MySQL实战45讲(16--20)-笔记
笔记做的不好,因为还是又不少地方没有能够理解。见谅,后面理解了在更新…………
16 | “order by”是怎么工作的?
场景:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` int(11) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
select city,name,age from t where city='杭州' order by name limit 1000 ;
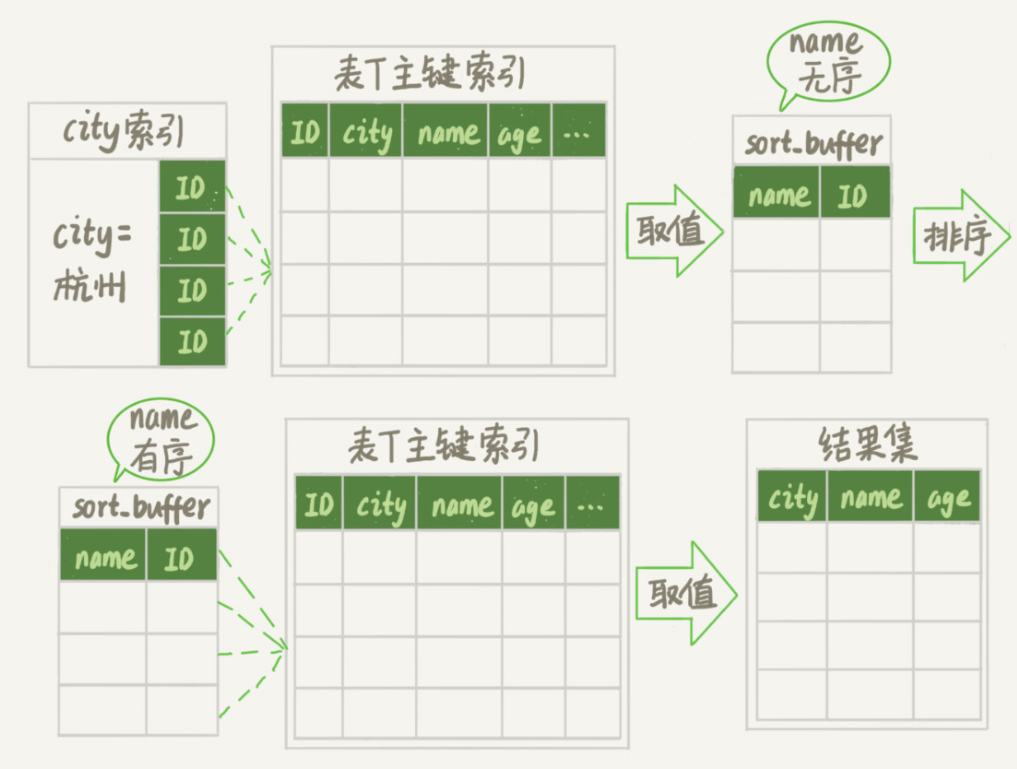
全字段排序
Extra 这个字段中的“Using filesort”表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。

图中“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
可以用这个语句来确定一个排序语句是否使用了临时文件:
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Inndb'
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb'
/* 计算 Innodb_rows_read 差值 */
select @b-@a
number_of_tmp_files 表示的是,排序过程中使用的临时文件数。
MySQL会将需要排序的文件分割成多份,小份单独排序后合一。(sort_buffer_size 越小,需要分成的份数越多,
number_of_tmp_files 的值就越大。)
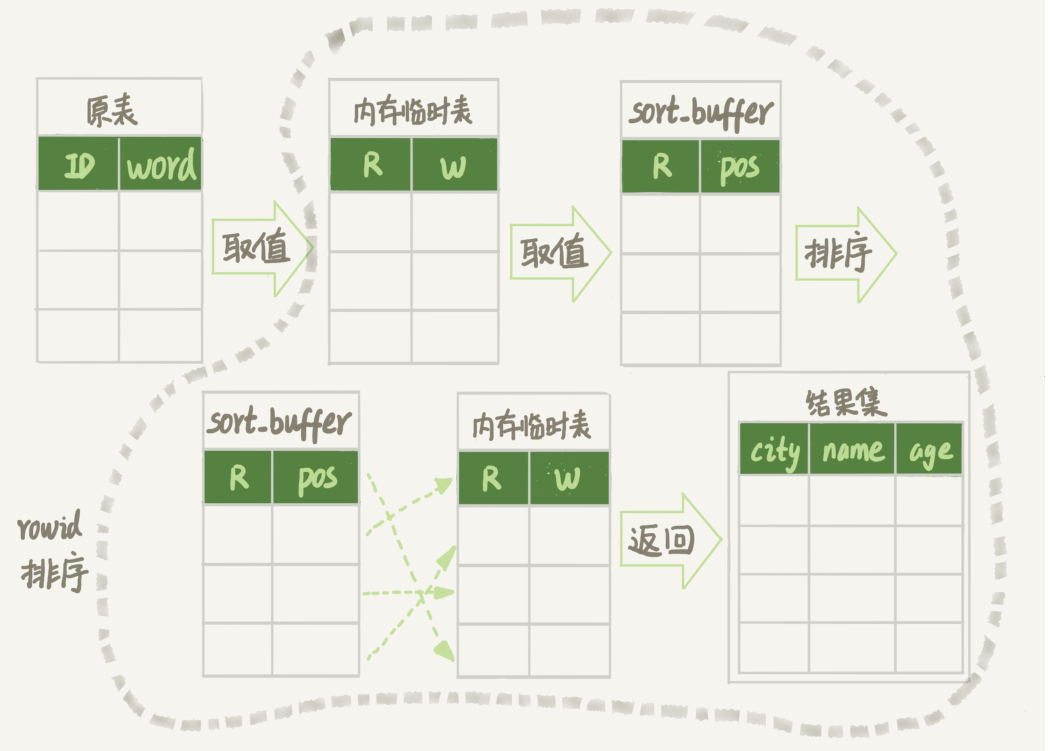
rowid 排序
MySQL 认为排序的单行长度太大 会使用 这个参数 max_length_for_sort_data 来提示MySQL要换一个算法。
过程:因为多了一次索引,排序使用的字段少了,所以数据量就下来了,相应的所需要的临时文件也变少了。
17 | 如何正确地显示随机消息?
场景:
英语学习App 每天 根据用户的级别推荐 随机的单词
随着单词表的变大,这个操作越来越慢
mysql> CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
内存临时表
order by rand() 来实现这个逻辑。
mysql> select word from words order by rand() limit 3;
一个结论:对于 InnoDB 表来说,执行全字段排序会减少磁盘访问,因此会被优先选择。
如果你创建的表没有主键,或者把一个表的主键删掉了,那么 InnoDB 会自己生成一个长度为 6 字节的 rowid 来作为主键。
这也就是排序模式里面,rowid 名字的来历。
实际上它表示的是:每个引擎用来唯一标识数据行的信息。
- 对于有主键的 InnoDB 表来说,这个 rowid 就是主键 ID;
- 对于没有主键的 InnoDB 表来说,这个 rowid 就是由系统生成的;
- MEMORY 引擎不是索引组织表。
在这个例子里面,你可以认为它就是一个数组。因此,这个 rowid 其实就是数组的下标。
order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
磁盘临时表
不是所有的临时表都是内存表。
tmp_table_size 这个配置限制了内存临时表的大小,默认值是 16M。如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表。
磁盘临时表使用的引擎默认是 InnoDB,是由参数 internal_tmp_disk_storage_engine 控制的。
当使用磁盘临时表的时候,对应的就是一个没有显式索引的 InnoDB 表的排序过程。
MySQL 5.6 版本引入的一个新的排序算法,即:优先队列排序算法
但是如果超过了我设置的 sort_buffer_size 大小,所以只能使用归并排序算法,因为要维护的堆太大了。
随机排序方法
mysql> select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; // 在应用代码里面取 Y1、Y2、Y3 值,拼出 SQL 后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
18 | 为什么这些SQL语句逻辑相同,性能却差异巨大?
在 MySQL 中,有很多看上去逻辑相同,但性能却差异巨大的 SQL 语句。对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大。
案例一:条件字段函数操作
更新中…………
小结
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
MySQL 的优化器确实有“偷懒”的嫌疑,即使简单地把 where id+1=1000 改写成 whereid=1000-1 就能够用上索引快速查找,也不会主动做这个语句重写。
因此,每次你的业务代码升级时,把可能出现的、新的 SQL 语句 explain 一下,是一个很好的习惯。
19 | 为什么我只查一行的语句,也执行这么慢?
场景:
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
在里面插入了 10 万行记录
第一类:查询长时间不返回
mysql> select * from t where id=1;
一般碰到这种情况的话,大概率是表 t 被锁住了。
接下来分析原因的时候,一般都是首先执行一下 show processlist 命令,看看当前语句处于什么状态。
然后我们再针对每种状态,去分析它们产生的原因、如何复现,以及如何处理。
-
等 MDL 锁
-
等 flush
-
等行锁
第二类:查询慢
20 | 幻读是什么,幻读有什么问题?
https://www.cnblogs.com/zwtblog/p/15134977.html
https://www.cnblogs.com/zwtblog/p/15132201.html#基本语法
幻读
在同一个事务内,读取到了别人插入的数据,导致前后读出来结果不一致
如何解决幻读?
现在你知道了,产生幻读的原因是,行锁只能锁住行,
但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (GapLock)。
顾名思义,间隙锁,锁的就是两个值之间的空隙。
间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的。
我这里只是一个自己的学习笔记,大家有兴趣一定去看原文!!! 谢谢大家的阅读!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能