

如何指标择优、综合?
-
场景问题:
请教大家个问题~ 在工作中可能会有很多个指标来判断一个人或者访问的价值,例如时长,阅读的次数,曝光的次数,之类的很多个指标,那一般用什么算法或者办法去综合评判这个访问的价值。
RFM模型,感觉这个可能更偏向于有购买行为的一些指标,app内的粘性指标感觉不知道怎么往这三个指标上套用。我找到了这个指标的对应,但是这个模型还有一个地方不太适用是 这个的主要目的是把人分成了几类, 但是我这里的想法其实有5-6个指标,然后通过这些指标直接给他们打一个总分。
那对于这些评分指标,如何权重比较好呢?我就是在纠结这些问题。就是不是人为去拍定每个的权重,然后简单的去用权重当系数去加分,而是有什么算法可以去评判。 陈哲老师书里 是用变异系数,但我不知道,这样的话 ,对指标间的关系有没有要求
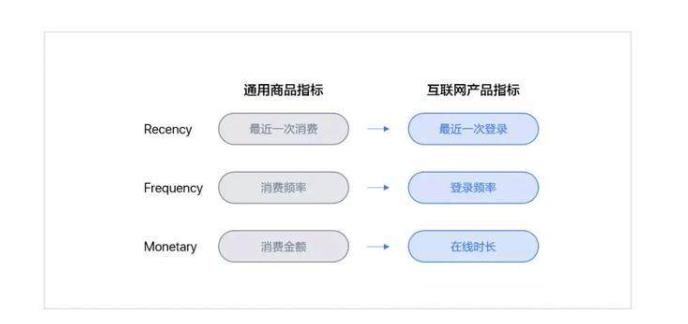
现在用于分析的指标不是太少了,而是太多了。所以当指标很多时,我们就要思考这样几个问题:
1、在同类指标中如何选择更为有效的指标
2、如何得到反映用户价值的综合指标
概括起来,所面临的问题就是两个:择优和综合。
-
如何择优?
要看这项指标能否指导你的行动。
比如,总用户数,PV,访问量这种,一般都会随着时间而增加,只会让企业自我感觉不错,而很难反映问题,像这种属于“虚荣指标”。
而相比总用户数,总活跃用户数会好一些,因为达到的难度增加了,但也是虚荣指标,也会随着时间而增加。
那如果用总活跃用户数除以总用户数呢,是不是就要好很多,因为它反应了用户参与度,当版面或是产品作出调整,可以用它反映调整效果。显然如果调整的好,这个占比是要提升的。此外,像新用户增速可以对比不同流量渠道的效果。
也就是,从诸多指标中你先要判断该指标是否是有价值的、可以有效帮你找到问题,衡量效果。分析的目的是为了找到可以落地改进的地方,因而找指标也要尽可能找可以衡量下手地方的指标。
-
如何综合?
综合的前提是要知道各项指标的联系。
一种是因果联系。
比如有些指标虽然很容易反映问题,比如最近一次购买的时间,或者说新近度,还有用户投诉量等,反映用户流失,如果用户很久没来了,或者用户说明用户可能会流失,但这种指标是“后见性指标”,是果。背后会有很多因素影响,你还需要继续找出反映这些因素的指标,比如有可能是页面不吸引人,反映在指标上可能就是用户停留时间短,或者若是电商,看看是哪个环节的转化率低。而在查找问题时,往往要有一个比较清晰的思维架构。
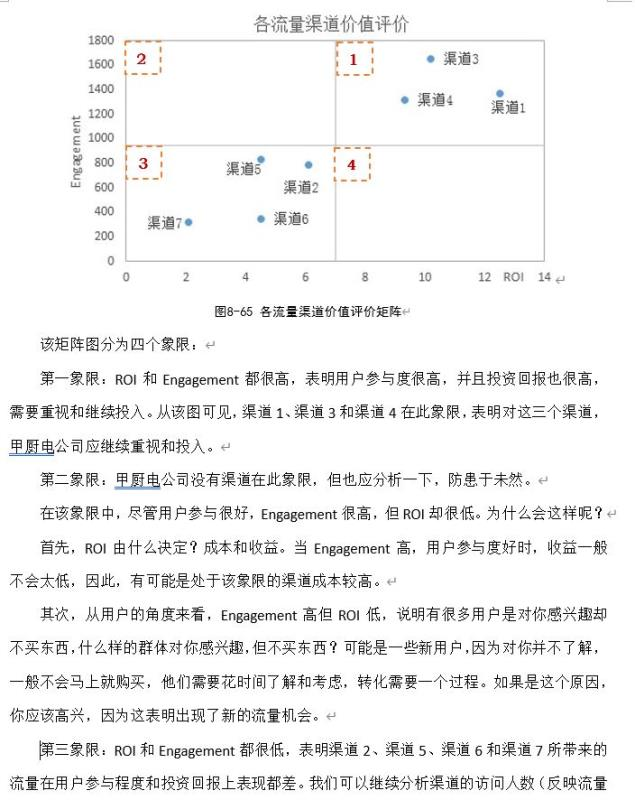
比如,在《活用数据》的第8章第6节讲到流量渠道价值评价,就是从访客行为的流程和各指标的内在联系,从诸多指标中找出ROI和engagement作为衡量流量价值的指标。因为如果访客只访问,却很少浏览,或是只浏览不下单,对于企业来说都无法变现。所以不仅要关注访客访问的规模,还要关注其浏览互动,更要关注他的购买转化及所带来的收益。而ROI,从它的内涵出发,你会发现它能同时反映规模,转化和收益这三项因素,但是ROI它就没把互动综合进来。也就是在刚才说的我们需要关注的访客行为所对应的四个影响因素上,ROI能衡量三个,可以看成是反映访客规模,转化和收益的综合指标,但是互动衡量不了,所以用engagement衡量。所以总结起来就是,在评价流量价值时就要用ROI和互动两个大维度来同时衡量。
但是,需要警惕的是我们所看到的指标,只是用户的痕迹,并不能反映用户的全部信息。所以这种因果关系并不一定能完全能反映到指标上。因此,不要妄想用算法解决一切,要多和销售业务人员沟通,要多进行自我体验。比如,有些电商网站在付款页面看不到或是改不了收件地址,可能就会引发跳出。如果把自己当成买家,多体验,即便没有指标也能发现问题。
如果手头的指标有明显的先见性和后见性的区别,可以试试建立回归模型来做综合。

另一种情况是同类指标。
像问题中所列举的都是反映用户访问的一些指标,如果难以判断这些指标哪个更优,能不能综合,还有一个方法就是做主成份分析。主成份分析结果中的KMO和Bartlett球形检验就会告诉你,你放进去的这些指标之间有没有相关性,试想如果这些指标完全不相关,那就没有综合的必要了。
接着主成份分析得到的特征根大于1的因子肯定会比原有的指标个数少,也就是主成份分析具有降维的作用,比如你原来有8个指标,通过主成份分析降成了2个因子,这2个因子其实就是原来8个指标的综合。
如果你说,不行,我就要合成一个综合因子,然后用这个综合因子对研究对象进行排名,那你可以以各个因子的方差贡献率归一化作权重,对研究对象在各个因子上的得分做加权平均。

如果要用算法来做RFM的权重,可以看表格中提到的变异系数法,最大熵,均方差,神经网络和回归。其实也可以做聚类。但提醒一点就是做这些分析之前要标准化,因为R、F、M的量纲是不同的。
不要抵触主观设置权重的方法,尤其是RFM模型中,到底更看重金额,频次还是最近一次购买的时间,这是和企业所处阶段以、业务、商业模式有关的,比如刚创业的企业会更看重拉新,所以对F就要比对M更看重,而成熟企业则对M更看重一些。再比如卖洗发水和卖眼镜,用户的新近度肯定不一样,一个人的眼镜不会像洗发水买的那么勤,所以用主观来设置权重,把相关人员叫来,他们会带给你数据上看不到的业务常识和经验。
RFM模型比较适合于to C类型的企业,尤其是日用消费品,因为如果是耐用消费品,R的跨度过大。所以像消费品,化妆品,小家电,超市,加油站,运输,快递,快餐店,电信等类似这些TO C的日用消费品应该都比较适合。
【参考】
【1】from 与陈哲老师的探讨总结

