

区别 |时间序列vs线性回归
小结:
(1)时间序列和回归分析的核心区别在于对数据的假设:回归分析假设每个样本数据点都是独立的;而时间序列则是利用数据之间的相关性进行预测。如:时间序列分析中一个基础模型就是AR(Auto-Regressive)模型,它利用过去的数据点y(t)、y(t-1)等来预测未来y(t+1)。还有如:移动平均、指数平滑法等。
(2)虽然AR模型(自回归模型)和线性回归看上去有很大的相似性。但由于缺失了独立性,利用线性回归求解的AR模型参数会是有偏的。但又由于这个解是一致的,所以在实际运用中还是利用线性回归来近似AR模型。
(3)忽视或假设数据的独立性很可能会造成模型的失效。金融市场的预测的建模尤其需要注意这一点。
本文会先说明两者对数据的具体假设差异,再说明AR模型(Autoregressive model 自回模型)为什么虽然看上去像回归分析,但还是有差别,最后也提到一个常见的混淆两者后在金融方向可能出现的问题。
一、回归分析对数据的假设:独立性
在回归分析中,我们假设数据是相互独立的。这种独立性体现在两个方面:一方面,自变量(X)是固定的,已被观测到的值,另一方面,每个因变量(y)的误差项是独立同分布,对于线性回归模型来说,误差项是独立同分布的正态分布,并且满足均值为0,方差恒定。
这种数据的独立性的具体表现就是:在回归分析中,数据顺序可以任意交换。在建模的时候,你可以随机选取数据循序进行模型训练,也可以随机选取一部分数据进行训练集和验证集的拆分。也正因为如此,在验证集中,每个预测值的误差都是相对恒定的:不会存在误差的积累,导致预测准确度越来越低。
二、时间序列对数据的假设:相关性
但对于时间序列分析而言,我们必须假设而且利用数据的相关性。核心的原因是我们没有其他任何的外部数据,只能利用现有的数据走向来预测未来。因此,我们需要假设每个数据点之间有相关性,并且通过建模找到对应的相关性,利用它去预测未来的数据走向。这也是为什么经典的时间序列分析(ARIMA)会用ACF(自相关系数)和PACF(偏自相关系数)来观察数据之间的相关性。
时间序列对相关性的假设直接违背了回归分析的独立性假设。在多段时间序列预测中,一方面,对于未来预测的自变量可能无法真实的观察到,另一方面,随着预测越来越远,误差会逐渐积累:你对于长远未来的预测应该会比近期预测更不确定。因此,时间序列分析需要采用一种完全不同的视角,用不同的模型去进行分析研究。

三、AR模型(自回归模型)和线性回归模型的“相似”&区别
时间序列分析中一个基础模型就是AR(Auto-Regressive)模型。它利用过去的数据点来预测未来。举例而言,AR(1)模型利用当前时刻的数据点预测未来的值,它们的数学关系可以被表示为:
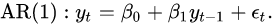
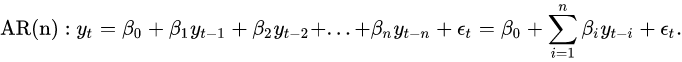
它的表达形式的确和线性回归模型非常类似,甚至连一般的AR(n)模型都和线性回归有很高的相似性。唯一的差别就是等式右边的自变量(X)变成了过去的因变量(y)。而正是因为这一点微小的差异,导致两者的解完全不同。在AR模型中,由于模型自变量成为了过去的因变量,使得自变量与过去的误差之间有相关性。而这种相关性使得利用线性模型得到的AR模型(自回归模型)的解会是有偏估计(biased)。
对于上述结论的实际证明需要引入过多的概念。在此我们只对AR(1)模型作为一个特例来分析。不失一般性,我们可以通过平移数据将AR(1)模型表示成如下的形式:
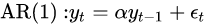
对于这类模型,线性回归会给出以下的估计值:
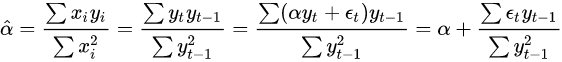
对于一般的线性回归模型而言,由于所有的自变量都会被视为已经观测到的真实值。所以当我们取均值的时候,我们可以把分母当作已知,通过过去观测值和未来误差无关的性质得到无偏的结论。
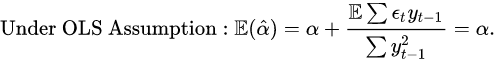
但是在时间序列下就无法得到无偏的兴致了,因为分子分母会互相干扰。因为自变量无法被视为已知,而且未来的观察值会与过去的误差项相互联系。因此,相关性使得利用线性模型得到的AR模型的解会是有偏估计(biased)。
更直观的数据模拟也可以说明这个问题[1]。如下图所示,左边是当参数真是值为0.9时通过数据模拟作出的平均值,可以看到真实值(黑线)和模拟值(红线)有一定的差距,但随着数据量的增大,差距在逐渐的缩小。右边是真正参数不同的时候,偏差的大小。可以看到,它们的误差一直存在,但是随着数据量的增加,误差逐渐变小。
事实上,我们会用线性回归模型去近似求解AR模型。因为虽然结果会是有偏的,但是却是一致估计。也就是说,当数据量足够大的时候,求解的值会收敛于真实值。这里就不再做展开了。
四、忽视独立性的后果:金融方向的常见错误
希望看到这里你已经弄懂了为什么不能混淆模型的假设:尤其是独立性或相关性的假设。接下来我会说一个我见过的因为混淆假设导致的金融方向的错误。
随着机器学习的发展,很多人希望能够将机器学习和金融市场结合起来。利用数据建模来对股票价格进行预测。他们会用传统的机器学习方法将得到的数据随机的分配成训练集和测试集。利用训练集训练模型去预测股票涨跌的概率(涨或跌的二维分类问题)。然后当他们去将模型应用到测试集时,他们发现模型的表现非常优秀——能够达到80~90%的准确度。但是在实际应用中却没有这么好的表现。
造成这个错误的原因就是他们没有认识到数据是高度相关的。对于时间序列,我们不能通过随机分配去安排训练集和测试集,否则就会出现“利用未来数据”来预测“过去走向”的问题。这个时候,即使你的模型在你的测试集表现出色,也不代表他真的能预测未来股价的走向。
【参考】
【1】知乎 时间序列和回归分析有什么本质区别?

