
JAVA复习笔记分布式篇:kafka
前言:第一次使用消息队列是在实在前年的时候,那时候还不了解kafka,用的是阿里的rocket_mq,当时觉得挺好用的,后来听原阿里的同事说rocket_mq是他们看来kafka的源码后自己开发了一套更适合业务的消息队列rocket_mq(kafka更多地适用于日志方面),所以我们从kafka下手去了解一个消息队列也是不错的选择
简介:Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
关键字:一个分布式发布-订阅消息传递系统
组件概念:
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer : 生产message发送到topic
Consumer : 订阅topic消费message, consumer作为一个线程来消费
Consumer Group:一个Consumer Group包含多个consumer
参考以下架构图
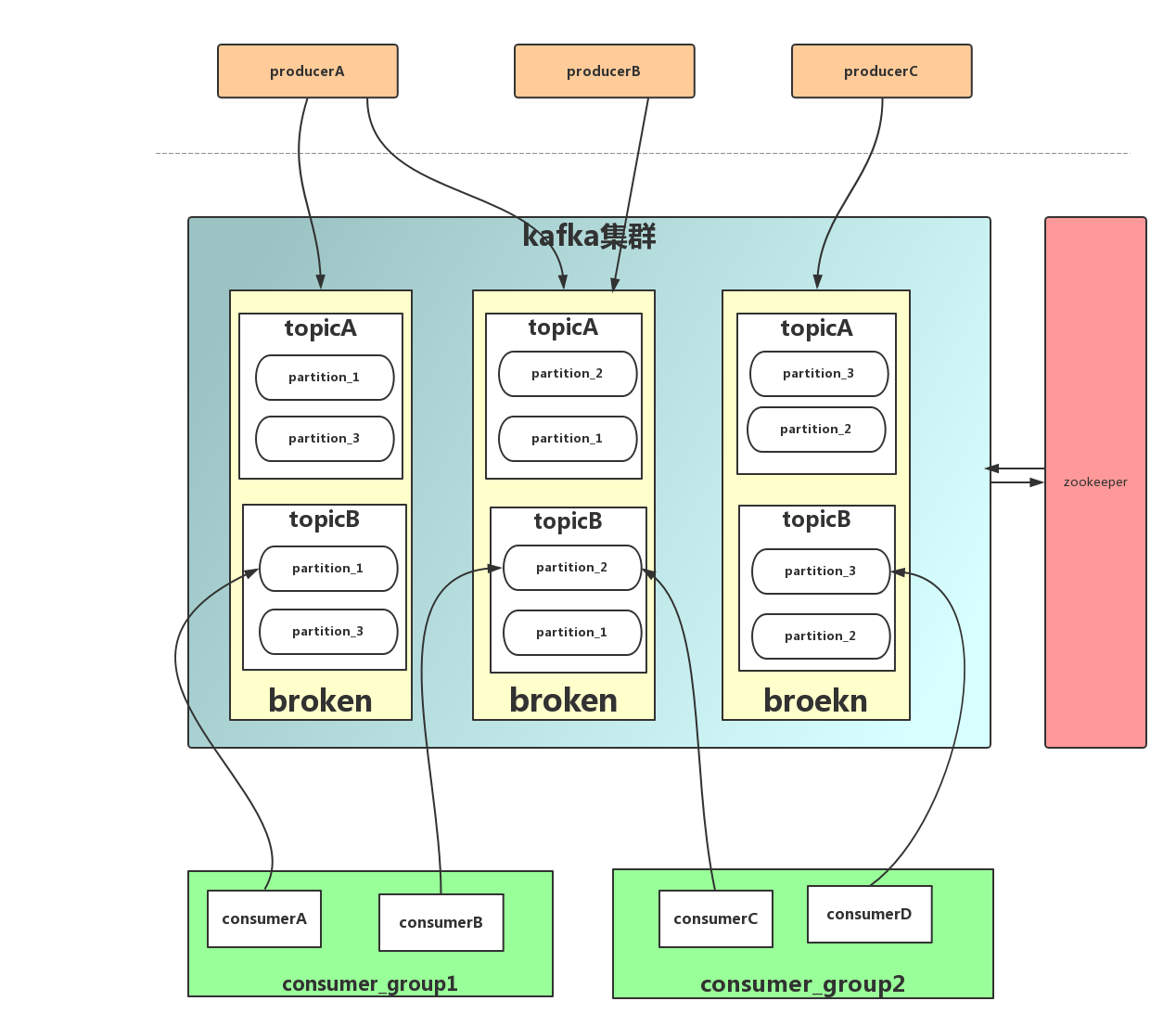
基本原理
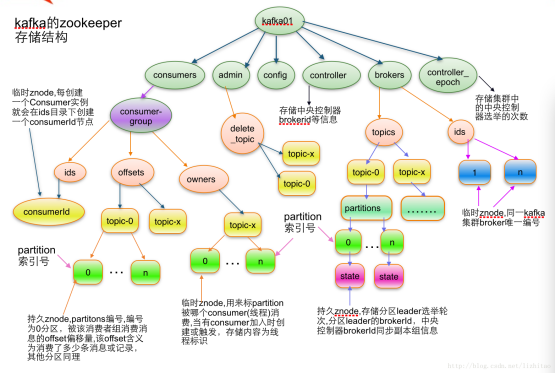
从上面的架构图发现,kafka还依赖到zookeeper了,那么zookeeper在kafka中扮演上面角色呢?
broken注册:每个broken启动的时候都会向zookeeper注册自己的信息,每个broker都使用不同的brokerId去zookeeper上创建一个临时节点,并保持长连接,创建节点完成后, broker会将自己的IP和端口记录到节点中去。一旦broker宕机,长连接断掉,该节点就会
删除(PS:只会有一个broker会创建成为controller节点,其他的broker就是follwers,follwers会注册watch到这个节点)
topic注册:在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护
消费者注册:
- 注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
- 对消费者分组中的消费者的变化注册监听。每个消费者都需要关注所属消费者分组中其他消费者服务器的变化情况,一旦发现消费者新增或减少,就触发消费者的负载均衡。
- 对Broker服务器变化注册监听。消费者需要对/broker/ids/[0-N]中的节点进行监听,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者负载均衡。
- 进行消费者负载均衡。为了让同一个Topic下不同分区的消息尽量均衡地被多个消费者消费而进行消费者与消息分区分配的过程,通常,对于一个消费者分组,如果组内的消费者服务器发生变更或Broker服务器发生变更,会发出消费者负载均衡。
生产者负载均衡:由于每个Broker启动时,都会完成Broker注册过程,生产者会通过该节点的变化来动态地感知到Broker服务器列表的变更,这样就可以实现动态的负载均衡机制。
消费者负载均衡:与生产者类似,消费者会把注册信息发送到Zookeeper上,每个消费者分组包含若干消费者,每条消息都只会发送给分组中的一个消费者,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰
消费者与消费组之前的关系:在Zookeeper上记录消息分区与消费者之间的关系,每个消费者一旦确定了对一个消息分区的消费权力,需要将其Consumer ID 写入到对应消息分区的临时节点上/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]
消费进度:在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息消费 /consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]
message在segment中的物理存储方式:


从上述图可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间
写message
- 消息从java堆转入page cache(即物理内存)。
- 由异步线程刷盘,消息从page cache刷入磁盘。
读message
- 消息直接从page cache转入socket发送出去。
- 当从page cache没有找到相应数据时,此时会产生磁盘IO,从磁
盘Load消息到page cache,然后直接从socket发出去
Kafka高效文件存储设计特点
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号