from sklearn import datasets
# 波士顿房价数据集
data = datasets.load_boston()
import pandas as pd
# 转为DataFrame
dataDF = pd.DataFrame(data.data,columns=data.feature_names)
dataDF
# 数据可视化操作和人为的一元线性拟合
import matplotlib.pyplot as plt
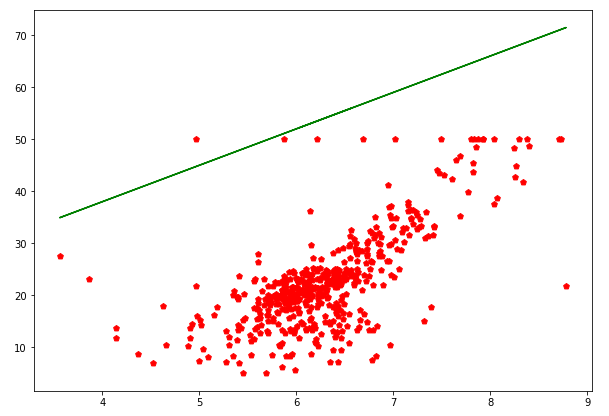
x = data.data[:,5]
y = data.target
plt.figure(figsize=(10,7))
plt.scatter(x,y,c='r',marker='p')
plt.plot(x,7*x+10,'g')
plt.show()
![]()
# 建立一元线性回归模型
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
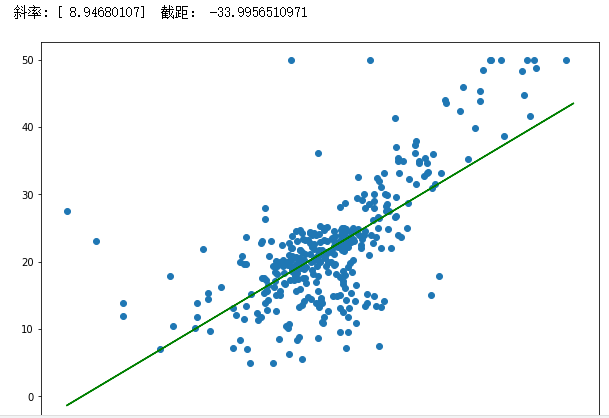
x_train,x_test,y_train,y_test = train_test_split(data.data[:,5],data.target,test_size=0.3,)
lr = LinearRegression()
lr.fit(x_train.reshape(-1,1), y_train)
print("斜率:",lr.coef_," 截距:",lr.intercept_)
# 再次绘图:
plt.figure(figsize=(10,7))
plt.scatter(x_train,y_train)
plt.plot(x,8.6*x-32,'g')
plt.show()
![]()
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data,data.target,test_size=0.3)
print(x_train.shape,y_train.shape)
# 建立多项式性回归模型
mlr = LinearRegression()
mlr.fit(x_train,y_train)
print('系数',mlr.coef_,"\n截距",mlr.intercept_)
# 检测模型好坏
import numpy as np
x_predict = mlr.predict(x_test)
# 打印预测的均方误差
print("预测的均方误差:", np.mean(x_predict - y_test)**2)
# 打印模型的分数
print("模型的分数:",mlr.score(x_test, y_test))
![]()
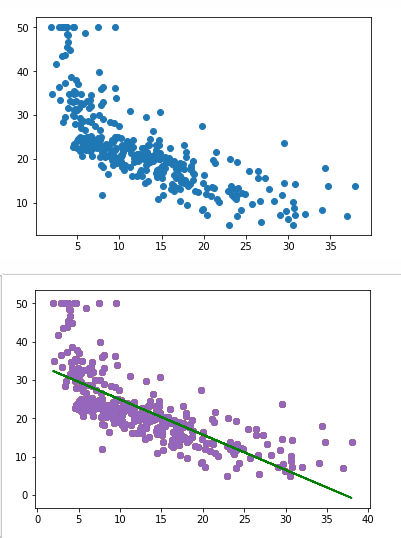
# 绘制房价和人口密度关系的散点图
plt.scatter(x_train[:,12],y_train)
plt.show()
# 用一元线性回归拟合观察效果
lr2 = LinearRegression()
lr2.fit(x,y_train)
plt.scatter(x, y_train)
plt.plot(x, lr2.coef_* x + lr2.intercept_, 'g')
plt.show()
![]()
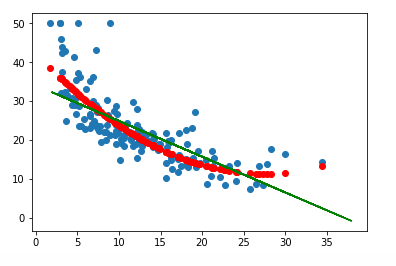
# 建立多项式模型
from sklearn.preprocessing import PolynomialFeatures
# 多项式化x
x = x_train[:,12].reshape(-1,1)
poly= PolynomialFeatures(degree=2)
x_poly = poly.fit_transform(x)
# 用多项式后的x建立多项式回归模型
lrp = LinearRegression()
lrp.fit(x_poly,y_train)
# 预测
x_poly2 = poly.transform(x_test[:, 12].reshape(-1,1))
y_ploy_predict = lrp.predict(x_poly2)
# 图形化,将元数据,一元拟合,多元拟合进行绘图观察
plt.scatter(x_test[:,12], y_test)
plt.plot(x, lr2.coef_* x + lr2.intercept_, 'g')
plt.scatter(x_test[:,12], y_ploy_predict, c='r')
plt.show()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号