JavaWeb-总结
Java网络编程
推荐阅读:
计算机网络基础
利用通信线路和通信设备,将地理位置不同的、功能独立的多台计算机互连起来,以功能完善的网络软件来实现资源共享和信息传递,就构成了计算机网络系统。

比如我们家里的路由器,通过将我们的设备(手机、平板、电脑、电视剧)连接到路由器,来实现对互联网的访问。
实际上,我们的路由器连接在互联网上,而我们的设备又连接了路由器,这样我们的设备就可以通过路由器访问到互联网了。通过网络,我们可以直接访问互联网上的另一台主机,比如我们要把QQ的消息发送给我们的朋友,或是通过远程桌面管理来操作另一台电脑,也可以是连接本地网络上的打印机。
既然我们可以通过网络访问其他计算机,那么如何区别不同的计算机呢?通过IP地址,我们就可以区分不同的计算机了:

每一台电脑在同一个网络上都有一个自己的IP地址,用于区别于其他的电脑,我们可以通过对方主机的IP地址对其进行访问。那么我手机连接的移动流量,能访问到连接家里路由器的电脑吗?(不能,因为他们不属于同一个网络)
而我们的电脑上可能运行着大量的程序,每一个程序可能都需要通过网络来访问其他计算机,那这时该如何区分呢?我们可以通过端口号来区分:

因此,我们一般看到的是这样的:192.168.0.11:8080,通过IP:端口的形式来访问目标主机上的一个应用程序服务。
注意端口号只能是0-65535之间的值!
IP地址分为IPv4和IPv6,IPv4 类似于192.168.0.11,我们上面提到的例子都是使用的IPv4,它一共有四组数字,每组数字占8个bit位,IPv4地址0.0.0.0表示为2进制就是:00000000.00000000.00000000.00000000,共32个bit,最大为255.255.255.255,实际上,IPv4能够表示的所有地址,早就已经被用完了。
IPv6 能够保存128个bit位,因此它也可以表示更多的IP地址,一个IPv6地址看起来像这样:
1030::C9B4:FF12:48AA:1A2B,目前也正在向IPv6的阶段过度。
TCP和UDP是两种不同的传输层协议:
- TCP:当一台计算机想要与另一台计算机通讯时,两台计算机之间的通信需要畅通且可靠(会进行三次握手,断开也会进行四次挥手),这样才能保证正确收发数据,因此TCP更适合一些可靠的数据传输场景。
- UDP:它是一种无连接协议,数据想发就发,而且不会建立可靠传输,也就是说传输过程中有可能会导致部分数据丢失,但是它比TCP传输更加简单高效,适合视频直播之类的。

了解Socket技术
通过Socket技术(它是计算机之间进行通信的一种约定或一种方式),我们就可以实现两台计算机之间的通信,Socket也被翻译为套接字,是操作系统底层提供的一项通信技术,它支持TCP和UDP。
而Java就对Socket底层支持进行了一套完整的封装,我们可以通过Java来实现Socket通信。
要实现Socket通信,我们必须创建一个数据发送者和一个数据接收者,也就是客户端和服务端,我们需要提前启动服务端,来等待客户端的连接,而客户端只需要随时启动去连接服务端即可!
//服务端
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
Socket socket = server.accept(); //当没有客户端连接时,线程会阻塞,直到有客户端连接为止
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
}catch (IOException e){
e.printStackTrace();
}
}
//客户端
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080)){
System.out.println("已连接到服务端!");
}catch (IOException e){
System.out.println("服务端连接失败!");
e.printStackTrace();
}
}
实际上它就是一个TCP连接的建立过程:

一旦TCP连接建立,服务端和客户端之间就可以相互发送数据,直到客户端主动关闭连接。
当然,服务端不仅仅只可以让一个客户端进行连接,我们可以尝试让服务端一直运行来不断接受客户端的连接:
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
while (true){ //无限循环等待客户端连接
Socket socket = server.accept();
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
}
}catch (IOException e){
e.printStackTrace();
}
}
现在我们就可以多次去连接此服务端了。
使用Socket进行数据传输
通过Socket对象,我们就可以获取到对应的I/O流进行网络数据传输:
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080);
Scanner scanner = new Scanner(System.in)){
System.out.println("已连接到服务端!");
OutputStream stream = socket.getOutputStream();
OutputStreamWriter writer = new OutputStreamWriter(stream); //通过转换流来帮助我们快速写入内容
System.out.println("请输入要发送给服务端的内容:");
String text = scanner.nextLine();
writer.write(text+'\n'); //因为对方是readLine()这里加个换行符
writer.flush();
System.out.println("数据已发送:"+text);
}catch (IOException e){
System.out.println("服务端连接失败!");
e.printStackTrace();
}finally {
System.out.println("客户端断开连接!");
}
}
}
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
Socket socket = server.accept();
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream())); //通过
System.out.print("接收到客户端数据:");
System.out.println(reader.readLine());
socket.close(); //和服务端TCP连接完成之后,记得关闭socket
}catch (IOException e){
e.printStackTrace();
}
}
同理,既然服务端可以读取客户端的内容,客户端也可以在发送后等待服务端给予响应:
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080);
Scanner scanner = new Scanner(System.in)){
System.out.println("已连接到服务端!");
OutputStream stream = socket.getOutputStream();
OutputStreamWriter writer = new OutputStreamWriter(stream); //通过转换流来帮助我们快速写入内容
System.out.println("请输入要发送给服务端的内容:");
String text = scanner.nextLine();
writer.write(text+'\n'); //因为对方是readLine()这里加个换行符
writer.flush();
System.out.println("数据已发送:"+text);
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
System.out.println("收到服务器返回:"+reader.readLine());
}catch (IOException e){
System.out.println("服务端连接失败!");
e.printStackTrace();
}finally {
System.out.println("客户端断开连接!");
}
}
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
Socket socket = server.accept();
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream())); //通过
System.out.print("接收到客户端数据:");
System.out.println(reader.readLine());
OutputStreamWriter writer = new OutputStreamWriter(socket.getOutputStream());
writer.write("已收到!");
writer.flush();
}catch (IOException e){
e.printStackTrace();
}
}
我们可以手动关闭单向的流:
socket.shutdownOutput(); //关闭输出方向的流
socket.shutdownInput(); //关闭输入方向的流
如果我们不希望服务端等待太长的时间,我们可以通过调用setSoTimeout()方法来设定IO超时时间:
socket.setSoTimeout(3000);
当超过设定时间都依然没有收到客户端或是服务端的数据时,会抛出异常:
java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
at java.io.InputStreamReader.read(InputStreamReader.java:184)
at java.io.BufferedReader.fill(BufferedReader.java:161)
at java.io.BufferedReader.readLine(BufferedReader.java:324)
at java.io.BufferedReader.readLine(BufferedReader.java:389)
at com.test.Main.main(Main.java:41)
我们之前使用的都是通过构造方法直接连接服务端,那么是否可以等到我们想要的时候再去连接呢?
try (Socket socket = new Socket(); //调用无参构造不会自动连接
Scanner scanner = new Scanner(System.in)){
socket.connect(new InetSocketAddress("localhost", 8080), 1000); //手动调用connect方法进行连接
如果连接的双方发生意外而通知不到对方,导致一方还持有连接,这样就会占用资源,因此我们可以使用setKeepAlive()方法来防止此类情况发生:
socket.setKeepAlive(true);
当客户端连接后,如果设置了keeplive为 true,当对方没有发送任何数据过来,超过一个时间(看系统内核参数配置),那么我们这边会发送一个ack探测包发到对方,探测双方的TCP/IP连接是否有效。
TCP在传输过程中,实际上会有一个缓冲区用于数据的发送和接收:

此缓冲区大小为:8192,我们可以手动调整其大小来优化传输效率:
socket.setReceiveBufferSize(25565); //TCP接收缓冲区
socket.setSendBufferSize(25565); //TCP发送缓冲区
使用Socket传输文件
既然Socket为我们提供了IO流便于数据传输,那么我们就可以轻松地实现文件传输了。
使用浏览器访问Socket服务器
在了解了如何使用Socket传输文件后,我们来看看,浏览器是如何向服务器发起请求的:
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
Socket socket = server.accept();
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
InputStream in = socket.getInputStream(); //通过
System.out.println("接收到客户端数据:");
while (true){
int i = in.read();
if(i == -1) break;
System.out.print((char) i);
}
}catch (Exception e){
e.printStackTrace();
}
}
我们现在打开浏览器,输入http://localhost:8080或是http://127.0.0.1:8080/,来连接我们本地开放的服务器。
我们发现浏览器是无法打开这个链接的,但是我们服务端却收到了不少的信息:
GET / HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,und;q=0.8,en;q=0.7
实际上这些内容都是Http协议规定的请求头内容。
HTTP是一种应用层协议,全称为超文本传输协议,它本质也是基于TCP协议进行数据传输,因此我们的服务端能够读取HTTP请求。
但是Http协议并不会保持长连接,在得到我们响应的数据后会立即关闭TCP连接。
既然使用的是Http连接,如果我们的服务器要支持响应HTTP请求,那么就需要按照HTTP协议的规则,返回一个规范的响应文本,首先是响应头,它至少要包含一个响应码:
HTTP/1.1 200 Accpeted
然后就是响应内容(注意一定要换行再写),我们尝试来编写一下支持HTTP协议的响应内容:
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(8080)){ //将服务端创建在端口8080上
System.out.println("正在等待客户端连接...");
Socket socket = server.accept();
System.out.println("客户端已连接,IP地址为:"+socket.getInetAddress().getHostAddress());
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream())); //通过
System.out.println("接收到客户端数据:");
while (reader.ready()) System.out.println(reader.readLine()); //ready是判断当前流中是否还有可读内容
OutputStreamWriter writer = new OutputStreamWriter(socket.getOutputStream());
writer.write("HTTP/1.1 200 Accepted\r\n"); //200是响应码,Http协议规定200为接受请求,400为错误的请求,404为找不到此资源(不止这些,还有很多)
writer.write("\r\n"); //在请求头写完之后还要进行一次换行,然后写入我们的响应实体(会在浏览器上展示的内容)
writer.write("lbwnb!");
writer.flush();
}catch (Exception e){
e.printStackTrace();
}
}
我们可以打开浏览器的开发者模式(这里推荐使用Chrome/Edge浏览器,按下F12即可打开),我们来观察一下浏览器的实际请求过程。
数据库基础
推荐阅读:
数据库是学习JavaWeb的一个前置,只有了解了数据库的操作和使用,我们才能更好地组织和管理网站应用产生的数据。

什么是数据库
数据库是数据管理的有效技术,是由一批数据构成的有序集合,这些数据被存放在结构化的数据表里。
数据表之间相互关联,反映客观事物间的本质联系。数据库能有效地帮助一个组织或企业科学地管理各类信息资源。简而言之,我们的数据可以交给数据库来帮助我们进行管理,同时数据库能够为我们提供高效的访问性能。
在JavaSE学习阶段中,我们学习了如何使用文件I/O来将数据保存到本地,这样就可以将一个数据持久地存储在本地,即使程序重新打开,我们也能加载回上一次的数据,但是当我们的数据变得非常多的时候,这样的方式就显得不太方便了。同时我们如果需要查找众多数据的中的某一个,就只能加载到内存再进行查找,这样显然是很难受的!
而数据库就是专门做这事的,我们可以快速查找想要的数据,便捷地插入、修改和删除数据,并且数据库不仅能做这些事,还能提供更多便于管理数据和操作数据的功能!
常见的数据库
常见的数据库有很多种,包括但不限于:
- MySQL - 免费,用的最多的,开源数据库,适用于中小型
- Microsoft SQL Server - 收钱的,但是提供技术支持,适用于Windows Server
- Oracle - 收钱的,大型数据库系统
而我们要学习的是MySQL数据,其实无论学习哪种数据库,SQL语句大部分都是通用的,只有少许语法是不通用的,因此我们只需要学习一种数据库其他的也就差不多都会了。
数据模型
数据模型与现实世界中的模型一样,是对现实世界数据特征的一种抽象。实际上,我们之前学习的类就是对现实世界数据的一种抽象,比如一个学生的特征包括姓名,年龄,年级,学号,专业等,这些特征也称为实体的一种属性,属性具有以下特点:
- 属性不可再分
- 一个实体的属性可以有很多个
- 用于唯一区分不同实体的的属性,称为Key,比如每个同学的学号都是不一样的
- 属性取值可以有一定的约束,比如性别只能是男或是女
实体或是属性之间可以具有一定的联系,比如一个老师可以教很多个学生,而学生相对于老师就是被教授的关系;又比如每个同学都有一个学号与其唯一对应,因此学号和学生之间也有一种联系。而像一个老师教多个学生的联系就是一种一对多的联系(1:n),而学号唯一对应,就是一种一对一的联系(1:1);每一个老师不仅可以教多个学生,每一个学生也可以有多个教师,这就是一种多对多的联系(n:m)
MySQL就是一种关系型数据库,通过使用关系型数据库,我们就可以很好地存储这样带有一定联系的数据。

通过构建一个ER图,我们就能很好地理清不同数据模型之间的关系和特点。
数据库的创建
既然了解了属性和联系,那么我们就来尝试创建一个数据库,并在数据库中添加用于存放数据的表,每一张表都代表一种实体的数据。首先我们要明确,我们需要创建什么样子的表:
- 学生表:用于存放所有学生的数据,学生(学号,姓名,性别)
- 教师表:用于存放所有教师的数据,教师(教师号,姓名)
- 授课表:用于存放教师与学生的授课信息,授课(学号,教师号)
其中,标注下划线的属性,作为Key,用于区别于其他实体数据的唯一标记。
为了理解起来更加轻松,我们从图形界面操作再讲到SQL语句,请不要着急。我们现在通过Navicat或idea自带的数据库客户端来创建一个数据库和上述三个表。
数据库的规范化
要去设计存放一个实体的表,我们就需要了解数据库的关系规范化,尽可能减少“不好”的关系存在,如何设计一个优良的关系模型是最关键的内容!简而言之,我们要学习一下每一个表该如何去设计。
第一范式(1NF)
第一范式是指数据库的每一列都是不可分割的基本数据项,而下面这样的就存在可分割的情况:
- 学生(姓名,电话号码)
电话号码实际上包括了家用座机电话和移动电话,因此它可以被拆分为:
- 学生(姓名,座机号码,手机号码)
满足第一范式是关系型数据库最基本的要求!
第二范式(2NF)
第二范式要求表中必须存在主键,且其他的属性必须完全依赖于主键,比如:
- 学生(学号,姓名,性别)
学号是每个学生的唯一标识,每个学生都有着不同的学号,因此此表中存在一个主键,并且每个学生的所有属性都依赖于学号,学号发生改变就代表学生发生改变,姓名和性别都会因此发生改变,所有此表满足第二范式。
第三范式(3NF)
在满足第二范式的情况下,所有的属性都不传递依赖于主键,满足第三范式。
- 学生借书情况(借阅编号,学生学号,书籍编号,书籍名称,书籍作者)
实际上书籍编号依赖于借阅编号,而书籍名称和书籍作者依赖于书籍编号,因此存在传递依赖的情况,我们可以将书籍信息进行单独拆分为另一张表:
- 学生借书情况(借阅编号,学生学号,书籍编号)
- 书籍(书籍编号,书籍名称,书籍作者)
这样就消除了传递依赖,从而满足第三范式。
BCNF
BCNF作为第三范式的补充,假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,如果修改管理员ID,那么就必须逐一进行修改,所以其不符合BCNF范式。
认识SQL语句
结构化查询语言(Structured Query Language)简称SQL,这是一种特殊的语言,它专门用于数据库的操作。每一种数据库都支持SQL,但是他们之间会存在一些细微的差异,因此不同的数据库都存在自己的“方言”。
SQL语句不区分大小写(关键字推荐使用大写),它支持多行,并且需要使用;进行结尾!
SQL也支持注释,通过使用--或是#来编写注释内容,也可以使用/*来进行多行注释。
我们要学习的就是以下四种类型的SQL语言:
- 数据查询语言(Data Query Language, DQL)基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块。
- 数据操纵语言(Data Manipulation Language, DML)是SQL语言中,负责对数据库对象运行数据访问工作的指令集,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除,是开发以数据为中心的应用程序必定会使用到的指令。
- 数据库定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。
- DCL(Data Control Language)是数据库控制语言。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL。
我们平时所说的CRUD其实就是增删改查(Create/Retrieve/Update/Delete)
数据库定义语言(DDL)
数据库操作
我们可以通过create database来创建一个数据库:
create database 数据库名
为了能够支持中文,我们在创建时可以设定编码格式:
CREATE DATABASE IF NOT EXISTS 数据库名 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
如果我们创建错误了,我们可以将此数据库删除,通过使用drop database来删除一个数据库:
drop database 数据库名
创建表
数据库创建完成后,我们一般通过create table语句来创建一张表:
create table 表名(列名 数据类型[列级约束条件],
列名 数据类型[列级约束条件],
...
[,表级约束条件])
SQL数据类型
以下的数据类型用于字符串存储:
- char(n)可以存储任意字符串,但是是固定长度为n,如果插入的长度小于定义长度时,则用空格填充。
- varchar(n)也可以存储任意数量字符串,长度不固定,但不能超过n,不会用空格填充。
以下数据类型用于存储数字:
- smallint用于存储小的整数,范围在 (-32768,32767)
- int用于存储一般的整数,范围在 (-2147483648,2147483647)
- bigint用于存储大型整数,范围在 (-9,223,372,036,854,775,808,9,223,372,036,854,775,807)
- float用于存储单精度小数
- double用于存储双精度的小数
以下数据类型用于存储时间:
- date存储日期
- time存储时间
- year存储年份
- datetime用于混合存储日期+时间
列级约束条件
列级约束有六种:主键Primary key、外键foreign key 、唯一 unique、检查 check (MySQL不支持)、默认default 、非空/空值 not null/ null
表级约束条件
表级约束有四种:主键、外键、唯一、检查
现在我们通过SQL语句来创建我们之前提到的三张表。
[CONSTRAINT <外键名>] FOREIGN KEY 字段名 [,字段名2,…] REFERENCES <主表名> 主键列1 [,主键列2,…]
修改表
如果我们想修改表结构,我们可以通过alter table来进行修改:
ALTER TABLE 表名[ADD 新列名 数据类型[列级约束条件]]
[DROP COLUMN 列名[restrict|cascade]]
[ALTER COLUMN 列名 新数据类型]
我们可以通过ADD来添加一个新的列,通过DROP来删除一个列,不过我们可以添加restrict或cascade,默认是restrict,表示如果此列作为其他表的约束或视图引用到此列时,将无法删除,而cascade会强制连带引用此列的约束、视图一起删除。还可以通过ALTER来修改此列的属性。
删除表
我们可以通过drop table来删除一个表:
DROP TABLE 表名[restrict|cascade]
其中restrict和cascade上面的效果一致。
数据库操纵语言(DML)
前面我们已经学习了如何使用SQL语句来创建、修改、删除数据库以及表,而如何向数据库中插入、删除、更新数据,将是本版块讨论的重点。
插入数据
通过使用insert into语句来向数据库中插入一条数据(一条记录):
INSERT INTO 表名 VALUES(值1, 值2, 值3)
如果插入的数据与列一一对应,那么可以省略列名,但是如果希望向指定列上插入数据,就需要给出列名:
INSERT INTO 表名(列名1, 列名2) VALUES(值1, 值2)
我们也可以一次性向数据库中插入多条数据:
INSERT INTO 表名(列名1, 列名2) VALUES(值1, 值2), (值1, 值2), (值1, 值2)
我们来试试看向我们刚刚创建的表中添加三条数据。
修改数据
我们可以通过update语句来更新表中的数据:
UPDATE 表名 SET 列名=值,... WHERE 条件
注意,SQL语句中的等于判断是=
警告:如果忘记添加WHERE字句来限定条件,将使得整个表中此列的所有数据都被修改!
删除数据
我们可以通过使用delete来删除表中的数据:
DELETE FROM 表名
通过这种方式,将删除表中全部数据,我们也可以使用where来添加条件,只删除指定的数据:
DELETE FROM 表名 WHERE 条件
数据库查询语言(DQL)
数据库的查询是我们整个数据库学习中的重点内容,面对数据库中庞大的数据,该如何去寻找我们想要的数据,就是我们主要讨论的问题。
单表查询
单表查询是最简单的一种查询,我们只需要在一张表中去查找数据即可,通过使用select语句来进行单表查询:
-- 指定查询某一列数据
SELECT 列名[,列名] FROM 表名
-- 会以别名显示此列
SELECT 列名 别名 FROM 表名
-- 查询所有的列数据
SELECT * FROM 表名
-- 只查询不重复的值
SELECT DISTINCT 列名 FROM 表名
我们也可以添加where字句来限定查询目标:
SELECT * FROM 表名 WHERE 条件
常用查询条件
- 一般的比较运算符,包括=、>、<、>=、<=、!=等。
- 是否在集合中:in、not in
- 字符模糊匹配:like,not like
- 多重条件连接查询:and、or、not
我们来尝试使用一下上面这几种条件。
排序查询
我们可以通过order by来将查询结果进行排序:
SELECT * FROM 表名 WHERE 条件 ORDER BY 列名 ASC|DESC
使用ASC表示升序排序,使用DESC表示降序排序,默认为升序。
我们也可以可以同时添加多个排序:
SELECT * FROM 表名 WHERE 条件 ORDER BY 列名1 ASC|DESC, 列名2 ASC|DESC
这样会先按照列名1进行排序,每组列名1相同的数据再按照列名2排序。
聚集函数
聚集函数一般用作统计,包括:
count([distinct]*)统计所有的行数(distinct表示去重再统计,下同)count([distinct]列名)统计某列的值总和sum([distinct]列名)求一列的和(注意必须是数字类型的)avg([distinct]列名)求一列的平均值(注意必须是数字类型)max([distinct]列名)求一列的最大值min([distinct]列名)求一列的最小值
一般聚集函数是这样使用的:
SELECT count(distinct 列名) FROM 表名 WHERE 条件
分组和分页查询
通过使用group by来对查询结果进行分组,它需要结合聚合函数一起使用:
SELECT sum(*) FROM 表名 WHERE 条件 GROUP BY 列名
我们还可以添加having来限制分组条件:
SELECT sum(*) FROM 表名 WHERE 条件 GROUP BY 列名 HAVING 约束条件
我们可以通过limit来限制查询的数量,只取前n个结果:
SELECT * FROM 表名 LIMIT 数量
我们也可以进行分页:
SELECT * FROM 表名 LIMIT 起始位置,数量
多表查询
多表查询是同时查询的两个或两个以上的表,多表查询会提通过连接转换为单表查询。
SELECT * FROM 表1, 表2
直接这样查询会得到两张表的笛卡尔积,也就是每一项数据和另一张表的每一项数据都结合一次,会产生庞大的数据。
SELECT * FROM 表1, 表2 WHERE 条件
这样,只会从笛卡尔积的结果中得到满足条件的数据。
注意:如果两个表中都带有此属性吗,需要添加表名前缀来指明是哪一个表的数据。
自身连接查询
自身连接,就是将表本身和表进行笛卡尔积计算,得到结果,但是由于表名相同,因此要先起一个别名:
SELECT * FROM 表名 别名1, 表名 别名2
其实自身连接查询和前面的是一样的,只是连接对象变成自己和自己了。
外连接查询
外连接就是专门用于联合查询情景的,比如现在有一个存储所有用户的表,还有一张用户详细信息的表,我希望将这两张表结合到一起来查看完整的数据,我们就可以通过使用外连接来进行查询,外连接有三种方式:
- 通过使用
inner join进行内连接,只会返回两个表满足条件的交集部分:
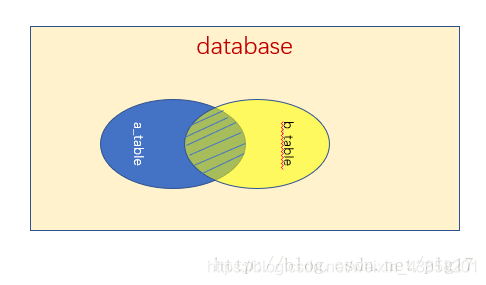
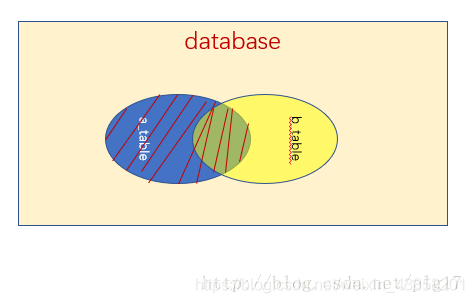
- 通过使用
left join进行左连接,不仅会返回两个表满足条件的交集部分,也会返回左边表中的全部数据,而在右表中缺失的数据会使用null来代替(右连接right join同理,只是反过来而已,这里就不再介绍了):
嵌套查询
我们可以将查询的结果作为另一个查询的条件,比如:
SELECT * FROM 表名 WHERE 列名 = (SELECT 列名 FROM 表名 WHERE 条件)
我们来再次尝试编写一下在最开始我们查找某教师所有学生的SQL语句。
数据库控制语言(DCL)
庞大的数据库不可能由一个人来管理,我们需要更多的用户来一起管理整个数据库。
创建用户
我们可以通过create user来创建用户:
CREATE USER 用户名 identified by 密码;
也可以不带密码:
CREATE USER 用户名;
我们可以通过@来限制用户登录的登录IP地址,%表示匹配所有的IP地址,默认使用的就是任意IP地址。
登陆用户
首先需要添加一个环境变量,然后我们通过cmd去登陆mysql:
login -u 用户名 -p
输入密码后即可登陆此用户,我们输入以下命令来看看能否访问所有数据库:
show databases;
我们发现,虽然此用户能够成功登录,但是并不能查看完整的数据库列表,这是因为此用户还没有权限!
用户授权
我们可以通过使用grant来为一个数据库用户进行授权:
grant all|权限1,权限2...(列1,...) on 数据库.表 to 用户 [with grant option]
其中all代表授予所有权限,当数据库和表为*,代表为所有的数据库和表都授权。如果在最后添加了with grant option,那么被授权的用户还能将已获得的授权继续授权给其他用户。
我们可以使用revoke来收回一个权限:
revoke all|权限1,权限2...(列1,...) on 数据库.表 from 用户
视图
视图本质就是一个查询的结果,不过我们每次都可以通过打开视图来按照我们想要的样子查看数据。
既然视图本质就是一个查询的结果,那么它本身就是一个虚表,并不是真实存在的,数据实际上还是存放在原来的表中。
我们可以通过create view来创建视图;
CREATE VIEW 视图名称(列名) as 子查询语句 [WITH CHECK OPTION];
WITH CHECK OPTION是指当创建后,如果更新视图中的数据,是否要满足子查询中的条件表达式,不满足将无法插入,创建后,我们就可以使用select语句来直接查询视图上的数据了,因此,还能在视图的基础上,导出其他的视图。
- 若视图是由两个以上基本表导出的,则此视图不允许更新。
- 若视图的字段来自字段表达式或常数,则不允许对此视图执行INSERT和UPDATE操作,但允许执行DELETE操作。
- 若视图的字段来自集函数,则此视图不允许更新。
- 若视图定义中含有GROUP BY子句,则此视图不允许更新。
- 若视图定义中含有DISTINCT短语,则此视图不允许更新。
- 若视图定义中有嵌套查询,并且内层查询的FROM子句中涉及的表也是导出该视图的基本表,则此视图不允许更新。例如将成绩在平均成绩之上的元组定义成一个视图GOOD_SC: CREATE VIEW GOOD_SC AS SELECT Sno, Cno, Grade FROM SC WHERE Grade > (SELECT AVG(Grade) FROM SC); 导出视图GOOD_SC的基本表是SC,内层查询中涉及的表也是SC,所以视图GOOD_SC是不允许更新的。
- 一个不允许更新的视图上定义的视图也不允许更新
通过drop来删除一个视图:
drop view apptest
索引
在数据量变得非常庞大时,通过创建索引,能够大大提高我们的查询效率,就像Hash表一样,它能够快速地定位元素存放的位置,我们可以通过下面的命令创建索引:
-- 创建索引
CREATE INDEX 索引名称 ON 表名 (列名)
-- 查看表中的索引
show INDEX FROM student
我们也可以通过下面的命令删除一个索引:
drop index 索引名称 on 表名
虽然添加索引后会使得查询效率更高,但是我们不能过度使用索引,索引为我们带来高速查询效率的同时,也会在数据更新时产生额外建立索引的开销,同时也会占用磁盘资源。
触发器
触发器就像其名字一样,在某种条件下会自动触发,在select/update/delete时,会自动执行我们预先设定的内容,触发器通常用于检查内容的安全性,相比直接添加约束,触发器显得更加灵活。
触发器所依附的表称为基本表,当触发器表上发生select/update/delete等操作时,会自动生成两个临时的表(new表和old表,只能由触发器使用)
比如在insert操作时,新的内容会被插入到new表中;在delete操作时,旧的内容会被移到old表中,我们仍可在old表中拿到被删除的数据;在update操作时,旧的内容会被移到old表中,新的内容会出现在new表中。
CREATE TRIGGER 触发器名称 [BEFORE|AFTER] [INSERT|UPDATE|DELETE] ON 表名/视图名 FOR EACH ROW DELETE FROM student WHERE student.sno = new.sno
FOR EACH ROW表示针对每一行都会生效,无论哪行进行指定操作都会执行触发器!
通过下面的命令来查看触发器:
SHOW TRIGGERS
如果不需要,我们就可以删除此触发器:
DROP TRIGGER 触发器名称
事务
当我们要进行的操作非常多时,比如要依次删除很多个表的数据,我们就需要执行大量的SQL语句来完成,这些数据库操作语句就可以构成一个事务!只有Innodb引擎支持事务,我们可以这样来查看支持的引擎:
SHOW ENGINES;
MySQL默认采用的是Innodb引擎,我们也可以去修改为其他的引擎。
事务具有以下特性:
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
我们通过以下例子来探究以下事务:
begin; #开始事务
...
rollback; #回滚事务
savepoint 回滚点; #添加回滚点
rollback to 回滚点; #回滚到指定回滚点
...
commit; #提交事务
-- 一旦提交,就无法再进行回滚了!
Java与数据库
初识JDBC
JDBC是什么?
JDBC英文名为:Java Data Base Connectivity(Java数据库连接),官方解释它是Java编程语言和广泛的数据库之间独立于数据库的连接标准的Java API,根本上说JDBC是一种规范,它提供的接口,一套完整的,允许便捷式访问底层数据库。
可以用JAVA来写不同类型的可执行文件:JAVA应用程序、JAVA Applets、Java Servlet、JSP等,不同的可执行文件都能通过JDBC访问数据库,又兼备存储的优势。简单说它就是Java与数据库的连接的桥梁或者插件,用Java代码就能操作数据库的增删改查、存储过程、事务等。
我们可以发现,JDK自带了一个java.sql包,而这里面就定义了大量的接口,不同类型的数据库,都可以通过实现此接口,编写适用于自己数据库的实现类。而不同的数据库厂商实现的这套标准,我们称为数据库驱动。
准备工作
那么我们首先来进行一些准备工作,以便开始JDBC的学习:
- 将idea连接到我们的数据库,以便以后调试。
- 将mysql驱动jar依赖导入到项目中(推荐6.0版本以上,这里用到是8.0)
- 向Jetbrians申请一个学生/教师授权,用于激活idea终极版(进行JavaWeb开发需要用到,一般申请需要3-7天时间审核)不是大学生的话...emmm...懂的都懂。
- 教育授权申请地址:https://www.jetbrains.com/shop/eform/students
一个Java程序并不是一个人的战斗,我们可以在别人开发的基础上继续向上开发,其他的开发者可以将自己编写的Java代码打包为jar,我们只需要导入这个jar作为依赖,即可直接使用别人的代码,就像我们直接去使用JDK提供的类一样。
使用JDBC连接数据库
注意:6.0版本以上,不用手动加载驱动,我们直接使用即可!
//1. 通过DriverManager来获得数据库连接
try (Connection connection = DriverManager.getConnection("连接URL","用户名","密码");
//2. 创建一个用于执行SQL的Statement对象
Statement statement = connection.createStatement()){ //注意前两步都放在try()中,因为在最后需要释放资源!
//3. 执行SQL语句,并得到结果集
ResultSet set = statement.executeQuery("select * from 表名");
//4. 查看结果
while (set.next()){
...
}
}catch (SQLException e){
e.printStackTrace();
}
//5. 释放资源,try-with-resource语法会自动帮助我们close
其中,连接的URL如果记不住格式,我们可以打开idea的数据库连接配置,复制一份即可。(其实idea本质也是使用的JDBC,整个idea程序都是由Java编写的,实际上idea就是一个Java程序)
了解DriverManager
我们首先来了解一下DriverManager是什么东西,它其实就是管理我们的数据库驱动的:
public static synchronized void registerDriver(java.sql.Driver driver,
DriverAction da)
throws SQLException {
/* Register the driver if it has not already been added to our list */
if(driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver, da)); //在刚启动时,mysql实现的驱动会被加载,我们可以断点调试一下。
} else {
// This is for compatibility with the original DriverManager
throw new NullPointerException();
}
println("registerDriver: " + driver);
}
我们可以通过调用getConnection()来进行数据库的链接:
@CallerSensitive
public static Connection getConnection(String url,
String user, String password) throws SQLException {
java.util.Properties info = new java.util.Properties();
if (user != null) {
info.put("user", user);
}
if (password != null) {
info.put("password", password);
}
return (getConnection(url, info, Reflection.getCallerClass())); //内部有实现
}
我们可以手动为驱动管理器添加一个日志打印:
static {
DriverManager.setLogWriter(new PrintWriter(System.out)); //这里直接设定为控制台输出
}
现在我们执行的数据库操作日志会在控制台实时打印。
了解Connection
Connection是数据库的连接对象,可以通过连接对象来创建一个Statement用于执行SQL语句:
Statement createStatement() throws SQLException;
我们发现除了普通的Statement,还存在PreparedStatement:
PreparedStatement prepareStatement(String sql)
throws SQLException;
在后面我们会详细介绍PreparedStatement的使用,它能够有效地预防SQL注入式攻击。
它还支持事务的处理,也放到后面来详细进行讲解。
了解Statement
我们发现,我们之前使用了executeQuery()方法来执行select语句,此方法返回给我们一个ResultSet对象,查询得到的数据,就存放在ResultSet中!
Statement除了执行这样的DQL语句外,我们还可以使用executeUpdate()方法来执行一个DML或是DDL语句,它会返回一个int类型,表示执行后受影响的行数,可以通过它来判断DML语句是否执行成功。
也可以通过excute()来执行任意的SQL语句,它会返回一个boolean来表示执行结果是一个ResultSet还是一个int,我们可以通过使用getResultSet()或是getUpdateCount()来获取。
执行DML操作
我们通过几个例子来向数据库中插入数据。
执行DQL操作
执行DQL操作会返回一个ResultSet对象,我们来看看如何从ResultSet中去获取数据:
//首先要明确,select返回的数据类似于一个excel表格
while (set.next()){
//每调用一次next()就会向下移动一行,首次调用会移动到第一行
}
我们在移动行数后,就可以通过set中提供的方法,来获取每一列的数据。

执行批处理操作
当我们要执行很多条语句时,可以不用一次一次地提交,而是一口气全部交给数据库处理,这样会节省很多的时间。
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection();
Statement statement = connection.createStatement()){
statement.addBatch("insert into user values ('f', 1234)");
statement.addBatch("insert into user values ('e', 1234)"); //添加每一条批处理语句
statement.executeBatch(); //一起执行
}catch (SQLException e){
e.printStackTrace();
}
}
将查询结果映射为对象
既然我们现在可以从数据库中获取数据了,那么现在就可以将这些数据转换为一个类来进行操作,首先定义我们的实体类:
public class Student {
Integer sid;
String name;
String sex;
public Student(Integer sid, String name, String sex) {
this.sid = sid;
this.name = name;
this.sex = sex;
}
public void say(){
System.out.println("我叫:"+name+",学号为:"+sid+",我的性别是:"+sex);
}
}
现在我们来进行一个转换:
while (set.next()){
Student student = new Student(set.getInt(1), set.getString(2), set.getString(3));
student.say();
}
注意:列的下标是从1开始的。
我们也可以利用反射机制来将查询结果映射为对象,使用反射的好处是,无论什么类型都可以通过我们的方法来进行实体类型映射:
private static <T> T convert(ResultSet set, Class<T> clazz){
try {
Constructor<T> constructor = clazz.getConstructor(clazz.getConstructors()[0].getParameterTypes()); //默认获取第一个构造方法
Class<?>[] param = constructor.getParameterTypes(); //获取参数列表
Object[] object = new Object[param.length]; //存放参数
for (int i = 0; i < param.length; i++) { //是从1开始的
object[i] = set.getObject(i+1);
if(object[i].getClass() != param[i])
throw new SQLException("错误的类型转换:"+object[i].getClass()+" -> "+param[i]);
}
return constructor.newInstance(object);
} catch (ReflectiveOperationException | SQLException e) {
e.printStackTrace();
return null;
}
}
现在我们就可以通过我们的方法来将查询结果转换为一个对象了:
while (set.next()){
Student student = convert(set, Student.class);
if(student != null) student.say();
}
实际上,在后面我们会学习Mybatis框架,它对JDBC进行了深层次的封装,而它就进行类似上面反射的操作来便于我们对数据库数据与实体类的转换。
自己写一个Mybatis。
实现登陆与SQL注入攻击
在使用之前,我们先来看看如果我们想模拟登陆一个用户,我们该怎么去写:
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
Statement statement = connection.createStatement();
Scanner scanner = new Scanner(System.in)){
ResultSet res = statement.executeQuery("select * from user where username='"+scanner.nextLine()+"'and pwd='"+scanner.nextLine()+"';");
while (res.next()){
String username = res.getString(1);
System.out.println(username+" 登陆成功!");
}
}catch (SQLException e){
e.printStackTrace();
}
用户可以通过自己输入用户名和密码来登陆,乍一看好像没啥问题,那如果我输入的是以下内容呢:
Test
1111' or 1=1; --
# Test 登陆成功!
1=1一定是true,那么我们原本的SQL语句会变为:
select * from user where username='Test' and pwd='1111' or 1=1; -- '
我们发现,如果允许这样的数据插入,那么我们原有的SQL语句结构就遭到了破坏,使得用户能够随意登陆别人的账号。
因此我们可能需要限制用户的输入来防止用户输入一些SQL语句关键字,但是关键字非常多,这并不是解决问题的最好办法。
使用PreparedStatement
我们发现,如果单纯地使用Statement来执行SQL命令,会存在严重的SQL注入攻击漏洞!而这种问题,我们可以使用PreparedStatement来解决:
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
PreparedStatement statement = connection.prepareStatement("select * from user where username= ? and pwd=?;");
Scanner scanner = new Scanner(System.in)){
statement.setString(1, scanner.nextLine());
statement.setString(2, scanner.nextLine());
System.out.println(statement); //打印查看一下最终执行的
ResultSet res = statement.executeQuery();
while (res.next()){
String username = res.getString(1);
System.out.println(username+" 登陆成功!");
}
}catch (SQLException e){
e.printStackTrace();
}
}
我们发现,我们需要提前给到PreparedStatement一个SQL语句,并且使用?作为占位符,它会预编译一个SQL语句,通过直接将我们的内容进行替换的方式来填写数据。
使用这种方式,我们之前的例子就失效了!我们来看看实际执行的SQL语句是什么:
com.mysql.cj.jdbc.ClientPreparedStatement: select * from user where username= 'Test' and pwd='123456'' or 1=1; -- ';
我们发现,我们输入的参数一旦出现'时,会被变为转义形式\',而最外层有一个真正的'来将我们输入的内容进行包裹,因此它能够有效地防止SQL注入攻击!
管理事务
JDBC默认的事务处理行为是自动提交,所以前面我们执行一个SQL语句就会被直接提交(相当于没有启动事务),所以JDBC需要进行事务管理时,首先要通过Connection对象调用setAutoCommit(false) 方法, 将SQL语句的提交(commit)由驱动程序转交给应用程序负责。
con.setAutoCommit(); //关闭自动提交后相当于开启事务。
// SQL语句
// SQL语句
// SQL语句
con.commit();或 con.rollback();
一旦关闭自动提交,那么现在执行所有的操作如果在最后不进行commit()来提交事务的话,那么所有的操作都会丢失,只有提交之后,所有的操作才会被保存!也可以使用rollback()来手动回滚之前的全部操作!
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
Statement statement = connection.createStatement()){
connection.setAutoCommit(false); //关闭自动提交,现在将变为我们手动提交
statement.executeUpdate("insert into user values ('a', 1234)");
statement.executeUpdate("insert into user values ('b', 1234)");
statement.executeUpdate("insert into user values ('c', 1234)");
connection.commit(); //如果前面任何操作出现异常,将不会执行commit(),之前的操作也就不会生效
}catch (SQLException e){
e.printStackTrace();
}
}
我们来接着尝试一下使用回滚操作:
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
Statement statement = connection.createStatement()){
connection.setAutoCommit(false); //关闭自动提交,现在将变为我们手动提交
statement.executeUpdate("insert into user values ('a', 1234)");
statement.executeUpdate("insert into user values ('b', 1234)");
connection.rollback(); //回滚,撤销前面全部操作
statement.executeUpdate("insert into user values ('c', 1234)");
connection.commit(); //提交事务(注意,回滚之前的内容都没了)
}catch (SQLException e){
e.printStackTrace();
}
}
同样的,我们也可以去创建一个回滚点来实现定点回滚:
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
Statement statement = connection.createStatement()){
connection.setAutoCommit(false); //关闭自动提交,现在将变为我们手动提交
statement.executeUpdate("insert into user values ('a', 1234)");
Savepoint savepoint = connection.setSavepoint(); //创建回滚点
statement.executeUpdate("insert into user values ('b', 1234)");
connection.rollback(savepoint); //回滚到回滚点,撤销前面全部操作
statement.executeUpdate("insert into user values ('c', 1234)");
connection.commit(); //提交事务(注意,回滚之前的内容都没了)
}catch (SQLException e){
e.printStackTrace();
}
}
通过开启事务,我们就可以更加谨慎地进行一些操作了,如果我们想从事务模式切换为原有的自动提交模式,我们可以直接将其设置回去:
public static void main(String[] args) throws ClassNotFoundException {
try (Connection connection = DriverManager.getConnection("URL","用户名","密码");
Statement statement = connection.createStatement()){
connection.setAutoCommit(false); //关闭自动提交,现在将变为我们手动提交
statement.executeUpdate("insert into user values ('a', 1234)");
connection.setAutoCommit(true); //重新开启自动提交,开启时把之前的事务模式下的内容给提交了
statement.executeUpdate("insert into user values ('d', 1234)");
//没有commit也成功了!
}catch (SQLException e){
e.printStackTrace();
}
通过学习JDBC,我们现在就可以通过Java来访问和操作我们的数据库了!为了更好地衔接,我们还会接着讲解主流持久层框架——Mybatis,加深JDBC的记忆。
使用Lombok
我们发现,在以往编写项目时,尤其是在类进行类内部成员字段封装时,需要编写大量的get/set方法,这不仅使得我们类定义中充满了get和set方法,同时如果字段名称发生改变,又要挨个进行修改,甚至当字段变得很多时,构造方法的编写会非常麻烦!
通过使用Lombok(小辣椒)就可以解决这样的问题!
我们来看看,使用原生方式和小辣椒方式编写类的区别,首先是传统方式:
public class Student {
private Integer sid;
private String name;
private String sex;
public Student(Integer sid, String name, String sex) {
this.sid = sid;
this.name = name;
this.sex = sex;
}
public Integer getSid() { //长!
return sid;
}
public void setSid(Integer sid) { //到!
this.sid = sid;
}
public String getName() { //爆!
return name;
}
public void setName(String name) { //炸!
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
而使用Lombok之后:
@Getter
@Setter
@AllArgsConstructor
public class Student {
private Integer sid;
private String name;
private String sex;
}
我们发现,使用Lombok之后,只需要添加几个注解,就能够解决掉我们之前长长的一串代码!
配置Lombok
- 首先我们需要导入Lombok的jar依赖,和jdbc依赖是一样的,放在项目目录下直接导入就行了。可以在这里进行下载:https://projectlombok.org/download
- 然后我们要安装一下Lombok插件,由于IDEA默认都安装了Lombok的插件,因此直接导入依赖后就可以使用了。
- 重启IDEA
Lombok是一种插件化注解API,是通过添加注解来实现的,然后在javac进行编译的时候,进行处理。
Java的编译过程可以分成三个阶段:
- 所有源文件会被解析成语法树。
- 调用注解处理器。如果注解处理器产生了新的源文件,新文件也要进行编译。
- 最后,语法树会被分析并转化成类文件。
实际上在上述的第二阶段,会执行lombok.core.AnnotationProcessor,它所做的工作就是我们上面所说的,修改语法树。
使用Lombok
我们通过实战来演示一下Lombok的实用注解:
- 我们通过添加
@Getter和@Setter来为当前类的所有字段生成get/set方法,他们可以添加到类或是字段上,注意静态字段不会生成,final字段无法生成set方法。- 我们还可以使用@Accessors来控制生成Getter和Setter的样式。
- 我们通过添加
@ToString来为当前类生成预设的toString方法。 - 我们可以通过添加
@EqualsAndHashCode来快速生成比较和哈希值方法。 - 我们可以通过添加
@AllArgsConstructor和@NoArgsConstructor来快速生成全参构造和无参构造。 - 我们可以添加
@RequiredArgsConstructor来快速生成参数只包含final或被标记为@NonNull的成员字段。 - 使用
@Data能代表@Setter、@Getter、@RequiredArgsConstructor、@ToString、@EqualsAndHashCode全部注解。- 一旦使用
@Data就不建议此类有继承关系,因为equal方法可能不符合预期结果(尤其是仅比较子类属性)。
- 一旦使用
- 使用
@Value与@Data类似,但是并不会生成setter并且成员属性都是final的。 - 使用
@SneakyThrows来自动生成try-catch代码块。 - 使用
@Cleanup作用与局部变量,在最后自动调用其close()方法(可以自由更换) - 使用
@Builder来快速生成建造者模式。- 通过使用
@Builder.Default来指定默认值。 - 通过使用
@Builder.ObtainVia来指定默认值的获取方式。
- 通过使用
认识Mybatis
在前面JDBC的学习中,虽然我们能够通过JDBC来连接和操作数据库,但是哪怕只是完成一个SQL语句的执行,都需要编写大量的代码,更不用说如果我还需要进行实体类映射,将数据转换为我们可以直接操作的实体类型,JDBC很方便,但是还不够方便,我们需要一种更加简洁高效的方式来和数据库进行交互。
再次强调:学习厉害的框架或是厉害的技术,并不是为了一定要去使用它,而是它们能够使得我们在不同的开发场景下,合理地使用这些技术,以灵活地应对需要解决的问题。

MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。
我们依然使用传统的jar依赖方式,从最原始开始讲起,不使用Maven,有关Maven内容我们会在后面统一讲解!全程围绕官方文档讲解!
这一块内容很多很杂,再次强调要多实践!
XML语言概述
在开始介绍Mybatis之前,XML语言发明最初是用于数据的存储和传输,它可以长这样:
<?xml version="1.0" encoding="UTF-8" ?>
<outer>
<name>阿伟</name>
<desc>怎么又在玩电动啊</desc>
<inner type="1">
<age>10</age>
<sex>男</sex>
</inner>
</outer>
如果你学习过前端知识,你会发现它和HTML几乎长得一模一样!但是请注意,虽然它们长得差不多,但是他们的意义却不同,
HTML主要用于通过编排来展示数据,而XML主要是存放数据,它更像是一个配置文件!当然,浏览器也是可以直接打开XML文件的。
一个XML文件存在以下的格式规范:
- 必须存在一个根节点,将所有的子标签全部包含。
- 可以但不必须包含一个头部声明(主要是可以设定编码格式)
- 所有的标签必须成对出现,可以嵌套但不能交叉嵌套
- 区分大小写。
- 标签中可以存在属性,比如上面的
type="1"就是inner标签的一个属性,属性的值由单引号或双引号包括。
XML文件也可以使用注释:
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 注释内容 -->
通过IDEA我们可以使用Ctrl+/来快速添加注释文本(不仅仅适用于XML,还支持很多种类型的文件)
那如果我们的内容中出现了<或是>字符,那该怎么办呢?我们就可以使用XML的转义字符来代替:

如果嫌一个一个改太麻烦,也可以使用CD来快速创建不解析区域:
<test>
<name><![CDATA[我看你<><><>是一点都不懂哦>>>]]></name>
</test>
那么,我们现在了解了XML文件的定义,现在该如何去解析一个XML文件呢?比如我们希望将定义好的XML文件读取到Java程序中,这时该怎么做呢?
JDK为我们内置了一个叫做org.w3c的XML解析库,我们来看看如何使用它来进行XML文件内容解析:
// 创建DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder对象
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document d = builder.parse("file:mappers/test.xml");
// 每一个标签都作为一个节点
NodeList nodeList = d.getElementsByTagName("test"); // 可能有很多个名字为test的标签
Node rootNode = nodeList.item(0); // 获取首个
NodeList childNodes = rootNode.getChildNodes(); // 一个节点下可能会有很多个节点,比如根节点下就囊括了所有的节点
//节点可以是一个带有内容的标签(它内部就还有子节点),也可以是一段文本内容
for (int i = 0; i < childNodes.getLength(); i++) {
Node child = childNodes.item(i);
if(child.getNodeType() == Node.ELEMENT_NODE) //过滤换行符之类的内容,因为它们都被认为是一个文本节点
System.out.println(child.getNodeName() + ":" +child.getFirstChild().getNodeValue());
// 输出节点名称,也就是标签名称,以及标签内部的文本(内部的内容都是子节点,所以要获取内部的节点)
}
} catch (Exception e) {
e.printStackTrace();
}
当然,学习和使用XML只是为了更好地去认识Mybatis的工作原理,以及如何使用XML来作为Mybatis的配置文件,这是在开始之前必须要掌握的内容(使用Java读取XML内容不要求掌握,但是需要知道Mybatis就是通过这种方式来读取配置文件的)
不仅仅是Mybatis,包括后面的Spring等众多框架都会用到XML来作为框架的配置文件!
初次使用Mybatis
那么我们首先来感受一下Mybatis给我们带来的便捷,就从搭建环境开始,
中文文档网站:https://mybatis.org/mybatis-3/zh/configuration.html
我们需要导入Mybatis的依赖,Jar包需要在github上下载,如果卡得一匹,自己%%%。
依赖导入完成后,我们就可以编写Mybatis的配置文件了(现在不是在Java代码中配置了,而是通过一个XML文件去配置,这样就使得硬编码的部分大大减少,项目后期打包成Jar运行不方便修复,但是通过配置文件,我们随时都可以去修改,就变得很方便了,同时代码量也大幅度减少,配置文件填写完成后,我们只需要关心项目的业务逻辑而不是如何去读取配置文件)我们按照官方文档给定的提示,在项目根目录下新建名为mybatis-config.xml的文件,并填写以下内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${驱动类(含包名)}"/>
<property name="url" value="${数据库连接URL}"/>
<property name="username" value="${用户名}"/>
<property name="password" value="${密码}"/>
</dataSource>
</environment>
</environments>
</configuration>
我们发现,在最上方还引入了一个叫做DTD(文档类型定义)的东西,它提前帮助我们规定了一些标签,我们就需要使用Mybatis提前帮助我们规定好的标签来进行配置(因为只有这样Mybatis才能正确识别我们配置的内容)
通过进行配置,我们就告诉了Mybatis我们链接数据库的一些信息,包括URL、用户名、密码等,这样Mybatis就知道该链接哪个数据库、使用哪个账号进行登陆了(也可以不使用配置文件,这里不做讲解,还请各位小伙伴自行阅读官方文档)
配置文件完成后,我们需要在Java程序启动时,让Mybatis对配置文件进行读取并得到一个SqlSessionFactory对象:
public static void main(String[] args) throws FileNotFoundException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
//暂时还没有业务
}
}
直接运行即可,虽然没有干什么事情,但是不会出现错误,如果之前的配置文件编写错误,直接运行会产生报错!那么现在我们来看看,SqlSessionFactory对象是什么东西:

每个基于 MyBatis 的应用都是以一个 SqlSessionFactory 的实例为核心的,我们可以通过SqlSessionFactory来创建多个新的会话,SqlSession对象,每个会话就相当于我不同的地方登陆一个账号去访问数据库,你也可以认为这就是之前JDBC中的Statement对象,会话之间相互隔离,没有任何关联。
而通过SqlSession就可以完成几乎所有的数据库操作,我们发现这个接口中定义了大量数据库操作的方法,因此,现在我们只需要通过一个对象就能完成数据库交互了,极大简化了之前的流程。
我们来尝试一下直接读取实体类,读取实体类肯定需要一个映射规则,比如类中的哪个字段对应数据库中的哪个字段,在查询语句返回结果后,Mybatis就会自动将对应的结果填入到对象的对应字段上。首先编写实体类,,直接使用Lombok是不是就很方便了:
import lombok.Data;
@Data
public class Student {
int sid; //名称最好和数据库字段名称保持一致,不然可能会映射失败导致查询结果丢失
String name;
String sex;
}
在根目录下重新创建一个mapper文件夹,新建名为TestMapper.xml的文件作为我们的映射器,并填写以下内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="TestMapper">
<select id="selectStudent" resultType="com.test.entity.Student">
select * from student
</select>
</mapper>
其中namespace就是命名空间,每个Mapper都是唯一的,因此需要用一个命名空间来区分,它还可以用来绑定一个接口。我们在里面写入了一个select标签,表示添加一个select操作,同时id作为操作的名称,resultType指定为我们刚刚定义的实体类,表示将数据库结果映射为Student类,然后就在标签中写入我们的查询语句即可。
编写好后,我们在配置文件中添加这个Mapper映射器:
<mappers>
<mapper url="file:mappers/TestMapper.xml"/>
<!-- 这里用的是url,也可以使用其他类型,我们会在后面讲解 -->
</mappers>
最后在程序中使用我们定义好的Mapper即可:
public static void main(String[] args) throws FileNotFoundException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
List<Student> student = sqlSession.selectList("selectStudent");
student.forEach(System.out::println);
}
}
我们会发现,Mybatis非常智能,我们只需要告诉一个映射关系,就能够直接将查询结果转化为一个实体类。
配置Mybatis
在了解了Mybatis为我们带来的便捷之后,现在我们就可以正式地去学习使用Mybatis了!
由于SqlSessionFactory一般只需要创建一次,因此我们可以创建一个工具类来集中创建SqlSession,这样会更加方便一些:
public class MybatisUtil {
//在类加载时就进行创建
private static SqlSessionFactory sqlSessionFactory;
static {
try {
sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
/**
* 获取一个新的会话
* @param autoCommit 是否开启自动提交(跟JDBC是一样的,如果不自动提交,则会变成事务操作)
* @return SqlSession对象
*/
public static SqlSession getSession(boolean autoCommit){
return sqlSessionFactory.openSession(autoCommit);
}
}
现在我们只需要在main方法中这样写即可查询结果了:
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
List<Student> student = sqlSession.selectList("selectStudent");
student.forEach(System.out::println);
}
}
之前我们演示了,如何创建一个映射器来将结果快速转换为实体类,但是这样可能还是不够方便,我们每次都需要去找映射器对应操作的名称,而且还要知道对应的返回类型,再通过SqlSession来执行对应的方法,能不能再方便一点呢?
现在,我们可以通过namespace来绑定到一个接口上,利用接口的特性,我们可以直接指明方法的行为,而实际实现则是由Mybatis来完成。
public interface TestMapper {
List<Student> selectStudent();
}
将Mapper文件的命名空间修改为我们的接口,建议同时将其放到同名包中,作为内部资源:
<mapper namespace="com.test.mapper.TestMapper">
<select id="selectStudent" resultType="com.test.entity.Student">
select * from student
</select>
</mapper>
作为内部资源后,我们需要修改一下配置文件中的mapper定义,不使用url而是resource表示是Jar内部的文件:
<mappers>
<mapper resource="com/test/mapper/TestMapper.xml"/>
</mappers>
现在我们就可以直接通过SqlSession获取对应的实现类,通过接口中定义的行为来直接获取结果:
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
List<Student> student = testMapper.selectStudent();
student.forEach(System.out::println);
}
}
那么肯定有人好奇,TestMapper明明是一个我们自己定义接口啊,Mybatis也不可能提前帮我们写了实现类啊,那这接口怎么就出现了一个实现类呢?我们可以通过调用getClass()方法来看看实现类是个什么:
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
System.out.println(testMapper.getClass());
我们发现,实现类名称很奇怪,名称为com.sun.proxy.$Proxy4,它是通过动态代理生成的,相当于动态生成了一个实现类,而不是预先定义好的,有关Mybatis这一部分的原理,我们放在最后一节进行讲解。
接下来,我们再来看配置文件,之前我们并没有对配置文件进行一个详细的介绍:
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/study"/>
<property name="username" value="test"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/test/mapper/TestMapper.xml"/>
</mappers>
</configuration>
首先就从environments标签说起,一般情况下,我们在开发中,都需要指定一个数据库的配置信息,包含连接URL、用户、密码等信息,而environment就是用于进行这些配置的!
实际情况下可能会不止有一个数据库连接信息,比如开发过程中我们一般会使用本地的数据库,而如果需要将项目上传到服务器或是防止其他人的电脑上运行时,我们可能就需要配置另一个数据库的信息,因此,我们可以提前定义好所有的数据库信息,该什么时候用什么即可!
在environments标签上有一个default属性,来指定默认的环境,当然如果我们希望使用其他环境,可以修改这个默认环境,也可以在创建工厂时选择环境:
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"), "环境ID");
我们还可以给类型起一个别名,以简化Mapper的编写:
<!-- 需要在environments的上方 -->
<typeAliases>
<typeAlias type="com.test.entity.Student" alias="Student"/>
</typeAliases>
现在Mapper就可以直接使用别名了:
<mapper namespace="com.test.mapper.TestMapper">
<select id="selectStudent" resultType="Student">
select * from student
</select>
</mapper>
如果这样还是很麻烦,我们也可以直接让Mybatis去扫描一个包,并将包下的所有类自动起别名(别名为首字母小写的类名)
<typeAliases>
<package name="com.test.entity"/>
</typeAliases>
也可以为指定实体类添加一个注解,来指定别名:
@Data
@Alias("lbwnb")
public class Student {
private int sid;
private String name;
private String sex;
}
当然,Mybatis也包含许多的基础配置,通过使用:
<settings>
<setting name="" value=""/>
</settings>
所有的配置项可以在中文文档处查询,本文不会进行详细介绍,在后面我们会提出一些比较重要的配置项。
有关配置文件的介绍就暂时到这里为止,我们讨论的重心应该是Mybatis的应用,而不是配置文件,所以省略了一部分内容的讲解。
增删改查
在了解了Mybatis的一些基本配置之后,我们就可以正式来使用Mybatis来进行数据库操作了!
在前面我们演示了如何快速进行查询,我们只需要编写一个对应的映射器既可以了:
<mapper namespace="com.test.mapper.TestMapper">
<select id="studentList" resultType="Student">
select * from student
</select>
</mapper>
当然,如果你不喜欢使用实体类,那么这些属性还可以被映射到一个Map上:
<select id="selectStudent" resultType="Map">
select * from student
</select>
public interface TestMapper {
List<Map> selectStudent();
}
Map中就会以键值对的形式来存放这些结果了。
通过设定一个resultType属性,让Mybatis知道查询结果需要映射为哪个实体类,要求字段名称保持一致。那么如果我们不希望按照这样的规则来映射呢?我们可以自定义resultMap来设定映射规则:
<resultMap id="Test" type="Student">
<result column="sid" property="sid"/>
<result column="sex" property="name"/>
<result column="name" property="sex"/>
</resultMap>
通过指定映射规则,我们现在名称和性别一栏就发生了交换,因为我们将其映射字段进行了交换。
如果一个类中存在多个构造方法,那么很有可能会出现这样的错误:
### Exception in thread "main" org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.executor.ExecutorException: No constructor found in com.test.entity.Student matching [java.lang.Integer, java.lang.String, java.lang.String]
### The error may exist in com/test/mapper/TestMapper.xml
### The error may involve com.test.mapper.TestMapper.getStudentBySid
### The error occurred while handling results
### SQL: select * from student where sid = ?
### Cause: org.apache.ibatis.executor.ExecutorException: No constructor found in com.test.entity.Student matching [java.lang.Integer, java.lang.String, java.lang.String]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
...
这时就需要使用constructor标签来指定构造方法:
<resultMap id="test" type="Student">
<constructor>
<arg column="sid" javaType="Integer"/>
<arg column="name" javaType="String"/>
</constructor>
</resultMap>
值得注意的是,指定构造方法后,若此字段被填入了构造方法作为参数,将不会通过反射给字段单独赋值,而构造方法中没有传入的字段,依然会被反射赋值,有关resultMap的内容,后面还会继续讲解。
如果数据库中存在一个带下划线的字段,我们可以通过设置让其映射为以驼峰命名的字段,比如my_test映射为myTest
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
如果不设置,默认为不开启,也就是默认需要名称保持一致。
我们接着来看看条件查询,既然是条件查询,那么肯定需要我们传入查询条件,比如现在我们想通过sid字段来通过学号查找信息:
Student getStudentBySid(int sid);
<select id="getStudentBySid" parameterType="int" resultType="Student">
select * from student where sid = #{sid}
</select>
我们通过使用#{xxx}或是${xxx}来填入我们给定的属性,实际上Mybatis本质也是通过PreparedStatement首先进行一次预编译,有效地防止SQL注入问题,但是如果使用${xxx}就不再是通过预编译,而是直接传值,因此我们一般都使用#{xxx}来进行操作。
使用parameterType属性来指定参数类型(非必须,可以不用,推荐不用)
接着我们来看插入、更新和删除操作,其实与查询操作差不多,不过需要使用对应的标签,比如插入操作:
<insert id="addStudent" parameterType="Student">
insert into student(name, sex) values(#{name}, #{sex})
</insert>
int addStudent(Student student);
我们这里使用的是一个实体类,我们可以直接使用实体类里面对应属性替换到SQL语句中,只需要填写属性名称即可,和条件查询是一样的。
复杂查询
一个老师可以教授多个学生,那么能否一次性将老师的学生全部映射给此老师的对象呢,比如:
@Data
public class Teacher {
int tid;
String name;
List<Student> studentList;
}
映射为Teacher对象时,同时将其教授的所有学生一并映射为List列表,显然这是一种一对多的查询,那么这时就需要进行复杂查询了。而我们之前编写的都非常简单,直接就能完成映射,因此我们现在需要使用resultMap来自定义映射规则:
<select id="getTeacherByTid" resultMap="asTeacher">
select *, teacher.name as tname from student inner join teach on student.sid = teach.sid
inner join teacher on teach.tid = teacher.tid where teach.tid = #{tid}
</select>
<resultMap id="asTeacher" type="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
<collection property="studentList" ofType="Student">
<id property="sid" column="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
</collection>
</resultMap>
可以看到,我们的查询结果是一个多表联查的结果,而联查的数据就是我们需要映射的数据(比如这里是一个老师有N个学生,联查的结果也是这一个老师对应N个学生的N条记录),其中id标签用于在多条记录中辨别是否为同一个对象的数据,比如上面的查询语句得到的结果中,tid这一行始终为1,因此所有的记录都应该是tid=1的教师的数据,而不应该变为多个教师的数据,如果不加id进行约束,那么会被识别成多个教师的数据!
通过使用collection来表示将得到的所有结果合并为一个集合,比如上面的数据中每个学生都有单独的一条记录,因此tid相同的全部学生的记录就可以最后合并为一个List,得到最终的映射结果,当然,为了区分,最好也设置一个id,只不过这个例子中可以当做普通的result使用。
了解了一对多,那么多对一又该如何查询呢,比如每个学生都有一个对应的老师,现在Student新增了一个Teacher对象,那么现在又该如何去处理呢?
@Data
@Accessors(chain = true)
public class Student {
private int sid;
private String name;
private String sex;
private Teacher teacher;
}
@Data
public class Teacher {
int tid;
String name;
}
现在我们希望的是,每次查询到一个Student对象时都带上它的老师,同样的,我们也可以使用resultMap来实现(先修改一下老师的类定义,不然会很麻烦):
<resultMap id="test2" type="Student">
<id column="sid" property="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
<association property="teacher" javaType="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
</association>
</resultMap>
<select id="selectStudent" resultMap="test2">
select *, teacher.name as tname from student left join teach on student.sid = teach.sid
left join teacher on teach.tid = teacher.tid
</select>
通过使用association进行关联,形成多对一的关系,实际上和一对多是同理的,都是对查询结果的一种处理方式罢了。
事务操作
我们可以在获取SqlSession关闭自动提交来开启事务模式,和JDBC其实都差不多:
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(false)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
testMapper.addStudent(new Student().setSex("男").setName("小王"));
testMapper.selectStudent().forEach(System.out::println);
}
}
我们发现,在关闭自动提交后,我们的内容是没有进入到数据库的,现在我们来试一下在最后提交事务:
sqlSession.commit();
在事务提交后,我们的内容才会被写入到数据库中。现在我们来试试看回滚操作:
try (SqlSession sqlSession = MybatisUtil.getSession(false)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
testMapper.addStudent(new Student().setSex("男").setName("小王"));
testMapper.selectStudent().forEach(System.out::println);
sqlSession.rollback();
sqlSession.commit();
}
回滚操作也印证成功。
动态SQL
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
我们直接使用官网的例子进行讲解。
缓存机制
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。
其实缓存机制我们在之前学习IO流的时候已经提及过了,我们可以提前将一部分内容放入缓存,下次需要获取数据时,我们就可以直接从缓存中读取,这样的话相当于直接从内存中获取而不是再去向数据库索要数据,效率会更高。
因此Mybatis内置了一个缓存机制,我们查询时,如果缓存中存在数据,那么我们就可以直接从缓存中获取,而不是再去向数据库进行请求。

Mybatis存在一级缓存和二级缓存,我们首先来看一下一级缓存,默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存(一级缓存无法关闭,只能调整),我们来看看下面这段代码:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
我们发现,两次得到的是同一个Student对象,也就是说我们第二次查询并没有重新去构造对象,而是直接得到之前创建好的对象。如果还不是很明显,我们可以修改一下实体类:
@Data
@Accessors(chain = true)
public class Student {
public Student(){
System.out.println("我被构造了");
}
private int sid;
private String name;
private String sex;
}
我们通过前面的学习得知Mybatis在映射为对象时,在只有一个构造方法的情况下,无论你构造方法写成什么样子,都会去调用一次构造方法,如果存在多个构造方法,那么就会去找匹配的构造方法。我们可以通过查看构造方法来验证对象被创建了几次。
结果显而易见,只创建了一次,也就是说当第二次进行同样的查询时,会直接使用第一次的结果,因为第一次的结果已经被缓存了。
那么如果我修改了数据库中的内容,缓存还会生效吗:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
testMapper.addStudent(new Student().setName("小李").setSex("男"));
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
我们发现,当我们进行了插入操作后,缓存就没有生效了,我们再次进行查询得到的是一个新创建的对象。
也就是说,一级缓存,在进行DML操作后,会使得缓存失效,也就是说Mybatis知道我们对数据库里面的数据进行了修改,所以之前缓存的内容可能就不是当前数据库里面最新的内容了。还有一种情况就是,当前会话结束后,也会清理全部的缓存,因为已经不会再用到了。但是一定注意,一级缓存只针对于单个会话,多个会话之间不相通。
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student2;
try(SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
student2 = testMapper2.getStudentBySid(1);
}
Student student1 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
注意:一个会话DML操作只会重置当前会话的缓存,不会重置其他会话的缓存,也就是说,其他会话缓存是不会更新的!
一级缓存给我们提供了很高速的访问效率,但是它的作用范围实在是有限,如果一个会话结束,那么之前的缓存就全部失效了,但是我们希望缓存能够扩展到所有会话都能使用,因此我们可以通过二级缓存来实现,二级缓存默认是关闭状态,要开启二级缓存,我们需要在映射器XML文件中添加:
<cache/>
可见二级缓存是Mapper级别的,也就是说,当一个会话失效时,它的缓存依然会存在于二级缓存中,因此如果我们再次创建一个新的会话会直接使用之前的缓存,我们首先根据官方文档进行一些配置:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
我们来编写一个代码:
public static void main(String[] args) {
Student student;
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
student = testMapper.getStudentBySid(1);
}
try (SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
Student student2 = testMapper2.getStudentBySid(1);
System.out.println(student2 == student);
}
}
我们可以看到,上面的代码中首先是第一个会话在进行读操作,完成后会结束会话,而第二个操作重新创建了一个新的会话,再次执行了同样的查询,我们发现得到的依然是缓存的结果。
那么如果我不希望某个方法开启缓存呢?我们可以添加useCache属性来关闭缓存:
<select id="getStudentBySid" resultType="Student" useCache="false">
select * from student where sid = #{sid}
</select>
我们也可以使用flushCache="false"在每次执行后都清空缓存,通过这这个我们还可以控制DML操作完成之后不清空缓存。
<select id="getStudentBySid" resultType="Student" flushCache="true">
select * from student where sid = #{sid}
</select>
添加了二级缓存之后,会先从二级缓存中查找数据,当二级缓存中没有时,才会从一级缓存中获取,当一级缓存中都还没有数据时,才会请求数据库,因此我们再来执行上面的代码:
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student2;
try(SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
student2 = testMapper2.getStudentBySid(1);
}
Student student1 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
得到的结果就会是同一个对象了,因为现在是优先从二级缓存中获取。
读取顺序:二级缓存 => 一级缓存 => 数据库

虽然缓存机制给我们提供了很大的性能提升,但是缓存存在一个问题,我们之前在计算机组成原理中可能学习过缓存一致性问题,也就是说当多个CPU在操作自己的缓存时,可能会出现各自的缓存内容不同步的问题,而Mybatis也会这样,我们来看看这个例子:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
while (true){
Thread.sleep(3000);
System.out.println(testMapper.getStudentBySid(1));
}
}
}
我们现在循环地每三秒读取一次,而在这个过程中,我们使用IDEA手动修改数据库中的数据,将1号同学的学号改成100,那么理想情况下,下一次读取将无法获取到小明,因为小明的学号已经发生变化了。
但是结果却是依然能够读取,并且sid并没有发生改变,这也证明了Mybatis的缓存在生效,因为我们是从外部进行修改,Mybatis不知道我们修改了数据,所以依然在使用缓存中的数据,但是这样很明显是不正确的。
因此,如果存在多台服务器或者是多个程序都在使用Mybatis操作同一个数据库,并且都开启了缓存,需要解决这个问题,要么就得关闭Mybatis的缓存来保证一致性:
<settings>
<setting name="cacheEnabled" value="false"/>
</settings>
<select id="getStudentBySid" resultType="Student" useCache="false" flushCache="true">
select * from student where sid = #{sid}
</select>
要么就需要实现缓存共用,也就是让所有的Mybatis都使用同一个缓存进行数据存取,在后面,我们会继续学习
Redis、Ehcache、Memcache等缓存框架,通过使用这些工具,就能够很好地解决缓存一致性问题。
使用注解开发
在之前的开发中,我们已经体验到Mybatis为我们带来的便捷了,我们只需要编写对应的映射器,并将其绑定到一个接口上,即可直接通过该接口执行我们的SQL语句,极大的简化了我们之前JDBC那样的代码编写模式。
那么,能否实现无需xml映射器配置,而是直接使用注解在接口上进行配置呢?
答案是可以的,也是现在推荐的一种方式(也不是说XML就不要去用了,由于Java 注解的表达能力和灵活性十分有限,可能相对于XML配置某些功能实现起来会不太好办,但是在大部分场景下,直接使用注解开发已经绰绰有余了)
首先我们来看一下,使用XML进行映射器编写时,我们需要现在XML中定义映射规则和SQL语句,然后再将其绑定到一个接口的方法定义上,然后再使用接口来执行:
<insert id="addStudent">
insert into student(name, sex) values(#{name}, #{sex})
</insert>
int addStudent(Student student);
而现在,我们可以直接使用注解来实现,每个操作都有一个对应的注解:
@Insert("insert into student(name, sex) values(#{name}, #{sex})")
int addStudent(Student student);
当然,我们还需要修改一下配置文件中的映射器注册:
<mappers>
<mapper class="com.test.mapper.MyMapper"/>
<!-- 也可以直接注册整个包下的 <package name="com.test.mapper"/> -->
</mappers>
通过直接指定Class,来让Mybatis知道我们这里有一个通过注解实现的映射器。
我们接着来看一下,如何使用注解进行自定义映射规则:
@Results({
@Result(id = true, column = "sid", property = "sid"),
@Result(column = "sex", property = "name"),
@Result(column = "name", property = "sex")
})
@Select("select * from student")
List<Student> getAllStudent();
直接通过@Results注解,就可以直接进行配置了,此注解的value是一个@Result注解数组,每个@Result注解都都一个单独的字段配置,其实就是我们之前在XML映射器中写的:
<resultMap id="test" type="Student">
<id property="sid" column="sid"/>
<result column="name" property="sex"/>
<result column="sex" property="name"/>
</resultMap>
现在我们就可以通过注解来自定义映射规则了。那么如何使用注解来完成复杂查询呢?我们还是使用一个老师多个学生的例子:
@Results({
@Result(id = true, column = "tid", property = "tid"),
@Result(column = "name", property = "name"),
@Result(column = "tid", property = "studentList", many =
@Many(select = "getStudentByTid")
)
})
@Select("select * from teacher where tid = #{tid}")
Teacher getTeacherBySid(int tid);
@Select("select * from student inner join teach on student.sid = teach.sid where tid = #{tid}")
List<Student> getStudentByTid(int tid);
我们发现,多出了一个子查询,而这个子查询是单独查询该老师所属学生的信息,而子查询结果作为@Result注解的一个many结果,代表子查询的所有结果都归入此集合中(也就是之前的collection标签)
<resultMap id="asTeacher" type="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
<collection property="studentList" ofType="Student">
<id property="sid" column="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
</collection>
</resultMap>
同理,@Result也提供了@One子注解来实现一对一的关系表示,类似于之前的assocation标签:
@Results({
@Result(id = true, column = "sid", property = "sid"),
@Result(column = "sex", property = "name"),
@Result(column = "name", property = "sex"),
@Result(column = "sid", property = "teacher", one =
@One(select = "getTeacherBySid")
)
})
@Select("select * from student")
List<Student> getAllStudent();
如果现在我希望直接使用注解编写SQL语句但是我希望映射规则依然使用XML来实现,这时该怎么办呢?
@ResultMap("test")
@Select("select * from student")
List<Student> getAllStudent();
提供了@ResultMap注解,直接指定ID即可,这样我们就可以使用XML中编写的映射规则了,这里就不再演示了。
那么如果出现之前的两个构造方法的情况,且没有任何一个构造方法匹配的话,该怎么处理呢?
@Data
@Accessors(chain = true)
public class Student {
public Student(int sid){
System.out.println("我是一号构造方法"+sid);
}
public Student(int sid, String name){
System.out.println("我是二号构造方法"+sid+name);
}
private int sid;
private String name;
private String sex;
}
我们可以通过@ConstructorArgs注解来指定构造方法:
@ConstructorArgs({
@Arg(column = "sid", javaType = int.class),
@Arg(column = "name", javaType = String.class)
})
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(@Param("sid") int sid, @Param("sex") String sex);
得到的结果和使用constructor标签效果一致,这里就不多做讲解了。
我们发现,当参数列表中出现两个以上的参数时,会出现错误:
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(int sid, String sex);
Exception in thread "main" org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.binding.BindingException: Parameter 'sid' not found. Available parameters are [arg1, arg0, param1, param2]
### Cause: org.apache.ibatis.binding.BindingException: Parameter 'sid' not found. Available parameters are [arg1, arg0, param1, param2]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:153)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:145)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:140)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectOne(DefaultSqlSession.java:76)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:87)
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy6.getStudentBySidAndSex(Unknown Source)
at com.test.Main.main(Main.java:16)
原因是Mybatis不明确到底哪个参数是什么,因此我们可以添加@Param来指定参数名称:
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(@Param("sid") int sid, @Param("sex") String sex);
探究:要是我两个参数一个是基本类型一个是对象类型呢?
System.out.println(testMapper.addStudent(100, new Student().setName("小陆").setSex("男")));
@Insert("insert into student(sid, name, sex) values(#{sid}, #{name}, #{sex})")
int addStudent(@Param("sid") int sid, @Param("student") Student student);
那么这个时候,就出现问题了,Mybatis就不能明确这些属性是从哪里来的:
### SQL: insert into student(sid, name, sex) values(?, ?, ?)
### Cause: org.apache.ibatis.binding.BindingException: Parameter 'name' not found. Available parameters are [student, param1, sid, param2]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.update(DefaultSqlSession.java:196)
at org.apache.ibatis.session.defaults.DefaultSqlSession.insert(DefaultSqlSession.java:181)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:62)
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy6.addStudent(Unknown Source)
at com.test.Main.main(Main.java:16)
那么我们就通过参数名称.属性的方式去让Mybatis知道我们要用的是哪个属性:
@Insert("insert into student(sid, name, sex) values(#{sid}, #{student.name}, #{student.sex})")
int addStudent(@Param("sid") int sid, @Param("student") Student student);
那么如何通过注解控制缓存机制呢?
@CacheNamespace(readWrite = false)
public interface MyMapper {
@Select("select * from student")
@Options(useCache = false)
List<Student> getAllStudent();
使用@CacheNamespace注解直接定义在接口上即可,然后我们可以通过使用@Options来控制单个操作的缓存启用。
探究Mybatis的动态代理机制
在探究动态代理机制之前,我们要先聊聊什么是代理:其实顾名思义,就好比我开了个大棚,里面栽种的西瓜,那么西瓜成熟了是不是得去卖掉赚钱,而我们的西瓜非常多,一个人肯定卖不过来,肯定就要去多找几个开水果摊的帮我们卖,这就是一种代理。实际上是由水果摊老板在帮我们卖瓜,我们只告诉老板卖多少钱,而至于怎么卖的是由水果摊老板决定的。

那么现在我们来尝试实现一下这样的类结构,首先定义一个接口用于规范行为:
public interface Shopper {
//卖瓜行为
void saleWatermelon(String customer);
}
然后需要实现一下卖瓜行为,也就是我们要告诉老板卖多少钱,这里就直接写成成功出售:
public class ShopperImpl implements Shopper{
//卖瓜行为的实现
@Override
public void saleWatermelon(String customer) {
System.out.println("成功出售西瓜给 ===> "+customer);
}
}
最后老板代理后肯定要用自己的方式去出售这些西瓜,成交之后再按照我们告诉老板的价格进行出售:
public class ShopperProxy implements Shopper{
private final Shopper impl;
public ShopperProxy(Shopper impl){
this.impl = impl;
}
//代理卖瓜行为
@Override
public void saleWatermelon(String customer) {
//首先进行 代理商讨价还价行为
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":给我挑一个。");
impl.saleWatermelon(customer); //讨价还价成功,进行我们告诉代理商的卖瓜行为
}
}
现在我们来试试看:
public class Main {
public static void main(String[] args) {
Shopper shopper = new ShopperProxy(new ShopperImpl());
shopper.saleWatermelon("小强");
}
}
这样的操作称为静态代理,也就是说我们需要提前知道接口的定义并进行实现才可以完成代理,而Mybatis这样的是无法预知代理接口的,我们就需要用到动态代理。
JDK提供的反射框架就为我们很好地解决了动态代理的问题,在这里相当于对JavaSE阶段反射的内容进行一个补充。
public class ShopperProxy implements InvocationHandler {
Object target;
public ShopperProxy(Object target){
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String customer = (String) args[0];
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":行,给我挑一个。");
return method.invoke(target, args);
}
}
通过实现InvocationHandler来成为一个动态代理,我们发现它提供了一个invoke方法,用于调用被代理对象的方法并完成我们的代理工作。现在就可以通过 Proxy.newProxyInstance来生成一个动态代理类:
public static void main(String[] args) {
Shopper impl = new ShopperImpl();
Shopper shopper = (Shopper) Proxy.newProxyInstance(impl.getClass().getClassLoader(),
impl.getClass().getInterfaces(), new ShopperProxy(impl));
shopper.saleWatermelon("小强");
System.out.println(shopper.getClass());
}
通过打印类型我们发现,就是我们之前看到的那种奇怪的类:class com.sun.proxy.$Proxy0,因此Mybatis其实也是这样的来实现的(肯定有人问了:Mybatis是直接代理接口啊,你这个不还是要把接口实现了吗?)那我们来改改,现在我们不代理任何类了,直接做接口实现:
public class ShopperProxy implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String customer = (String) args[0];
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":行,给我挑一个。");
return null;
}
}
public static void main(String[] args) {
Shopper shopper = (Shopper) Proxy.newProxyInstance(Shopper.class.getClassLoader(),
new Class[]{ Shopper.class }, //因为本身就是接口,所以直接用就行
new ShopperProxy());
shopper.saleWatermelon("小强");
System.out.println(shopper.getClass());
}
我Mybatis属于半自动框架,SQL语句依然需要我们自己编写,虽然存在一定的麻烦,但是会更加灵活,而后面我们还会学***A,它是全自动的框架,你几乎见不到SQL的影子!
使用JUnit进行单元测试
首先一问:我们为什么需要单元测试?
随着我们的项目逐渐变大,我们都是边在写边在测试,而我们当时使用的测试方法,就是直接在主方法中运行测试。
但是,在很多情况下,我们的项目可能会很庞大,不可能每次都去完整地启动一个项目来测试某一个功能,这样显然会降低我们的开发效率。
因此,我们需要使用单元测试来帮助我们针对于某个功能或是某个模块单独运行代码进行测试,而不是启动整个项目。
同时,在我们项目的维护过程中,难免会涉及到一些原有代码的修改,很有可能出现改了代码导致之前的功能出现问题(牵一发而动全身),而我们又不一定能立即察觉到。
因此,我们可以提前保存一些测试用例,每次完成代码后都可以跑一遍测试用例,来确保之前的功能没有因为后续的修改而出现问题。
我们还可以利用单元测试来评估某个模块或是功能的耗时和性能,快速排查导致程序运行缓慢的问题,这些都可以通过单元测试来完成,可见单元测试对于开发的重要性。
尝试JUnit
首先需要导入JUnit依赖,我们在这里使用Junit4进行介绍,最新的Junit5放到Maven板块一起讲解,Jar包已经放在视频下方简介中,直接去下载即可。同时IDEA需要安装JUnit插件(默认是已经捆绑安装的,因此无需多余配置)
现在我们创建一个新的类,来编写我们的单元测试用例:
public class TestMain {
@Test
public void method(){
System.out.println("我是测试用例1");
}
@Test
public void method2(){
System.out.println("我是测试用例2");
}
}
我们可以点击类前面的测试按钮,或是单个方法前的测试按钮,如果点击类前面的测试按钮,会执行所有的测试用例。
运行测试后,我们发现控制台得到了一个测试结果,显示为绿色表示测试通过。
只需要通过打上@Test注解,即可将一个方法标记为测试案例,我们可以直接运行此测试案例,但是我们编写的测试方法有以下要求:
- 方法必须是public的
- 不能是静态方法
- 返回值必须是void
- 必须是没有任何参数的方法
对于一个测试案例来说,我们肯定希望测试的结果是我们所期望的一个值,因此,如果测试的结果并不是我们所期望的结果,那么这个测试就应该没有成功通过!
我们可以通过断言工具类来进行判定:
public class TestMain {
@Test
public void method(){
System.out.println("我是测试案例!");
Assert.assertEquals(1, 2); //参数1是期盼值,参数2是实际测试结果值
}
}
通过运行代码后,我们发现测试过程中抛出了一个错误,并且IDEA给我们显示了期盼结果和测试结果,那么现在我们来测试一个案例,比如我们想查看冒泡排序的编写是否正确:
@Test
public void method(){
int[] arr = {0, 4, 5, 2, 6, 9, 3, 1, 7, 8};
//错误的冒泡排序
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if(arr[j] > arr[j + 1]){
int tmp = arr[j];
arr[j] = arr[j+1];
// arr[j+1] = tmp;
}
}
}
Assert.assertArrayEquals(new int[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, arr);
}
通过测试,我们发现得到的结果并不是我们想要的结果,因此现在我们需要去修改为正确的冒泡排序,修改后,测试就能正确通过了。我们还可以再通过一个案例来更加深入地了解测试,现在我们想测试从数据库中取数据是否为我们预期的数据:
@Test
public void method(){
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
Student student = mapper.getStudentBySidAndSex(1, "男");
Assert.assertEquals(new Student().setName("小明").setSex("男").setSid(1), student);
}
}
那么如果我们在进行所有的测试之前需要做一些前置操作该怎么办呢,一种办法是在所有的测试用例前面都加上前置操作,但是这样显然是很冗余的,因为一旦发生修改就需要挨个进行修改,因此我们需要更加智能的方法,我们可以通过@Before注解来添加测试用例开始之前的前置操作:
public class TestMain {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before(){
System.out.println("测试前置正在初始化...");
try {
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
System.out.println("测试初始化完成,正在开始测试案例...");
}
@Test
public void method1(){
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
Student student = mapper.getStudentBySidAndSex(1, "男");
Assert.assertEquals(new Student().setName("小明").setSex("男").setSid(1), student);
System.out.println("测试用例1通过!");
}
}
@Test
public void method2(){
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
Student student = mapper.getStudentBySidAndSex(2, "女");
Assert.assertEquals(new Student().setName("小红").setSex("女").setSid(2), student);
System.out.println("测试用例2通过!");
}
}
}
同理,在所有的测试完成之后,我们还想添加一个收尾的动作,那么只需要使用@After注解即可添加结束动作:
@After
public void after(){
System.out.println("测试结束,收尾工作正在进行...");
}
JUL日志系统
首先一问:我们为什么需要日志系统?
我们之前一直都在使用System.out.println来打印信息,但是,如果项目中存在大量的控制台输出语句,会显得很凌乱,而且日志的粒度是不够细的,假如我们现在希望,项目只在debug的情况下打印某些日志,而在实际运行时不打印日志,采用直接输出的方式就很难实现了,因此我们需要使用日志框架来规范化日志输出。
而JDK为我们提供了一个自带的日志框架,位于java.util.logging包下,我们可以使用此框架来实现日志的规范化打印,使用起来非常简单:
public class Main {
public static void main(String[] args) {
// 首先获取日志打印器
Logger logger = Logger.getLogger(Main.class.getName());
// 调用info来输出一个普通的信息,直接填写字符串即可
logger.info("我是普通的日志");
}
}
我们可以在主类中使用日志打印,得到日志的打印结果:
十一月 15, 2021 12:55:37 下午 com.test.Main main
信息: 我是普通的日志
我们发现,通过日志输出的结果会更加规范。
JUL日志讲解
日志分为7个级别,详细信息我们可以在Level类中查看:
- SEVERE(最高值)- 一般用于代表严重错误
- WARNING - 一般用于表示某些警告,但是不足以判断为错误
- INFO (默认级别) - 常规消息
- CONFIG
- FINE
- FINER
- FINEST(最低值)
我们之前通过info方法直接输出的结果就是使用的默认级别的日志,我们可以通过log方法来设定该条日志的输出级别:
public static void main(String[] args) {
Logger logger = Logger.getLogger(Main.class.getName());
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
logger.log(Level.CONFIG, "级别低于普通信息");
}
我们发现,级别低于默认级别的日志信息,无法输出到控制台,我们可以通过设置来修改日志的打印级别:
public static void main(String[] args) {
Logger logger = Logger.getLogger(Main.class.getName());
//修改日志级别
logger.setLevel(Level.CONFIG);
//不使用父日志处理器
logger.setUseParentHandlers(false);
//使用自定义日志处理器
ConsoleHandler handler = new ConsoleHandler();
handler.setLevel(Level.CONFIG);
logger.addHandler(handler);
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
logger.log(Level.CONFIG, "级别低于普通信息");
}
每个Logger都有一个父日志打印器,我们可以通过getParent()来获取:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
System.out.println(logger.getParent().getClass());
}
我们发现,得到的是java.util.logging.LogManager$RootLogger这个类,它默认使用的是ConsoleHandler,且日志级别为INFO,由于每一个日志打印器都会直接使用父类的处理器,因此我们之前需要关闭父类然后使用我们自己的处理器。
我们通过使用自己日志处理器来自定义级别的信息打印到控制台,当然,日志处理器不仅仅只有控制台打印,我们也可以使用文件处理器来处理日志信息,我们继续添加一个处理器:
//添加输出到本地文件
FileHandler fileHandler = new FileHandler("test.log");
fileHandler.setLevel(Level.WARNING);
logger.addHandler(fileHandler);
注意,这个时候就有两个日志处理器了,因此控制台和文件的都会生效。如果日志的打印格式我们不喜欢,我们还可以自定义打印格式,比如我们控制台处理器就默认使用的是SimpleFormatter,而文件处理器则是使用的XMLFormatter,我们可以自定义:
//使用自定义日志处理器(控制台)
ConsoleHandler handler = new ConsoleHandler();
handler.setLevel(Level.CONFIG);
handler.setFormatter(new XMLFormatter());
logger.addHandler(handler);
我们可以直接配置为想要的打印格式,如果这些格式还不能满足你,那么我们也可以自行实现:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
logger.setUseParentHandlers(false);
//为了让颜色变回普通的颜色,通过代码块在初始化时将输出流设定为System.out
ConsoleHandler handler = new ConsoleHandler(){{
setOutputStream(System.out);
}};
//创建匿名内部类实现自定义的格式
handler.setFormatter(new Formatter() {
@Override
public String format(LogRecord record) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String time = format.format(new Date(record.getMillis())); //格式化日志时间
String level = record.getLevel().getName(); // 获取日志级别名称
// String level = record.getLevel().getLocalizedName(); // 获取本地化名称(语言跟随系统)
String thread = String.format("%10s", Thread.currentThread().getName()); //线程名称(做了格式化处理,留出10格空间)
long threadID = record.getThreadID(); //线程ID
String className = String.format("%-20s", record.getSourceClassName()); //发送日志的类名
String msg = record.getMessage(); //日志消息
//\033[33m作为颜色代码,30~37都有对应的颜色,38是没有颜色,IDEA能显示,但是某些地方可能不支持
return "\033[38m" + time + " \033[33m" + level + " \033[35m" + threadID
+ "\033[38m --- [" + thread + "] \033[36m" + className + "\033[38m : " + msg + "\n";
}
});
logger.addHandler(handler);
logger.info("我是测试消息1...");
logger.log(Level.INFO, "我是测试消息2...");
logger.log(Level.WARNING, "我是测试消息3...");
}
日志可以设置过滤器,如果我们不希望某些日志信息被输出,我们可以配置过滤规则:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
//自定义过滤规则
logger.setFilter(record -> !record.getMessage().contains("普通"));
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
}
实际上,整个日志的输出流程如下:

Properties配置文件
Properties文件是Java的一种配置文件,我们之前学习了XML,但是我们发现XML配置文件读取实在是太麻烦,那么能否有一种简单一点的配置文件呢?我们可以使用Properties文件:
name=Test
desc=Description
该文件配置很简单,格式为配置项=配置值,我们可以直接通过Properties类来将其读取为一个类似于Map一样的对象:
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.load(new FileInputStream("test.properties"));
System.out.println(properties);
}
我们发现,Properties类是继承自Hashtable,而Hashtable是实现的Map接口,也就是说,Properties本质上就是一个Map一样的结构,它会把所有的配置项映射为一个Map,这样我们就可以快速地读取对应配置的值了。
我们也可以将已经存在的Properties对象放入输出流进行保存,我们这里就不保存文件了,而是直接打印到控制台,我们只需要提供输出流即可:
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
// properties.setProperty("test", "lbwnb"); //和put效果一样
properties.put("test", "lbwnb");
properties.store(System.out, "????");
//properties.storeToXML(System.out, "????"); 保存为XML格式
}
我们可以通过System.getProperties()获取系统的参数,我们来看看:
public static void main(String[] args) throws IOException {
System.getProperties().store(System.out, "系统信息:");
}
编写日志配置文件
我们可以通过进行配置文件来规定日志打印器的一些默认值:
# RootLogger 的默认处理器为
handlers= java.util.logging.ConsoleHandler
# RootLogger 的默认的日志级别
.level= CONFIG
我们来尝试使用配置文件来进行配置:
public static void main(String[] args) throws IOException {
//获取日志管理器
LogManager manager = LogManager.getLogManager();
//读取我们自己的配置文件
manager.readConfiguration(new FileInputStream("logging.properties"));
//再获取日志打印器
Logger logger = Logger.getLogger(Main.class.getName());
logger.log(Level.CONFIG, "我是一条日志信息"); //通过自定义配置文件,我们发现默认级别不再是INFO了
}
我们也可以去修改ConsoleHandler的默认配置:
# 指定默认日志级别
java.util.logging.ConsoleHandler.level = ALL
# 指定默认日志消息格式
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
# 指定默认的字符集
java.util.logging.ConsoleHandler.encoding = UTF-8
其实,我们阅读ConsoleHandler的源码就会发现,它就是通过读取配置文件来进行某些参数设置:
// Private method to configure a ConsoleHandler from LogManager
// properties and/or default values as specified in the class
// javadoc.
private void configure() {
LogManager manager = LogManager.getLogManager();
String cname = getClass().getName();
setLevel(manager.getLevelProperty(cname +".level", Level.INFO));
setFilter(manager.getFilterProperty(cname +".filter", null));
setFormatter(manager.getFormatterProperty(cname +".formatter", new SimpleFormatter()));
try {
setEncoding(manager.getStringProperty(cname +".encoding", null));
} catch (Exception ex) {
try {
setEncoding(null);
} catch (Exception ex2) {
// doing a setEncoding with null should always work.
// assert false;
}
}
}
使用Lombok快速开启日志
我们发现,如果我们现在需要全面使用日志系统,而不是传统的直接打印,那么就需要在每个类都去编写获取Logger的代码,这样显然是很冗余的,能否简化一下这个流程呢?
前面我们学习了Lombok,我们也体会到Lombok给我们带来的便捷,我们可以通过一个注解快速生成构造方法、Getter和Setter,同样的,Logger也是可以使用Lombok快速生成的。
@Log
public class Main {
public static void main(String[] args) {
System.out.println("自动生成的Logger名称:"+log.getName());
log.info("我是日志信息");
}
}
只需要添加一个@Log注解即可,添加后,我们可以直接使用一个静态变量log,而它就是自动生成的Logger。我们也可以手动指定名称:
@Log(topic = "打工是不可能打工的")
public class Main {
public static void main(String[] args) {
System.out.println("自动生成的Logger名称:"+log.getName());
log.info("我是日志信息");
}
}
Mybatis日志系统
Mybatis也有日志系统,它详细记录了所有的数据库操作等,但是我们在前面的学习中没有开启它,现在我们学习了日志之后,我们就可以尝试开启Mybatis的日志系统,来监控所有的数据库操作,要开启日志系统,我们需要进行配置:
<setting name="logImpl" value="STDOUT_LOGGING" />
logImpl包括很多种配置项,包括 SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING,而默认情况下是未配置,也就是说不打印。我们这里将其设定为STDOUT_LOGGING表示直接使用标准输出将日志信息打印到控制台,我们编写一个测试案例来看看效果:
public class TestMain {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before(){
try {
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
@Test
public void test(){
try(SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
System.out.println(mapper.getStudentBySidAndSex(1, "男"));
System.out.println(mapper.getStudentBySidAndSex(1, "男"));
}
}
}
我们发现,两次获取学生信息,只有第一次打开了数据库连接,而第二次并没有。
现在我们学习了日志系统,那么我们来尝试使用日志系统输出Mybatis的日志信息:
<setting name="logImpl" value="JDK_LOGGING" />
将其配置为JDK_LOGGING表示使用JUL进行日志打印,因为Mybatis的日志级别都比较低,因此我们需要设置一下logging.properties默认的日志级别:
handlers= java.util.logging.ConsoleHandler
.level= ALL
java.util.logging.ConsoleHandler.level = ALL
代码编写如下:
@Log
public class TestMain {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before(){
try {
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"));
LogManager manager = LogManager.getLogManager();
manager.readConfiguration(new FileInputStream("logging.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void test(){
try(SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
log.info(mapper.getStudentBySidAndSex(1, "男").toString());
log.info(mapper.getStudentBySidAndSex(1, "男").toString());
}
}
}
但是我们发现,这样的日志信息根本没法看,因此我们需要修改一下日志的打印格式,我们自己创建一个格式化类:
public class TestFormatter extends Formatter {
@Override
public String format(LogRecord record) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String time = format.format(new Date(record.getMillis())); //格式化日志时间
return time + " : " + record.getMessage() + "\n";
}
}
现在再来修改一下默认的格式化实现:
handlers= java.util.logging.ConsoleHandler
.level= ALL
java.util.logging.ConsoleHandler.level = ALL
java.util.logging.ConsoleHandler.formatter = com.test.TestFormatter
现在就好看多了,当然,我们还可以继续为Mybatis添加文件日志,这里就不做演示了。
使用Maven管理项目
Maven 翻译为"专家"、"内行",是 Apache 下的一个纯 Java 开发的开源项目。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。Maven 也可被用于构建和管理各种项目,例如 C#,Ruby,Scala 和其他语言编写的项目。Maven 曾是 Jakarta 项目的子项目,现为由 Apache 软件基金会主持的独立 Apache 项目。
通过Maven,可以帮助我们做:
- 项目的自动构建,包括代码的编译、测试、打包、安装、部署等操作。
- 依赖管理,项目使用到哪些依赖,可以快速完成导入。
我们之前并没有讲解如何将我们的项目打包为Jar文件运行,同时,我们导入依赖的时候,每次都要去下载对应的Jar包,这样其实是很麻烦的,并且还有可能一个Jar包依赖于另一个Jar包,就像之前使用JUnit一样,因此我们需要一个更加方便的包管理机制。
Maven也需要安装环境,但是IDEA已经自带了Maven环境,因此我们不需要再去进行额外的环境安装(无IDEA也能使用Maven,但是配置过程很麻烦,并且我们现在使用的都是IDEA的集成开发环境,所以这里就不讲解Maven命令行操作了)我们直接创建一个新的Maven项目即可。
Maven项目结构
我们可以来看一下,一个Maven项目和我们普通的项目有什么区别:

那么首先,我们需要了解一下POM文件,它相当于是我们整个Maven项目的配置文件,它也是使用XML编写的:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>MavenTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
我们可以看到,Maven的配置文件是以project为根节点,而modelVersion定义了当前模型的版本,一般是4.0.0,我们不用去修改。
groupId、artifactId、version这三个元素合在一起,用于唯一区别每个项目,别人如果需要将我们编写的代码作为依赖,那么就必须通过这三个元素来定位我们的项目,我们称为一个项目的基本坐标,所有的项目一般都有自己的Maven坐标,因此我们通过Maven导入其他的依赖只需要填写这三个基本元素就可以了,无需再下载Jar文件,而是Maven自动帮助我们下载依赖并导入。
groupId一般用于指定组名称,命名规则一般和包名一致,比如我们这里使用的是org.example,一个组下面可以有很多个项目。artifactId一般用于指定项目在当前组中的唯一名称,也就是说在组中用于区分于其他项目的标记。version代表项目版本,随着我们项目的开发和改进,版本号也会不断更新,就像LOL一样,每次赛季更新都会有一个大版本更新,我们的Maven项目也是这样,我们可以手动指定当前项目的版本号,其他人使用我们的项目作为依赖时,也可以根本版本号进行选择(这里的SNAPSHOT代表快照,一般表示这是一个处于开发中的项目,正式发布项目一般只带版本号)
properties中一般都是一些变量和选项的配置,我们这里指定了JDK的源代码和编译版本为1.8,无需进行修改。
Maven依赖导入
现在我们尝试使用Maven来帮助我们快速导入依赖,我们需要导入之前的JDBC驱动依赖、JUnit依赖、Mybatis依赖、Lombok依赖,那么如何使用Maven来管理依赖呢?
我们可以创建一个dependencies节点:
<dependencies>
//里面填写的就是所有的依赖
</dependencies>
那么现在就可以向节点中填写依赖了,那么我们如何知道每个依赖的坐标呢?我们可以在:https://mvnrepository.com/ 进行查询(可能打不开,建议用流量,或是直接百度某个项目的Maven依赖),我们直接搜索lombok即可,打开后可以看到已经给我们写出了依赖的坐标:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
我们直接将其添加到dependencies节点中即可,现在我们来编写一个测试用例看看依赖导入成功了没有:
public class Main {
public static void main(String[] args) {
Student student = new Student("小明", 18);
System.out.println(student);
}
}
@Data
@AllArgsConstructor
public class Student {
String name;
int age;
}
项目运行成功,表示成功导入了依赖。那么,Maven是如何进行依赖管理呢,以致于如此便捷的导入依赖,我们来看看Maven项目的依赖管理流程:

通过流程图我们得知,一个项目依赖一般是存储在中央仓库中,也有可能存储在一些其他的远程仓库(私服),几乎所有的依赖都被放到了中央仓库中,因此,Maven可以直接从中央仓库中下载大部分的依赖(Maven第一次导入依赖是需要联网的),远程仓库中下载之后 ,会暂时存储在本地仓库,我们会发现我们本地存在一个.m2文件夹,这就是Maven本地仓库文件夹,默认建立在C盘,如果你C盘空间不足,会出现问题!
在下次导入依赖时,如果Maven发现本地仓库中就已经存在某个依赖,那么就不会再去远程仓库下载了。
可能在导入依赖时,小小伙伴们会出现卡顿的问题,我们建议配置一下IDEA自带的Maven插件远程仓库地址,我们打开IDEA的安装目录,找到安装根目录/plugins/maven/lib/maven3/conf文件夹,找到settings.xml文件,打开编辑:
找到mirros标签,添加以下内容:
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
这样,我们就将默认的远程仓库地址(国外),配置为国内的阿里云仓库地址了(依赖的下载速度就会快起来了)
Maven依赖作用域
除了三个基本的属性用于定位坐标外,依赖还可以添加以下属性:
- type:依赖的类型,对于项目坐标定义的packaging。大部分情况下,该元素不必声明,其默认值为jar
- scope:依赖的范围(作用域,着重讲解)
- optional:标记依赖是否可选
- exclusions:用来排除传递性依赖(一个项目有可能依赖于其他项目,就像我们的项目,如果别人要用我们的项目作为依赖,那么就需要一起下载我们项目的依赖,如Lombok)
我们着重来讲解一下scope属性,它决定了依赖的作用域范围:
- compile :为默认的依赖有效范围。如果在定义依赖关系的时候,没有明确指定依赖有效范围的话,则默认采用该依赖有效范围。此种依赖,在编译、运行、测试时均有效。
- provided :在编译、测试时有效,但是在运行时无效,也就是说,项目在运行时,不需要此依赖,比如我们上面的Lombok,我们只需要在编译阶段使用它,编译完成后,实际上已经转换为对应的代码了,因此Lombok不需要在项目运行时也存在。
- runtime :在运行、测试时有效,但是在编译代码时无效。比如我们如果需要自己写一个JDBC实现,那么肯定要用到JDK为我们指定的接口,但是实际上在运行时是不用自带JDK的依赖,因此只保留我们自己写的内容即可。
- test :只在测试时有效,例如:JUnit,我们一般只会在测试阶段使用JUnit,而实际项目运行时,我们就用不到测试了,那么我们来看看,导入JUnit的依赖:
同样的,我们可以在网站上搜索Junit的依赖,我们这里导入最新的JUnit5作为依赖:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.8.1</version>
<scope>test</scope>
</dependency>
我们所有的测试用例全部编写到Maven项目给我们划分的test目录下,位于此目录下的内容不会在最后被打包到项目中,只用作开发阶段测试使用:
public class MainTest {
@Test
public void test(){
System.out.println("测试");
//Assert在JUnit5时名称发生了变化Assertions
Assertions.assertArrayEquals(new int[]{1, 2, 3}, new int[]{1, 2});
}
}
因此,一般仅用作测试的依赖如JUnit只保留在测试中即可,那么现在我们再来添加JDBC和Mybatis的依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
我们发现,Maven还给我们提供了一个resource文件夹,我们可以将一些静态资源,比如配置文件,放入到这个文件夹中,项目在打包时会将资源文件夹中文件一起打包的Jar中,比如我们在这里编写一个Mybatis的配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="cacheEnabled" value="true"/>
<setting name="logImpl" value="JDK_LOGGING" />
</settings>
<!-- 需要在environments的上方 -->
<typeAliases>
<package name="com.test.entity"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/study"/>
<property name="username" value="test"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper class="com.test.mapper.TestMapper"/>
</mappers>
</configuration>
现在我们创建一下测试用例,顺便带大家了解一下Junit5的一些比较方便的地方:
public class MainTest {
//因为配置文件位于内部,我们需要使用Resources类的getResourceAsStream来获取内部的资源文件
private static SqlSessionFactory factory;
//在JUnit5中@Before被废弃,它被细分了:
@BeforeAll // 一次性开启所有测试案例只会执行一次 (方法必须是static)
// @BeforeEach 一次性开启所有测试案例每个案例开始之前都会执行一次
@SneakyThrows
public static void before(){
factory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream("mybatis.xml"));
}
@DisplayName("Mybatis数据库测试") //自定义测试名称
@RepeatedTest(3) //自动执行多次测试
public void test(){
try (SqlSession sqlSession = factory.openSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
System.out.println(testMapper.getStudentBySid(1));
}
}
}
那么就有人提问了,如果我需要的依赖没有上传的远程仓库,而是只有一个Jar怎么办呢?我们可以使用第四种作用域:
- system:作用域和provided是一样的,但是它不是从远程仓库获取,而是直接导入本地Jar包:
<dependency>
<groupId>javax.jntm</groupId>
<artifactId>lbwnb</artifactId>
<version>2.0</version>
<scope>system</scope>
<systemPath>C://学习资料/4K高清无码/test.jar</systemPath>
</dependency>
比如上面的例子,如果scope为system,那么我们需要添加一个systemPath来指定jar文件的位置,这里就不再演示了。
Maven可选依赖
当项目中的某些依赖不希望被使用此项目作为依赖的项目使用时,我们可以给依赖添加optional标签表示此依赖是可选的,默认在导入依赖时,不会导入可选的依赖:
<optional>true</optional>
比如Mybatis的POM文件中,就存在大量的可选依赖:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<optional>true</optional>
</dependency>
...
由于Mybatis要支持多种类型的日志,需要用到很多种不同的日志框架,因此需要导入这些依赖来做兼容,但是我们项目中并不一定会使用这些日志框架作为Mybatis的日志打印器,因此这些日志框架仅Mybatis内部做兼容需要导入使用,而我们可以选择不使用这些框架或是选择其中一个即可,也就是说我们导入Mybatis之后想用什么日志框架再自己加就可以了。
Maven排除依赖
我们了解了可选依赖,现在我们可以让使用此项目作为依赖的项目默认不使用可选依赖,但是如果存在那种不是可选依赖,但是我们导入此项目有不希望使用此依赖该怎么办呢,这个时候我们就可以通过排除依赖来防止添加不必要的依赖:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.8.1</version>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
我们这里演示了排除JUnit的一些依赖,我们可以在外部库中观察排除依赖之后和之前的效果。
Maven继承关系
一个Maven项目可以继承自另一个Maven项目,比如多个子项目都需要父项目的依赖,我们就可以使用继承关系来快速配置。
我们右键左侧栏,新建一个模块,来创建一个子项目:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>MavenTest</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>ChildModel</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
我们可以看到,IDEA默认给我们添加了一个parent节点,表示此Maven项目是父Maven项目的子项目,子项目直接继承父项目的groupId,子项目会直接继承父项目的所有依赖,除非依赖添加了optional标签,我们来编写一个测试用例尝试一下:
import lombok.extern.java.Log;
@Log
public class Main {
public static void main(String[] args) {
log.info("我是日志信息");
}
}
可以看到,子项目也成功继承了Lombok依赖。
我们还可以让父Maven项目统一管理所有的依赖,包括版本号等,子项目可以选取需要的作为依赖,而版本全由父项目管理,我们可以将dependencies全部放入dependencyManagement节点,这样父项目就完全作为依赖统一管理。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
</dependencyManagement>
我们发现,子项目的依赖失效了,因为现在父项目没有依赖,而是将所有的依赖进行集中管理,子项目需要什么再拿什么即可,同时子项目无需指定版本,所有的版本全部由父项目决定,子项目只需要使用即可:
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
当然,父项目如果还存在dependencies节点的话,里面的内依赖依然是直接继承:
<dependencies>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
...
Maven常用命令
我们可以看到在IDEA右上角Maven板块中,每个Maven项目都有一个生命周期,实际上这些是Maven的一些插件,每个插件都有各自的功能,比如:
clean命令,执行后会清理整个target文件夹,在之后编写Springboot项目时可以解决一些缓存没更新的问题。validate命令可以验证项目的可用性。compile命令可以将项目编译为.class文件。install命令可以将当前项目安装到本地仓库,以供其他项目导入作为依赖使用verify命令可以按顺序执行每个默认生命周期阶段(validate,compile,package等)
Maven测试项目
通过使用test命令,可以一键测试所有位于test目录下的测试案例,请注意有以下要求:
- 测试类的名称必须是以
Test结尾,比如MainTest - 测试方法上必须标注
@Test注解,实测@RepeatedTest无效
这是由于JUnit5比较新,我们需要重新配置插件升级到高版本,才能完美的兼容Junit5:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<!-- JUnit 5 requires Surefire version 2.22.0 or higher -->
<version>2.22.0</version>
</plugin>
</plugins>
</build>
现在@RepeatedTest、@BeforeAll也能使用了。
Maven打包项目
我们的项目在编写完成之后,要么作为Jar依赖,供其他模型使用,要么就作为一个可以执行的程序,在控制台运行,我们只需要直接执行package命令就可以直接对项目的代码进行打包,生成jar文件。
当然,以上方式仅适用于作为Jar依赖的情况,如果我们需要打包一个可执行文件,那么我不仅需要将自己编写的类打包到Jar中,同时还需要将依赖也一并打包到Jar中,因为我们使用了别人为我们通过的框架,自然也需要运行别人的代码,我们需要使用另一个插件来实现一起打包:
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.test.Main</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
在打包之前也会执行一次test命令,来保证项目能够正常运行,当测试出现问题时,打包将无法完成,我们也可以手动跳过,选择执行Maven目标来手动执行Maven命令,输入mvn package -Dmaven.test.skip=true 来以跳过测试的方式进行打包。
最后得到我们的Jar文件,在同级目录下输入java -jar xxxx.jar来运行我们打包好的Jar可执行程序(xxx代表文件名称)
deploy命令用于发布项目到本地仓库和远程仓库,一般情况下用不到,这里就不做讲解了。site命令用于生成当前项目的发布站点,暂时不需要了解。
我们之前还讲解了多模块项目,那么多模块下父项目存在一个packing打包类型标签,所有的父级项目的packing都为pom,packing默认是jar类型,如果不作配置,maven会将该项目打成jar包。作为父级项目,还有一个重要的属性,那就是modules,通过modules标签将项目的所有子项目引用进来,在build父级项目时,会根据子模块的相互依赖关系整理一个build顺序,然后依次build。
JavaWeb后端
我们学习JavaWeb的最终目的是为了搭建一个网站,并且让用户能访问我们的网站并在我们的网站上做一些事情。
计算机网络基础
在计算机网络(谢希仁 第七版 第264页)中,是这样描述万维网的:
万维网(World Wide Web)并非是某种特殊的计算机网络,万维网是一个大规模的联机式信息储藏所,英文简称
Web,万维网用链接的方法,能够非常方便地从互联网上的一个站点访问另一个站点,从而主动地按需求获取丰富的信息。
这句话说的非常官方,但是也蕴藏着许多的信息,首先它指明,我们的互联网上存在许许多多的服务器,而我们通过访问这些服务器就能快速获取服务器为我们提供的信息(比如打开百度就能展示搜索、打开小破站能刷视频、打开微博能查看实时热点)而这些服务器就是由不同的公司在运营。
其次,我们通过浏览器,只需要输入对应的网址或是点击页面中的一个链接,就能够快速地跳转到另一个页面,从而按我们的意愿来访问服务器。
而书中是这样描述万维网的工作方式:
万维网以客户服务器的方式工作,浏览器就是安装在用户主机上的万维网客户程序,万维网文档所驻留的主机则运行服务器程序,因此这台主机也称为万维网服务器。客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所要的万维网文档,在一个客户程序主窗口上显示出的万维网文档称为页面。
上面提到的客户程序其实就是我们电脑上安装的浏览器,而服务端就是我们即将要去学习的Web服务器,也就是说,我们要明白如何搭建一个Web服务器并向用户发送我们提供的Web页面,在浏览器中显示的,一般就是HTML文档被解析后的样子。
那么,我们的服务器可能不止一个页面,可能会有很多个页面,那么客户端如何知道该去访问哪个服务器的哪个页面呢?这个时候就需要用到URL统一资源定位符。互联网上所有的资源,都有一个唯一确定的URL,比如http://www.baidu.com
URL的格式为:
<协议>://<主机>:<端口>/<路径>
协议是指采用什么协议来访问服务器,不同的协议决定了服务器返回信息的格式,我们一般使用HTTP协议。
主机可以是一个域名,也可以是一个IP地址(实际上域名最后会被解析为IP地址进行访问)
端口是当前服务器上Web应用程序开启的端口,我们前面学习TCP通信的时候已经介绍过了,HTTP协议默认使用80端口,因此有时候可以省略。
路径就是我们希望去访问此服务器上的某个文件,不同的路径代表访问不同的资源。
我们接着来了解一下什么是HTTP协议:
HTTP是面向事务的应用层协议,它是万维网上能够可靠交换文件的重要基础。HTTP不仅传送完成超文本跳转所需的必须信息,而且也传送任何可从互联网上得到的信息,如文本、超文本、声音和图像。
实际上我们之前访问百度、访问自己的网站,所有的传输都是以HTTP作为协议进行的。
我们来看看HTTP的传输原理:
HTTP使用了面向连接的TCP作为运输层协议,保证了数据的可靠传输。HTTP不必考虑数据在传输过程中被丢弃后又怎样被重传。但是HTTP协议本身是无连接的。也就是说,HTTP虽然使用了TCP连接,但是通信的双方在交换HTTP报文之前不需要先建立HTTP连接。1997年以前使用的是HTTP/1.0协议,之后就是HTTP/1.1协议了。
那么既然HTTP是基于TCP进行通信的,我们首先来回顾一下TCP的通信原理:

TCP协议实际上是经历了三次握手再进行通信,也就是说保证整个通信是稳定的,才可以进行数据交换,并且在连接已经建立的过程中,双方随时可以互相发送数据,直到有一方主动关闭连接,这时在进行四次挥手,完成整个TCP通信。
而HTTP和TCP并不是一个层次的通信协议,TCP是传输层协议,而HTTP是应用层协议,因此,实际上HTTP的内容会作为TCP协议的报文被封装,并继续向下一层进行传递,而传输到客户端时,会依次进行解包,还原为最开始的HTTP数据。

HTTP使用TCP协议是为了使得数据传输更加可靠,既然它是依靠TCP协议进行数据传输,那么为什么说它本身是无连接的呢?我们来看一下HTTP的传输过程:
用户在点击鼠标链接某个万维网文档时,HTTP协议首先要和服务器建立TCP连接。这需要使用三报文握手。当建立TCP连接的三报文握手的前两部分完成后(即经过了一个RTT时间后),万维网客户就把HTTP请求报文作为建立TCP连接的三报文握手中的第三个报文的数据,发送给万维网服务器。服务器收到HTTP请求报文后,就把所请求的文档作为响应报文返回给客户。

因此,我们的浏览器请求一个页面,需要两倍的往返时间。
最后,我们再来了解一下HTTP的报文结构:

由客户端向服务端发送是报文称为请求报文,而服务端返回给客户端的称为响应报文,实际上,整个报文全部是以文本形式发送的,通过使用空格和换行来完成分段。
现在,我们已经了解了HTTP协议的全部基础知识,那么什么是Web服务器呢,实际上,它就是一个软件,但是它已经封装了所有的HTTP协议层面的操作,我们无需关心如何使用HTTP协议通信,而是直接基于服务器软件进行开发,我们只需要关心我们的页面数据如何展示、前后端如何交互即可。
认识Tomcat服务器

Tomcat(汤姆猫)就是一个典型的Web应用服务器软件,通过运行Tomcat服务器,我们就可以快速部署我们的Web项目,并交由Tomcat进行管理,我们只需要直接通过浏览器访问我们的项目即可。
那么首先,我们需要进行一个简单的环境搭建,我们需要在Tomcat官网下载最新的Tomcat服务端程序:https://tomcat.apache.org/download-10.cgi(下载速度可能有点慢)
- 下载:64-bit Windows zip
下载完成后,解压,并放入桌面,接下来需要配置一下环境变量,打开高级系统设置,打开环境变量,添加一个新的系统变量,变量名称为JRE_HOME,填写JDK的安装目录+/jre,比如Zulujdk默认就是:C:\Program Files\Zulu\zulu-8\jre
设置完成后,我们进入tomcat文件夹bin目录下,并在当前位置打开CMD窗口,将startup.sh拖入窗口按回车运行,如果环境变量配置有误,会提示,若没问题,服务器则正常启动。
如果出现乱码,说明编码格式配置有问题,我们修改一下服务器的配置文件,打开conf文件夹,找到logging.properties文件,这就是日志的配置文件(我们在前面已经给大家讲解过了)将ConsoleHandler的默认编码格式修改为GBK编码格式:
java.util.logging.ConsoleHandler.encoding = GBK
现在重新启动服务器,就可以正常显示中文了。
服务器启动成功之后,不要关闭,我们打开浏览器,在浏览器中访问:http://localhost:8080/,Tomcat服务器默认是使用8080端口(可以在配置文件中修改),访问成功说明我们的Tomcat环境已经部署成功了。
整个Tomcat目录下,我们已经认识了bin目录(所有可执行文件,包括启动和关闭服务器的脚本)以及conf目录(服务器配置文件目录),那么我们接着来看其他的文件夹:
- lib目录:Tomcat服务端运行的一些依赖,不用关心。
- logs目录:所有的日志信息都在这里。
- temp目录:存放运行时产生的一些临时文件,不用关心。
- work目录:工作目录,Tomcat会将jsp文件转换为java文件(我们后面会讲到,这里暂时不提及)
- webapp目录:所有的Web项目都在这里,每个文件夹都是一个Web应用程序:
我们发现,官方已经给我们预设了一些项目了,访问后默认使用的项目为ROOT项目,也就是我们默认打开的网站。
我们也可以访问example项目,只需要在后面填写路径即可:http://localhost:8080/examples/,或是docs项目(这个是Tomcat的一些文档)http://localhost:8080/docs/
Tomcat还自带管理页面,我们打开:http://localhost:8080/manager,提示需要用户名和密码,由于不知道是什么,我们先点击取消,页面中出现如下内容:
You are not authorized to view this page. If you have not changed any configuration files, please examine the file
conf/tomcat-users.xmlin your installation. That file must contain the credentials to let you use this webapp.For example, to add the
manager-guirole to a user namedtomcatwith a password ofs3cret, add the following to the config file listed above.<role rolename="manager-gui"/> <user username="tomcat" password="s3cret" roles="manager-gui"/>Note that for Tomcat 7 onwards, the roles required to use the manager application were changed from the single
managerrole to the following four roles. You will need to assign the role(s) required for the functionality you wish to access.
manager-gui- allows access to the HTML GUI and the status pagesmanager-script- allows access to the text interface and the status pagesmanager-jmx- allows access to the JMX proxy and the status pagesmanager-status- allows access to the status pages onlyThe HTML interface is protected against CSRF but the text and JMX interfaces are not. To maintain the CSRF protection:
- Users with the
manager-guirole should not be granted either themanager-scriptormanager-jmxroles.- If the text or jmx interfaces are accessed through a browser (e.g. for testing since these interfaces are intended for tools not humans) then the browser must be closed afterwards to terminate the session.
For more information - please see the Manager App How-To.
现在我们按照上面的提示,去配置文件中进行修改:
<role rolename="manager-gui"/>
<user username="admin" password="admin" roles="manager-gui"/>
现在再次打开管理页面,已经可以成功使用此用户进行登陆了。登录后,展示给我们的是一个图形化界面,我们可以快速预览当前服务器的一些信息,包括已经在运行的Web应用程序,甚至还可以查看当前的Web应用程序有没有出现内存泄露。
同样的,还有一个虚拟主机管理页面,用于一台主机搭建多个Web站点,一般情况下使用不到,这里就不做演示了。
我们可以将我们自己的项目也放到webapp文件夹中,这样就可以直接访问到了,我们在webapp目录下新建test文件夹,将我们之前编写的前端代码全部放入其中(包括html文件、js、css、icon等),重启服务器。
我们可以直接通过 http://localhost:8080/test/ 来进行访问。
使用Maven创建Web项目
虽然我们已经可以在Tomcat上部署我们的前端页面了,但是依然只是一个静态页面(每次访问都是同样的样子),那么如何向服务器请求一个动态的页面呢(比如显示我们访问当前页面的时间)这时就需要我们编写一个Web应用程序来实现了,我们需要在用户向服务器发起页面请求时,进行一些处理,再将结果发送给用户的浏览器。
注意:这里需要使用终极版IDEA,如果你的还是社区版,就很难受了。
我们打开IDEA,新建一个项目,选择Java Enterprise(社区版没有此选项!)项目名称随便,项目模板选择Web应用程序,然后我们需要配置Web应用程序服务器,将我们的Tomcat服务器集成到IDEA中。配置很简单,首先点击新建,然后设置Tomcat主目录即可,配置完成后,点击下一步即可,依赖项使用默认即可,然后点击完成,之后IDEA会自动帮助我们创建Maven项目。
创建完成后,直接点击右上角即可运行此项目了,但是我们发现,有一个Servlet页面不生效。
需要注意的是,Tomcat10以上的版本比较新,Servlet API包名发生了一些变化,因此我们需要修改一下依赖:
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<version>5.0.0</version>
<scope>provided</scope>
</dependency>
注意包名全部从javax改为jakarta,我们需要手动修改一下。
感兴趣的可以了解一下为什么名称被修改了:
Eclipse基金会在2019年对 Java EE 标准的每个规范进行了重命名,阐明了每个规范在Jakarta EE平台未来的角色。
新的名称Jakarta EE是Java EE的第二次重命名。2006年5月,“J2EE”一词被弃用,并选择了Java EE这个名称。在YouTube还只是一家独立的公司的时候,数字2就就从名字中消失了,而且当时冥王星仍然被认为是一颗行星。同样,作为Java SE 5(2004)的一部分,数字2也从J2SE中删除了,那时谷歌还没有上市。
因为不能再使用javax名称空间,Jakarta EE提供了非常明显的分界线。
- Jakarta 9(2019及以后)使用jakarta命名空间。
- Java EE 5(2005)到Java EE 8(2017)使用javax命名空间。
- Java EE 4使用javax命名空间。
我们可以将项目直接打包为war包(默认),打包好之后,放入webapp文件夹,就可以直接运行我们通过Java编写的Web应用程序了,访问路径为文件的名称。
Servlet
前面我们已经完成了基本的环境搭建,那么现在我们就可以开始来了解我们的第一个重要类——Servlet。
它是Java EE的一个标准,大部分的Web服务器都支持此标准,包括Tomcat,就像之前的JDBC一样,由官方定义了一系列接口,而具体实现由我们来编写,最后交给Web服务器(如Tomcat)来运行我们编写的Servlet。
那么,它能做什么呢?
我们可以通过实现Servlet来进行动态网页响应,使用Servlet,不再是直接由Tomcat服务器发送我们编写好的静态网页内容(HTML文件),而是由我们通过Java代码进行动态拼接的结果,它能够很好地实现动态网页的返回。
当然,Servlet并不是专用于HTTP协议通信,也可以用于其他的通信,但是一般都是用于HTTP。
创建Servlet
那么如何创建一个Servlet呢,非常简单,我们只需要实现Servlet类即可,并添加注解@WebServlet来进行注册。
@WebServlet("/test")
public class TestServlet implements Servlet {
...实现接口方法
}
我们现在就可以去访问一下我们的页面:http://localhost:8080/test/test
我们发现,直接访问此页面是没有任何内容的,这是因为我们还没有为该请求方法编写实现,这里先不做讲解,后面我们会对浏览器的请求处理做详细的介绍。
除了直接编写一个类,我们也可以在web.xml中进行注册,现将类上@WebServlet的注解去掉:
<servlet>
<servlet-name>test</servlet-name>
<servlet-class>com.example.webtest.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>test</servlet-name>
<url-pattern>/test</url-pattern>
</servlet-mapping>
这样的方式也能注册Servlet,但是显然直接使用注解更加方便,因此之后我们一律使用注解进行开发。只有比较新的版本才支持此注解,老的版本是不支持的哦。
实际上,Tomcat服务器会为我们提供一些默认的Servlet,也就是说在服务器启动后,即使我们什么都不编写,Tomcat也自带了几个默认的Servlet,他们编写在conf目录下的web.xml中:
<!-- The mapping for the default servlet -->
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<!-- The mappings for the JSP servlet -->
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
<url-pattern>*.jspx</url-pattern>
</servlet-mapping>
我们发现,默认的Servlet实际上可以帮助我们去访问一些静态资源,这也是为什么我们启动Tomcat服务器之后,能够直接访问webapp目录下的静态页面。
我们可以将之前编写的页面放入到webapp目录下,来测试一下是否能直接访问。
探究Servlet的生命周期
我们已经了解了如何注册一个Servlet,那么我们接着来看看,一个Servlet是如何运行的。
首先我们需要了解,Servlet中的方法各自是在什么时候被调用的,我们先编写一个打印语句来看看:
public class TestServlet implements Servlet {
public TestServlet(){
System.out.println("我是构造方法!");
}
@Override
public void init(ServletConfig servletConfig) throws ServletException {
System.out.println("我是init");
}
@Override
public ServletConfig getServletConfig() {
System.out.println("我是getServletConfig");
return null;
}
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
System.out.println("我是service");
}
@Override
public String getServletInfo() {
System.out.println("我是getServletInfo");
return null;
}
@Override
public void destroy() {
System.out.println("我是destroy");
}
}
我们首先启动一次服务器,然后访问我们定义的页面,然后再关闭服务器,得到如下的顺序:
我是构造方法!
我是init
我是service
我是service(出现两次是因为浏览器请求了2次,是因为有一次是请求favicon.ico,浏览器通病)我是destroy
我们可以多次尝试去访问此页面,但是init和构造方法只会执行一次,而每次访问都会执行的是service方法,因此,一个Servlet的生命周期为:
- 首先执行构造方法完成 Servlet 初始化
- Servlet 初始化后调用 init () 方法。
- Servlet 调用 service() 方法来处理客户端的请求。
- Servlet 销毁前调用 destroy() 方法。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
现在我们发现,实际上在Web应用程序运行时,每当浏览器向服务器发起一个请求时,都会创建一个线程执行一次service方法,来让我们处理用户的请求,并将结果响应给用户。
我们发现service方法中,还有两个参数,ServletRequest和ServletResponse,实际上,用户发起的HTTP请求,就被Tomcat服务器封装为了一个ServletRequest对象,我们得到是其实是Tomcat服务器帮助我们创建的一个实现类,HTTP请求报文中的所有内容,都可以从ServletRequest对象中获取,同理,ServletResponse就是我们需要返回给浏览器的HTTP响应报文实体类封装。
那么我们来看看ServletRequest中有哪些内容,我们可以获取请求的一些信息:
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
//首先将其转换为HttpServletRequest(继承自ServletRequest,一般是此接口实现)
HttpServletRequest request = (HttpServletRequest) servletRequest;
System.out.println(request.getProtocol()); //获取协议版本
System.out.println(request.getRemoteAddr()); //获取访问者的IP地址
System.out.println(request.getMethod()); //获取请求方法
//获取头部信息
Enumeration<String> enumeration = request.getHeaderNames();
while (enumeration.hasMoreElements()){
String name = enumeration.nextElement();
System.out.println(name + ": " + request.getHeader(name));
}
}
我们发现,整个HTTP请求报文中的所有内容,都可以通过HttpServletRequest对象来获取,当然,它的作用肯定不仅仅是获取头部信息,我们还可以使用它来完成更多操作,后面会一一讲解。
那么我们再来看看ServletResponse,这个是服务端的响应内容,我们可以在这里填写我们想要发送给浏览器显示的内容:
//转换为HttpServletResponse(同上)
HttpServletResponse response = (HttpServletResponse) servletResponse;
//设定内容类型以及编码格式(普通HTML文本使用text/html,之后会讲解文件传输)
response.setHeader("Content-type", "text/html;charset=UTF-8");
//获取Writer直接写入内容
response.getWriter().write("我是响应内容!");
//所有内容写入完成之后,再发送给浏览器
现在我们在浏览器中打开此页面,就能够收到服务器发来的响应内容了。其中,响应头部分,是由Tomcat帮助我们生成的一个默认响应头。

因此,实际上整个流程就已经很清晰明了了。
解读和使用HttpServlet
前面我们已经学习了如何创建、注册和使用Servlet,那么我们继续来深入学习Servlet接口的一些实现类。
首先Servlet有一个直接实现抽象类GenericServlet,那么我们来看看此类做了什么事情。
我们发现,这个类完善了配置文件读取和Servlet信息相关的的操作,但是依然没有去实现service方法,因此此类仅仅是用于完善一个Servlet的基本操作,那么我们接着来看HttpServlet,它是遵循HTTP协议的一种Servlet,继承自GenericServlet,它根据HTTP协议的规则,完善了service方法。
在阅读了HttpServlet源码之后,我们发现,其实我们只需要继承HttpServlet来编写我们的Servlet就可以了,并且它已经帮助我们提前实现了一些操作,这样就会给我们省去很多的时间。
@Log
@WebServlet("/test")
public class TestServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("<h1>恭喜你解锁了全新玩法</h1>");
}
}
现在,我们只需要重写对应的请求方式,就可以快速完成Servlet的编写。
@WebServlet注解详解
我们接着来看WebServlet注解,我们前面已经得知,可以直接使用此注解来快速注册一个Servlet,那么我们来想细看看此注解还有什么其他的玩法。
首先name属性就是Servlet名称,而urlPatterns和value实际上是同样功能,就是代表当前Servlet的访问路径,它不仅仅可以是一个固定值,还可以进行通配符匹配:
@WebServlet("/test/*")
上面的路径表示,所有匹配/test/随便什么的路径名称,都可以访问此Servlet,我们可以在浏览器中尝试一下。
也可以进行某个扩展名称的匹配:
@WebServlet("*.js")
这样的话,获取任何以js结尾的文件,都会由我们自己定义的Servlet处理。
那么如果我们的路径为/呢?
@WebServlet("/")
此路径和Tomcat默认为我们提供的Servlet冲突,会直接替换掉默认的,而使用我们的,此路径的意思为,如果没有找到匹配当前访问路径的Servlet,那么久会使用此Servlet进行处理。
我们还可以为一个Servlet配置多个访问路径:
@WebServlet({"/test1", "/test2"})
我们接着来看loadOnStartup属性,此属性决定了是否在Tomcat启动时就加载此Servlet,默认情况下,Servlet只有在被访问时才会加载,它的默认值为-1,表示不在启动时加载,我们可以将其修改为大于等于0的数,来开启启动时加载。并且数字的大小决定了此Servlet的启动优先级。
@Log
@WebServlet(value = "/test", loadOnStartup = 1)
public class TestServlet extends HttpServlet {
@Override
public void init() throws ServletException {
super.init();
log.info("我被初始化了!");
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("<h1>恭喜你解锁了全新玩法</h1>");
}
}
其他内容都是Servlet的一些基本配置,这里就不详细讲解了。
使用POST请求完成登陆
我们前面已经了解了如何使用Servlet来处理HTTP请求,那么现在,我们就结合前端,来实现一下登陆操作。
我们需要修改一下我们的Servlet,现在我们要让其能够接收一个POST请求:
@Log
@WebServlet("/login")
public class LoginServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.getParameterMap().forEach((k, v) -> {
System.out.println(k + ": " + Arrays.toString(v));
});
}
}
ParameterMap存储了我们发送的POST请求所携带的表单数据,我们可以直接将其遍历查看,浏览器发送了什么数据。
现在我们再来修改一下前端:
<body>
<h1>登录到系统</h1>
<form method="post" action="login">
<hr>
<div>
<label>
<input type="text" placeholder="用户名" name="username">
</label>
</div>
<div>
<label>
<input type="password" placeholder="密码" name="password">
</label>
</div>
<div>
<button>登录</button>
</div>
</form>
</body>
通过修改form标签的属性,现在我们点击登录按钮,会自动向后台发送一个POST请求,请求地址为当前地址+/login(注意不同路径的写法),也就是我们上面编写的Servlet路径。
运行服务器,测试后发现,在点击按钮后,确实向服务器发起了一个POST请求,并且携带了表单中文本框的数据。
现在,我们根据已有的基础,将其与数据库打通,我们进行一个真正的用户登录操作,首先修改一下Servlet的逻辑:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//首先设置一下响应类型
resp.setContentType("text/html;charset=UTF-8");
//获取POST请求携带的表单数据
Map<String, String[]> map = req.getParameterMap();
//判断表单是否完整
if(map.containsKey("username") && map.containsKey("password")) {
String username = req.getParameter("username");
String password = req.getParameter("password");
//权限校验(待完善)
}else {
resp.getWriter().write("错误,您的表单数据不完整!");
}
}
接下来我们再去编写Mybatis的依赖和配置文件,创建一个表,用于存放我们用户的账号和密码。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${驱动类(含包名)}"/>
<property name="url" value="${数据库连接URL}"/>
<property name="username" value="${用户名}"/>
<property name="password" value="${密码}"/>
</dataSource>
</environment>
</environments>
</configuration>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
配置完成后,在我们的Servlet的init方法中编写Mybatis初始化代码,因为它只需要初始化一次。
SqlSessionFactory factory;
@SneakyThrows
@Override
public void init() throws ServletException {
factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis-config.xml"));
}
现在我们创建一个实体类以及Mapper来进行用户信息查询:
@Data
public class User {
String username;
String password;
}
public interface UserMapper {
@Select("select * from users where username = #{username} and password = #{password}")
User getUser(@Param("username") String username, @Param("password") String password);
}
<mappers>
<mapper class="com.example.dao.UserMapper"/>
</mappers>
好了,现在完事具备,只欠东风了,我们来完善一下登陆验证逻辑:
//登陆校验(待完善)
try (SqlSession sqlSession = factory.openSession(true)){
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUser(username, password);
//判断用户是否登陆成功,若查询到信息则表示存在此用户
if(user != null){
resp.getWriter().write("登陆成功!");
}else {
resp.getWriter().write("登陆失败,请验证您的用户名或密码!");
}
}
现在再去浏览器上进行测试吧!
注册界面其实是同理的,这里就不多做讲解了。
上传和下载文件
首先我们来看看比较简单的下载文件,首先将我们的icon.png放入到resource文件夹中,接着我们编写一个Servlet用于处理文件下载:
@WebServlet("/file")
public class FileServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("image/png");
OutputStream outputStream = resp.getOutputStream();
InputStream inputStream = Resources.getResourceAsStream("icon.png");
}
}
为了更加快速地编写IO代码,我们可以引入一个工具库:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
使用此类库可以快速完成IO操作:
resp.setContentType("image/png");
OutputStream outputStream = resp.getOutputStream();
InputStream inputStream = Resources.getResourceAsStream("icon.png");
//直接使用copy方法完成转换
IOUtils.copy(inputStream, outputStream);
现在我们在前端页面添加一个链接,用于下载此文件:
<hr>
<a href="file" download="icon.png">点我下载高清资源</a>
下载文件搞定,那么如何上传一个文件呢?
首先我们编写前端部分:
<form method="post" action="file" enctype="multipart/form-data">
<div>
<input type="file" name="test-file">
</div>
<div>
<button>上传文件</button>
</div>
</form>
注意必须添加enctype="multipart/form-data",来表示此表单用于文件传输。
现在我们来修改一下Servlet代码:
@MultipartConfig
@WebServlet("/file")
public class FileServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
try(FileOutputStream stream = new FileOutputStream("/Users/nagocoler/Documents/IdeaProjects/WebTest/test.png")){
Part part = req.getPart("test-file");
IOUtils.copy(part.getInputStream(), stream);
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("文件上传成功!");
}
}
}
注意,必须添加@MultipartConfig注解来表示此Servlet用于处理文件上传请求。
现在我们再运行服务器,并将我们刚才下载的文件又上传给服务端。
使用XHR请求数据
现在我们希望,网页中的部分内容,可以动态显示,比如网页上有一个时间,旁边有一个按钮,点击按钮就可以刷新当前时间。
这个时候就需要我们在网页展示时向后端发起请求了,并根据后端响应的结果,动态地更新页面中的内容,要实现此功能,就需要用到JavaScript来帮助我们,首先在js中编写我们的XHR请求,并在请求中完成动态更新:
function updateTime() {
let xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
document.getElementById("time").innerText = xhr.responseText
}
};
xhr.open('GET', 'time', true);
xhr.send();
}
接着修改一下前端页面,添加一个时间显示区域:
<hr>
<div id="time"></div>
<br>
<button onclick="updateTime()">更新数据</button>
<script>
updateTime()
</script>
最后创建一个Servlet用于处理时间更新请求:
@WebServlet("/time")
public class TimeServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
String date = dateFormat.format(new Date());
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write(date);
}
}
现在点击按钮就可以更新了。
GET请求也能传递参数,这里做一下演示。
重定向与请求转发
当我们希望用户登录完成之后,直接跳转到网站的首页,那么这个时候,我们就可以使用重定向来完成。
当浏览器收到一个重定向的响应时,会按照重定向响应给出的地址,再次向此地址发出请求。
实现重定向很简单,只需要调用一个方法即可,我们修改一下登陆成功后执行的代码:
resp.sendRedirect("time");
调用后,响应的状态码会被设置为302,并且响应头中添加了一个Location属性,此属性表示,需要重定向到哪一个网址。
现在,如果我们成功登陆,那么服务器会发送给我们一个重定向响应,这时,我们的浏览器会去重新请求另一个网址。这样,我们在登陆成功之后,就可以直接帮助用户跳转到用户首页了。
那么我们接着来看请求转发,请求转发其实是一种服务器内部的跳转机制,我们知道,重定向会使得浏览器去重新请求一个页面,而请求转发则是服务器内部进行跳转,它的目的是,直接将本次请求转发给其他Servlet进行处理,并由其他Servlet来返回结果,因此它是在进行内部的转发。
req.getRequestDispatcher("/time").forward(req, resp);
现在,在登陆成功的时候,我们将请求转发给处理时间的Servlet,注意这里的路径规则和之前的不同,我们需要填写Servlet上指明的路径,并且请求转发只能转发到此应用程序内部的Servlet,不能转发给其他站点或是其他Web应用程序。
现在再次进行登陆操作,我们发现,返回结果为一个405页面,证明了,我们的请求现在是被另一个Servlet进行处理,并且请求的信息全部被转交给另一个Servlet,由于此Servlet不支持POST请求,因此返回405状态码。
那么也就是说,该请求包括请求参数也一起被传递了,那么我们可以尝试获取以下POST请求的参数。
现在我们给此Servlet添加POST请求处理,直接转交给Get请求处理:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doGet(req, resp);
}
再次访问,成功得到结果,但是我们发现,浏览器只发起了一次请求,并没有再次请求新的URL,也就是说,这一次请求直接返回了请求转发后的处理结果。
那么,请求转发有什么好处呢?它可以携带数据!
req.setAttribute("test", "我是请求转发前的数据");
req.getRequestDispatcher("/time").forward(req, resp);
System.out.println(req.getAttribute("test"));
通过setAttribute方法来给当前请求添加一个附加数据,在请求转发后,我们可以直接获取到该数据。
重定向属于2次请求,因此无法使用这种方式来传递数据,那么,如何在重定向之间传递数据呢?
我们可以使用即将要介绍的ServletContext对象。
最后总结,两者的区别为:
- 请求转发是一次请求,重定向是两次请求
- 请求转发地址栏不会发生改变, 重定向地址栏会发生改变
- 请求转发可以共享请求参数 ,重定向之后,就获取不了共享参数了
- 请求转发只能转发给内部的Servlet
了解ServletContext对象
ServletContext全局唯一,它是属于整个Web应用程序的,我们可以通过getServletContext()来获取到此对象。
此对象也能设置附加值:
ServletContext context = getServletContext();
context.setAttribute("test", "我是重定向之前的数据");
resp.sendRedirect("time");
System.out.println(getServletContext().getAttribute("test"));
因为无论在哪里,无论什么时间,获取到的ServletContext始终是同一个对象,因此我们可以随时随地获取我们添加的属性。
它不仅仅可以用来进行数据传递,还可以做一些其他的事情,比如请求转发:
context.getRequestDispatcher("/time").forward(req, resp);
它还可以获取根目录下的资源文件(注意是webapp根目录下的,不是resource中的资源)
初始化参数
初始化参数类似于初始化配置需要的一些值,比如我们的数据库连接相关信息,就可以通过初始化参数来给予Servlet,或是一些其他的配置项,也可以使用初始化参数来实现。
我们可以给一个Servlet添加一些初始化参数:
@WebServlet(value = "/login", initParams = {
@WebInitParam(name = "test", value = "我是一个默认的初始化参数")
})
它也是以键值对形式保存的,我们可以直接通过Servlet的getInitParameter方法获取:
System.out.println(getInitParameter("test"));
但是,这里的初始化参数仅仅是针对于此Servlet,我们也可以定义全局初始化参数,只需要在web.xml编写即可:
<context-param>
<param-name>lbwnb</param-name>
<param-value>我是全局初始化参数</param-value>
</context-param>
我们需要使用ServletContext来读取全局初始化参数:
ServletContext context = getServletContext();
System.out.println(context.getInitParameter("lbwnb"));
有关ServletContext其他的内容,我们需要完成后面内容的学习,才能理解。
Cookie
什么是Cookie?
不是曲奇,它可以在浏览器中保存一些信息,并且在下次请求时,请求头中会携带这些信息。
我们可以编写一个测试用例来看看:
Cookie cookie = new Cookie("test", "yyds");
resp.addCookie(cookie);
resp.sendRedirect("time");
for (Cookie cookie : req.getCookies()) {
System.out.println(cookie.getName() + ": " + cookie.getValue());
}
我们可以观察一下,在HttpServletResponse中添加Cookie之后,浏览器的响应头中会包含一个Set-Cookie属性,同时,在重定向之后,我们的请求头中,会携带此Cookie作为一个属性,同时,我们可以直接通过HttpServletRequest来快速获取有哪些Cookie信息。

还有这么神奇的事情吗?那么我们来看看,一个Cookie包含哪些信息:
- name - Cookie的名称,Cookie一旦创建,名称便不可更改
- value - Cookie的值,如果值为Unicode字符,需要为字符编码。如果为二进制数据,则需要使用BASE64编码
- maxAge - Cookie失效的时间,单位秒。如果为正数,则该Cookie在maxAge秒后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为-1。
- secure - 该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。
- path - Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”。
- domain - 可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.”。
- comment - 该Cookie的用处说明,浏览器显示Cookie信息的时候显示该说明。
- version - Cookie使用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范
我们发现,最关键的其实是name、value、maxAge、domain属性。
那么我们来尝试修改一下maxAge来看看失效时间:
cookie.setMaxAge(20);
设定为20秒,我们可以直接看到,响应头为我们设定了20秒的过期时间。20秒内访问都会携带此Cookie,而超过20秒,Cookie消失。
既然了解了Cookie的作用,我们就可以通过使用Cookie来实现记住我功能,我们可以将用户名和密码全部保存在Cookie中,如果访问我们的首页时携带了这些Cookie,那么我们就可以直接为用户进行登陆,如果登陆成功则直接跳转到首页,如果登陆失败,则清理浏览器中的Cookie。
那么首先,我们先在前端页面的表单中添加一个勾选框:
<div>
<label>
<input type="checkbox" placeholder="记住我" name="remember-me">
记住我
</label>
</div>
接着,我们在登陆成功时进行判断,如果用户勾选了记住我,那么就讲Cookie存储到本地:
if(map.containsKey("remember-me")){ //若勾选了勾选框,那么会此表单信息
Cookie cookie_username = new Cookie("username", username);
cookie_username.setMaxAge(30);
Cookie cookie_password = new Cookie("password", password);
cookie_password.setMaxAge(30);
resp.addCookie(cookie_username);
resp.addCookie(cookie_password);
}
然后,我们修改一下默认的请求地址,现在一律通过http://localhost:8080/yyds/login进行登陆,那么我们需要添加GET请求的相关处理:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Cookie[] cookies = req.getCookies();
if(cookies != null){
String username = null;
String password = null;
for (Cookie cookie : cookies) {
if(cookie.getName().equals("username")) username = cookie.getValue();
if(cookie.getName().equals("password")) password = cookie.getValue();
}
if(username != null && password != null){
//登陆校验
try (SqlSession sqlSession = factory.openSession(true)){
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUser(username, password);
if(user != null){
resp.sendRedirect("time");
return; //直接返回
}
}
}
}
req.getRequestDispatcher("/").forward(req, resp); //正常情况还是转发给默认的Servlet帮我们返回静态页面
}
现在,30秒内都不需要登陆,访问登陆页面后,会直接跳转到time页面。
现在已经离我们理想的页面越来越接近了,但是仍然有一个问题,就是我们的首页,无论是否登陆,所有人都可以访问。
那么,如何才可以实现只有登陆之后才能访问呢?这就需要用到Session了。
Session
由于HTTP是无连接的,那么如何能够辨别当前的请求是来自哪个用户发起的呢?
Session就是用来处理这种问题的,每个用户的会话都会有一个自己的Session对象,来自同一个浏览器的所有请求,就属于同一个会话。
但是HTTP协议是无连接的呀,那Session是如何做到辨别是否来自同一个浏览器呢?Session实际上是基于Cookie实现的,前面我们了解了Cookie,我们知道,服务端可以将Cookie保存到浏览器,当浏览器下次访问时,就会附带这些Cookie信息。
Session也利用了这一点,它会给浏览器设定一个叫做JSESSIONID的Cookie,值是一个随机的排列组合,而此Cookie就对应了你属于哪一个对话,只要我们的浏览器携带此Cookie访问服务器,服务器就会通过Cookie的值进行辨别,得到对应的Session对象,因此,这样就可以追踪到底是哪一个浏览器在访问服务器。

那么现在,我们在用户登录成功之后,将用户对象添加到Session中,只要是此用户发起的请求,我们都可以从HttpSession中读取到存储在会话中的数据:
HttpSession session = req.getSession();
session.setAttribute("user", user);
同时,如果用户没有登录就去访问首页,那么我们将发送一个重定向请求,告诉用户,需要先进行登录才可以访问:
HttpSession session = req.getSession();
User user = (User) session.getAttribute("user");
if(user == null) {
resp.sendRedirect("login");
return;
}
在访问的过程中,注意观察Cookie变化。
Session并不是永远都存在的,它有着自己的过期时间,默认时间为30分钟,若超过此时间,Session将丢失,我们可以在配置文件中修改过期时间:
<session-config>
<session-timeout>1</session-timeout>
</session-config>
我们也可以在代码中使用invalidate方法来使Session立即失效:
session.invalidate();
现在,通过Session,我们就可以更好地控制用户对于资源的访问,只有完成登陆的用户才有资格访问首页。
Filter
有了Session之后,我们就可以很好地控制用户的登陆验证了,只有授权的用户,才可以访问一些页面。
但是我们需要一个一个去进行配置,还是太过复杂,能否一次性地过滤掉没有登录验证的用户呢?
过滤器相当于在所有访问前加了一堵墙,来自浏览器的所有访问请求都会首先经过过滤器,只有过滤器允许通过的请求,才可以顺利地到达对应的Servlet,而过滤器不允许的通过的请求,我们可以自由地进行控制是否进行重定向或是请求转发。并且过滤器可以添加很多个,就相当于添加了很多堵墙,我们的请求只有穿过层层阻碍,才能与Servlet相拥,像极了爱情。

添加一个过滤器非常简单,只需要实现Filter接口,并添加@WebFilter注解即可:
@WebFilter("/*") //路径的匹配规则和Servlet一致,这里表示匹配所有请求
public class TestFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
}
}
这样我们就成功地添加了一个过滤器,那么添加一句打印语句看看,是否所有的请求都会经过此过滤器:
HttpServletRequest request = (HttpServletRequest) servletRequest;
System.out.println(request.getRequestURL());
我们发现,现在我们发起的所有请求,一律需要经过此过滤器,并且所有的请求都没有任何的响应内容。
那么如何让请求可以顺利地到达对应的Servlet,也就是说怎么让这个请求顺利通过呢?我们只需要在最后添加一句:
filterChain.doFilter(servletRequest, servletResponse);
那么这行代码是什么意思呢?
由于我们整个应用程序可能存在多个过滤器,那么这行代码的意思实际上是将此请求继续传递给下一个过滤器,当没有下一个过滤器时,才会到达对应的Servlet进行处理,我们可以再来创建一个过滤器看看效果:
@WebFilter("/*")
public class TestFilter2 implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是2号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
}
}
由于过滤器的过滤顺序是按照类名的自然排序进行的,因此我们将第一个过滤器命名进行调整。
我们发现,在经过第一个过滤器之后,会继续前往第二个过滤器,只有两个过滤器全部经过之后,才会到达我们的Servlet中。

实际上,当doFilter方法调用时,就会一直向下直到Servlet,在Servlet处理完成之后,又依次返回到最前面的Filter,类似于递归的结构,我们添加几个输出语句来判断一下:
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是2号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("我是2号过滤器,处理后");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是1号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("我是1号过滤器,处理后");
}
最后验证我们的结论。
同Servlet一样,Filter也有对应的HttpFilter专用类,它针对HTTP请求进行了专门处理,因此我们可以直接使用HttpFilter来编写:
public abstract class HttpFilter extends GenericFilter {
private static final long serialVersionUID = 7478463438252262094L;
public HttpFilter() {
}
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
if (req instanceof HttpServletRequest && res instanceof HttpServletResponse) {
this.doFilter((HttpServletRequest)req, (HttpServletResponse)res, chain);
} else {
throw new ServletException("non-HTTP request or response");
}
}
protected void doFilter(HttpServletRequest req, HttpServletResponse res, FilterChain chain) throws IOException, ServletException {
chain.doFilter(req, res);
}
}
那么现在,我们就可以给我们的应用程序添加一个过滤器,用户在未登录情况下,只允许静态资源和登陆页面请求通过,登陆之后畅行无阻:
@WebFilter("/*")
public class MainFilter extends HttpFilter {
@Override
protected void doFilter(HttpServletRequest req, HttpServletResponse res, FilterChain chain) throws IOException, ServletException {
String url = req.getRequestURL().toString();
//判断是否为静态资源
if(!url.endsWith(".js") && !url.endsWith(".css") && !url.endsWith(".png")){
HttpSession session = req.getSession();
User user = (User) session.getAttribute("user");
//判断是否未登陆
if(user == null && !url.endsWith("login")){
res.sendRedirect("login");
return;
}
}
//交给过滤链处理
chain.doFilter(req, res);
}
}
现在,我们的页面已经基本完善为我们想要的样子了。
Listener
监听器并不是我们学习的重点内容,那么什么是监听器呢?
如果我们希望,在应用程序加载的时候,或是Session创建的时候,亦或是在Request对象创建的时候进行一些操作,那么这个时候,我们就可以使用监听器来实现。

默认为我们提供了很多类型的监听器,我们这里就演示一下监听Session的创建即可:
@WebListener
public class TestListener implements HttpSessionListener {
@Override
public void sessionCreated(HttpSessionEvent se) {
System.out.println("有一个Session被创建了");
}
}
有关监听器相关内容,了解即可。
了解JSP页面与加载规则
前面我们已经完成了整个Web应用程序生命周期中所有内容的学习,我们已经完全了解,如何编写一个Web应用程序,并放在Tomcat上部署运行,以及如何控制浏览器发来的请求,通过Session+Filter实现用户登陆验证,通过Cookie实现自动登陆等操作。到目前为止,我们已经具备编写一个完整Web网站的能力。
在之前的教程中,我们的前端静态页面并没有与后端相结合,我们前端页面所需的数据全部需要单独向后端发起请求获取,并动态进行内容填充,这是一种典型的前后端分离写法,前端只负责要数据和显示数据,后端只负责处理数据和提供数据,这也是现在更流行的一种写法,让前端开发者和后端开发者各尽其责,更加专一,这才是我们所希望的开发模式。
JSP并不是我们需要重点学习的内容,因为它已经过时了,使用JSP会导致前后端严重耦合,因此这里只做了解即可。
JSP其实就是一种模板引擎,那么何谓模板引擎呢?顾名思义,它就是一个模板,而模板需要我们填入数据,才可以变成一个页面,也就是说,我们可以直接在前端页面中直接填写数据,填写后生成一个最终的HTML页面返回给前端。
首先我们来创建一个新的项目,项目创建成功后,删除Java目录下的内容,只留下默认创建的jsp文件,我们发现,在webapp目录中,存在一个index.jsp文件,现在我们直接运行项目,会直接访问这个JSP页面。
<%@ page contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %>
<!DOCTYPE html>
<html>
<head>
<title>JSP - Hello World</title>
</head>
<body>
<h1><%= "Hello World!" %>
</h1>
<br/>
<a href="hello-servlet">Hello Servlet</a>
</body>
</html>
但是我们并没有编写对应的Servlet来解析啊,那么为什么这个JSP页面会被加载呢?
实际上,我们一开始提到的两个Tomcat默认的Servlet中,一个是用于请求静态资源,还有一个就是用于处理jsp的:
<!-- The mappings for the JSP servlet -->
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
<url-pattern>*.jspx</url-pattern>
</servlet-mapping>
那么,JSP和普通HTML页面有什么区别呢,我们发现它的语法和普通HTML页面几乎一致,我们可以直接在JSP中编写Java代码,并在页面加载的时候执行,我们随便找个地方插入:
<%
System.out.println("JSP页面被加载");
%>
我们发现,请求一次页面,页面就会加载一次,并执行我们填写的Java代码。也就是说,我们可以直接在此页面中执行Java代码来填充我们的数据,这样我们的页面就变成了一个动态页面,使用<%= %>来填写一个值:
<h1><%= new Date() %></h1>
现在访问我们的网站,每次都会创建一个新的Date对象,因此每次访问获取的时间都不一样,我们的网站已经算是一个动态的网站的了。
虽然这样在一定程度上上为我们提供了便利,但是这样的写法相当于整个页面既要编写前端代码,也要编写后端代码,随着项目的扩大,整个页面会显得难以阅读,并且现在都是前后端开发人员职责非常明确的,如果要编写JSP页面,那就必须要招一个既会前端也会后端的程序员,这样显然会导致不必要的开销。
那么我们来研究一下,为什么JSP页面能够在加载的时候执行Java代码呢?
首先我们将此项目打包,并在Tomcat服务端中运行,生成了一个文件夹并且可以正常访问。
我们现在看到work目录,我们发现这个里面多了一个index_jsp.java和index_jsp.class,那么这些东西是干嘛的呢,我们来反编译一下就啥都知道了:
public final class index_jsp extends org.apache.jasper.runtime.HttpJspBase //继承自HttpServlet
implements org.apache.jasper.runtime.JspSourceDependent,
org.apache.jasper.runtime.JspSourceImports {
...
public void _jspService(final jakarta.servlet.http.HttpServletRequest request, final jakarta.servlet.http.HttpServletResponse response)
throws java.io.IOException, jakarta.servlet.ServletException {
if (!jakarta.servlet.DispatcherType.ERROR.equals(request.getDispatcherType())) {
final java.lang.String _jspx_method = request.getMethod();
if ("OPTIONS".equals(_jspx_method)) {
response.setHeader("Allow","GET, HEAD, POST, OPTIONS");
return;
}
if (!"GET".equals(_jspx_method) && !"POST".equals(_jspx_method) && !"HEAD".equals(_jspx_method)) {
response.setHeader("Allow","GET, HEAD, POST, OPTIONS");
response.sendError(HttpServletResponse.SC_METHOD_NOT_ALLOWED, "JSP 只允许 GET、POST 或 HEAD。Jasper 还允许 OPTIONS");
return;
}
}
final jakarta.servlet.jsp.PageContext pageContext;
jakarta.servlet.http.HttpSession session = null;
final jakarta.servlet.ServletContext application;
final jakarta.servlet.ServletConfig config;
jakarta.servlet.jsp.JspWriter out = null;
final java.lang.Object page = this;
jakarta.servlet.jsp.JspWriter _jspx_out = null;
jakarta.servlet.jsp.PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=UTF-8");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\n");
out.write("\n");
out.write("<!DOCTYPE html>\n");
out.write("<html>\n");
out.write("<head>\n");
out.write(" <title>JSP - Hello World</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("<h1>");
out.print( new Date() );
out.write("</h1>\n");
System.out.println("JSP页面被加载");
out.write("\n");
out.write("<br/>\n");
out.write("<a href=\"hello-servlet\">Hello Servlet</a>\n");
out.write("</body>\n");
out.write("</html>");
} catch (java.lang.Throwable t) {
if (!(t instanceof jakarta.servlet.jsp.SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try {
if (response.isCommitted()) {
out.flush();
} else {
out.clearBuffer();
}
} catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
else throw new ServletException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
}
我们发现,它是继承自HttpJspBase类,我们可以反编译一下jasper.jar(它在tomcat的lib目录中)来看看:
package org.apache.jasper.runtime;
import jakarta.servlet.ServletConfig;
import jakarta.servlet.ServletException;
import jakarta.servlet.http.HttpServlet;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import jakarta.servlet.jsp.HttpJspPage;
import java.io.IOException;
import org.apache.jasper.compiler.Localizer;
public abstract class HttpJspBase extends HttpServlet implements HttpJspPage {
private static final long serialVersionUID = 1L;
protected HttpJspBase() {
}
public final void init(ServletConfig config) throws ServletException {
super.init(config);
this.jspInit();
this._jspInit();
}
public String getServletInfo() {
return Localizer.getMessage("jsp.engine.info", new Object[]{"3.0"});
}
public final void destroy() {
this.jspDestroy();
this._jspDestroy();
}
public final void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this._jspService(request, response);
}
public void jspInit() {
}
public void _jspInit() {
}
public void jspDestroy() {
}
protected void _jspDestroy() {
}
public abstract void _jspService(HttpServletRequest var1, HttpServletResponse var2) throws ServletException, IOException;
}
实际上,Tomcat在加载JSP页面时,会将其动态转换为一个java类并编译为class进行加载,而生成的Java类,正是一个Servlet的子类,而页面的内容全部被编译为输出字符串,这便是JSP的加载原理,因此,JSP本质上依然是一个Servlet!

如果同学们感兴趣的话,可以查阅一下其他相关的教程,本教程不再讲解此技术。
使用Thymeleaf模板引擎
虽然JSP为我们带来了便捷,但是其缺点也是显而易见的,那么有没有一种既能实现模板,又能兼顾前后端分离的模板引擎呢?
Thymeleaf(百里香叶)是一个适用于Web和独立环境的现代化服务器端Java模板引擎,官方文档:https://www.thymeleaf.org/documentation.html。
那么它和JSP相比,好在哪里呢,我们来看官网给出的例子:
<table>
<thead>
<tr>
<th th:text="#{msgs.headers.name}">Name</th>
<th th:text="#{msgs.headers.price}">Price</th>
</tr>
</thead>
<tbody>
<tr th:each="prod: ${allProducts}">
<td th:text="${prod.name}">Oranges</td>
<td th:text="${#numbers.formatDecimal(prod.price, 1, 2)}">0.99</td>
</tr>
</tbody>
</table>
我们可以在前端页面中填写占位符,而这些占位符的实际值则由后端进行提供,这样,我们就不用再像JSP那样前后端都写在一起了。
那么我们来创建一个例子感受一下,首先还是新建一个项目,注意,在创建时,勾选Thymeleaf依赖。
首先编写一个前端页面,名称为test.html,注意,是放在resource目录下,在html标签内部添加xmlns:th="http://www.thymeleaf.org"引入Thymeleaf定义的标签属性:
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div th:text="${title}"></div>
</body>
</html>
接着我们编写一个Servlet作为默认页面:
@WebServlet("/index")
public class HelloServlet extends HttpServlet {
TemplateEngine engine;
@Override
public void init() throws ServletException {
engine = new TemplateEngine();
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("title", "我是标题");
engine.process("test.html", context, resp.getWriter());
}
}
我们发现,浏览器得到的页面,就是已经经过模板引擎解析好的页面,而我们的代码依然是后端处理数据,前端展示数据,因此使用Thymeleaf就能够使得当前Web应用程序的前后端划分更加清晰。
虽然Thymeleaf在一定程度上分离了前后端,但是其依然是在后台渲染HTML页面并发送给前端,并不是真正意义上的前后端分离。
Thymeleaf语法基础
那么,如何使用Thymeleaf呢?
首先我们看看后端部分,我们需要通过TemplateEngine对象来将模板文件渲染为最终的HTML页面:
TemplateEngine engine;
@Override
public void init() throws ServletException {
engine = new TemplateEngine();
//设定模板解析器决定了从哪里获取模板文件,这里直接使用ClassLoaderTemplateResolver表示加载内部资源文件
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
由于此对象只需要创建一次,之后就可以一直使用了。接着我们来看如何使用模板引擎进行解析:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//创建上下文,上下文中包含了所有需要替换到模板中的内容
Context context = new Context();
context.setVariable("title", "<h1>我是标题</h1>");
//通过此方法就可以直接解析模板并返回响应
engine.process("test.html", context, resp.getWriter());
}
操作非常简单,只需要简单几步配置就可以实现模板的解析。接下来我们就可以在前端页面中通过上下文提供的内容,来将Java代码中的数据解析到前端页面。
接着我们来了解Thymeleaf如何为普通的标签添加内容,比如我们示例中编写的:
<div th:text="${title}"></div>
我们使用了th:text来为当前标签指定内部文本,注意任何内容都会变成普通文本,即使传入了一个HTML代码,如果我希望向内部添加一个HTML文本呢?我们可以使用th:utext属性:
<div th:utext="${title}"></div>
并且,传入的title属性,不仅仅只是一个字符串的值,而是一个字符串的引用,我们可以直接通过此引用调用相关的方法:
<div th:text="${title.toLowerCase()}"></div>
这样看来,Thymeleaf既能保持JSP为我们带来的便捷,也能兼顾前后端代码的界限划分。
除了替换文本,它还支持替换一个元素的任意属性,我们发现,th:能够拼接几乎所有的属性,一旦使用th:属性名称,那么属性的值就可以通过后端提供了,比如我们现在想替换一个图片的链接:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("url", "http://n.sinaimg.cn/sinakd20121/600/w1920h1080/20210727/a700-adf8480ff24057e04527bdfea789e788.jpg");
context.setVariable("alt", "图片就是加载不出来啊");
engine.process("test.html", context, resp.getWriter());
}
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img width="700" th:src="${url}" th:alt="${alt}">
</body>
</html>
现在访问我们的页面,就可以看到替换后的结果了。
Thymeleaf还可以进行一些算术运算,几乎Java中的运算它都可以支持:
<div th:text="${value % 2}"></div>
同样的,它还支持三元运算:
<div th:text="${value % 2 == 0 ? 'yyds' : 'lbwnb'}"></div>
多个属性也可以通过+进行拼接,就像Java中的字符串拼接一样,这里要注意一下,字符串不能直接写,要添加单引号:
<div th:text="${name}+' 我是文本 '+${value}"></div>
Thymeleaf流程控制语法
除了一些基本的操作,我们还可以使用Thymeleaf来处理流程控制语句,当然,不是直接编写Java代码的形式,而是添加一个属性即可。
首先我们来看if判断语句,如果if条件满足,则此标签留下,若if条件不满足,则此标签自动被移除:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("eval", true);
engine.process("test.html", context, resp.getWriter());
}
<div th:if="${eval}">我是判断条件标签</div>
th:if会根据其中传入的值或是条件表达式的结果进行判断,只有满足的情况下,才会显示此标签,具体的判断规则如下:
- 如果值不是空的:
- 如果值是布尔值并且为
true。 - 如果值是一个数字,并且是非零
- 如果值是一个字符,并且是非零
- 如果值是一个字符串,而不是“错误”、“关闭”或“否”
- 如果值不是布尔值、数字、字符或字符串。
- 如果值是布尔值并且为
- 如果值为空,th:if将计算为false
th:if还有一个相反的属性th:unless,效果完全相反,这里就不演示了。
我们接着来看多分支条件判断,我们可以使用th:switch属性来实现:
<div th:switch="${eval}">
<div th:case="1">我是1</div>
<div th:case="2">我是2</div>
<div th:case="3">我是3</div>
</div>
只不过没有default属性,但是我们可以使用th:case="*"来代替:
<div th:case="*">我是Default</div>
最后我们再来看看,它如何实现遍历,假如我们有一个存放书籍信息的List需要显示,那么如何快速生成一个列表呢?我们可以使用th:each来进行遍历操作:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("list", Arrays.asList("伞兵一号的故事", "倒一杯卡布奇诺", "玩游戏要啸着玩", "十七张牌前的电脑屏幕"));
engine.process("test.html", context, resp.getWriter());
}
<ul>
<li th:each="title : ${list}" th:text="'《'+${title}+'》'"></li>
</ul>
th:each中需要填写 "单个元素名称 : ${列表}",这样,所有的列表项都可以使用遍历的单个元素,只要使用了th:each,都会被循环添加。因此最后生成的结果为:
<ul>
<li>《伞兵一号的故事》</li>
<li>《倒一杯卡布奇诺》</li>
<li>《玩游戏要啸着玩》</li>
<li>《十七张牌前的电脑屏幕》</li>
</ul>
我们还可以获取当前循环的迭代状态,只需要在最后添加iterStat即可,从中可以获取很多信息,比如当前的顺序:
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
状态变量在th:each属性中定义,并包含以下数据:
- 当前迭代索引,以0开头。这是
index属性。 - 当前迭代索引,以1开头。这是
count属性。 - 迭代变量中的元素总量。这是
size属性。 - 每个迭代的迭代变量。这是
current属性。 - 当前迭代是偶数还是奇数。这些是
even/odd布尔属性。 - 当前迭代是否是第一个迭代。这是
first布尔属性。 - 当前迭代是否是最后一个迭代。这是
last布尔属性。
通过了解了流程控制语法,现在我们就可以很轻松地使用Thymeleaf来快速替换页面中的内容了。
Thymeleaf模板布局
在某些网页中,我们会发现,整个网站的页面,除了中间部分的内容会随着我们的页面跳转而变化外,有些部分是一直保持一个状态的,比如打开小破站,我们翻动评论或是切换视频分P的时候,变化的仅仅是对应区域的内容,实际上,其他地方的内容会无论内部页面如何跳转,都不会改变。
Thymeleaf就可以轻松实现这样的操作,我们只需要将不会改变的地方设定为模板布局,并在不同的页面中插入这些模板布局,就无需每个页面都去编写同样的内容了。现在我们来创建两个页面:
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div class="head">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
</body>
</html>
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div class="head">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
<div class="body">
<div>这个页面的样子是这样的</div>
</div>
</body>
</html>
接着将模板引擎写成工具类的形式:
public class ThymeleafUtil {
private static final TemplateEngine engine;
static {
engine = new TemplateEngine();
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
public static TemplateEngine getEngine() {
return engine;
}
}
@WebServlet("/index2")
public class HelloServlet2 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
ThymeleafUtil.getEngine().process("test2.html", context, resp.getWriter());
}
}
现在就有两个Servlet分别对应两个页面了,但是这两个页面实际上是存在重复内容的,我们要做的就是将这些重复内容提取出来。
我们单独编写一个head.html来存放重复部分:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org" lang="en">
<body>
<div class="head" th:fragment="head-title">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
</body>
</html>
现在,我们就可以直接将页面中的内容快速替换:
<div th:include="head.html::head-title"></div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
我们可以使用th:insert和th:replace和th:include这三种方法来进行页面内容替换,那么th:insert和th:replace(和th:include,自3.0年以来不推荐)有什么区别?
th:insert最简单:它只会插入指定的片段作为标签的主体。th:replace实际上将标签直接替换为指定的片段。th:include和th:insert相似,但它没有插入片段,而是只插入此片段的内容。
你以为这样就完了吗?它还支持参数传递,比如我们现在希望插入二级标题,并且由我们的子页面决定:
<div class="head" th:fragment="head-title">
<div>
<h1>我是标题内容,每个页面都有</h1>
<h2>我是二级标题</h2>
</div>
<hr>
</div>
稍加修改,就像JS那样添加一个参数名称:
<div class="head" th:fragment="head-title(sub)">
<div>
<h1>我是标题内容,每个页面都有</h1>
<h2 th:text="${sub}"></h2>
</div>
<hr>
</div>
现在直接在替换位置添加一个参数即可:
<div th:include="head.html::head-title('这个是第1个页面的二级标题')"></div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
这样,不同的页面还有着各自的二级标题。
探讨Tomcat类加载机制
有关JavaWeb的内容,我们就聊到这里,在最后,我们还是来看一下Tomcat到底是如何加载和运行我们的Web应用程序的。
Tomcat服务器既然要同时运行多个Web应用程序,那么就必须要实现不同应用程序之间的隔离,也就是说,Tomcat需要分别去加载不同应用程序的类以及依赖,还必须保证应用程序之间的类无法相互访问,而传统的类加载机制无法做到这一点,同时每个应用程序都有自己的依赖,如果两个应用程序使用了同一个版本的同一个依赖,那么还有必要去重新加载吗,带着诸多问题,Tomcat服务器编写了一套自己的类加载机制。

首先我们要知道,Tomcat本身也是一个Java程序,它要做的是去动态加载我们编写的Web应用程序中的类,而要解决以上提到的一些问题,就出现了几个新的类加载器,我们来看看各个加载器的不同之处:
- Common ClassLoader:Tomcat最基本的类加载器,加载路径中的class可以被Tomcat容器本身以及各个Web应用程序访问。
- Catalina ClassLoader:Tomcat容器私有的类加载器,加载路径中的class对于Web应用程序不可见。
- Shared ClassLoader:各个Web应用程序共享的类加载器,加载路径中的class对于所有Web应用程序可见,但是对于Tomcat容器不可见。
- Webapp ClassLoader:各个Web应用程序私有的类加载器,加载路径中的class只对当前Web应用程序可见,每个Web应用程序都有一个自己的类加载器,此加载器可能存在多个实例。
- JasperLoader:JSP类加载器,每个JSP文件都有一个自己的类加载器,也就是说,此加载器可能会存在多个实例。
通过这样进行划分,就很好地解决了我们上面所提到的问题,但是我们发现,这样的类加载机制,破坏了JDK的双亲委派机制(在JavaSE阶段讲解过),比如Webapp ClassLoader,它只加载自己的class文件,它没有将类交给父类加载器进行加载,也就是说,我们可以随意创建和JDK同包同名的类,岂不是就出问题了?
难道Tomcat的开发团队没有考虑到这个问题吗?

实际上,WebAppClassLoader的加载机制是这样的:WebAppClassLoader 加载类的时候,绕开了 AppClassLoader,直接先使用 ExtClassLoader 来加载类。这样的话,如果定义了同包同名的类,就不会被加载,而如果是自己定义 的类,由于该类并不是JDK内部或是扩展类,所有不会被加载,而是再次回到WebAppClassLoader进行加载,如果还失败,再使用AppClassloader进行加载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!