义。多条指令形成一个部分连接的数据流图。循环的数据流使用 PHI 指令表示。控制流总是隐含的。
-
IR 是线性的、无指针的且隐含编号:每条指令都可以通过其在线性数组中的位置来唯一引用 (IRRef)。特制的、有偏见的 IR 参考允许快速做出 const 与非 const 决策。存储明确的参考编号、值编号或类似信息不会浪费任何空间。
-
IR 是 2-operand-normalized 形式:每条指令都有一个操作码和最多两个操作数。一些指令可能需要更多的操作数(例如
CALL*),这些操作数是使用扩展指令(CARG)组成的。 -
IR 是有类型的:每条指令都有一个输出数据类型。建模类型对应于基本 Lua 数据类型和低级数据类型。更高级别的数据类型根据需要使用受保护的断言进行间接建模。
-
IR 具有隔离的每个操作码链接:这允许以相反的顺序快速搜索特定指令,而无需完全遍历。这用于加速许多优化,例如 CSE 或别名分析。大多数搜索在零(不匹配)之后停止,实际上是一两次取消引用。
-
IR 非常紧凑:每条指令只需要 64 位,并且所有指令彼此相邻。这种布局的缓存效率非常高,索引或遍历速度非常快。
-
IR 是增量生成的:IR 数组是双向增长的:常量向下增长,所有其他指令向上增长。大多数优化都是即时执行的,消除的指令要么根本不发出,要么在代码生成期间被忽略,要么被适当地标记。一般不需要在中间插入或删除指令。这避免了大多数编译器教科书中提出的缓存效率非常低的链接节点海数据结构。
-
IR 是统一的:它同时携带高级语义和低级细节。编译器的不同阶段使用 IR 的不同方面,但共享一个通用的 IR 格式。消除经典的 HIR、MIR、LIR 分离(高、中、低级 IR)大大降低了复杂性和编译器开销。它避免了由于抽象不匹配导致的语义信息丢失,并允许对内存引用进行廉价且有效的高级语义消歧。
-
IR 使用辅助快照:快照捕获对应于字节码执行堆栈中修改的槽和帧的 IR 引用。每个快照都保存一个特定的字节码执行状态,以后可以在跟踪退出时恢复。快照被稀疏地发射和压缩。快照提供了 IR 和字节码域(以及源代码域,通过字节码调试信息)之间的链接。
Status
COMPLETE REWRITE IN PROGRESS
src/lj_ir.h有关完整的详细信息,请参阅src/lj_jit.hLuaJIT 源代码。生成的 IR 可以与luajit -jdump(跟踪的字节码、IR 和机器代码)或luajit -jdump=i(仅 IR)一起列出。
示例 IR 转储
$ ./luajit -jdump=bitmsr
LuaJIT 2.0.0-beta10 -- Copyright (C) 2005-2012 Mike Pall. http://luajit.org/
JIT: ON CMOV SSE2 SSE3 AMD fold cse dce fwd dse narrow loop abc sink fuse
> local x = 1.2 for i=1,1e3 do x = x * -3 end
---- TRACE 1 start stdin:1
0006 MULVN 0 0 1 ; -3
0007 FORL 1 => 0006
---- TRACE 1 IR
.... SNAP #0 [ ---- ]
0001 rbp int SLOAD #2 CI
0002 xmm7 > num SLOAD #1 T
0003 xmm7 + num MUL 0002 -3
0004 rbp + int ADD 0001 +1
.... SNAP #1 [ ---- 0003 ]
0005 > int LE 0004 +1000
.... SNAP #2 [ ---- 0003 0004 ---- ---- 0004 ]
0006 ------------ LOOP ------------
0007 xmm7 + num MUL 0003 -3
0008 rbp + int ADD 0004 +1
.... SNAP #3 [ ---- 0007 ]
0009 > int LE 0008 +1000
0010 rbp int PHI 0004 0008
0011 xmm7 num PHI 0003 0007
---- TRACE 1 mcode 81
394cffa3 mov dword [0x4183f4a0], 0x1
394cffae movsd xmm0, [0x4184f698]
394cffb7 cvtsd2si ebp, [rdx+0x8]
394cffbc cmp dword [rdx+0x4], 0xfffeffff
394cffc3 jnb 0x394c0010 ->0
394cffc9 movsd xmm7, [rdx]
394cffcd mulsd xmm7, xmm0
394cffd1 add ebp, +0x01
394cffd4 cmp ebp, 0x3e8
394cffda jg 0x394c0014 ->1
->LOOP:
394cffe0 mulsd xmm7, xmm0
394cffe4 add ebp, +0x01
394cffe7 cmp ebp, 0x3e8
394cffed jle 0x394cffe0 ->LOOP
394cffef jmp 0x394c001c ->3
---- TRACE 1 stop -> loop上面打印了跟踪的字节码、从带有快照的字节码生成的 IR,以及从 IR 生成的机器码.
The columns of the IR are as follows:
1st column: IR instruction number (implicit SSA ref)
2nd column: physical CPU register or physical CPU stack slot that
value is written to when converted to machine code.
'[%x+]' (rather than register name) indicates hexadecimal offset
from stack pointer.
(This column is only present if the 'r' flags is included in -jdump, which
augments the IR with register/stack slots. It is not part of the IR itself.)
3rd column: Instruction flags:
">" (IRT_GUARD = 0x80 instruction flag) are locations of
guards (leading to possible side exits from the trace).
"+" (IRT_ISPHI = 0x40 instruction flag) indicates
instruction is left or right PHI operand. (i.e referred
to in some PHI instruction).
4th column: IR type (see IR Types below)
5th column: IR opcode (see opcode reference)
6th/7th column: IR operands (SSA refs or literals)
'#' prefixes refer to slot numbers, used in SLOADS.
#0 is the base frame (modified only in tail calls).
#1 is the first slot in the first frame (register 0 in
the bytecode)
'[+-]' prefixes indicate positive or negative numeric literals.
'[0x%d+]' and NULL are memory addresses.
'"..."' are strings.
'@' prefixes indicate slots (what is this?).
Other possible values: "bias" (number 2^52+2^51 ?), "userdata:%p",
"userdata:%p" (table)--when do these occur?.另见 SSA 转储格式注释: http: //lua-users.org/lists/lua-l/2008-06/msg00225.html(旧版本)。参见dump.lua。formatk_
每个快照 (SNAP) 都会列出修改后的堆栈槽及其值。快照列表中的第 i 个值表示在插槽号#i 中写入值的 IR 的索引。'---' 表示该槽没有被写入。帧由“|”分隔。有关快照的更多评论,请参阅http://lua-users.org/lists/lua-l/2009-11/msg00089.html。
IR Types
每条指令都有一个输出数据类型,它要么是基本 Lua 类型之一,要么是低级类型。该顺序经过精心设计,以简化标记值类型的映射并优化常见检查(例如“任何整数类型”)。见src/lj_ir.h和src/lj_obj.h。
| # | Dump | IRT_ | Description |
|---|---|---|---|
| 0 | nil | NIL | 'nil' value |
| 1 | fal | FALSE | 'false' value |
| 2 | tru | TRUE | 'true' value |
| 3 | lud | LIGHTUD | Lightuserdata value |
| 4 | str | STR | Interned string object |
| 5 | p32 | P32 | 32 bit pointer |
| 6 | thr | THREAD | Thread object |
| 7 | pro | PROTO | Function prototype object |
| 8 | fun | FUNC | Function (closure) object |
| 9 | p64 | P64 | 64 bit pointer |
| 10 | cdt | CDATA | cdata object |
| 11 | tab | TAB | Table object |
| 12 | udt | UDATA | Userdata object |
| 13 | flt | FLOAT | 32 bit FP number (float) |
| 14 | num | NUM | 64 bit FP number (double) |
| 15 | i8 | I8 | 8 bit signed integer (int8_t) |
| 16 | u8 | U8 | 8 bit unsigned integer (uint8_t) |
| 17 | i16 | I16 | 16 bit signed integer (int16_t) |
| 18 | u16 | U16 | 16 bit unsigned integer (uint16_t) |
| 19 | int | INT | 32 bit signed integer (int32_t) |
| 20 | u32 | U32 | 32 bit unsigned integer (uint32_t) |
| 21 | i64 | I64 | 64 bit signed integer (int64_t) |
| 22 | u64 | U64 | 64 bit unsigned integer (uint64_t) |
| 23 | sfp | SOFTFP | Hi-word of split soft-fp operations |
Constants
常量指令仅存在于 IR 的常量部分(向上增长到较低的参考)。IR 常量是 interned(去重),并且只能通过查看它们的引用来比较它们的相等性。
常量指令永远不会出现在转储中,因为-jdump始终显示内联到引用指令中的实际常量值
| Description | |||
|---|---|---|---|
| KPRI | Primitive type: nil, false, true | ||
| KINT | #int | 32 bit integer constant | |
| KGC | #ptr | Garbage collected constant | |
| KPTR | #ptr | Pointer constant | |
| KKPTR | #ptr | Pointer constant to constant data | |
| KNULL | #ptr | Typed NULL constant | |
| KNUM | #k64ptr | Double-precision floating-point constant | |
| KINT64 | #k64ptr | 64 bit integer constant | |
| KSLOT | kref | #slot | Hash slot for constant |
每个跟踪KPRI在固定引用处都有三个指令,用于常量 nil、false 和 true(REF_NIL、REF_FALSE、REF_TRUE)。
32 位整数或指针值占用左右 16 位操作数的空间。64 位值在一个全局常量表中,并由 32 位指针间接引用。
KPTR是指向可能非常量数据的常量指针(绝对地址)。KKPTR指向绝对恒定的数据。只有VM已知为常量的数据才符合条件,例如,一个内部的 Lua 字符串。被用户(例如const char *)标记为“const”的内容不符合条件。
KSLOT用作键HREFK并保存要在其中找到键的哈希槽和对常量键本身的引用。
Guarded Assertions
受保护的断言有双重目的:
- 它们提供有关其操作数的断言,编译器可以使用该断言来优化同一跟踪中的所有后续指令。
- 它们由后端作为分支比较发出,在直通路径中具有“真实”结果。“假”结果退出跟踪并将状态恢复到最近的快照。
| Description | |||
|---|---|---|---|
| LT | left | right | left < right (signed) |
| GE | left | right | left ≥ right (signed) |
| LE | left | right | left ≤ right (signed) |
| GT | left | right | left > right (signed) |
| ULT | left | right | left < right (unsigned/unordered) |
| UGE | left | right | left ≥ right (unsigned/unordered) |
| ULE | left | right | left ≤ right (unsigned/unordered) |
| UGT | left | right | left > right (unsigned/unordered) |
| EQ | left | right | left = right |
| NE | left | right | left ≠ right |
| ABC | bound | index | Array Bounds Check: bound > index (unsigned) |
| RETF | proto | pc | Return to lower frame: check target PC, shift base |
操作码为整数类型提供无符号比较语义,U..为浮点类型提供无序比较语义。操作数导致有序比较的 NaN“假”结果和无序比较EQ的“真”结果NE。
ABC就像UGT在后端一样对待。但它遵循不同的 FOLD 规则,这简化了 ABC 消除。
返回的原型RETF位于到目前为止的跟踪所覆盖的调用图下方。因此RETF需要锚定原型以防止垃圾回收后回收PC。
Bit Ops
| Description | |||
|---|---|---|---|
| BNOT | ref | Bitwise NOT of ref | |
| BSWAP | ref | Byte-swapped ref | |
| BAND | left | right | Bitwise AND of left and right |
| BOR | left | right | Bitwise OR of left and right |
| BXOR | left | right | Bitwise XOR of left and right |
| BSHL | ref | shift | Bitwise left shift of ref |
| BSHR | ref | shift | Bitwise logical right shift of ref |
| BSAR | ref | shift | Bitwise arithmetic right shift of ref |
| BROL | ref | shift | Bitwise left rotate of ref |
| BROR | ref | shift | Bitwise right rotate of ref |
移位和循环指令的移位计数以移位类型的位宽为模进行解释,即只有最低的 N 位是有效的。适当的位掩码指令 ( BAND) 被插入到底层机器指令本身不执行掩码的后端。类似地,旋转统一到一个方向,以防架构不为这两个方向提供机器指令。
Arithmetic Ops
| Description | |||
|---|---|---|---|
| ADD | left | right | left + right |
| SUB | left | right | left - right |
| MUL | left | right | left * right |
| DIV | left | right | left / right |
| MOD | left | right | left % right |
| POW | left | right | left ^ right |
| NEG | ref | kneg | -ref |
| ABS | ref | kabs | abs(ref) |
| ATAN2 | left | right | atan2(left, right) |
| LDEXP | left | right | ldexp(left, right) |
| MIN | left | right | min(left, right) |
| MAX | left | right | max(left, right) |
| FPMATH | ref | #fpm | fpmath(ref), see below |
| ADDOV | left | right | left + right, overflow-checked |
| SUBOV | left | right | left - right, overflow-checked |
| MULOV | left | right | left * right, overflow-checked |
所有算术运算都在其类型的域内运行:整数、指针或浮点数。并非所有操作都针对所有可能的类型定义。有符号和无符号整数都会在溢出时回绕。
溢出检查操作在有符号整数算术溢出时退出跟踪。
MOD被分解为浮点数的left-floor(left/right)right。POW要么转换为POW整数作为右操作数,要么转换为 sqrt(left),如果 right 为 0.5,否则转换为 exp2(log2(left) right)(后端可能稍后将其合并到对 pow() 的调用中)。
的整数变体的未定义情况DIV,MOD并POW 返回仅设置了最高位的整数值。
NEGABS对于浮点数,请在右操作数中引用 SIMD 对齐的常量。一些后端将这些实现为数字和常数的按位异或或与。
的右操作LDEXP数在 x86 和 x64 平台上是浮点数,在所有其他平台上是 32 位整数。
所有浮点算术运算都遵循 IEEE 754 wrt 的标准定义。+-0、+-Inf、NaN 和非规范化。MIN并且MAX对 NaN 操作数没有定义的行为。
FPMATH用于一元浮点算术运算。右操作数指定实际操作:
| Description | |
|---|---|
| FPM_FLOOR | floor(ref) |
| FPM_CEIL | ceil(ref) |
| FPM_TRUNC | trunc(ref) |
| FPM_SQRT | sqrt(ref) |
| FPM_EXP | exp(ref) |
| FPM_EXP2 | exp2(ref) |
| FPM_LOG | log(ref) |
| FPM_LOG2 | log2(ref) |
| FPM_LOG10 | log10(ref) |
| FPM_SIN | sin(ref) |
| FPM_COS | cos(ref) |
| FPM_TAN | tan(ref) |
Memory References
内存引用生成一个指针值,供相应的加载或存储使用。为了保留更高级别的语义并简化别名分析,它们不会分解为较低级别的操作(如XLOAD引用)。其中一些可以(部分)融合到大多数后端的加载或存储指令的操作数中。
| Description | |||
|---|---|---|---|
| AREF | array | index | Array reference |
| HREFK | hash | kslot | Constant hash reference |
| HREF | tab | key | Hash reference |
| NEWREF | tab | key | Create new reference |
| UREFO | func | #uv | Open upvalue reference |
| UREFC | func | #uv | Closed upvalue reference |
| FREF | obj | #field | Object field reference |
| STRREF | str | index | String reference |
AREF并使用其左操作数HREFK引用FLOADLua 表的数组部分或哈希部分。HREF并NEWREF直接引用 Lua 表,因为他们需要搜索或扩展表。 HREFK专用于期望常量键的哈希槽——见KSLOT上面的右操作数。NEWREF假设该键在 Lua 表中尚不存在。
UREFO和UREFC引用当前函数的左操作数(闭包)。右操作数在最低 8 位中保存上值消歧散列,在高位中保存上值索引。
有关 中的字段 ID 的可能值FREF,请参阅 中的 IRFLDEF src/lj_ir.h。
Loads and Stores
加载和存储对内存引用进行操作,并加载一个值(指令的结果)或存储一个值(右操作数)。为了保留更高级别的语义并简化别名分析,它们没有统一或分解为较低级别的操作。
| Description | |||
|---|---|---|---|
| ALOAD | aref | Array load | |
| HLOAD | href | Hash load | |
| ULOAD | uref | Upvalue load | |
| FLOAD | obj | #field | Object field load |
| XLOAD | xref | #flags | Extended load |
| SLOAD | #slot | #flags | Stack slot load |
| VLOAD | aref | Vararg slot load | |
| ASTORE | aref | val | Array store |
| HSTORE | href | val | Hash store |
| USTORE | uref | val | Upvalue store |
| FSTORE | fref | val | Object field store |
| XSTORE | xref | val | Extended store |
FLOAD并SLOAD内联它们的内存引用,所有其他加载和所有存储都将内存引用作为其左操作数。除了标签值之外的所有加载FLOAD,XLOAD并同时作为一个受保护的断言来检查加载的类型。
FLOAD并FSTORE访问对象内部的特定字段,由其引用的字段 ID 标识(例如,表或用户数据对象中的元表字段)。
XLOAD适用于较低级别的类型,并且内存引用是 a STRREF或分解为较低级别的操作、指针、偏移量或索引的组合 ADD或组合MUL。BSHL
的槽号SLOAD是相对于跟踪的起始帧的,其中#0 表示闭包/帧槽,#1 表示第一个可变槽(对应于字节码的槽 0)。请注意,RETF下移 BASE 和后续SLOAD指令指的是较低帧的插槽。
请注意,堆栈插槽或可变参数插槽没有存储操作。所有堆垛槽的商店都有效地沉入出口或侧面痕迹。快照有效地管理要存储的引用。从被调用的可变参数函数的角度来看,可变参数插槽是只读的。
对于字段 ID 的可能值FLOAD和 和 中的标志 SLOAD,XLOAD请参阅 IRFLDEF、IRSLOAD_* 和 IRXLOAD_* 中 src/lj_ir.h。
Allocations
| Description | |||
|---|---|---|---|
| SNEW | data | length | Allocate interned string |
| XSNEW | data | length | Allocate interned string from cdata |
| TNEW | #asize | #hbits | Allocate Lua table with minimum array and hash sizes |
| TDUP | template | Allocate Lua table, copying a template table | |
| CNEW | ctypeid | (size) | Allocate mutable cdata |
| CNEWI | ctypeid | val | Allocate immutable cdata |
SNEW仅用于引用保证保持不变的数据,例如其他字符串。这允许在不使用字符串对象的情况下消除分配(它的数据可能仍被使用)。这个假设不适用于由 引用的数据ffi.string(),它必须发出XSNEW。
分配的 cdata 对象的大小CNEW是CNEWI从 ctypeid 操作数推断出来的。对于变长 cdata,大小由大小操作数明确给出,否则大小操作数为 REF_NIL。
CNEWI仅用于不可变的标量 cdata 类型。它结合了分配和初始化。右操作数给出的值被隐式存储。这缩短了 IR 并将分配下沉转变为简单的死代码消除(仅适用于不可变类型 -更涉及通用分配下沉优化)。
Barriers
| Description | |||
|---|---|---|---|
| TBAR | tab | Table write barrier | |
| OBAR | obj | val | Object write barrier |
| XBAR | XLOAD/XSTORE optimization barrier |
TBAR并且OBAR是增量 GC 所需的写屏障。 OBAR目前仅用于商店升值。这些障碍被放置在相应的商店之后。
XBAR防止优化XLOAD和XSTORE跨越障碍。请注意,CALLX*隐含地充当这样的屏障。
Type Conversions
| Description | |||
|---|---|---|---|
| CONV | src | #flags | Generic type conversion |
| TOBIT | num | bias | Convert double to integer with Lua BitOp semantics |
| TOSTR | number | Convert double or integer to string | |
| STRTO | str | Convert string to double |
的偏置操作数TOBIT引用浮点常数 2^52+2^51,它被添加到 FP 数上。结果的低 32 位表示以 2^32 为模的整数分量(在一定范围内,请参阅Lua BitOp 语义。
flags 操作数的低 5 位CONV指定源类型,接下来的 5 位指定目标类型(与 IR 指令结果类型相同)。第 10 位指定 FP 到整数转换的截断行为,第 11 位指定扩大整数转换的符号扩展。位 12 和 13 指定检查(保护)从双精度数到整数的转换的强度:1 表示任何 FP 数都可以,2 和 3 表示检查 FP 数的整数。2 为索引转换的反向传播启用了特殊规则。
Calls
| Description | |||
|---|---|---|---|
| CALLN | args | #ircall | Call internal function (normal) |
| CALLL | args | #ircall | Call internal function (load) |
| CALLS | args | #ircall | Call internal function (store) |
| CALLXS | args | func | Call external function (store/barrier) |
| CARG | args | arg | Call argument extension |
对内部函数的调用分为三类:
- 正常调用可以像大多数算术运算一样被共同和消除。
- 对于执行加载(例如
lj_tabl_len())的调用,编译器必须检查干预存储。 - 无法消除执行存储的调用(但如果这样的优化是有益的,它们可能会被沉没)。
有关 ircall 操作数的可能值,请参阅src/lj_ircall.h。
FFI 发出CALLXS对外部函数的调用。它们通常被认为是商店,不能被淘汰。它们形成了XLOAD和XSTORE指令的隐式优化屏障。
CARGcall 指令的 args 操作数使用扩展指令引用左倾参数树:
- func(): args = REF_NIL
- 函数(arg1):args = arg1
- 函数(arg1,arg2):args = CARG(arg1,arg2)
- 函数(arg1,arg2,arg3):args = CARG(CARG(arg1,arg2),arg3)
- 等等
func 操作数CALLXS要么直接引用函数CARG指针,要么为非标准调用约定(例如可变参数调用)保存函数指针和 ctypeid。
Miscellaneous Ops
| Description | |||
|---|---|---|---|
| NOP | No operation | ||
| BASE | #parent | #exit | BASE reference, link to parent side exit |
| PVAL | #pref | Parent value reference | |
| GCSTEP | Explicit GC step | ||
| HIOP | left | right | Hold hi-word operands of split instructions |
| LOOP | Separator before loop-part of a trace | ||
| USE | ref | Explicit use of a reference | |
| PHI | left | right | PHI node for loops |
| RENAME | ref | #snap | Renamed reference below snapshot |
NOP用于修补先前发出的 IR 指令,以防它们无法即时消除或忽略。
BASE是 REF_BASE 处的固定指令,用于保存 BASE 指针。它由 eg 隐式引用SLOAD。
PVAL提供了一种替代方法来引用父跟踪的特定值,这些值不能被父引用SLOAD(因为它们没有存储在快照的堆栈中)。
GCSTEP为某些需要在初始快照之后完成的情况提供显式 GC 步骤。
HIOP必须立即遵循拆分指令(拆分 64 位操作或软 fp 操作)。
USE需要为它们的副作用保留指令,否则这些副作用将被消除:例如ADDOV,用于检查循环边界的潜在整数溢出。
PHI指令位于循环跟踪的末尾。左操作数保存对初始值的引用,右操作数保存对每次循环迭代后的值的引用。
RENAME由寄存器分配器在为某个值重命名寄存器时生成(为了提高效率或保留 PHI 寄存器)。一条 RENAME指令保存用于在给定快照下方引用的寄存器。对于同一个参考,可能会出现多个这种情况。最初引用的指令保存上面使用的最高此类快照(如果有)的寄存器。
字节码优化
单通道解析器将 Lua 源代码转换为 LuaJIT字节码。字节码对动态类型的值进行操作,并且具有非常接近源代码的语义。这就是为什么可以对字节码本身执行相对较少的优化的原因——它们中的大多数都不是动态语言中的有效转换。
类似地,字节码的虚拟寄存器分配紧跟 Lua 源代码中局部变量的作用域。没有尝试最小化或重叠局部变量的生命周期(虚拟寄存器既便宜又充足)。
恒定折叠
对所有算术运算符(+ - * / % ^ 和一元减号)和逻辑运算符执行常量折叠not。如果输入仅由常数组成,则输出也会变成常数。例如,这是字节码return 1.5 * 3:
0001 KNUM 0 0 ; 4.5
0002 RET1 0 2乘法已被消除,只返回其结果。
优化复合条件
像这样的复合条件表达式x < 10 and x or 10被转换为一系列分支,而不是将中间表达式评估为布尔值。逻辑运算符and永远or不会出现在字节码中。not仅当结果在逻辑结果上下文之外使用时才会出现。例如,这是字节码 return a < b and x or y:
0001 GGET 0 0 ; "a"
0002 GGET 1 1 ; "b"
0003 ISGE 0 1
0004 JMP 0 => 0008
0005 GGET 0 2 ; "x"
0006 IST 0
0007 JMP 1 => 0009
0008 => GGET 0 3 ; "y"
0009 => RET1 0 2消除条件
如果输入是常数,则可以消除条件。这仅适用于“真实性”测试。例如,这是字节码 return "a" and 99:
0001 KSHORT 0 99
0002 RET1 0 2"a"已取消对 的真实性的检查。
一个更常见的习语是cond and x or y,它可用作三元条件句。但是行为是不一样的,因为x被评估并且不能是false或nil(或者成语会失败)。然而x ,很多时候是一个常数。例如,这是字节码 return a and 10 or 20:
0001 GGET 0 0 ; "a"
0002 ISF 0
0003 JMP 1 => 0006
0004 KSHORT 0 10
0005 JMP 1 => 0007
0006 => KSHORT 0 20
0007 => RET1 0 210已取消对 的真实性的测试。
消除不需要的结果
逻辑运算符计算实际结果,例如print("a" and 99) prints 99。if但是在逻辑结果上下文(例如语句)中不需要此结果。例如,这是字节码 if "a" and 99 then end:
0001 RET0 0 1条件及其结果已被消除。
不需要的调用结果也被消除:例如,CALL* 指令被修补以不返回任何结果。
跳跃折叠
导致其他跳跃的无条件跳跃被折叠成到最终目标的跳跃。类似地,在作用域结束时关闭 upvalues 通常会跟随一个跳转。然后将跳转折叠到UCLO接受分支目标的 中。
模板表
Lua 可以用作数据描述语言,这通常涉及创建用许多常量初始化的表。不是分配一个空表并生成大量显式存储,而是由解析器生成一个模板表。使用指令可以非常快速地复制模板表TDUP(复制是必要的,因为结果表可能会被修改)。
也允许混合常量和变量初始化器。仅当表构造函数表达式中存在至少一个常量初始值设定项(常量键和常量值)时,才会创建模板表。例如,这是字节码return { foo=1, bar=2, 1,2,x,4 }:
0001 TDUP 0 0
0002 GGET 1 1 ; "x"
0003 TSETB 1 0 3
0004 RET1 0 2所有常量初始化器都合并到模板表中。只有存储操作t[3] = x保留在字节码中。
指令和操作数专业化
许多字节码指令具有用于常用操作数类型或操作数数量的特殊形式。这降低了调度成本,因为它消除了(通常是不可预测的)实现内部的分支:
- 每种常量类型(和范围)都有专门的常量负载。例如
KSTR加载字符串常量。或者KSHORT加载 16 位有符号整数常量,而KNUM加载所有其他数字常量。 - 比较和测试操作员专门针对他们的测试方向。例如,两者都有
ISTandISF,它们会跳到真假上。与出于相同目的使用单个指令和操作数相比,这节省了分派。 - 如果操作数之一是常数,则相等性比较专门针对操作数类型。例如
ISEQN,是与数字常量的相等比较。 - 算术指令专门用于在左侧或右侧具有数字常量的常见情况。例如
ADDVN,右边是一个数字常数的加法。 - 设置上值是专门针对操作数类型的。例如
USETN用于存储数字常数。 - 索引操作专门针对 getter 和 setter 以及索引操作数类型和范围。例如
TGETB,用于具有常量整数索引 0 到 255 的加载,或者TSETS用于具有常量字符串键的存储。 - 调用专门分为常规调用
CALL和尾调用CALLT。 - 返回 0 或 1 个结果,使用
RET0或RET1代替泛型RET。 - 使用多个结果的调用、返回和表初始值设定项是专门的。例如
CALLM,是一个将多个结果作为参数传递的调用。 - 每种类型的循环都使用自己专门的字节码指令。例如,
*FOR*指令用于数字“for”循环。 - 循环使用
pairs()使用专门的ISNEXT和ITERN指令。 - 函数头专门用于固定参数与可变参数函数以及 Lua 函数与 C 函数与快速函数。例如
FUNCV,是 vararg Lua 函数的函数头。
有关更多详细信息,请参阅字节码指令的描述。
SSA IR 优化
去做
TRACE:区域选择
NLF:自然循环优先
热点检测
处罚和黑名单
函数内联
尾声消除
递归展开
控制流优化
记录:跟踪记录
即时 SSA 转换
构造不可变的上值
升值别名分析
数据流分析
稀疏快照
一维快照压缩
控制流专业化
哈希键专业化
快速函数内联
字节码修补
折叠:折叠引擎
恒定折叠
代数简化
强度降低
重新关联
CSE:通用子表达式消除
ABC:数组边界检查消除
标量演化分析
NARROW:缩小
缩小整数转换
算术运算符的缩窄
归纳变量的预测缩小
消除溢出检查
MEM:内存访问优化
AA:别名分析
ESC:逃逸分析
索引重新关联
FWD:加载转发、存储转发
DSE:死店消除
读取-修改-写入简化
LOOP:循环优化
DCE:死代码消除
通过合成展开的循环不变提升
PHI 消除
不稳定的循环展开
SPLIT:指令拆分
FFI64:64 位指令拆分
SOFTFP:FP 值拆分和软浮点调用
SINK:分配下沉和存储下沉
如果可能,分配下沉和存储下沉尝试消除代码快速路径中的临时分配。
详细信息可以在这里找到:分配下沉优化
ASM:汇编器后端
反向代码生成
DCE:即时死码消除
线性扫描寄存器分配
注册提示
注册重命名
注册合并
PHI 寄存器洗牌
重新实现
不断合成
溢出和恢复调度
循环反转
循环对齐
GC 步骤消除
FUSE:操作数融合
教学专业化
指令结合
机器码补丁
以上是官方文档没有内容,不是没有翻译
非公开 jit.* API
LuaJIT 有一些未记录的工具用于跟踪程序执行以及跟踪编译器正在做什么。下面的内容有点粗糙、不准确、可能会发生变化并且非常不完整。这可能是没有记录的一个很好的理由。
这些函数在几个 -j 库文件中使用。 dump.lua可能是一个很好的起点。
jit.attach
您可以使用jit.attach. 可以调用回调:
- 当一个函数被编译为字节码(“bc”);
- 当跟踪记录开始或停止时(“跟踪”);
- 正在记录痕迹(“记录”);
- 或者当跟踪通过侧出口(“texit”)退出时。
设置回调jit.attach(callback, "event")并清除相同的回调jit.attach(callback)
传递给回调的参数取决于所报告的事件:
- “bc”:
callback(func)。func是刚刚录制的函数。 - “trace”:
callback(what, tr, func, pc, otr, oex)what是对跟踪事件的描述:“flush”、“start”、“stop”、“abort”。适用于所有活动。tr是跟踪号。不可用于冲洗。func是被跟踪的函数。可用于启动和中止。pc是程序计数器 - 被记录的函数的字节码编号(如果这是一个 Lua 函数)。可用于启动和中止。otr开始:父跟踪号,如果这是边跟踪,中止:中止代码(整数)?oexstart:父跟踪的退出号,abort:中止原因(字符串)
- “record”:
callback(tr, func, pc, depth)。第一个参数与跟踪启动相同。depth是当前字节码的内联深度。 - “texit”:
callback(tr, ex, ngpr, nfpr)。tr是跟以前一样的跟踪号ex是出口号ngpr和nfpr是在出口处活动的通用和浮点寄存器的数量。
jit.util.funcinfo(func, pc)
当从回调中传递时, func返回一个关于函数的信息表,很像.pcjit.attachjit.util.funcinfodebug.getinfo
该表的字段是:
linedefined: 至于debug.getinfolastlinedefined: 至于debug.getinfoparams: 函数接受的参数个数stackslots: 函数局部变量使用的栈槽数upvalues:函数使用的上值数bytecodes: 编译函数的字节码数gcconsts: ??nconsts: ??currentline: 至于debug.getinfoisvararg:如果函数是可变参数函数`source: 至于debug.getinfoloc: 描述源和当前行的字符串,如 "<source>:<line>"ffid: 函数的快速函数 id(如果它是一个)。在这种情况下,只有upvalues上面和addr下面是有效的addr: 函数的地址(如果不是 Lua 函数)。如果它是 C 函数而不是快速函数,upvalues则仅上述有效
新的垃圾收集器
介绍
以下设计文档描述了 LuaJIT 3.0 引入的新垃圾收集器 (GC)。这份文件目前在很大程度上是一项正在进行的工作。实际实施可能会发生任何变化。目前还没有可用的代码。
本文档的目的是收集所有设计方面的早期反馈,并向赞助商展示计划中的工作。
潜在赞助商注意:此功能需要赞助!LuaJIT 3.0 的工作可能不会开始,直到我能够为这个和其他计划的新特性获得完整的契约。请参考 LuaJIT 赞助页面。谢谢!
您可能需要至少有一些垃圾收集算法的背景知识才能充分享受以下文档。有大量的书籍、研究论文和其他免费可用的在线资源。一个好的开始是 关于垃圾收集的维基百科文章。
基本原理
LuaJIT 2.0 使用的垃圾收集器与 Lua 5.1 GC 基本相同。写入障碍和一些速度优化有一些小的改进。但基本算法和数据结构没有改变。
与其他语言运行时的实现相比,当前的垃圾收集器相对较慢。它与顶级 GC 没有竞争力,尤其是对于大型工作负载。造成这种情况的主要原因是独立的内存分配器、缓存效率低的数据结构和大量的分支错误预测。当前的 GC 设计在进一步的性能调整方面是一条死胡同。
需要的是从头开始完全重新设计,并实现以下目标:
- 它必须是一个非常快速、顶级、竞争激烈的垃圾收集器。
- 它必须能够维持高吞吐量和大工作量。
- 但它应该在合理的最小内存量下运行良好。
- 它需要以非常低的延迟增量(但不是实时)。
- 由于 Lua/C API 中的各种限制,它必须是不可复制的。
- 但它需要严格控制碎片。
- 它不需要并发,因为 Lua 状态是完全独立的。
- 为某些工作负载提供(自动)分代模式会很好。
- 它应该通过解释器和 JIT 编译器的组合来优化操作。
- 它需要额外的调试和分析支持,因为常规工具(Valgrind memcheck 等)将不再有效。
- 总体实现复杂度应保持尽可能低。
这导致以下实施限制:
- 内存分配器和垃圾收集器必须紧密集成。
- 应尽可能避免使用纯链表。
- 数据结构应针对高速分配、遍历、标记和扫描进行优化。
- 对象元数据,例如标记和块信息应该被隔离。
- 巨大的物体应该被隔离。
- 可遍历和不可遍历的对象应该分开。
- 遍历应该是线性的或至少具有很强的局部性。
- 内存只能以大块的形式从操作系统请求和返回。
创建一个高度复杂和实验性的垃圾收集器显然不是目标,它也顺便解决了世界上的饥饿问题,但需要比 Eclipse 更多的内存才能顺利运行。:-)
新的垃圾收集器应该基于经过充分研究和验证的算法,以及一些经过全面评估的创新(在适当的情况下)。真正的创新应该是在特定的技术组合上,形成一个连贯而平衡的系统,对细节一丝不苟,对性能进行不懈的优化。
概述
新的垃圾收集器是基于竞技场的、四色增量、分代、非复制、高速、缓存优化的垃圾收集器。
内存在大对齐的内存块中从操作系统请求,称为 arenas。Arenas被分成 16 字节大小的单元。一个或多个单元组成一个块,是用于存储对象和相关对象数据的基本内存单元。竞技场内的所有对象要么是可遍历的,要么是不可遍历的。块位图和标记位图 保存在每个 arena 的元数据区域中,元数据开销为 1.5%。大块位于单独的内存区域中。
指向 arena、巨大块、实习字符串、弱表、终结器等的指针保存在专用的、缓存高效的数据结构中,从而最大限度地减少分支错误预测。例如散列、展开的链表或具有高扇出的树。
根据碎片压力,分配器从一个凹凸分配器即时切换到一个 隔离适合、具有有界搜索的最佳适合分配器。
收集器是一个四色增量标记和扫描收集器 ,延迟非常低。遍历对于竞技场来说是本地的并且表现出高缓存局部性。甚至不需要考虑具有不可穿越对象的竞技场。对象标记和超快速扫描阶段仅适用于元数据以减少缓存压力。扫描阶段既不会将活动对象数据也不会将死对象数据带回缓存。
增量 GC的写屏障非常便宜,很少触发。顺序存储缓冲区 (SSB) 有助于进一步减少开销。写屏障检查只需 2 或 3 条机器指令即可完成。JIT 编译器可以消除大多数写障碍。
收集器根据工作负载特征自动在常规模式和分代模式之间切换 。
GC 算法
这是 Lua 5.x 和 LuaJIT 1.x/2.0 中使用的不同 GC 算法以及 LuaJIT 3.0 中提议的新 GC 的简短概述。
所有这些实现都使用具有两个基本阶段的跟踪垃圾收集器 (#):
- 标记阶段从 GC 根(例如主线程)开始,并迭代地标记所有可到达(活动)对象。任何剩余的对象都被认为是不可访问的,即已死。
- 扫描阶段释放所有无法到达(死)的对象。
任何实际的 GC 实现都有几个阶段(例如原子阶段),但这与下面的讨论无关。为了避免递归算法,可以使用标记堆栈或标记列表来跟踪需要遍历的对象。
请注意,以下大部分内容只是描述成熟的技术。有关详细信息,请参阅有关垃圾收集的文献。
(#) 在这种情况下,“跟踪”意味着它通过活动对象图进行跟踪,而不是引用计数垃圾收集器,后者管理每个对象的引用计数。该术语与跟踪编译器的概念无关。
双色标记和扫描
这是经典的(非增量)双色标记和扫描算法:
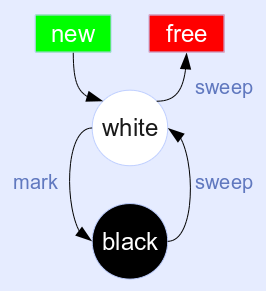
新分配的对象是白色的。标记阶段将所有可到达的对象变为黑色。扫描阶段释放所有白色(无法到达)对象并将所有黑色(幸存)对象的颜色翻转回白色。
该算法的主要缺点是 mutator(您正在运行的程序代码)不能与收集器交错运行。一个收集周期必须完全完成,这意味着该算法是非增量的(原子收集)。
有各种优化,例如可以在每次 GC 循环后切换两种颜色的含义。这节省了扫描阶段的颜色翻转。您可以在文献中找到很多变体。
这是 Lua 5.0 使用的 GC 算法。所有对象都保存在一个链表中,该链表在标记和扫描阶段进行处理。已标记并需要遍历的对象链接在单独的标记列表中。
三色增量标记和扫描
这是 Dijkstra 的三色增量标记和扫描算法:
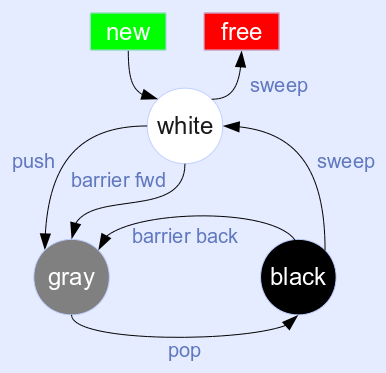
新分配的对象是白色的。标记阶段从 GC 根开始。标记可达对象意味着将其颜色从白色翻转为灰色并将其推入灰色堆栈(或将其重新链接到灰色列表中)。灰色堆栈被迭代处理,一次移除一个灰色对象。遍历一个灰色对象,并标记所有可从它到达的对象,如上所示。对象被遍历后,它会从灰色变为黑色。扫描阶段就像上面的双色算法一样工作。
这个算法是增量的:收集器可以小步操作,只处理灰色堆栈中的几个对象,然后让 mutator 再次运行一段时间。这将 GC 暂停分散到许多短时间间隔中,这对于高度交互的工作负载(例如游戏或 Internet 服务器)很重要。
但是有一个问题:mutator 可能会妨碍收集器并将对白色(未处理)对象的引用存储在黑色(已处理)对象中。这个对象永远不会被标记并且会被扫描释放,即使它显然仍然是从一个可达对象引用的,即它应该保持活动状态。
为了避免这种情况,必须保留三色不变量:黑色对象可能永远不会持有对白色对象的引用。这是通过写屏障完成的,必须在每次写入后检查。如果违反了不变量,则需要进行修复步骤。有两种选择:
- 将黑色对象变为灰色并将其推回灰色堆栈。这是将屏障“向后”移动,因为稍后必须重新处理对象。这对容器对象是有益的,因为它们通常会连续接收多个存储。这避免了存储在其中的下一个对象(也可能是白色的)的障碍。
- 或者立即标记白色物体,将其变为灰色并将其推入灰色堆栈。这将屏障“向前”移动,因为它隐式地推动 GC 向前。这对于只接收独立存储的对象最有效。
有许多优化可以把它变成一个实用的算法。以下是最重要的:
- 堆栈应始终保持灰色并在最终扫描阶段之前重新遍历。这避免了存储到堆栈槽的写入障碍,这是最常见的存储类型。
- 没有引用子对象的对象可以立即从白色变为黑色,不需要经过灰色堆栈。
- 可以通过使用两个白色并在进入扫描阶段之前在它们之间翻转来使扫描阶段递增。需要保留具有“当前”白色的对象。只有具有“其他”白色的对象才能被释放。
这是 Lua 5.1/5.2 和 LuaJIT 1.x/2.0 使用的 GC 算法。它是对 Lua 5.0 中链表算法的增强。表使用后向障碍,所有其他可遍历对象使用前向障碍。
LuaJIT 2.0 进一步优化了表的写屏障,只检查黑色表,忽略存储对象的颜色。这可以更快地检查并且仍然安全:写屏障可能会更频繁地触发,但这没有害处。在实践中这并不重要,因为 GC 周期进展非常快并且中间有很长的停顿,所以对象很少是黑色的。无论如何,存储的对象通常也是白色的。
四色优化增量标记和扫描
四色算法是三色算法的改进:
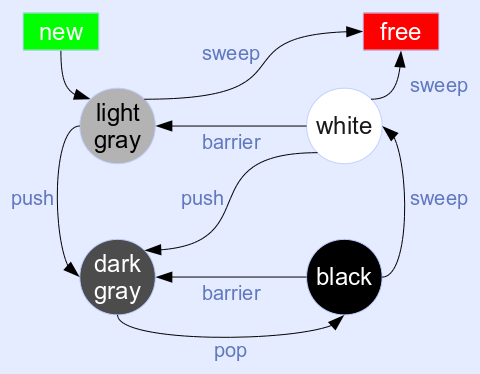
用于后向屏障的三色算法存在一个问题:如果标记位不在对象本身内联,则写屏障检查可能会变得很昂贵。但是,当屏障触发时,必须先对黑色物体进行精确检查,然后再将其变为灰色。唉,标记位(白色与黑色)在新的 GC 中被隔离,只有灰色位在对象中是内联的。
仅检查“非灰色”不是一个好主意:白色和黑色对象都会触发写入屏障,总是在第一次写入时将它们变为灰色。这对于 GC 暂停期间的白色对象尤其不利,因为大量灰色对象可能会不必要地堆积在灰色堆栈中。
解决方案是引入第四种颜色,将灰色分为浅灰色和深灰色。新分配的可遍历对象为浅灰色:标记位为白色,灰色位已设置。新对象通常在分配后立即写入。写屏障仅检查清除的灰色位,在这种情况下不会触发。
在标记阶段标记对象时,它会变为深灰色(标记位变为黑色)并被推入灰色堆栈。万一它无法到达,扫描阶段可以像任何其他标记为白色的对象一样释放浅灰色对象。
深灰色物体经过遍历(清除灰色位)后变黑,扫过后变白。写屏障可能会在此短时间内触发,并通过再次将其变为深灰色来将屏障移回。
在一个 GC 周期中幸存下来的对象会像所有其他幸存者一样变成白色。如果对象在那之后被写入,它会再次变成浅灰色。但这不会立即将对象推到灰色堆栈上!事实上,只需要翻转灰色位,这避免了如上所述的进一步障碍。
四色算法的主要优点是超便宜的写屏障:只需检查灰色位,只需要 2 或 3 条机器指令。并且由于初始着色和特定的颜色转换,在实践中几乎不会触发例如表格的写入障碍。写屏障的快速路径不需要访问标记位图,避免了在 mutator 运行时被 GC 元数据污染缓存。
对于某些可遍历对象,四色算法可以很容易地退回到三色算法,方法是最初将它们变为白色并使用前向写入屏障。并且对于不可遍历的对象有一个明显的捷径:标记立即将白色对象变为黑色,这仅触及标记位图。由于这些对象位于隔离的区域中,因此不需要遍历它们,并且在标记阶段也不需要将它们的数据带入缓存。
这是 LuaJIT 3.0 使用的 GC 算法。对象和分离的元数据在 arenas 中管理(而不是在链表中)。
有各种其他 GC 算法使用标准颜色以外的颜色,例如两个白色(见上文)。然而,他们都没有像这个算法那样使用颜色。此外,搜索“四色”GC(或变体)并没有任何结果。在没有相反证据的情况下,我(Mike Pall)特此声称发明了这个算法。如果您不同意,请立即通知我。与我在 LuaJIT 上的所有研究成果一样,我特此将相关知识产权捐赠给公共领域。所以请使用它,分享它,玩得开心!
分代GC
分代 GC 的标准方法仅适用于复制 GC:
- 为每一代使用单独的内存空间(2 个或更多,通常为 3 个)。
- 新对象被分配到专用于最年轻一代的空间中。
- 扫描阶段被复制阶段取代,复制阶段将 GC 周期的幸存者复制到老年代。之后可以简单地清空剩余空间。
- 只有最老的一代必须使用传统的扫描阶段或标记和紧凑型收集器。
显然,这种方法不适用于非复制 GC。但是可以抽象出分代 GC 背后的主要见解:
- 次要集合只处理新分配的对象。
- 主要集合处理所有对象,但运行频率要低得多。
基本思想是修改扫描阶段:释放(无法到达的)白色对象,但在次要收集之前不要翻转黑色对象的颜色。接下来的次要集合的标记阶段只遍历新分配的块和写入的对象(标记为灰色)。假设所有其他对象在次要 GC 期间仍然可以访问,并且既不会遍历,也不会扫描,也不会更改它们的标记(保持黑色)。如果要进行主要收集,则使用常规扫描阶段。
收集器的分代模式由年轻分配死亡率高的工作负载自动触发。运行(比如说)五个只处理年轻分配的次要收集加上一个主要收集应该比在同一时间跨度内运行(比如说)两个主要收集便宜。并且最大内存使用量也应该更低。收集器返回到常规的非分代模式,以防这些假设结果不成立。
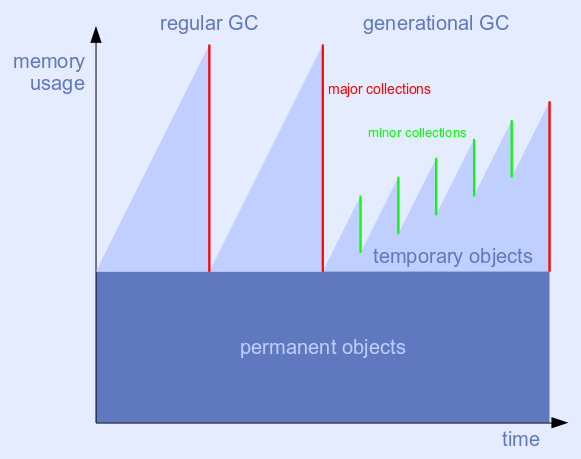
显示的图像大大简化:分配和幸存率是恒定的;永久物体不会改变;集合是原子的。
Arenas
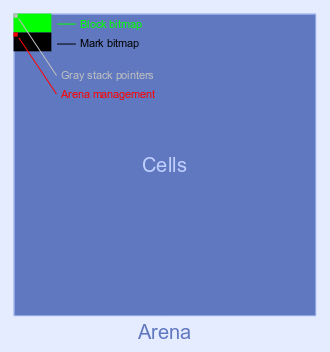
arena 是一个很大的、特别对齐的内存块。使用系统特定代码直接从操作系统请求竞技场。为非标准操作系统或嵌入式使用提供了通用内存管理 API。一个简单的“一个固定块”内存管理器可用作构建时选项。
所有竞技场都具有相同的大小,并且它们自然地与它们的大小对齐。例如,64 KB 大小的 arena 具有以 16 个零位结尾的地址。这有两个优点:
- 对齐的 arena 可以密集打包,并且不会对操作系统造成任何额外的内存碎片问题。
- 只需通过屏蔽地址的最低位,就可以从任何内部指针导出其竞技场的元数据区域。
竞技场内的所有对象要么是可遍历的,要么是不可遍历的。只有不可遍历对象的 Arenas 显然根本不需要遍历。而且也不需要在这些对象中存储对象类型。
竞技场大小可以是从 64 KB 到 1 MB 的任何 2 的幂。每个操作系统和 CPU 的最佳竞技场大小仍需要通过实验确定。内存管理器可能会向操作系统请求更大的块(例如 2 MB 或 4 MB 用于支持大页面)并将它们拆分。
每个 arena 的 1/64 空间专用于元数据区域,导致 1.5% 的固定开销。元数据区域位于每个竞技场的开头。剩余空间用于数据区。下图显示了竞技场的总体布局:
单元格和块
每个 arena 的数据区域被分成 16 字节大小的单元。一个或多个单元组成一个块,是用于存储对象和相关对象数据的基本内存单元。
一个单元(或一个块)的索引可以从它的起始地址得出:屏蔽掉标识竞技场的最高位,并将得到的相对地址向右移动 4 位以获得单元索引。
单元索引不从零开始,因为第一个索引将指向元数据区域。单元索引始终适合 16 位,因为最大区域大小为 1 MB。
块和标记位图
块和标记位图构成了每个竞技场元数据区域中的大部分空间。这两个位图被隔离以实现更好的缓存行为。每个单元在块位图和标记位图中都有一个关联的位。每个位图中的位索引对应于单元格索引。
这两个位图确定了竞技场的块及其状态:
| 堵塞 | 标记 | 意义 |
|---|---|---|
| 0 | 0 | 块范围 |
| 0 | 1 | 空闲块 |
| 1 | 0 | 白块 |
| 1 | 1 | 黑方块 |
这是一种差分编码:块的类型(自由、白色或黑色)由其第一个单元确定。一个块可以跨越多个单元格,它通过块范围进行扩展。
例如,一个包含 3 个单元的白色块,后跟一个包含 1 个单元的空闲块和一个包含 2 个单元的黑色块,编码为:
10 00 00 01 11 00
优点是第一个单元只需要翻转一个或两个位就可以改变整个块的状态:分配一个块只需要设置块位;标记一个块只需要设置标记位。
其他元数据
由于单元索引不从零开始,块和标记位图的前几个字节可用于与竞技场相关的其他元数据。至少 16 个字节可用于区域管理和灰色堆栈指针,因为最小区域大小为 64 KB。
巨大的积木
大块位于单独的连续内存区域中。它们的大小始终是竞技场大小的倍数,并且它们服从竞技场对齐。从常规块分配切换到大块分配的最佳大小阈值仍需要通过实验确定。
大块前面没有额外的标题。相反,所有元数据(地址、大小、标记和灰度位)都存储在一个单独的哈希表中,由块地址作为关键字。
块分配器
块分配器根据请求的大小从竞技场或大块中为块分配空间。块分配器具有不同的模式并在它们之间动态切换,具体取决于碎片压力和来自 GC 阶段的其他反馈。
大块通过内存管理器直接从操作系统分配。
凹凸分配器
标准块分配器是一种高速凹凸分配器。它在给定的内存空间上运行并分配连续的内存块,直到它到达给定空间的末尾。它在 arena 内的大型可用内存空间上效果最佳。
凹凸分配器只需要设置块位并为每个分配的块“凹凸”一个指针,这使得它非常快。这少量的逻辑甚至可以内联在性能关键代码中。
只要有足够大的内存区域并且碎片压力较低,就会使用凹凸分配器。
适合分配器
如果碎片压力变得太高,分配器会自动切换到具有有界搜索的隔离拟合、最佳拟合分配器。这种分配器比凹凸分配器更昂贵,但它能够通过在严重碎片化的领域中“填补漏洞”来减少整体碎片化。
分配器是一个隔离适合的分配器:请求的分配根据它们的大小类被分成多个箱。尺寸等级从单元尺寸的倍数开始,然后切换到 2 的幂以获得更大的尺寸。每个 bin 都是该大小类中空闲块列表的锚。最初所有的箱子都是空的。为了最大限度地减少启动延迟并避免不必要的工作,分配器动态构建其数据结构。
分配器首先尝试为请求的大小类进行最合适的分配。如果相应的 bin 是空的,则启动一个简短的有限努力清除阶段,该阶段扫描块映射以查找孤立的空闲块并将它们链接到它们相应的 bin。
如果这没有找到最合适的分配,则分配器会降级为第一个合适的分配器,将候选块分成有限数量的更高大小的类。如果没有找到,它会退回到凹凸分配器,可能是从新创建的竞技场分配的。
分配器是自适应的:如果第一次适合的分配器的未命中率很高,则随后搜索更多更大尺寸的类。如果最佳匹配分配器的命中率变得更好,则再次降低此限制。
在碎片减少到某个阈值以下之后,分配器切换回凹凸分配器。
标记阶段
所有活动对象的标记都是迭代执行的,使用先进的缓存优化数据结构来保存要标记的对象。
写屏障
写屏障只需要检查存储的对象的灰色位。这是一个非常快速的测试,只有在未设置灰色位时才会触发(这种情况很少见)。
如果写入屏障被触发,白色物体会变成浅灰色,黑色物体会变成深灰色。深灰色对象还被推送到快速顺序存储缓冲区 (SSB)。
浅灰色对象不需要被推到 SSB 上,但这需要检查标记位。如果触发屏障的性能成为问题,则可以避免这种情况。可以改为对 SSB 溢出进行检查。当收集器暂停时,可以完全避免对标记位的检查,因为不能有任何黑色物体。
顺序存储缓冲区
顺序存储缓冲区 (SSB) 是一个小型缓冲区,用于保存触发写屏障的对象的块地址。它总是至少有一个空闲槽,所以最后可以进行溢出检查。
如果 SSB 溢出,则通过将存储的对象地址转换为单元索引并将它们推入相应的灰色堆栈来清空它。这可能涉及多次分配和其他开销。
两步过程的优点是在 mutator 运行时由于 SSB 造成的缓存污染相对较低。
灰栈
每个具有可遍历对象的 arena 都有一个关联的灰色堆栈,其中保存所有灰色对象的单元格索引。灰色堆栈的内存是按需分配和增长的,不需要是竞技场本身的一部分。堆栈以哨兵开始并向下增长。
当一个对象被标记为深灰色时,它会被推入相应竞技场的灰色堆栈中。
为了提高缓存访问的局部性,每个 arena 的灰色堆栈被单独处理。从灰色堆栈中删除的对象在遍历之前变为黑色。遍历可能会标记其他对象,这些对象可能位于不同的领域。但是处理总是在当前竞技场继续进行,直到灰色堆栈为空。
灰色队列
灰色队列包含具有非空灰色堆栈的竞技场。灰色队列是一个优先级队列,按每个竞技场的灰色堆栈大小排序。这可确保首先处理最大的灰色堆栈。二叉堆用于实现优先级队列。对于具有相同优先级的元素,它的行为主要类似于堆栈 (LIFO)。
灰色队列被迭代处理,总是移除最高优先级的 arena 并处理它的灰色堆栈。当灰色队列为空(并且 SSB 也被清空)时,标记阶段结束。
扫描阶段
扫描阶段只需要访问每个竞技场的块和标记位图。它可以为每个竞技场单独执行。
根本不需要访问竞技场的数据区!与大多数其他 GC 布局相比,这是一个主要优势,因为它不会在扫描阶段将活对象数据和死对象数据带回缓存。
位图技巧
块和标记位图的特殊布局允许使用逐字并行位操作来实现扫描:
大扫除释放白色块并将黑色块变成白色块:block' = block & mark mark' = block ^ mark
次要扫描释放白色块,但保留黑色块: block' = block & mark mark' = block | mark
位分配的另一个方便的特性是,在算术上比较块字与标记字给出了以该字开头的最后一个块的状态:block' < mark' => free 跨字传播“空闲”状态允许粗略合并空闲块,可以组合进入扫荡。
所有这些都适用于任何字长:SIMD 操作可用于在 128 位上并行工作,即一次 2 KB 的单元。
扫描阶段仅在总内存的 1/64 上运行,并且能够使用完整的缓存或内存带宽,因为内存访问是严格线性的。与其他 GC 算法相比,这使得扫描阶段超快。
特别注意事项
堆栈
字符串
弱表
终结者
对象布局
对象标签
性能优化
缓存效果
分支预测
数据结构
颠簸前沿
隔离遍历
问题?
在此处添加您的问题,我会尽力澄清。 - 麦克风
Q:在四色系统中,扫一扫后,为什么不把黑色变成浅灰色而不是黑色变成白色?
答:因为黑色到浅灰色需要更改本地存储在每个对象中的“灰色”位(因此更改所有对象的成本很高)。
问:是否可以为新分配器设置最大内存限制,以获得适当的沙盒支持?
A : 是的,内置内存管理器有一个可配置的内存限制。粒度是竞技场大小。您可以插入自己的内存管理器以应对更复杂的场景。
问:你(迈克)打算什么时候写这个页面的缺失部分?(我最感兴趣的是“性能优化”部分
)
问:新的 gc 会支持完整的 64 位地址空间吗?
答:标记值中 GC 引用的存储布局是一个正交问题。
问:我喜欢四色标记/扫描,但我认为它需要进行两个更改,以便黑色始终“可达”,灰色始终“脏”(需要扫描):
- 白色的推弧应该变成黑色,而不是深灰色。仅仅因为您找到了指向它的指针而触摸该对象是不好的,因为该对象的实际标记可能在将来的某个时间。
- 从黑色到黑色的流行应该有一个自弧。或者,在白色和黑色之间插入一个新状态,它也是黑色,表示“干净,已知可到达,但尚未从(在标记堆栈上)标记”。push from white 进入这个新状态,pop 进入现有的黑色节点,表示“干净,已知可达,已经标记为(或正在进行)。对象中的灰色标志应该在它之后被清除(如果设置)从标记堆栈中删除,但在任何嵌入对象指针被推入标记堆栈之前。
答:当然,在那个时间点上,mutator 访问的所有对象都是可访问的。但这无关紧要。可达性最终由收集器决定。这只是一次运行结束时的快照。垃圾收集器的目标是不时释放绝对无法访问的对象,而不是不断更新每个对象的确切状态。
从白色到深灰色的推动弧用于将障碍物向前移动的变体(参见三色算法)。这仅对少数情况感兴趣(不适用于表格)。它不能变黑,因为这需要直接从 mutator 调用收集器的遍历阶段,这是一个非常糟糕的主意。
你所描述的已经被灰色状态解决了。除非有不同的定义,基于收集器时间,而不是突变器时间。
问:这似乎不是全部:“写屏障不需要访问标记位图,这样可以避免在 mutator 运行时用 GC 元数据污染缓存。”。真,如果灰色位已经设置。但是如果灰色位是明确的,那么不仅需要设置它,您还需要检查黑色位和 IFF 它是否已设置,然后将对象推入标记堆栈。例如
if (!obj->grey) setGrey(obj);
void setGrey(obj){
obj->grey = true;
if (isBlack(obj)){
// if black state has been split as suggested above, also
// need to check that it's not already on the mark stack
push(obj);
}
}答:不需要访问快速路径的标记位,即当写屏障没有触发时。
如前所述,写屏障在实践中几乎不会触发。如果它触发一个黑色对象,这意味着我们处于 GC 运行结束的短时间内,增量收集器与 mutator 竞争。这是更罕见的情况,然后由 mutator 发起推送并不重要,因为 GC 元数据无论如何都在缓存中。
也可以避免检查慢速路径中的标记位。见标记阶段写屏障的描述。
永远不需要检查对象是否已经在灰色堆栈上,因为如果灰色位已经设置,它永远不会到达代码的那部分
分配下沉优化
介绍
分配下沉和存储下沉优化于 2012年7 月添加到 LuaJIT 2.0。此页面记录了此优化的基本原理、使用的算法及其实现。也讨论了由此产生的性能并与其他语言进行了比较。
该优化的研究和开发在 2012 年得到了一位匿名企业赞助商的赞助。
尽管这种优化是基于其他众所周知的技术,但这种组合可能被认为是创新的。我(Mike Pall)特此将相关知识产权捐赠给公共领域。如果您觉得有用,请使用并分享!
基本原理
避免临时分配是高级语言的重要优化。分配是昂贵的并且会导致额外的开销,因为它们需要稍后被垃圾收集。可以通过相当大的努力降低成本(参见新垃圾收集器),但消除分配始终是最便宜的选择。
LuaJIT 已经通过多种技术消除了许多临时分配:例如,浮点数没有装箱,JIT 编译器消除了大多数不可变对象的分配。但是,仍然存在许多分配,尤其是在 OO 繁重的工作负载中。
避免临时分配的传统技术是逃逸分析和聚合标量替换 (SRA)。转义分析验证对象不会通过任何代码路径进行转义。但是为动态语言生成的代码有许多后备路径,例如处理动态类型。可悲的是,这意味着几乎任何对象都不可避免地会通过这些不常见的代码路径中的至少一个逃逸。这使得传统技术对动态语言无效。
激励例子
出于解释的目的,以下综合示例具有分配转义到的显式代码路径。当然,同样的底层逻辑也适用于由动态语言语义引起的隐式代码路径。
local x, z = 0, nil
for i=1,100 do
local t = {i}
if i == 90 then
z = t
end
x = x + t[1]
end
print(x, z[1])虽然不常见的代码路径i == 90只被采用一次,但传统的逃逸分析会失败,因为t 确实逃逸到 z控制流中的某一点。
[当然,没有理智的程序员会写出这样的代码。但它可能是由于高级语言抽象而间接产生的,例如在对聚合进行操作时。请参阅下面的一些实际示例。]
让我们看一下 IR 和 LuaJIT 在禁用下沉优化的情况下生成的快照 ( -O-sink)。仅显示跟踪的循环部分:
.... SNAP #4 [ ---- 0009 ---- 0010 ---- ---- 0010 ]
0012 ------ LOOP ------------
0013 > tab TNEW #3 #0
0014 p32 FLOAD 0013 tab.array
0015 p32 AREF 0014 +1
0016 num CONV 0010 num.int
0017 num ASTORE 0015 0016
.... SNAP #5 [ ---- 0009 ---- 0010 ---- ---- 0010 0013 ]
0018 > int NE 0010 +90
0019 + num ADD 0016 0009
0020 + int ADD 0010 +1
.... SNAP #6 [ ---- 0019 ---- ]
0021 > int LE 0020 +100
0022 int PHI 0010 0020
0023 num PHI 0009 0019如我们所见,TNEW指令 0013 中的表分配逃逸到侧出口 #5 的快照。更有趣的是看到负载t[1]已被消除。存储的值i(0010 处的左侧 PHI 操作数,未显示)已通过整数到数字的转换 (0016) 转发,然后添加到x指令 0019 中。x它本身通过侧出口 #6 逃逸,但分配在此之前已失效下一个循环迭代。
[注意:从侧面出口 #5 开始的代码路径永远不会编译,因为侧面出口的使用频率不够高。编译侧跟踪时会发生什么如下所示。]
上面讨论的问题的解决方案从观察开始:临时对象没有负载了!由于高级别名分析,LuaJIT 中的存储到加载转发通常非常有效地从临时对象中删除所有负载:它们只需替换为相应的存储值。
对临时分配的唯一引用是存储本身(通过上面示例中的 theAREF和 the FLOAD)。但是,如果稍后不在快速代码路径中使用分配,这些存储就毫无意义。因此,分配只是为了与其他代码路径保持一致而创建,但对快速路径没有实际功能。
现在的基本思想是将临时分配移到真正需要的地方。这是编译器术语中的“代码运动”。由于我们想将其移至代码的侧路径,因此更准确的术语是“下沉”。
这里还是上面的例子,但是在右侧手动应用了存储到加载转发和下沉:
local x, z = 0, nil | local x, z = 0, nil
for i=1,100 do | for i=1,100 do
local t = {i} | ---.
if i == 90 then | if i == 90 then |
| local t = {i} <--´
z = t | z = t |
end | end |
x = x + t[1] | x = x + i <--´
end | end
print(x, z[1]) | print(x, z[1])
您可以轻松验证两者是否产生完全相同的输出。但是手动优化的 Lua 代码的 IR 是非常不同的:
.... SNAP #4 [ ---- 0005 ---- 0006 ---- ---- 0006 ]
0008 ------ LOOP ------------
.... SNAP #5 [ ---- 0005 ---- 0006 ---- ---- 0006 ]
0009 > int NE 0006 +90
0010 num CONV 0006 num.int
0011 + num ADD 0010 0005
0012 + int ADD 0006 +1
.... SNAP #6 [ ---- 0011 ---- ]
0013 > int LE 0012 +100
0014 int PHI 0006 0012
0015 num PHI 0005 0011分配和相关存储从循环的快速路径中消失了,这意味着它将运行得更快!
目标
上述方法的主要创新是将 store-to-load-forwarding 与 store sinking 和 allocation sinking 结合起来。这在避免快速路径中的临时分配方面非常有效,即使在存在许多临时对象可能逃逸到的不常见路径的情况下也是如此。
这两种优化的组合与聚合的标量替换 (SRA) 具有相同的效果,但它适用于更多上下文。这种方法对动态语言最有效,但当经典技术失败时,可能会成功应用于其他地方。
目标是在可行且有利可图的情况下自动执行上述优化。
请注意,此优化完全消除了快速路径的分配。它不会将堆分配转换为堆栈分配。存储的值仍然有效,通常在寄存器中,有时在溢出槽中。但是,溢出槽的布局不需要匹配已分配对象的布局(也不适合传递给期望此类对象的 C 函数)。
缺失的细节
当然,上面的例子被大大简化了。在实践中,分配可能会逃逸到多个快照或同一快照中的多个堆栈槽。快照前后可能都有存储,它们甚至可能覆盖彼此的值。而且,最重要的是,临时分配可能保存在循环携带的变量中,这使分析更加复杂。
下沉一个逃逸到快照的分配意味着数据驱动的退出处理程序的额外工作:分配需要不沉没,即动态创建并且还需要执行相关的存储。
类似地,可能需要编译对应于具有下沉分配的快照的侧跟踪:需要在侧跟踪中重放分配和相关存储。当然,对于一个真正通用的解决方案,在侧面跟踪中重放的沉没分配可能会再次沉没。
相同的方法需要适用于所有类型的分配,而不仅仅是 Lua 表。可变和不可变 FFI 对象的临时分配也很常见。
例子
用于此优化的确切算法在下面的实现部分中进行了说明。为了更好地理解,本节显示了一系列示例的优化结果。
再次激励榜样
这是另一个激励示例,加上打开下沉优化的循环部分的 IR 和机器代码:
local x, z = 0, nil
for i=1,100 do
local t = {i}
if i == 90 then
z = t
end
x = x + t[1]
end
print(x, z[1]).... SNAP #4 [ ---- 0009 ---- 0010 ---- ---- 0010 ]
0012 ------------ LOOP ------------
0013 {sink} tab TNEW #3 #0
0014 p32 FLOAD 0013 tab.array
0015 p32 AREF 0014 +1
0016 xmm6 num CONV 0010 num.int
0017 {0013} num ASTORE 0015 0016
.... SNAP #5 [ ---- 0009 ---- 0010 ---- ---- 0010 0013 ]
0018 > int NE 0010 +90
0019 xmm7 + num ADD 0016 0009
0020 rbp + int ADD 0010 +1
.... SNAP #6 [ ---- 0019 ---- ]
0021 > int LE 0020 +100
0022 rbp int PHI 0010 0020
0023 xmm7 num PHI 0009 0019->LOOP:
394cffd0 xorps xmm6, xmm6
394cffd3 cvtsi2sd xmm6, ebp
394cffd7 cmp ebp, +0x5a
394cffda jz 0x394c0024 ->5
394cffe0 addsd xmm7, xmm6
394cffe4 add ebp, +0x01
394cffe7 cmp ebp, +0x64
394cffea jle 0x394cffd0 ->LOOP
394cffec jmp 0x394c0028 ->6可以看到,分配和存储都下沉了。没有为它们分配寄存器或溢出槽:它显示{sink}或引用对应于存储的分配。循环的机器代码只包含转换、i == 90校验、求和x和循环增量加上边界校验。
[注意:xorps避免了 SSE2 转换指令的部分寄存器写入停顿。]
再沉没
这是一个示例,它显示了一个沉没的分配是如何在侧面跟踪中再次沉没的:
local z = nil
for i=1,200 do
local t = {i}
if i > 100 then
if i == 190 then z = t end
end
end
print(z[1])这是第一个跟踪的 IR(}显示下沉指令):
.... SNAP #0 [ ---- ]
0001 int SLOAD #2 CI
0002 } tab TNEW #3 #0
0003 p32 FLOAD 0002 tab.array
0004 p32 AREF 0003 +1
0005 num CONV 0001 num.int
0006 } num ASTORE 0004 0005
.... SNAP #1 [ ---- ---- 0001 ---- ---- 0001 0002 ]
0007 > int LE 0001 +100
0008 + int ADD 0001 +1
.... SNAP #2 [ ---- ---- ]
0009 > int LE 0008 +200
.... SNAP #3 [ ---- ---- 0008 ---- ---- 0008 ]
0010 ------ LOOP ------------
0011 } tab TNEW #3 #0
0012 p32 FLOAD 0011 tab.array
0013 p32 AREF 0012 +1
0014 num CONV 0008 num.int
0015 } num ASTORE 0013 0014
.... SNAP #4 [ ---- ---- 0008 ---- ---- 0008 0011 ]
0016 > int LE 0008 +100
0017 + int ADD 0008 +1
.... SNAP #5 [ ---- ---- ]
0018 > int LE 0017 +200
0019 int PHI 0008 0017在第一个快照之前,生成了一个边跟踪,沉没的分配和沉没的存储。然后又沉了下去:
0001 int SLOAD #2 PI
0002 } tab TNEW #3 #0
0003 p32 FLOAD 0002 tab.array
0004 p32 AREF 0003 +1
0005 num CONV 0001 num.int
0006 } num ASTORE 0004 0005
.... SNAP #0 [ ---- ---- 0001 ---- ---- 0001 0002 ]
0007 > nil GCSTEP
.... SNAP #1 [ ---- ---- 0001 ---- ---- ---- 0002 ]
0008 > int NE 0001 +190
0009 int ADD 0001 +1
.... SNAP #2 [ ---- ---- ]
0010 > int LE 0009 +200
0011 num CONV 0009 num.int
.... SNAP #3 [ ---- ---- 0011 ---- ---- 0011 ][GCSTEP在第一个快照之后需要一个显式指令,以防止在第一个快照之前执行隐式 GC 步骤。这实际上是一个空操作,因为没有执行任何分配。]
点类
这是高级语言抽象的一个实际示例:(简化的)“点”类。它需要创建临时对象作为对点对象的算术运算的一部分。
带有 Lua 表的点类
首先,普通 Lua 表的版本:
local point
point = {
new = function(self, x, y)
return setmetatable({x=x, y=y}, self)
end,
__add = function(a, b)
return point:new(a.x + b.x, a.y + b.y)
end,
}
point.__index = point
local a, b = point:new(1.5, 2.5), point:new(3.25, 4.75)
for i=1,100000000 do a = (a + b) + b end
print(a.x, a.y)
它每次迭代都会创建两个临时对象,但 LuaJIT 能够将它们优化掉。这是循环部分的机器代码:
->LOOP:
394cffe0 addsd xmm6, xmm1
394cffe4 addsd xmm7, xmm0
394cffe8 addsd xmm6, xmm1
394cffec addsd xmm7, xmm0
394cfff0 add ebp, +0x01
394cfff3 cmp ebp, 0x05f5e100
394cfff9 jle 0x394cffe0 ->LOOP
394cfffb jmp 0x394c0028 ->6[注意:浮点运算不是关联的。不允许编译器转换(a+b)+b成. 对于每个循环迭代总共需要四个 SSE2 指令,它确实需要每个组件添加两个 FP 。]a+(b+b)b+baddsd
带有 FFI cdata 结构的点类
local ffi = require("ffi")
local point
point = ffi.metatype("struct { double x, y; }", {
__add = function(a, b)
return point(a.x + b.x, a.y + b.y)
end
})
local a, b = point(1.5, 2.5), point(3.25, 4.75)
for i=1,100000000 do a = (a + b) + b end
print(a.x, a.y)循环内的机器代码与上面的示例相同。具有不可变“复杂”cdata 对象的类似示例也会生成相同的代码。
C++ 和 Java 中的点类
为了比较,这里是用 C++ 实现的同一个点类:
#include <iostream>
class Point {
public:
Point(double x, double y) : x(x), y(y) { }
Point operator+(const Point &b) const {
return Point(x+b.x, y+b.y);
}
double x, y;
};
int main()
{
int i;
Point a(1.5, 2.5), b(3.25, 4.75);
for (i = 0; i < 100000000; i++)
a = (a + b) + b;
std::cout << a.x << ' ' << a.y << '\n';
return 0;
}请注意,此代码正在传递聚合值,而不是实际分配对象。但是,C++ 编译器仍然必须执行 SRA 以获得最佳结果。毫不奇怪,循环的机器代码与 LuaJIT 生成的代码基本相同。
[我们暂时忽略自动矢量化/自动模拟。]
这是用 Java 实现的同一个点类:
public class Point {
public double x, y;
public Point(double x0, double y0) { x = x0; y = y0; }
public Point add(Point b) { return new Point(x + b.x, y + b.y); }
public static void main(String args[])
{
int i;
Point a = new Point(1.5, 2.5);
Point b = new Point(2.25, 4.75);
for (i = 0; i < 100000000; i++)
a = a.add(b).add(b);
System.out.println(a.x + " " + a.y);
}
}JVM/Hotspot 1.7 无法消除分配。添加该选项-XX:+DoEscapeAnalysis不会改变任何内容。将循环移动到单独的方法或使用外部循环也无济于事。
点类基准
这是点类的运行时间(以秒为单位)(YMMV)。越低越好:
| 时间 | 点对象 | 虚拟机/编译器 |
|---|---|---|
| 140.0 | Lua 表 | 路亚 5.1.5 |
| 26.9 | Lua 表 | LuaJIT 2.0 git HEAD -O-sink |
| 10.9 | FFI 结构 | LuaJIT 2.0 git HEAD -O-sink |
| 0.2 | Lua 表 | LuaJIT 2.0 git HEAD -O+sink |
| 0.2 | FFI 结构 | LuaJIT 2.0 git HEAD -O+sink |
| 0.2 | C++ 类 | GCC 4.4.3 -O2(或-O3) |
| 1.2 | Java 类 | JVM/热点 1.7.0_05 |
LuaJIT 比普通 Lua 快大约 700 倍,并且与 C++ 的速度相同——在这个例子中。
JVM 1.7 无法消除分配,但具有快速分配器和垃圾收集器。尽管如此,在这个例子中,JVM 还是比 LuaJIT 或 C++ 慢了大约 6 倍。
注意:当然,这不能外推到其他代码。并且它不会 导致关于 Lua、LuaJIT、Java 或 C++ 的相对性能的概括性陈述。
[是的,0.2 秒的运行时间对于精确的结果来说太短了。但是对于这个简单的例子,扩大循环迭代会产生一致的结果。LuaJIT 和 C++ 生成的代码确实具有相同的性能。]
执行
JIT 编译器的不同部分参与处理分配接收和存储接收。以下小节描述了实现所需的添加和更改。
SINK 优化通行证
只有在以下情况下才会调用 SINK 优化过程:
- SINK 优化和 FOLD、CSE、DCE 和 FWD 优化已打开。这是 的情况
-O3,这是默认值。 - 当前迹线的IR 至少包含一条
TNEW、TDUP或指令。CNEWCNEWI
此 pass 分两个阶段遍历当前 trace 的 IR,非常类似于经典的 mark & sweep 垃圾收集算法:
- 标记阶段标记所有不能沉没的分配。
- 扫描阶段将未标记的分配和相关存储标记为沉没。
标记阶段
标记阶段是单程反向传播算法。最初,所有 IR 指令的标记都是清晰的。然后标记根(其中大部分发生在运行中)并且标记向后传播。考虑以下根:
- 如果跟踪链接到另一个跟踪,则跟踪的最后一个快照引用的所有指令。
PHI由不引用分配指令或引用两个不同操作码的指令引用的所有指令。- 任何剩余负载或
CALLL说明的参考。 - 任何 IR
CALLS或CALLXS指令的参数。 - 所有存储指令的存储值和
CNEWI。 - 任何不符合条件的商店说明的参考。
仅当所有这些条件都为真时,存储指令才符合条件:
- 存储引用是一条指令。加上一些引用类型的基指针获取。
- 存储引用具有常量键、索引或偏移量。
- 存储引用指向分配。
- 如果分配是 PHI 值,则存储的值必须是 PHI 值本身(或它的整数到数字的转换)或循环不变值。
最后,对 PHI 引用进行迭代注释。如果左侧和右侧具有不同的标记或存储的 PHI 值数量不同,则标记两侧。重复此操作,直到标记收敛。
在此过程完成后,未标记的分配被认为是安全的沉没。
扫描阶段
扫描阶段是单次通过 IR 指令:
- 如果一条
PHI指令引用了未标记的分配,则将其标记为沉没(检查一侧就足够了)。 - 如果未标记相应的分配,则将商店或 a
NEWREF标记为沉没。 - 如果未标记分配,则将其标记为已沉没。
所有标记也被清除。标记工作如下:
- IR 被标记为包含有效的寄存器/溢出槽分配。
- 所有未标记的指令都设置为 REGSP_INIT(未分配寄存器或溢出槽)。
- 沉没分配
NEWREF和存储将寄存器字段设置为 RID_SINK(就像没有分配任何寄存器一样)。 - 沉没分配并
NEWREF具有零溢出插槽字段。 - 沉没存储有一个溢出槽字段,它保存存储和相应分配之间的增量(如果增量太大,则为 255)。这可以用作遍历 IR 以搜索相关商店时的快速测试(见下文)。
汇编器后端
汇编器后端将 IR 转换为机器代码。它需要了解沉没指令以避免为它们生成机器代码。
快照分配
第一个遇到需要为快照添加出口的守卫会调用一个准备当前快照的特殊例程。每条产生转义值的指令都必须分配一个寄存器或溢出槽,如果它还没有的话。
这可确保通过快照转义的所有值在所有出口处都处于活动状态。处理是向后的,因此在第一个遇到的守卫(最高 IR 指令)处存在的任何值都在所有其他守卫处存在,直到快照。
快照准备检查沉没分配并改为分配存储的值。这涉及搜索与分配相关的所有商店。只需要考虑分配引用和快照引用之间的存储指令。
完成此操作后,分配寄存器将从 RID_SINK 更改为 RID_SUNK。这可以防止额外的调用,以防分配逃逸到多个堆栈槽或通过另一个更远的快照。
附加逻辑尝试为整数到数字转换的输入分配一个值,而不是转换本身。这有效地降低了转化率并将它们从快速路径中移除。
沉没指令
沉没分配指令的寄存器设置为 RID_SINK 或 RID_SUNK 以及零(未使用)溢出槽。因此,动态死码消除 (DCE) 认为该结果未使用。没有为沉没分配发出代码。
DCE 消除了未使用的、沉没的转换,并且不会为它们发出任何代码。
存储指令和NEWREF指令不适用于 DCE,因此它们需要在后端处理程序中显式检查 RID_SINK 以不发出任何代码。
沉没PHI指令需要相同的检查以避免为引用的分配分配寄存器或溢出槽。
快照处理
从字节码解释器的角度来看,快照保存跟踪中选定点的执行状态。沉没分配和沉没转换实际上并未实时执行,因此不会产生价值。但是,存储的值(或用于转换的输入值) 是经过计算的,可用于恢复或重放快照。
快照还原
一个没有附加侧面跟踪的采取的侧面出口(还)需要将 Lua 堆栈恢复到正常状态。与出口对应的快照有一个要恢复的 Lua 堆栈槽列表及其 IR 引用。这些可以与 IR 中的寄存器和溢出槽分配一起使用,以从跟踪的退出状态恢复 Lua 堆栈,其中保存当前寄存器和溢出槽值。
沉没分配(通过快照逃逸)将其寄存器设置为 RID_SUNK。分配需要是“未沉没的”:需要分配对象并且需要执行相关的存储,就好像对象已被跟踪分配一样。
汇编器后端中的快照分配确保所有沉没的存储在出口处都有实时值。实际值也通过它们的 IR 参考和退出状态恢复。沉没商店的钥匙总是不变的,因此它们可以单独从 IR 中重建。
需要注意去重复分配引用。沉没分配可能会逃逸到多个堆栈槽,并且它们都必须引用同一个对象。
快照回放
侧面跟踪的 IR 需要从链接到快照中包含的父值的指令开始。带有 IRSLOAD_PARENT 标志的SLOAD指令为对应于 Lua 堆栈槽的值提供父链接。
沉没分配、沉没存储和沉没转换需要重放。沉没的存储和转换可能会引用来自没有相应 Lua 堆栈槽的父级的值。该PVAL 指令提供了必要的父链接。
所有父链接都必须位于跟踪的开头,因为它们的寄存器和堆栈槽必须与父跟踪原子地合并。此外,如果有 相同引用PVAL的父级,则不得使用 a 。SLOAD这会导致一些排序约束,这要求使用多遍算法:
SLOAD从快照中发出非沉没槽的所有父指令。- 从沉没的分配或转换中发出
PVAL所有相关值的指令,除非有SLOAD相同引用的父指令。 - 重播沉没的指令。分配需要重放沉没商店和沉没商店本身的关键引用。
[注意:这听起来比实际更贵。该算法迭代次数有限——通常少于五次。此外,仅在需要时执行第二遍和第三遍。]
扩展 BNF
基于Lua 5.1 参考手册的第 8 节,包括FFI 的文字扩展和选择性地合并Lua 5.2的功能。
chunk ::= {stat [`;´]} [laststat [`;´]]
block ::= chunk
stat ::= varlist `=´ explist |
functioncall |
lua52_label |
`do´ block `end´ |
`while´ exp `do´ block `end´ |
`repeat´ block `until´ exp |
`if´ exp `then´ block {`elseif´ exp `then´ block} [`else´ block] `end´ |
`for´ Name `=´ exp `,´ exp [`,´ exp] `do´ block `end´ |
`for´ namelist `in´ explist `do´ block `end´ |
`function´ funcname funcbody |
`local´ `function´ Name funcbody |
`local´ namelist [`=´ explist]
laststat ::= `return´ [explist] | `break´ | lua52_goto
lua52_goto ::= `goto´ Name
lua52_label ::= ‘::’ Name ‘::’
funcname ::= Name {`.´ Name} [`:´ Name]
varlist ::= var {`,´ var}
var ::= Name | prefixexp `[´ exp `]´ | prefixexp `.´ Name
namelist ::= Name {`,´ Name}
explist ::= {exp `,´} exp
exp ::= `nil´ | `false´ | `true´ | numeric | String | `...´ | function |
prefixexp | tableconstructor | exp binop exp | unop exp
numeric ::= FFI_Int64 | FFI_Uint64 | FFI_Imaginary | Number
prefixexp ::= var | functioncall | `(´ exp `)´
functioncall ::= prefixexp args | prefixexp `:´ Name args
args ::= `(´ [explist] `)´ | tableconstructor | String
function ::= `function´ funcbody
funcbody ::= `(´ [parlist] `)´ block `end´
parlist ::= namelist [`,´ `...´] | `...´
tableconstructor ::= `{´ [fieldlist] `}´
fieldlist ::= field {fieldsep field} [fieldsep]
field ::= `[´ exp `]´ `=´ exp | Name `=´ exp | exp
fieldsep ::= `,´ | `;´
binop ::= `+´ | `-´ | `*´ | `/´ | `^´ | `%´ | `..´ |
`<´ | `<=´ | `>´ | `>=´ | `==´ | `~=´ |
`and´ | `or´
unop ::= `-´ | `not´ | `#´QQ二群 166427999
如果项目有技术瓶颈问题,请联系↓↓
QQ: 903464207
微信: zx903464207

 浙公网安备 33010602011771号
浙公网安备 33010602011771号