JVM-初见
推荐:
JVM的体系结构
简化图:
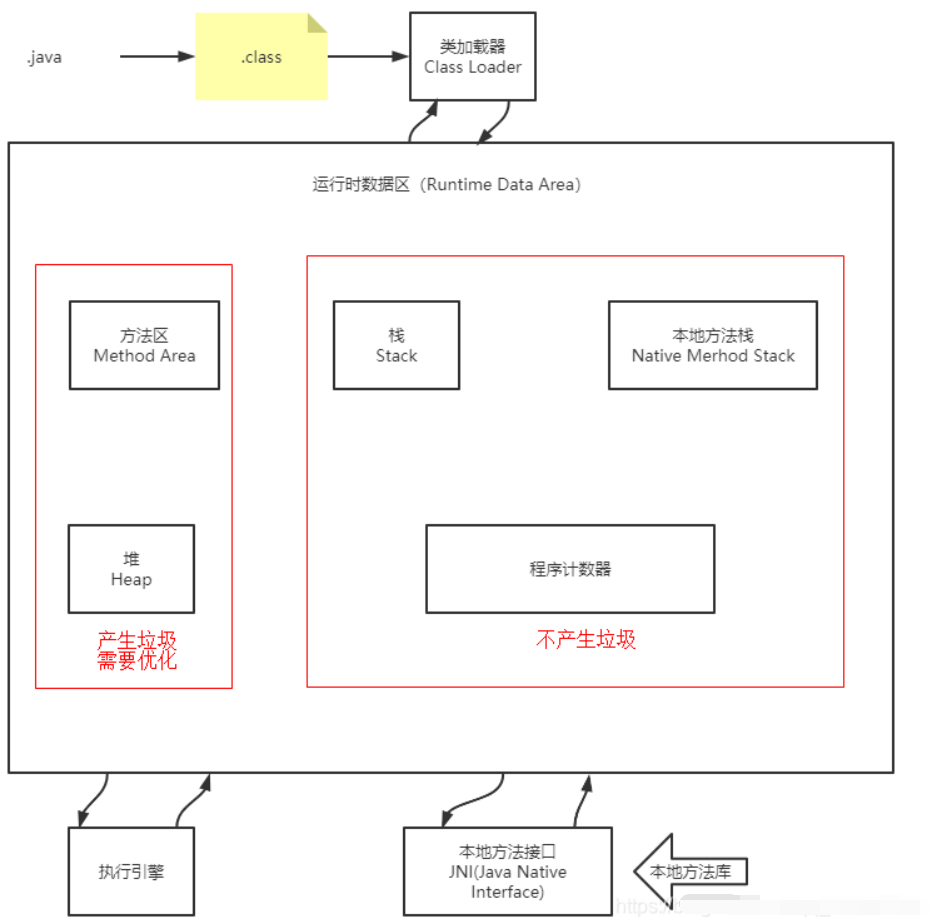
类加载器
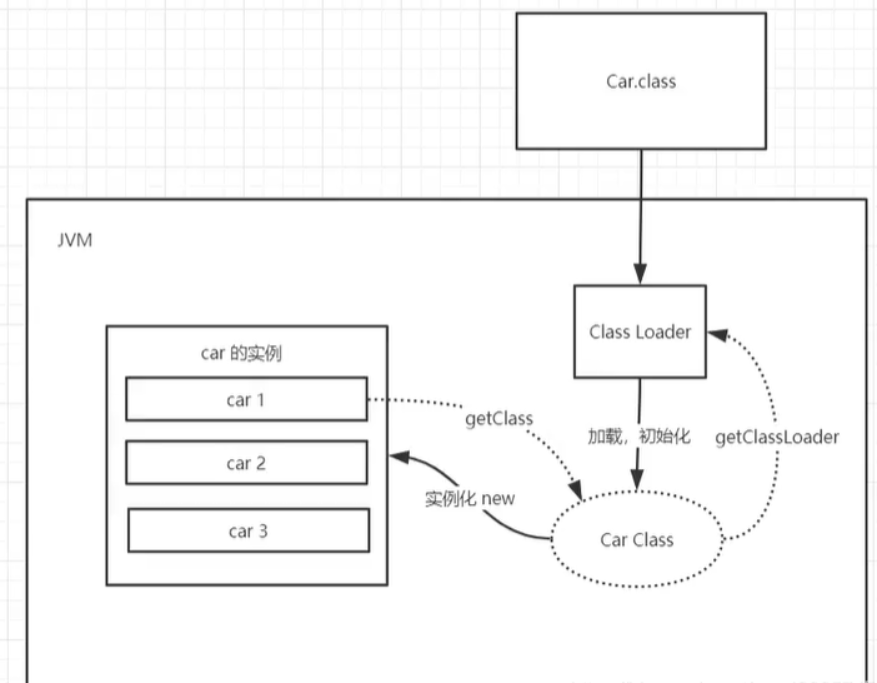
类加载器作用:加载.class文件
类加载流程(三个阶段):
1.加载阶段
将编译好的class文件加载到内存中(方法区),然后会生成一个代表这个类的Class对象。
2.链接阶段
会为静态变量分配内存并设置默认值。
3.初始化阶段
执行类构造器()进行初始化赋值。
java自带的类加载器:
- 启动类加载器(Bootstrap ClassLoader):又名根类加载器或引导类加载器,负责加载%JAVA_HOME%\bin目录下的所有jar包,或者是-Xbootclasspath参数指定的路径,例:rt.jar
- 拓展类加载器(Extension ClassLoader):负责加载%JAVA_HOME%\bin\ext目录下的所有jar包,或者是java.ext.dirs参数指定的路径
- 系统类加载器(Application ClassLoader):又名应用类加载器,负责加载用户类路径上所指定的类库,如果应用程序中没有自定义加载器,那么此加载器就为默认加载器
双亲委派机制
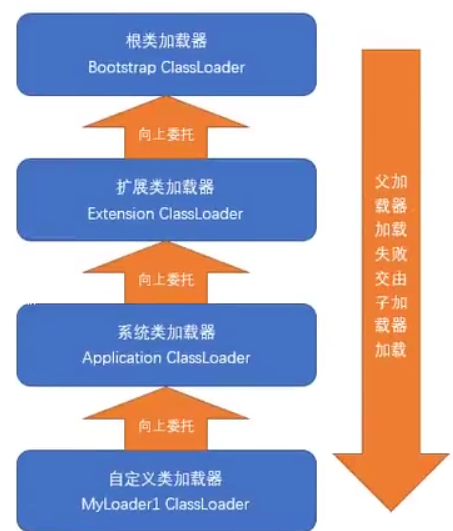
类加载器收到加载请求
1.不会自己先去加载,把请求委托给父类加载器,如果父类加载器还存在其父类加载器,则进一步向上委托,最终将到达顶层的启动类加载器
2.如果父类可以完成加载任务,就成功返回
3.如果完不成,子加载器才会尝试自己去加载
优点:避免重复加载 + 避免核心类篡改
Native
程序中使用:private native void start0();
1.凡是带了native关键字的,说明java的作用范围达不到了,回去调用底层c语言的库!
2.会进入本地方法栈,然后去调用本地方法接口将native方法引入执行
本地方法栈(Native Method Stack)
内存区域中专门开辟了一块标记区域: Native Method Stack,负责登记native方法,
在执行引擎( Execution Engine )执行的时候通过本地方法接口(JNI)加载本地方法库中的方法
本地方法接口(JNI)
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序,
Java在诞生的时候是C/C++横行的时候,想要立足,必须有调用C、C++的程序,
然后在内存区域中专门开辟了一块标记区域: Native Method Stack,负责登记native方法,
在执行引擎( Execution Engine )执行的时候通过本地方法接口(JNI)加载本地方法库中的方法
PC程序计数器
程序计数器: Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针,
指向方法区中的方法字节码(用来存储指向像一条指令的地址, 也即将要执行的指令代码),
在执行引擎读取下一条指令, 是一个非常小的内存空间,几乎可以忽略不计
为什么需要程序计数器?记录要执行的代码位置,防止线程切换重新执行
字节码执行引擎修改程序计数器的值
方法区(Method Area)
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,
简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间。
静态变量(static)、常量(final)、类信息(构造方法、接口定义)(Class)、运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关
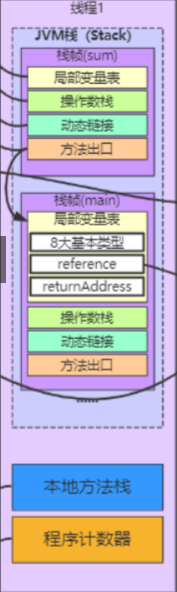
栈
栈:先出后进,每个线程都有自己的栈,栈内存主管程序的运行,生命周期和线程同步,线程结束,栈内存也就是释放。
对于栈来说,不存在垃圾回收问题,一旦线程结束,栈就结束。
栈内存中运行:8大基本类型 + 对象引用 + 实例的方法。
栈运行原理:栈桢
栈满了:StackOverflowError
队列:先进先出(FIFO:First Input First Output)
堆
一个JVM只有一个堆内存,堆内存的大小是可以调节的,
类加载器读取类文件后,一般会把类,方法,常量,变量,我们所有引用类型的真实对象,放入堆中。
堆内存细分为三个区域:
- 新生区(伊甸园区):Young/New
- 养老区old
- 永久区Perm
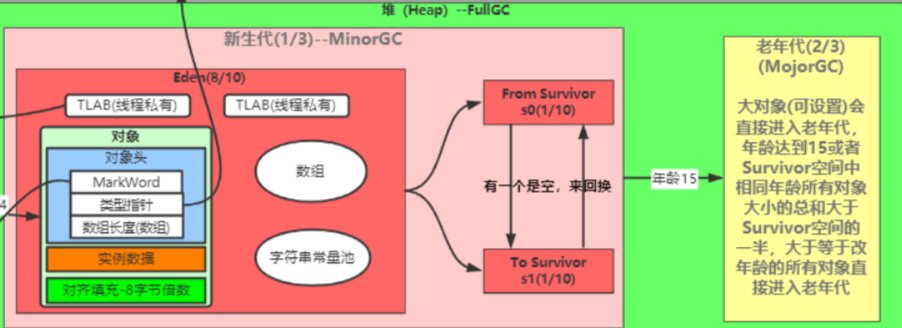
新生区:类的诞生,成长和死亡的地方
分为:
- 伊甸园区:所有对象都在伊甸园区new出来
- 幸存0区和幸存1区:轻GC之后存下来的
老年区(养老区):多次轻GC存活下来的对象放在老年区
真理:经过研究,99%的对象都是临时对象
永久区
这个区域常驻内存的,用来存放IDK自身携带的Class对象,Interface元数据,存储的是Java运行时的一些环境或
类信息,这个区域不存在垃圾回收。
关闭VM虚拟就会释放这个区域的内存,一个启动类,加载了大量的第三方jar包。
Tomcat部署了太多的应用,大量动态生成的反射类,不断的被加载,直到内存满,就会出现0OM;
- jdk1.6之前:永久代,常量池是在方法区。
- jdk1.7永久代,但是慢慢的退化了,去永久代, 常量池在堆中
- jdk1.8之后:无永久代,常量池在元空间
注意:
元空间:逻辑上存在,物理上不存在 ,因为:存储在本地磁盘内,不占用虚拟机内存
默认情况下,JVM使用的最大内存为电脑总内存的四分之一,JVM使用的初始化内存为电脑总内存的六十四分之一.
总结:
- 栈:基本类型的变量,对象的引用变量,实例对象的方法
- 堆:存放由new创建的对象和数组
- 方法区:Class对象,static变量,常量池(常量)
调优工具
public class Test2 {
static String a="111111111111";
public static void main(String[] args) {
while (true){
a=a+ new Random().nextInt(99999999)+new Random().nextInt(99999999);
}
}
}
下载地址:https://www.ej-technologies.com/download/jprofiler/version_92
安装完成后,需要在IDEA中安装插件。
添加参数运行程序:
-Xms1m -Xmx1m -XX:+HeapDumpOnOutOfMemoryError:当出现OOM错误,会生成一个dump文件(进程的内存镜像)
在项目目录下找到dump文件,双击打开 , 可以看到什么占用了大量的内存
常见JVM调优参数
| 配置参数 | 功能 |
|---|---|
| -Xms | 初始堆大小。如:-Xms256m |
| -Xmx | 最大堆大小。如:-Xmx512m |
| -Xmn | 新生代大小。通常为 Xmx 的 1/3 或 1/4。新生代 = Eden + 2 个 Survivor 空间。实际可用空间为 = Eden + 1 个 Survivor,即 90% |
| -XX:NewRatio | 新生代与老年代的比例,如 –XX:NewRatio=2,则新生代占整个堆空间的1/3,老年代占2/3 |
| -XX:SurvivorRatio | 新生代中 Eden 与 Survivor 的比值。默认值为 8。即 Eden 占新生代空间的 8/10,另外两个 Survivor 各占 1/10 |
| -XX:+PrintGCDetails | 打印 GC 信息 |
| XX:+HeapDumpOnOutOfMemoryError | 让虚拟机在发生内存溢出时 Dump 出当前的内存堆转储快照,以便分析用 |
常见垃圾回收算法
引用计数算法
原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。
垃圾回收时,只用收集计数为 0 的对象。此算法最致命的是无法处理循环引用的问题。
复制算法
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。
垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。
此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理。
优点:不会出现碎片化问题
缺点:需要两倍内存空间,浪费

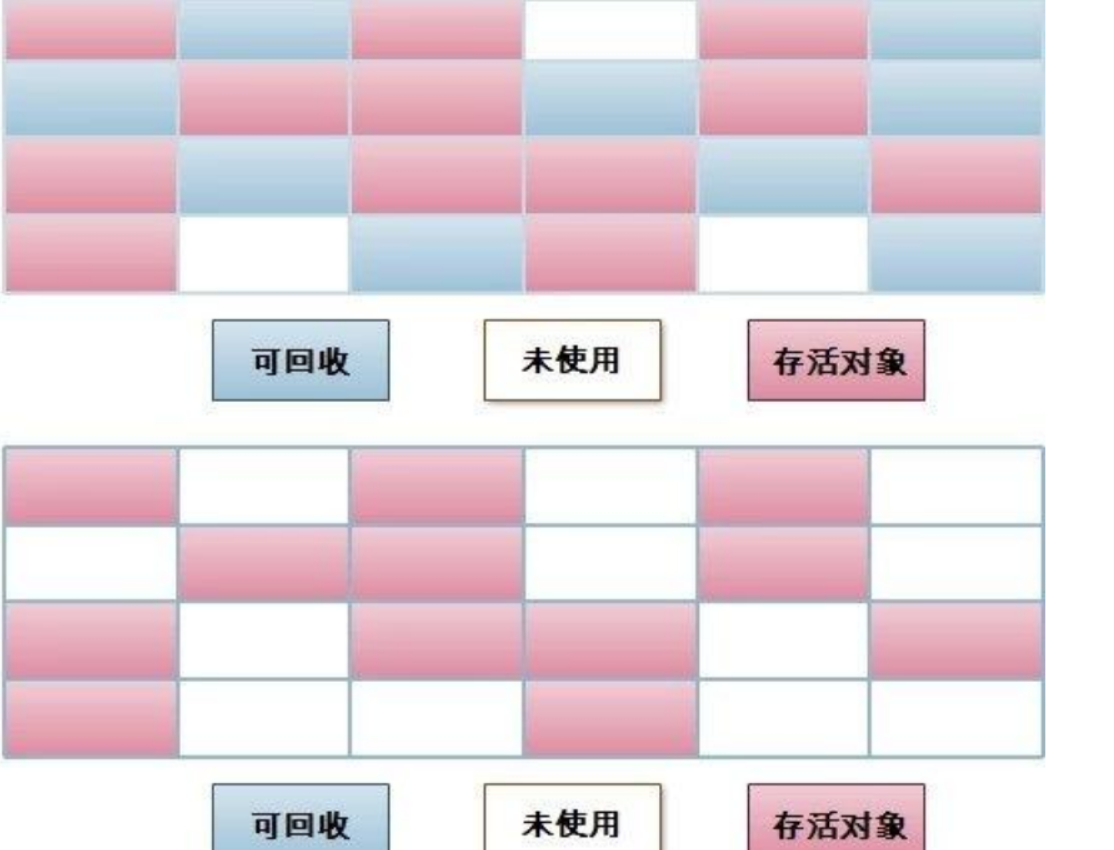
标记-清除算法
此算法执行分两阶段。
第一阶段从引用根节点开始标记可回收对象,
第二阶段遍历整个堆,把未标记的对象清除。
优点:不会浪费内存空间
缺点:此算法需要暂停整个应用,同时,会产生内存碎片
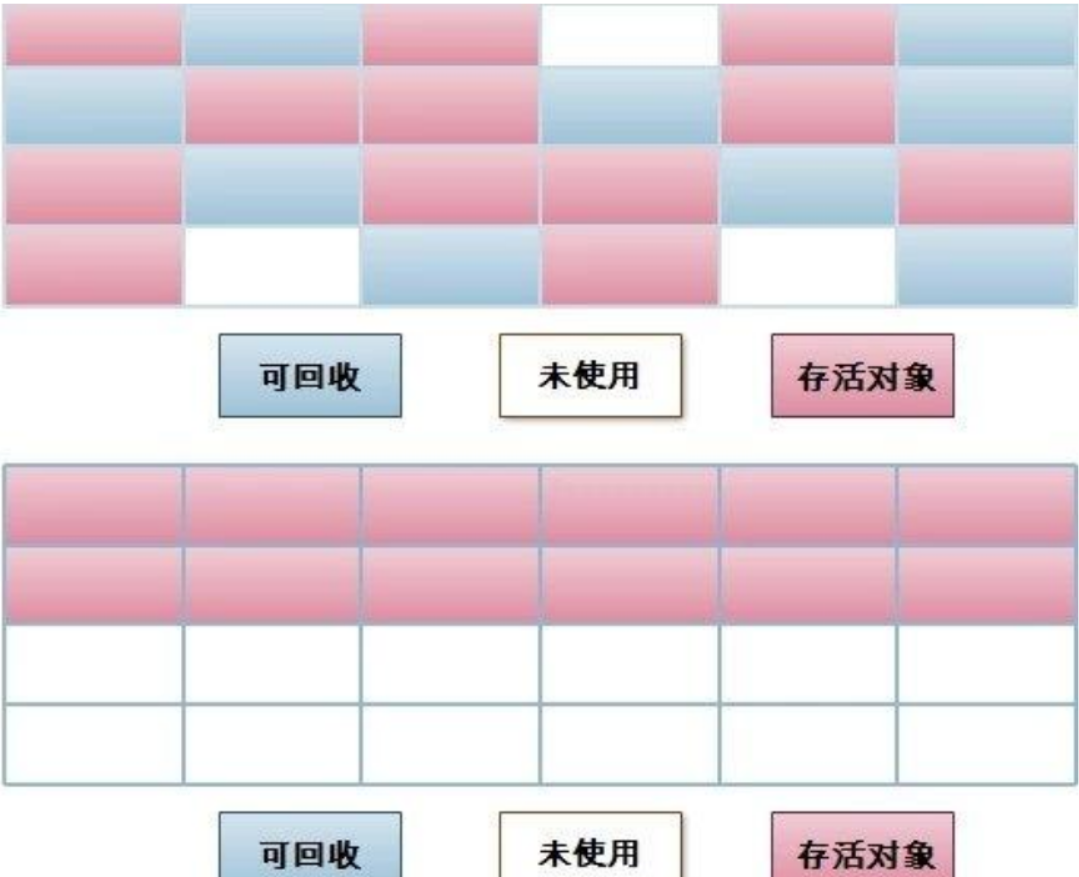
标记-压缩算法
此算法结合了 " 标记-清除 ” 和 “ 复制 ” 两个算法的优点。
也是分两阶段,
第一阶段从根节点开始标记所有可回收对象,
第二阶段遍历整个堆,清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。
此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
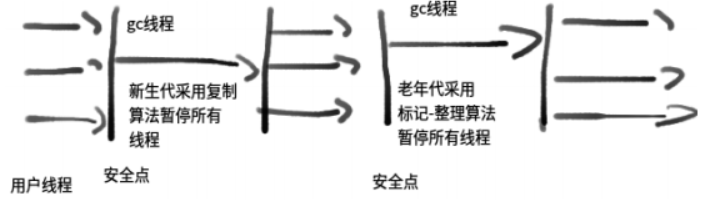
分代回收策略

1.绝大多数刚刚被创建的对象会存放在Eden区
2.当Eden区第一次满的时候,会触发MinorGC(轻GC)。首先将Eden区的垃圾对象回收清除,并将存活的对象复制到S0,此时S1是空的。
3.下一次Eden区满时,再执行一次垃圾回收,此次会将Eden和S0区中所有垃圾对象清除,并将存活对象复制到S1,此时S0变为空。
4.如此反复在S0和S1之间切换几次(默认15次)之后,还存活的对象将他们转移到老年代中。
5.当老年代满了时会触发FullGC(全GC)
MinorGC
- 使用的算法是复制算法
- 年轻代堆空间紧张时会被触发
- 相对于全收集而言,收集间隔较短
FullGC
- 使用的算法一般是标记压缩算法
- 当老年代堆空间满了,会触发全收集操作
- 可以使用 System.gc()方法来显式的启动全收集
- 全收集非常耗时
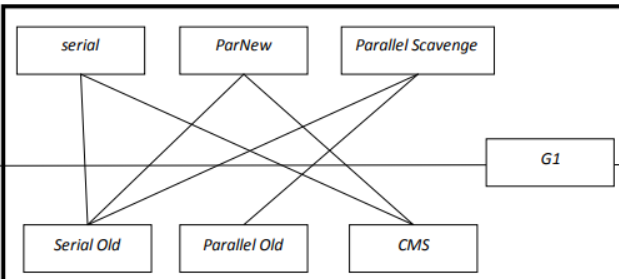
垃圾收集器
垃圾回收器的常规匹配:
串行收集器(Serial)
Serial 收集器是 Hotspot 运行在 Client 模式下的默认新生代收集器, 它的特点是:单线程收集,但它却简单而高效
并行收集器(ParNew)
ParNew 收集器其实是前面 Serial 的多线程版本
Parallel Scavenge 收集器
与 ParNew 类似,Parallel Scavenge 也是使用复制算法,也是并行多线程收集器。
但与其他收集器关注尽可能缩短垃圾收集时间不同,Parallel Scavenge 更关注系统吞吐量,
系统吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本, 同样是单线程收集器,使用 “ 标记-整理 ” 算法
Parallel Old 收集器
Parallel Old 是 Parallel Scavenge 收集器的老年代版本, 使用多线程和 “ 标记-整理 ” 算
法,吞吐量优先
CMS 收集器(Concurrent Mark Sweep)
CMS是一种以获取最短回收停顿时间为目标的收集器(CMS又称多并发低暂停的收集器),
基于 ” 标记-清除 ” 算法实现, 整个 GC 过程分为以下 4 个步骤:
初始标记(CMS initial mark)
并发标记(CMS concurrent mark: GC Roots Tracing 过程)
重新标记(CMS remark)
并发清除(CMS concurrent sweep: 已死对象将会就地释放, 注意:此处没有压缩)
G1 收集器
G1将堆内存 “ 化整为零 ” ,将堆内存划分成多个大小相等独立区域(Region),
每一个Region都可以根据需要,扮演新生代的Eden空间、Survivor空间,或者老年代空间。
收集器能够对扮演不同角色的Region采用不同的策略去处理,这样无论是新创建的对象还是已经存活了一段时间、熬过多次收集的旧对象都能获取很好的收集效果。
为什么要垃圾回收时要设计STW(stop the world)?
如果不设计STW,可能在垃圾回收时用户线程就执行完了,堆中的对象都失去了引用,全部变成了垃圾,索性就
设计了STW,快速做完垃圾回收,再恢复用户线程运行。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能