

待完成 |机器学习常用算法原理及优缺点
原理:
https://www.cnblogs.com/hellochennan/p/6654126.html
https://www.cnblogs.com/hellochennan/p/6654128.html
https://www.cnblogs.com/hellochennan/p/6654129.html
常见问题https://www.cnblogs.com/hellochennan/p/6654134.html
【参考】
简单的算法选择技巧:
- 首当其冲应该选择的就是「逻辑回归」,如果它的效果不怎么样,那么可以将它的结果作为基准来参考,在基础上与其他算法进行比较;
- 然后试试「决策树(随机森林)」看看是否可以大幅度提升你的模型性能。即便最后你并没有把它当做为最终模型,你也可以使用随机森林来移除噪声变量,做特征选择;
- 如果特征的数量和观测样本特别多,那么当资源和时间充足时(这个前提很重要),使用「SVM」不失为一种选择。
通常情况下:GBDT ≧ SVM ≧ RF ≧ Adaboost ≧ Other…,现在深度学习很热门,很多领域都用到,它是以神经网络为基础的。
算法固然重要,但好的数据却要优于好的算法,设计优良特征是大有裨益的。假如你有一个超大数据集,那么无论你使用哪种算法可能对分类性能都没太大影响(此时就可以根据速度和易用性来进行抉择)
监督学习
逻辑回归
原理
Logistic回归模型就是将线性回归的结果输入一个Sigmoid函数,将回归值映射到0~1,表示输出为类别“1”的概率。
公式:![]()

定义yi=1和yi=0两者的比值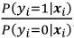 为“概率”,对其取对数得到“对数概率”,可得:
为“概率”,对其取对数得到“对数概率”,可得: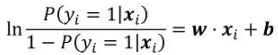 ,
,
由此可知,Logistic回归的本质其实就是用线性回归的预测结果w·xi+b去逼近真实标记的对数概率[插图],实际上这也是Logistic回归被称为“对数概率回归”的原因。
参数求解策略和算法:
我们的目标就是所有样本发生的概率最大化 ,即损失函数(最大似然函数)为:
L(w,b)=argmax ∏ f(xi)yi(1-f(xi))(1-yi)
求对数:argmax Σ yilogf(xi)+(1-yi)log(1-f(xi))
即:argmin -Σ yilogf(xi)+(1-yi)log(1-f(xi))
该函数为凸函数,再根据梯度下降法或牛顿法,很容易求得最小值,结果为:
∂L/∂w=Σ(xi(yi-f(xi)))
∂L/∂b=Σ(yi-f(xi))
1.优点
(1)Logistic回归模型直接对分类的可能性进行建模,无须事先假设数据满足某种分布类型。
(2)Logistic回归模型不仅可以预测出样本类别,还可以得到预测为某类别的近似概率,这在许多需要利用概率辅助决策的任务中比较实用。
(3)Logistic回归模型中使用的对数损失函数是任意阶可导的凸函数(max ln L(ω,b)是凹函数,即转换为求 -min L ln(ω,b) 凸函数),有很好的数学性质,可避免局部最小值问题。
(4)Logistic回归模型对一般的分类问题都可使用,特别是对稀疏高维特征的处理没有太大压力,这在处理类似广告点击率预测问题很有优势。
2.缺点
(1)Logistic回归模型本质上还是一种线性模型,只能做线性分类,不适合处理非线性的情况,一般需要结合较多的人工特征处理使用。
(2)Logistic回归对正负样本的分布比较敏感,所以要注意正负样本的平衡性,即y=1的样本数不能太少。
决策树
随机森林
支持向量机(SVM)
KNN
1.优点:
1)简单,易于理解,易于实现,无需估计参数,无需训练。
2) 适合对稀有事件进行分类。
3)特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
2.缺点:
1)该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2)该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3)可理解性差,无法给出像决策树那样的规则。
4)类别评分不是规则化的。
3.改进策略:
针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
分类效果:采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
非监督学习——聚类
算法的优缺点
K-means
1.优点:
1)算法快速、简单。
2)对大数据集有较高的效率并且是可伸缩性的。
3)时间复杂度近于线性,为O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k<<n,适合挖掘大规模数据集。
2.缺点:
1)k是事先给定的,这个k值的选定是非常难以估计的。
2)在该算法中首先需要根据初始聚类中心来确定一个初始划分,然后对初始聚类中心进行优化。这个初始聚类中心的选择对聚类结果又较大影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。
3)从K-means算法中可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此数据量非常大时,算法的时间开销也是非常大的。
3.改进:
基于熵值法及动态规划的改进k-means算法。
熵值法用来修订算法的距离计算公式,以提高算法的聚类精确程度, 动态规划算法用来确定算法的初始聚类中心。
非监督学习——关联
Apriori
是经典的关联规则数据挖掘算法。
1.优点:
1)简单、易理解。
2)数据要求低。
2.缺点:
1)在每一步产生候选项目集时循环产生的组合过多,没有排除不应该参与组合的元素。
2)每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,如果是一个大型的数据库时,这种扫描会大大增加计算机的I/O开销。
3.改进:
1)利用建立临时数据库的方法来提高Apriori算法的效率。
2)Fp-tree 算法。以树形的形式来展示、表达数据的形态;可以理解为水在不同河流分支的流动过程。
3)垂直数据分布。相当于把原始数据进行行转列的操作,并且记录每个元素的个数。
FP-growth

