
ABtest 原理及用法总结
一、A/B test 目的
检验产品或活动方案调整优化在某指标上是否有显著改善效果。检验构建实验组和对照组。之后,在后期的观察中,通过一些统计方法,验证效果的差异性是否显著。
二、A/B test 原理
两独立样本t检验(注意区分计算不同:两总体均值检验、两总体率值检验)
三、A/B test 流程
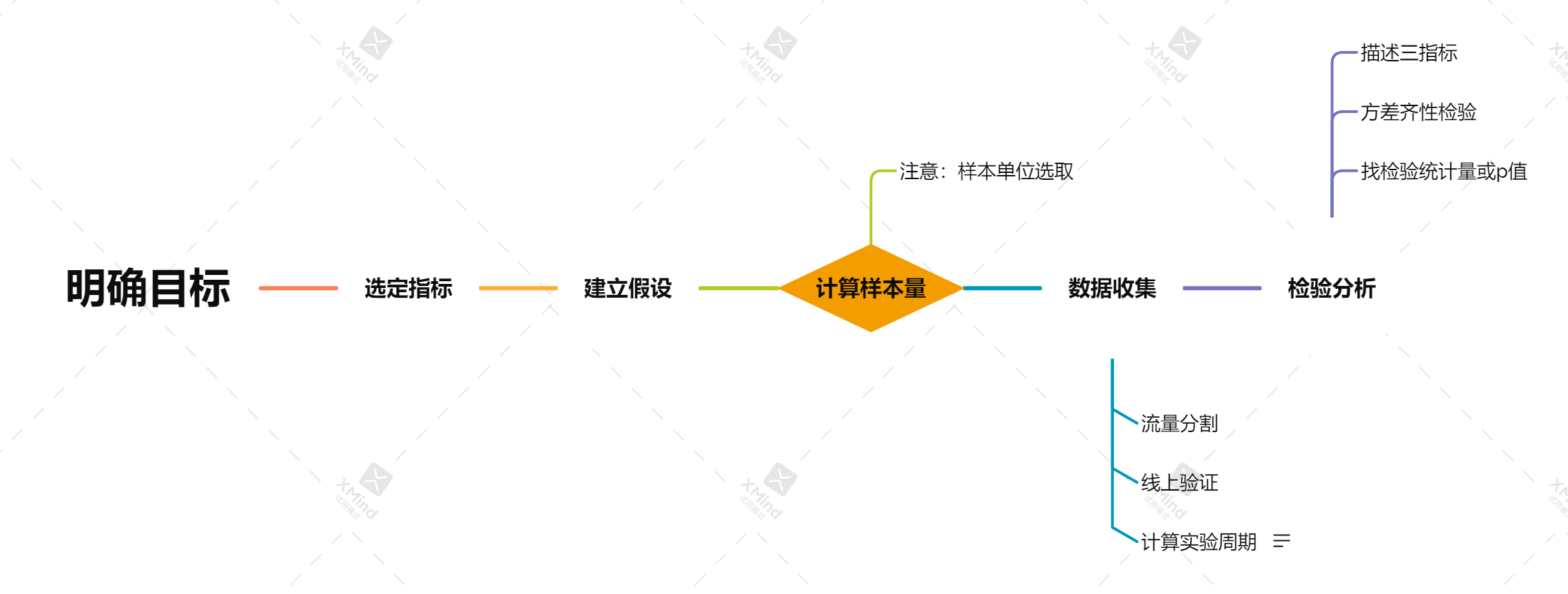
①明确目标:验证实验相比对照组是否有显著性差异变化(提升或下降),如点击率、转化率、人均订单量等等。
②选定指标:根据实验目的和业务需求选定实验结果好坏的评价指标。
一般分层级,一个核心指标+多个观察指标。
核心指标用来计算需要的样本量,以及度量我们这次实验的效果。
观察指标则用来度量,该实验对其他数据的影响(比如对大盘留存的影响,对网络延迟的影响等等)
③建立假设:建立零假设和备选假设。
零假设一般是实验改动没有效果,备选假设是有效果,即实验组相比对照组有显著性差异。
④计算样本量:选取显著性水平、功效值,根据公式计算实验组所需最小样本量。
样本量与变异系数、功效(一般要求0.8~0.95)成正比,与提升度(一般小于0.05)成反比。
因此,当延长可接受的实验周期累计样本量还是不够时,可以通过以下2种思路来降低样本量要求。
(1)选择变异系数较小的衡量指标;
(2)降低功效值要求,放宽提升度 。
注意:以下方法代入σ² 的是A和B的2个方差组合(点这里了解其它3种两组率比较样本量计算方法),相当于2倍方差,因此计算的也是A、B两组总共需要的最小样本量,假设检验时每组只需一半的样本量即可。
 ,
,
注意:通常以用户粒度来作为实验单位。
(1)用户粒度:这个是最推荐的,即以一个用户的唯一标识来作为实验样本。好处是符合AB测试的分桶单位唯一性,不会造成一个实验单位处于两个分桶,造成的数据不置信。
(2)设备粒度:以一个设备标识为实验单位。相比用户粒度,如果一个用户有两个手机,那么也可能出现一个用户在两个分桶中的情况,所以也会造成数据不置信的情况。
(3)行为粒度:以一次行为为实验单位,也就是用户某一次使用该功能,是实验桶,下一次使用可能就被切换为基线桶。会造成大量的用户处于不同的分桶。强烈不推荐这种方式。
⑤收集数据:网站或APP的访问者将被随机分配对照组和实验组,上线验证,并收集数据。
流量分割:有分流和分层两种思路。如果要同时上线多个实验,分流流量不够切,或者为了达到最小样本量需要很长的实验周期怎么办?这也不现实。此时就可以考虑分层的思路,就是将同一批用户,不停的随机后,处于不同的桶。也就是说,一个用户会处于多个实验中,只要实验之间不相互影响,我们就能够无限次的切割用户。

实验周期:最小样本量 / 实验桶天均流量 。
注意:在做AB测试时,尽量设定一个测试生效期,这个周期一般是用户的一个活跃间隔期。
线上验证:(1)验证实验改动是否生效 ;(2)验证必须分流时,同一用户是否在一个桶里,否则数据就不置信了。
⑥检验分析:达到最小样本量,查看看显著性结果、功效。最好耐心观察一段时间等结果稳定时再得出最终结果。
(1)描述三指标
(2)方差齐性检验
(3)比较t检验统计量或p值(一般,绝对值指标用t检验,”相对值指标“,即比率用Z检验)
四、A/B test简单案例
实例背景简述:
某司「猜你想看」业务接入了的新推荐算法,新推荐策略算法开发完成后,在全流量上线之前要评估新推荐策略的优劣。所用的评估方法是A/B test,具体做法是在全量中抽样出两份小流量,分别走新推荐策略分支和旧推荐策略分支,通过对比这两份流量下的指标(这里按用户点击衡量)的差异,可以评估出新策略的优劣,进而决定新策略是否全适合全流量。
实例A/B test步骤:
选定指标:CTR
实验组:新的推荐策略B
建立假设:新的推荐策略实验组B可以带来更多的用户点击。
计算样本量:此处和大部分公司一样缺少这一步。
收集数据:实验组B数据为新的策略结果数据,对照组A数据为旧的策略结果数据。均为伪造数据。
检验分析(Python):利用 python 中的 scipy.stats.ttest_ind 做关于两组数据的双边 t 检验,结果比较简单。但是做大于或者小于的单边检测的时候需要将双边检验计算出来的 p-value 除于2 取单边的结果与显著性水平α=0.05进行比较。
注:大部分公司也只做了收集数据后三个描述指标的比较,未作假设检验。
我们先看看实验组B和对照组A均值情况:
很明显,实验组B的均值 >对照组A的均值,但这就能说明实验组B可以带来更多的业务转化吗?还是仅仅是由于一些随机因素造成的?
1 from scipy import stats 2 import numpy as np 3 import numpy as np 4 import seaborn as sns 5 6 A = np.array([ 1, 4, 2, 3, 5, 5, 5, 7, 8, 9,10,18]) 7 B = np.array([ 1, 2, 5, 6, 8, 10, 13, 14, 17, 20,13,8]) 8 print('策略A的均值是:',np.mean(A)) 9 print('策略B的均值是:',np.mean(B))
1 Output: 2 策略A的均值是:6.416666666666667 3 策略B的均值是:9.75
由于存在抽样误差,为了更加科学就需要进一步做个假设检验。因为我们是希望实验组B效果更好,所以设置:
(1)原假设H0:B<=A
(2)备择假设H1:B>A (一般研究者欲支持的结论设为备择假设,其反面作为原假设),即单侧检验
scipy.stats.ttest_ind(x,y)默认验证的是x.mean()-y.mean()这个假设。为了在结果中得到正数,计算如下:
stats.ttest_ind(B,A,equal_var= False)
1 output: 2 Ttest_indResult(statistic=1.556783470104261, pvalue=0.13462981561745652)
根据 scipy.stats.ttest_ind(x, y) 文档的解释,这是双边检验的结果。
为了得到单边检验的结果,需要将计算出来的 p-value 除于2 取单边的结果与显著性水平α进行比较。
显著性水平α选定取0.05,计算的 p-value=0.13462981561745652,p/2 > α=0.05,未落在拒绝域,所以不能够拒绝原假设,接受备择假设H1:B>A成立。即暂时还不能够认为实验组B就一定能带来多的用户点击。
五、A/B test需要注意点:
1、先验性:通过低代价,小流量的实验,在推广到全流量的用户。
- AB测试一定要从小流量逐渐放大
如果上线一个功能,直接流量开到50%去做测试,那么如果数据效果不好,或者功能意外出现bug,对线上用户将会造成极大的影响。所以,建议一开始从最小样本量开始实验,然后再逐渐扩大用户群体及实验样本量。
2、并行性:不同版本、不同方案在验证时,要保证其他条件都一致。
- 用户属性一定要一致
如果上线一个实验,我们对年轻群体上线,年老群体不上线,实验后拿着效果来对比,即使数据显著性检验通过,那么,实验也是不可信的。因为AB测试的基础条件之一,就是实验用户的同质化。即实验用户群,和非实验用户群的 地域、性别、年龄等自然属性因素分布基本一致。
- 一定要在同一时间维度下做实验
举例:如果某一个招聘app,年前3月份对用户群A做了一个实验,年中7月份对用户群B做了同一个实验,结果7月份的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
分流
- 上线后验证改动对用户是否生效
用户如果被分组后,未触发实验,我们需要排除这类用户。因为这类用户本身就不是AB该统计进入的用户(这种情况较少,如果有,那在做实验时打上生效标签即可)
- 上线后验证用户不能同时处于多个组
如果用户同时属于多个组,那么,一个是会对用户造成误导(如每次使用,效果都不一样),一个是会对数据造成影响,我们不能确认及校验实验的效果及准确性
- 如果多个实验同时进行,一定要对用户分层+分组
比如,在推荐算法修改的一个实验中,我们还上线了一个UI优化的实验,那么我们需要将用户划分为4个组:A、老算法+老UI,B、老算法+新UI,C、新算法+老UI,D、新算法+新UI,因为只有这样,我们才能同时进行的两个实验的参与改动的元素,做数据上的评估
3、科学性:是指不能直接用均值转化率、均值点击率等来进行AB test决策,应该通过置信区间、假设检验、收敛程度等数学原理进一步科学验证得出结论。
- AB测试最后得出结论B组相对于A组某指标提升了多少一般是一个区间,比如说(1.4,1.9)或者(1.5%,1.7%)
- 如果实验组最小样本量不足该怎么办
(1)优先考虑,流量分割时通过扩大分配的比例,拉长时间周期,累计获得理想的最小样本量。
(2)减少最小样本量。通过(a)更改指标选择变异系数小的指标,或(b)降低功效值要求、放大提升度来实现。
- 是否需要上线第一天就开始看效果?
达到最小样本量时,可以查看显著性结果、功效。最好继续耐心观察一段时间,结果稳定时得出最终结果。
另,由于AB-Test,会影响到不同的用户群体,所以,我们在做AB测试时,尽量设定一个测试生效期,这个周期一般是用户的一个活跃间隔期。如招聘用户活跃间隔是7天,那么生效期为7天,如果是一个机酒app,用户活跃间隔是30天,那生效期为30天
- 实际情况(如何改进)
样本量计算这步,可能在部分公司不会使用,更多的是偏向经验值;如果我们对总体均值区间估计范围精度要求不高,最小样本量计算其实不是一个必须的过程,当然样本量越大这个范围就越精确,但同时我们付出的时间成本也会越高。
假设检验这一步,部分公司可能也不会使用。
大部分公司,都会有自己的AB平台,产运更偏向于平台上直接测试,最后在一段时间后查看指标差异。
对于以上两种情况,我们需要计算不同流量分布下的指标波动数据,把相关自然波动下的阈值作为波动参考,这样能够大概率保证AB实验的严谨及可信度。
4、其它
- 网络效应
这种情况通常出现在社交网络,以及共享经济场景(如滴滴)。举个例子:如果微信改动了某一个功能,这个功能让实验组用户更加活跃。但是相应的,实验组的用户的好友没有分配到实验组,而是对照组。但是,实验组用户更活跃(比如更频繁的发朋友圈),作为对照组的我们也就会经常去刷朋友圈,那相应的,对照组用户也受到了实验组用户的影响。本质上,对照组用户也就收到了新的功能的影响,那么AB实验就不再能很好的检测出相应的效果。
解决办法:从地理上区隔用户,这种情况适合滴滴这种能够从地理上区隔的产品,比如北京是实验组,上海是对照组,只要两个城市样本量相近即可。或者从用户上直接区隔,比如我们刚刚举的例子,我们按照用户的亲密关系区分为不同的分层,按照用户分层来做实验即可。但是这种方案比较复杂,建议能够从地理上区隔,就从地理上区隔。
- 学习效应
这种情况就类似,产品做了一个醒目的改版,比如将某个按钮颜色从暗色调成亮色。那相应的,很多用户刚刚看到,会有个新奇心里,去点击该按钮,导致按钮点击率在一段时间内上涨,但是长时间来看,点击率可能又会恢复到原有水平。反之,如果我们将亮色调成暗色,也有可能短时间内点击率下降,长时间内又恢复到原有水平。这就是学习效应。
解决办法:一个是拉长周期来看,我们不要一开始就去观察该指标,而是在一段时间后再去观察指标。通过刚刚的描述大家也知道,新奇效应会随着时间推移而消失。另一种办法是只看新用户,因为新用户不会有学习效应这个问题,毕竟新用户并不知道老版本是什么样子的。
- 多重检验放大犯错概率问题
这个很好理解,就是如果我们在实验中,不断的检验指标是否有差异,会造成我们的结果不可信。也就是说,多次检验同一实验导致第一类错误概率上涨;同时检验多个分组导致第一类错误概率上涨。
举个例子:
出现第一类错误概率:P(A)=5%
检验了20遍:P(至少出现一次第一类错误)
=1-P(20次完全没有第一类错误)
=1- (1−5%) ^20
=64%
也就是说,当我们不断的去检验实验效果时,第一类错误的概率会直线上涨。所以我们在实验结束前,不要多次去观察指标,更不要观察指标有差异后,直接停止实验并下结论说该实验有效。
【参考】
【3】各类统计检验方法大汇总
【4】统计学知识系列:一篇搞懂假设检验(ps:精炼的应用总结,检验统计量选择逻辑有问题)
【5】史上最全AB-Test知识点(ps:最好的实践应用总结)
【7】AB实验中最小样本量的计算 /样本量估算(一):随机对照试验(两组率)比较的样本量计算方法
https://mp.weixin.qq.com/s?__biz=MzU5NDgyMjc0OQ==&mid=2247484789&idx=1&sn=633220ade76cf9fa3cf5192553bb56b0&chksm=fe7a1647c90d9f51058a853e71ffc2ceefd5b061031713baa84700a53b3db391d740ca3753b8&mpshare=1&scene=24&srcid=&sharer_sharetime=1573050285889&sharer_shareid=eb0f35d36ca2c67ef08aee2506048ecf&ascene=14&devicetype=iOS12.4.1&version=18000f2e&nettype=WIFI&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&fontScale=100&exportkey=AXM2YsKg23Rr7ADoRjtMe1M%3D&pass_ticket=sMwSw%2F%2FPv3sZ8lD35yaIOREYv6RLIXBLsoHZEK9ryJyElrniTuKEr4Uw5zs1iQD7&wx_header=1
https://mp.weixin.qq.com/s?__biz=MzAwOTYyMDY3OQ==&mid=2650378381&idx=2&sn=0a9eef1ac32853e560f00e34bdd41eaa&chksm=8351ed25b42664330c302495cc81bd0853090e25e28eef840a7e6c760555b3145a2d08f22b03&scene=21#wechat_redirect

 浙公网安备 33010602011771号
浙公网安备 33010602011771号