缓存穿透,击穿,雪崩详解
前言
缓存在大并发系统中的重要作用不言而喻。缓存属于内存操作,微秒或毫秒级别。
在互联网公司绝对绕不过这个缓存。

缓存穿透
缓存穿透的概念很简单,用户想要查询一个数据发现redis内存数据库没有,
也就是缓存没有命中,于是向持久层数据库查询。
发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。
这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
为了避免缓存穿透其实有很多种解决方案。下面介绍几种 :
将空数据存入缓存
if(list == null){
// key value 有效时间时间单位
redisTemplate . opsForValue( ). set( navKey,null,10, T imeUnit. MINUTES );
}else{
redisTemplate . opsForValue( ). set( navKey, result,7 ,TimeUnit. DAYS);
}
但是这个需要注意一点:空值的过期时间不能设置的太长 。
因为后面可能数据库中会添加这个数据,那么就会和缓存有不一致。
布隆过滤器
不存在于布隆过滤器中的KEY必定不存在于后置的缓存中 。
应用场景:如何查看一个东西是否在有大量数据的池子里面。
在Redisson中使用布隆过滤器API
引入Redisson的依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.1</version>
</dependency>
使用Redisson中的布隆过滤器API:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
RedissonClient redissonClient = Redisson.create(config);
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("ipBlockList");
// 第一个参数expectedInsertions代表期望插入的元素个数,第二个参数falseProbability代表期望的误判率,小数表示。
bloomFilter.tryInit(100000L, 0.03D);
bloomFilter.add("127.0.0.1");
bloomFilter.add("192.168.1.1");
System.out.println(bloomFilter.contains("192.168.1.1")); // true
System.out.println(bloomFilter.contains("192.168.1.2")); // false
}
}
原理:
-
一个超大的位数组
-
几个哈希函数进行判断
-
空间效率和查询效率高
-
不会漏判,但是有一定的误判率
一句话简单概括布隆过滤器的基本功能:「不存在则必不存在,存在则不一定存在。」
代码简单实现:
import java.util.BitSet;
//一个Bitset类创建一种特殊类型的数组来保存位值。BitSet中数组大小会随需要增加。
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] {7, 11, 13, 31, 37, 61,};
//一个超大的位数组
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = " stone2083@yahoo.cn ";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
//不会漏判,但是有一定的误判率
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
//几个哈希函数进行判断
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}
缓存击穿
大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。
于是就会导致: 在缓存失效瞬间,有大量线程构建缓存,导致后端负载加剧,甚至可能让系统崩溃。
所以问题就在于限制处理线程的数量,即KEY的更新操作添加全局互斥锁。
互斥锁
在缓存失效时(判断拿出来的值为空),不是立即去load db,而是
- 先使用(Redis的SETNX)去set一个mutex key
- 当操作返回成功时,再load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
mutex 互斥
使用 redis 分布式锁的伪代码,仅供参考:
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
优点:
-
思路简单
-
保证一致性
缺点:
-
代码复杂度增大
-
存在死锁的风险
-
存在线程池阻塞的风险
提前 使用互斥锁(mutex key)
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。
当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。
然后再从数据库加载数据并设置到cache中。伪代码如下:
V = memcache.get(key);
if (v == null) {
if (memcache.add(key_ mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_ mutex);
} else {
sleep(50);
retry();
}
} else {
if (v.timeout <= now()) {
if (memcache.add(key_ mutex, 3 * 60 * 1000) == true) {
// extend the t imeout for other threads
v.timeout += 3 * 60 * 1000
memcache.set(key, v, KEY_ TIMEOUT * 2);
// load the latest value from db
V = db.get(key);
v.timeout = KEY_ TIMEOUT;
memcache.set(key, value, KEY_ TIMEOUT * 2);
memcache.delete(key_ mutex);
} else {
sleep(50);
retry();
}
}
}
定时任务更新热点key
使用异步线程负责维护缓存的数据,定期或根据条件触发更新,这样就不会触发更新。
设置key 不失效
这种方式适用于比较极端的场景,例如流量特别特别大的场景,使用时需要考虑业务能接受数据不一致的时间。
资源保护(限流)
采用netflix的hystrix,可以做资源的隔离保护主线程池。
缓存雪崩
缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是一个热点 key,缓存雪崩是一组热点 key。
缓存雪崩,是指在某一一个时间段,缓存集中过期失效。
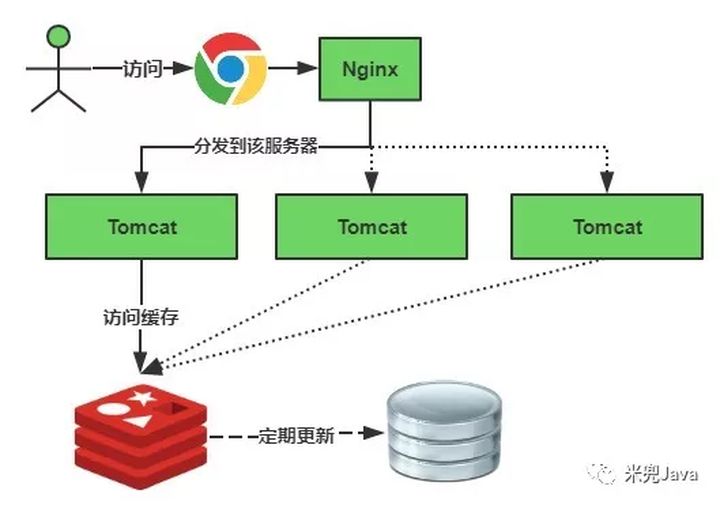
缓存失效瞬间示意图如下:

缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。
简单解决方法:
在原有失效时间基础上增加一个随机值,比如1~5分钟的随机,这样每个缓存的过期时间重复率就会降低,集体失效概率也会大大降低。
或者
数据库有限流方案,当达到了限流设置的参数,那么就会拒绝请求,从而保护了后台db。
或者
缓存预热
-使用http接口预热错峰加载
或者
加锁排队
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。
假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。
同样会导致用户等待超时,这是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题,线程还会被阻塞,用户体验很差!
因此,在真正的高并发场景下很少使用!
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}
随机值
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//缓存标记
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//获取缓存值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未过期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//这里一般是 sql查询数据
cacheValue = GetProductListFromDB();
//日期设缓存时间的2倍,用于脏读
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
}
总之,方法很多,具体情况具体分析
1.更多的页面静态化处理
2.构建多级缓存架构
Nginx缓存+redis缓存+ehcache缓存
3.检测Mysql严重耗时业务进行优化
4.对数据库的瓶颈排查:例如超时查询、耗时较高事务等
灾难预警机制
监控redis服务器性能指标
CPU占用、CPU使用率
内存容量
查询平均响应时间
线程数
5.限流、降级
短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
6.LRU与LFU切换
7.数据有效期策略调整
根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟
过期时间使用固定时间+随机值的形式,稀释集中到期的key的数量
8.超热数据使用永久key
9.定期维护(自动+人工)
对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时
10.加锁
拓展
LRU与LFU
LRU,即:最近最少使用淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的页面。
LFU,即:最不经常使用淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的页面。
参考链接
https://juejin.cn/post/6844903989654355976
https://juejin.cn/post/6979886456730812446
https://juejin.cn/post/6844904173725548557
https://zhuanlan.zhihu.com/p/58224918
https://zhuanlan.zhihu.com/p/199175706
https://zhuanlan.zhihu.com/p/75588064
https://zhuanlan.zhihu.com/p/145671483
https://zhuanlan.zhihu.com/p/359118610
https://www.jianshu.com/p/cae51ad2486c
https://blog.csdn.net/u013630349/article/details/102543169

