基于THUCNews数据的BERT分类
BERT预训练模型有以下几个:
BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Multilingual Uncased (Orig, not recommended):(Not recommended, useMultilingual Casedinstead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
数据集准备:
数据集(下载)包括训练集(train.tsv)、验证集(dev.tsv)和测试集(test.tsv),格式相同,每一行表示一条数据,每条数据格式为【标签+TAB+内容】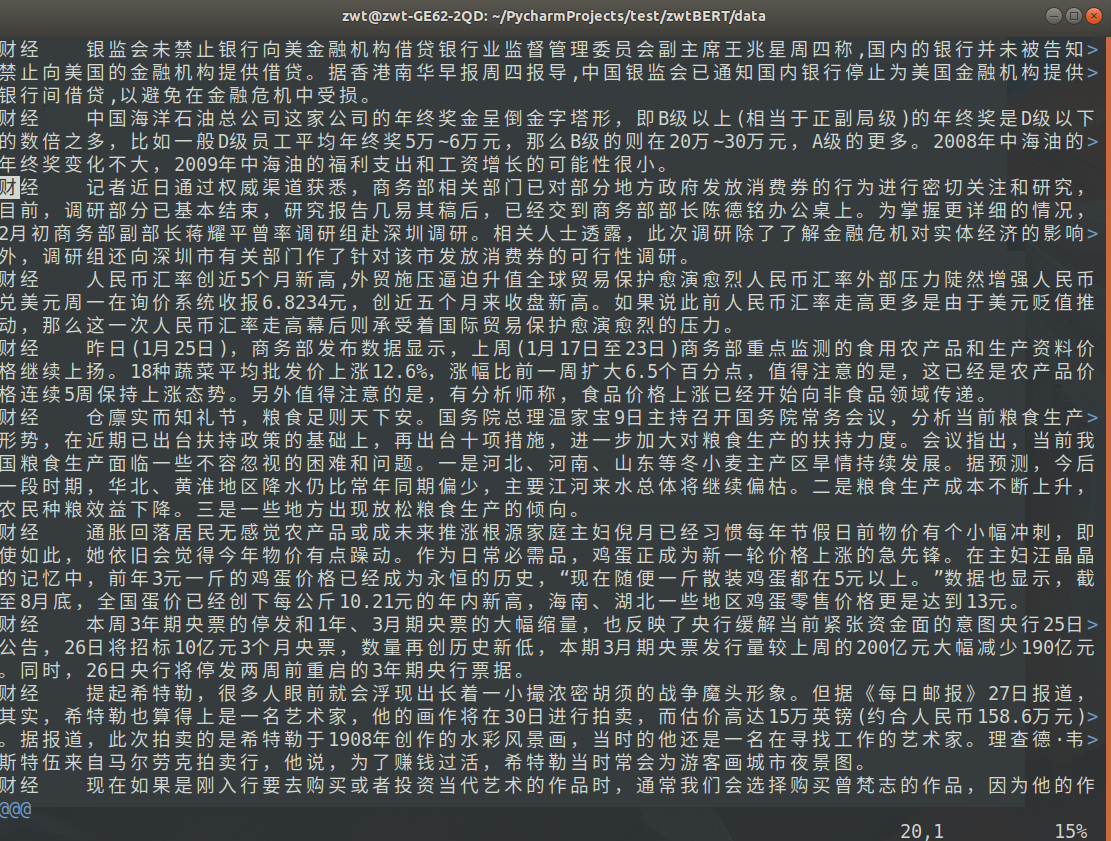
#批量转换数据格式
def _writeto_tsv(a):
fr = open('/home/zwt/Desktop/testbert/caijing/{}.txt'.format(a), 'r')
txt = fr.read()
txt = txt.replace('\n', '')
txt = txt.replace('\u3000', '')
txt = txt.replace(' ', '')
txt = txt[:128]
txt = '财经\t' + txt + '\n'
fw.write(txt)
fr.close()
fw = open('/home/zwt/Desktop/testbert/caijing.tsv','w')
for a in range(799401,799440):
_writeto_tsv(a)
fw.close()
#####
def _writeto_tsv(a):
fr = open('/home/zwt/Desktop/testbert/yule/{}.txt'.format(a), 'r')
txt = fr.read()
txt = txt.replace('\n', '')
txt = txt.replace('\u3000', '')
txt = txt.replace(' ', '')
txt = txt[:128]
txt = '娱乐\t' + txt + '\n'
fw.write(txt)
fr.close()
fw = open('/home/zwt/Desktop/testbert/yule.tsv','w')
for a in range(157340,157379):
_writeto_tsv(a)
fw.close()
#####
def _writeto_tsv(a):
fr = open('/home/zwt/Desktop/testbert/keji/{}.txt'.format(a), 'r')
txt = fr.read()
txt = txt.replace('\n', '')
txt = txt.replace('\u3000', '')
txt = txt.replace(' ', '')
txt = txt[:128]
txt = '科技\t' + txt + '\n'
fw.write(txt)
fr.close()
fw = open('/home/zwt/Desktop/testbert/keji.tsv','w')
for a in range(482362,482401):
_writeto_tsv(a)
fw.close()
修改代码:
run_classifier.py中有DataProcessor基类:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
在这个基类中定义了一个读取文件的静态方法_read_tsv,四个分别获取训练集,验证集,测试集和标签的方法。接下来我们要定义自己的数据处理的类,我们将我们的类命名ZwtProcessor,继承于DataProcessor,编写ZwtProcessor(本例中使用三分类数据,如果需要更多分类,修改labels参数)
class ZwtProcessor(DataProcessor):
"""Processor for the News data set (GLUE version)."""
def __init__(self):
self.labels = ['财经', '娱乐', '科技']
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
return self.labels
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
注意这里有一个self._read_tsv()方法,规定读取的数据是使用TAB分割的,如果你的数据集不是这种形式组织的,需要重写一个读取数据的方法,更改“_create_examples()”的实现。
在main函数的processors中加入自己的processors
修改前:
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
}
修改后:
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"zwt": ZwtProcessor,
}
至此已经完成准备工作,编写一个run.sh文件运行即可,内容如下:
#!/usr/bin/bash
python3 /home/zwt/PycharmProjects/test/bert-master/run_classifier.py \ --task_name=zwt \ --do_train=true \ --do_eval=true \ --data_dir=/home/zwt/PycharmProjects/test/zwtBERT/data/ \ --vocab_file=/home/zwt/PycharmProjects/test/data/chinese_L-12_H-768_A-12/vocab.txt \ --bert_config_file=/home/zwt/PycharmProjects/test/data/chinese_L-12_H-768_A-12/bert_config.json \ --init_checkpoint=/home/zwt/PycharmProjects/test/data/chinese_L-12_H-768_A-12/bert_model.ckpt \ --max_seq_length=128 \ --train_batch_size=32 \ --learning_rate=2e-5 \ --num_train_epochs=3.0 \ --output_dir=/home/zwt/PycharmProjects/test/zwtBERT/zwt_output
######参数解释#######
data_dir:存放数据集的文件夹
bert_config_file:bert中文模型中的bert_config.json文件
task_name:processors中添加的任务名“zbs”
vocab_file:bert中文模型中的vocab.txt文件
output_dir:训练好的分类器模型的存放文件夹
init_checkpoint:bert中文模型中的bert_model.ckpt.index文件
do_train:是否训练,设置为“True”
do_eval:是否验证,设置为“True”
do_predict:是否测试,设置为“False”
max_seq_length:输入文本序列的最大长度,也就是每个样本的最大处理长度,多余会去掉,不够会补齐。最大值512,当显存不足时,可以适当降低max_seq_length。
train_batch_size: 训练模型求梯度时,批量处理数据集的大小。值越大,训练速度越快,内存占用越多。
eval_batch_size: 验证时,批量处理数据集的大小。同上。
predict_batch_size: 测试时,批量处理数据集的大小。同上。
learning_rate: 反向传播更新权重时,步长大小。值越大,训练速度越快。值越小,训练速度越慢,收敛速度慢,
容易过拟合。迁移学习中,一般设置较小的步长(小于2e-4)
num_train_epochs:所有样本完全训练一遍的次数。
warmup_proportion:用于warmup的训练集的比例。
save_checkpoints_steps:检查点的保存频率。
终端输入/bin/bash zwtBERTrun.sh即可运行
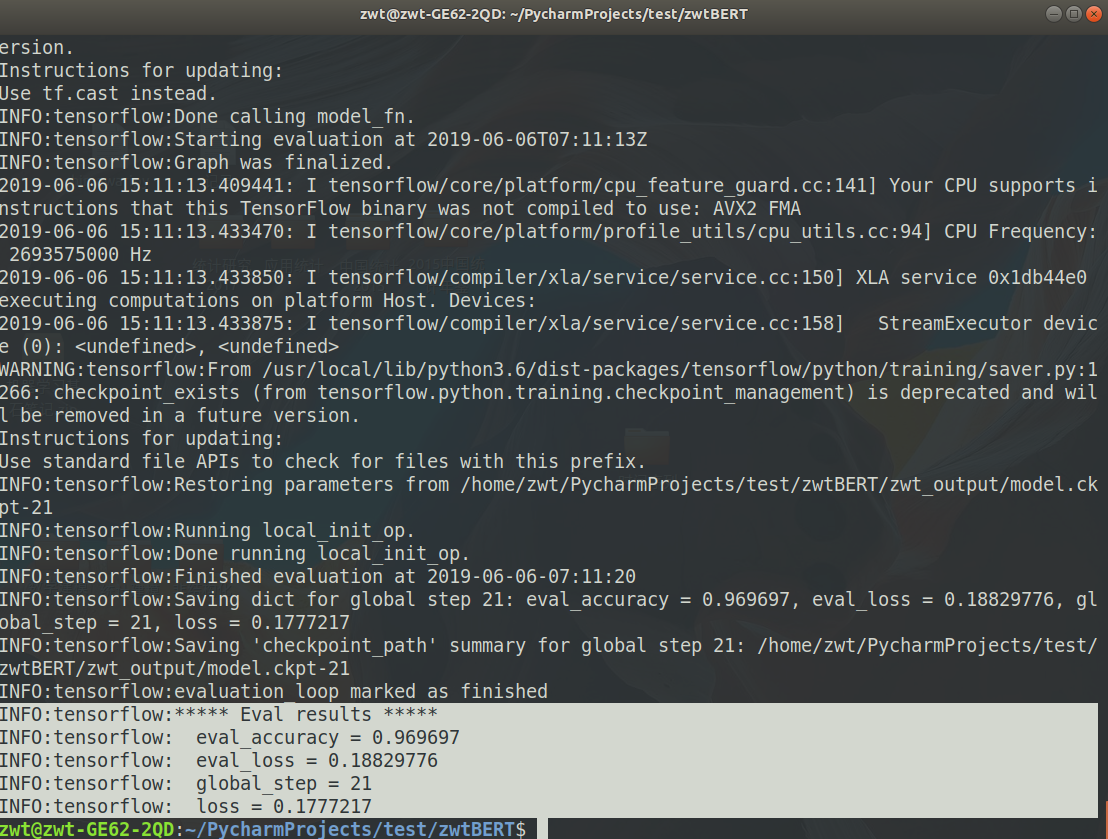
原生bert指标只有loss和accuracy,可自行修改
修改前:
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
修改后:
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
auc = tf.metrics.auc(labels=label_ids, predictions=predictions, weights=is_real_example)
precision = tf.metrics.precision(labels=label_ids, predictions=predictions, weights=is_real_example)
recall = tf.metrics.recall(labels=label_ids, predictions=predictions, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
'eval_auc': auc,
'eval_precision': precision,
'eval_recall': recall,
}
https://www.cnblogs.com/jiangxinyang/p/10241243.html
https://www.jiqizhixin.com/articles/2018-12-03
https://cloud.tencent.com/developer/article/1356797
https://blog.csdn.net/xiaosa_kun/article/details/84868475

 浙公网安备 33010602011771号
浙公网安备 33010602011771号