Facial Emotion Distribution Learning by Exploiting Low-Rank Label Correlations Locally(CVPR2019)
Posted on 2019-12-17 13:38 sugarcly 阅读(453) 评论(0) 收藏 举报本文提出一种利用局部低秩标签联系学习面部表情分布的方法,具体来说就是学习一个表情图片包含的不同表情标签的比例,
一.构造表情分布学习的损失函数
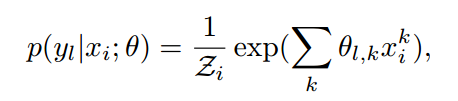
其中 xi 代表第i个样本的特征,k 代表第k个特征,yl 代表第 l 个标签,θl,k 代表从特征学习到第 l 个表情标签的参数,Zi 为![]() ,
,
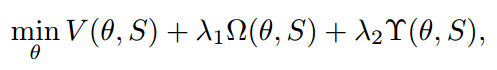
通过最小化上面的结构函数优化 θ ,V是训练数据上定义的损失函数,Ω是控制输出模型复杂度的正则化器,Υ是实现局部标记相关特性的正则化器,而λ1和λ2是两个参数来平衡三个项。
表情分布学习是为了得到预测分布与实际分布尽可能相似,因此选择测量两个分布的相似性作为损失函数,这里选择欧氏距离的平方
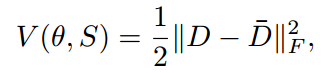 D与D-分别代表预测分布与真实分布
D与D-分别代表预测分布与真实分布
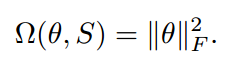 被用于强制预测分布的局部低秩结构
被用于强制预测分布的局部低秩结构
通过k-means聚类方法将训练数据聚类到m个类别,这里聚类的依据是标签空间而非特征空间,目的是为了使得到的聚类更可能是低秩结构。
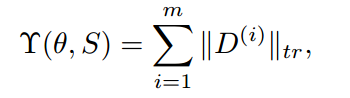 矩阵的秩很难优化,所以这里选择优化矩阵的迹,作为矩阵秩的凸近似。D(i) 为第 i 个聚类 G(i) 的预测分布。
矩阵的秩很难优化,所以这里选择优化矩阵的迹,作为矩阵秩的凸近似。D(i) 为第 i 个聚类 G(i) 的预测分布。
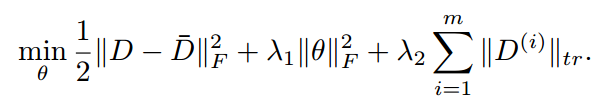
二.优化上述损失函数
ADMM (Alternating Direction Method of Multipliers) 乘法器交替方向法:它采用分解协调过程的形式,在分解协调过程中,对局部小问题的解进行协调,找到一个全局大问题的解。
为了更容易优化,将损失函数修改为以下形式:
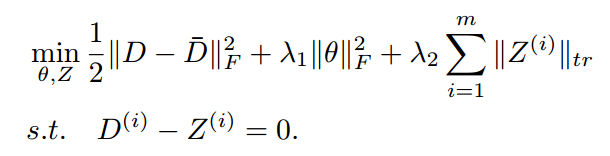
拉格朗日函数形式是:

其中
Λ= 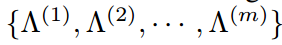 ,为拉格朗日橙子列表
,为拉格朗日橙子列表
ρ为正数列表,也叫惩罚参数,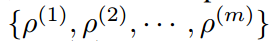
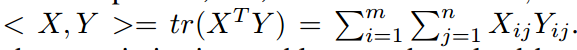
参数更新方式为更新其中一个固定其他参数,更新公式为:
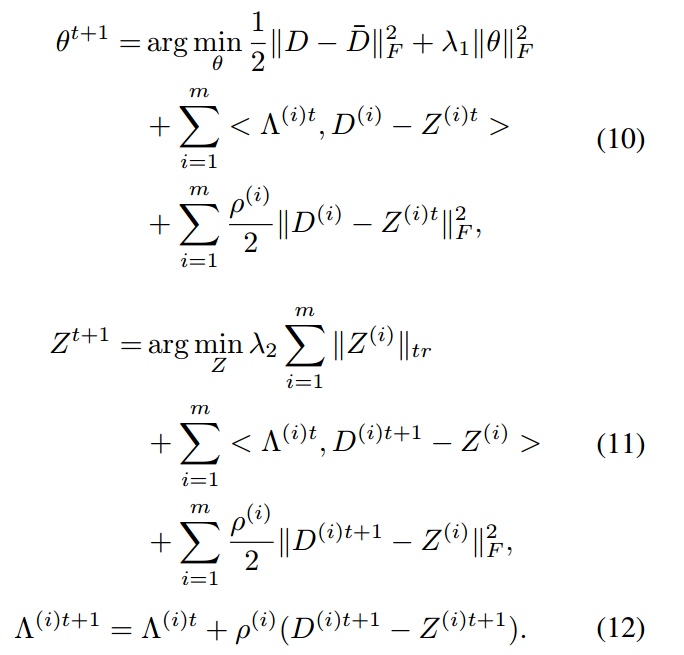
式(10)可用有限记忆拟牛顿法(L-BFGS)有效求解
三.利用两个数据集,六种测量方法对结果进行评价

 浙公网安备 33010602011771号
浙公网安备 33010602011771号