
完整的中英文词频统计
#.英文小说 词频统计 #读取字符串 str fo=open('lines.txt','r',encoding='utf-8') lines=fo.read().lower() fo.close() print(lines)

#字符串预处理 #全部转化为小写 h2=str.lower(lines) print(h2) #标准符号与特殊符号 sep = ',.;:?!-_' for en in sep: lines=lines.replace(en,'') print(lines)

#分解提取单词 list strList=lines.split() print(len(strList),strList)
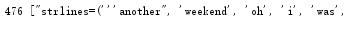
#单词计数字典 set(不重复) strSet=set(strList) print(len(strSet),strSet)
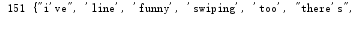
#单词计数字典 dict strDict={} for word in strSet: strDict[word]=strList.count(word) print(len(strDict),strDict)

#词频排序 list.sort(key=) wcList=list(strDict.items()) print(wcList) wcList.sort(key=lambda x:x[1],reverse=True) print(wcList)
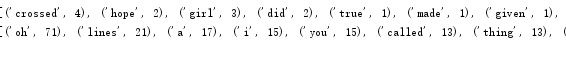
#输出TOP(20) for i in range(20): print(wcList[i])

#排除语法型词汇,代词、冠词、连词等无语义词 strSet=set(strSet) exclude={'a','the','and','you','oh'} strSet=strSet-exclude print(len(strSet),strSet)
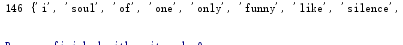
#.中文小说 词频统计
import jieba to=open('简爱.txt','r',encoding='utf-8') lines=to.read() to.close() sep = ',。?!;:“”‘’-——<_/>' for en in sep: lines=lines.replace(en, '') lines = list(jieba.cut_for_search(lines)) strSet = set(lines) #print(len(strSet), strSet) strDict = dict() for word in strSet: strDict[word] = lines.count(word) #print(len(strDict), strDict) wcList = list(strDict.items()) #print(wcList) wcList.sort(key=lambda x: x[1], reverse=True) #print(wcList) for i in range(20): print(wcList[i])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号