
用户研究 |KANO(卡诺)模型
KANO模型实操过程
一、KANO模型作用:
是对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
根据此模型可以分析出产品某功能/服务归属哪一种属性,具有怎样的特征。从而进一步明确该功能开发的优先级。
二、KANO模型原理
在卡诺模型中,将产品和服务的质量特性分为四种类型:⑴必备属性;⑵期望属性;⑶魅力属性;⑷无差异属性,(5)反向属性。

(1)必备属性:当优化此需求,用户满意度不会提升,当不提供此需求,用户满意度会大幅降低;
最下面一条曲线叫“基础(功能)”,没有的时候,用户对产品无法接受,有了,也不会夸奖你,用户会觉得这是理所应当的。所以,必须做,也叫“must have”,不管成本有多高都得做。在功能列表里,这种功能就不用参与pk了,比如手里的打电话、发短信,当然,也许多年以后不是了。
(2)期望属性:当提供此需求,用户满意度会提升,当不提供此需求,用户满意度会降低;
(3)魅力属性:用户意想不到的,如果不提供此需求,用户满意度不会降低,但当提供此需求,用户满意度会有很大提升;
最上面的曲线也叫“亮点(功能)”,没有的时候,用户也想不到,有了以后,用户会赞不绝口,wow,惊喜。比如手机的指纹识别,解决了安全(更多更复杂的密码、证书、外挂硬件等等)和方便这一对矛盾的需求。亮点功能的特性,使得我们在选择“做哪个”的时候有一个诀窍——挑选成本低的亮点功能去实现,比如苹果电脑的呼吸灯?不要费太大的功夫去做一个亮点——除非你在大公司的里的“研究中心、创新中心”。你认为的亮点到底能不能点亮用户,是要运气的,相比下面一种功能,它更像早期投资。
(4)无差异属性:无论提供或不提供此需求,用户满意度都不会有改变,用户根本不在意;
(5)反向属性:用户根本都没有此需求,提供后用户满意度反而会下降。
基础功能只能消除不满,不能带来满意,亮点的重要性在于,有了,才有口碑传播的概念,没有亮点的产品,只会有人用,没有口碑。
一个功能的类别,随着时间会变,一般从亮点到期望到基本,比如手机的彩屏、和旋铃声,在十几年前还是亮点,今天已经没人再提。所谓饱暖思淫欲,由俭入奢易……这也是人类创新进步的源泉。
三、卡诺模型应用——问卷设计与数据处理
KANO问卷对每个功能/服务都由正向和负向两个问题构成,分别测量用户在面对存在或不存在某项功能/服务时的反应。
需要注意:
① KANO问卷中与每个功能点相关的题目都有正反两个问题,正反问题之间的区别需注意强调,防止用户看错题意;
② 在题目数量上,当功能点个数比较多(大于5个时)或功能点的差异不大时,有相似之处时,建议对用户进行分组,每个用户最多回答5个功能点,且尽量是区分度大的功能点。
③ 在题型上,建议优先选择单选题,避免使用阵列题,因为阵列题下,用户更容易乱答或者回答得没有区分度,导致最终各个功能点没有区分度,如都属于期望功能。
② 功能的解释:简单描述该功能点,确保用户理解;
③ 选项说明:由于用户对“我很喜欢”“理应如此”“无所谓”“勉强接受”“我很不喜欢”的理解不尽相同,因此需要在问卷填写前给出统一解释说明,让用户有一个相对一致的标准,方便填答。
- 我很喜欢:让你感到满意、开心、惊喜。
- 它理应如此:你觉得是应该的、必备的功能/服务。
- 无所谓:你不会特别在意,但还可以接受。
- 勉强接受:你不喜欢,但是可以接受。
- 我很不喜欢:让你感到不满意。
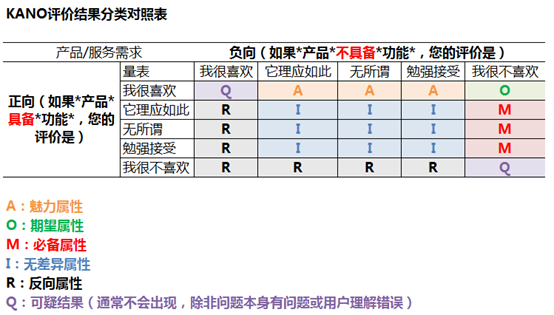
因此在编制问卷的时候,对每个项目都要有正反两道题来测,比如,“如果在微信中加入朋友圈功能,您怎样评价?”对应“如果在微信中去掉朋友圈功能,您怎样评价?”均提供五个选项:我很喜欢、它理应如此、无所谓、勉强接受、我很不喜欢
那么每个用户对于某一个项目的态度必然落入下图表中的某个格子。而对所有的用户来说,共有5*5即25种可能,统计每种可能下的用户人数占总人数的百分比,来填入下表。之后将下表中标A、O、M、I、R、Q的格子中百分比相加,即可得到五种属性对应的百分比。从需求的角度来说,先满足M百分比最高的去掉R百分比最高的,再满足O百分比最高的,最后满足A百分比最高的。
四、Better-Worse 系数矩阵
作用:
还可以通过Better-Worse系数矩阵 对功能/服务的属性进一步归类,得出增加或者消除某功能/服务对用户的具体影响程度:
(1)有了什么功能,能大大提升用户体验,增加产品竞争力;
(2)取消哪些功能,会使得用户很不高兴。从而明确产品功能开发优先级,便于落地。
纵轴 Better ,表示增加某功获得的满意系数。公式:Better/SI = (O+A) /(O+M+A+I)
横轴 Worse,表示去掉某功能引起不满意程度。公式:Worse/DSI = (O+M) /(O+M+A+I)
得到各个产品功能的better和worse两个系数以后,就可以对全部功能做出散点图,然后对比不同的功能它们该归为哪个属性类,由于这里的象限是相对来划分的,因此这里使用象限图对四种属性的分类也就是各个项目互相对比而来的。
因此,根据better-worse系数值,将散点图划分为四个象限,对系数绝对分值较高的功能/服务需求应当优先实施。
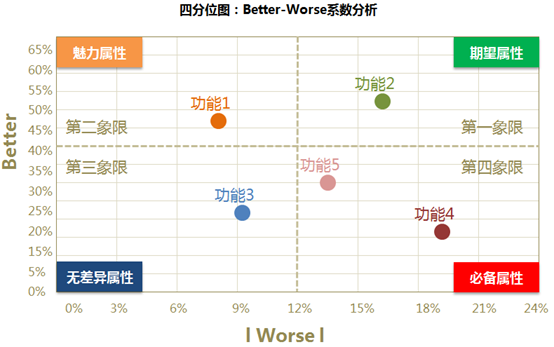
第一象限表示:better系数值高,worse系数绝对值也很高的情况。落入这一象限的属性,称之为是期望属性,即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象;
第二象限表示:better系数值高,worse系数绝对值低的情况。落入这一象限的属性,称之为是魅力属性,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升;
第三象限表示:better系数值低,worse系数绝对值也低的情况。落入这一象限的属性,称之为是无差异属性,即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能。
第四象限表示:better系数值低,worse系数绝对值高的情况。落入这一象限的属性,称之为是必备属性,即表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是最基本的功能,这些需求是用户认为我们有义务做到的事情。
同类型功能之间,建议优先考虑better系数较高,worse系数较低的。
在产品开发时,功能优先级的排序一般是:必备属性>期望属性>魅力属性>无差异属性。
但实际需要考虑产品的市场策略,如期望属性和魅力属性是可以击中用户的爽点或痒点的,在争取市场份额上期望属性和魅力属性更为重要,且可以考虑作为产品卖点进行包装营销。
参考:
【1】活用数据分析
【2】什么是卡诺KANO模型?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号