

UDP协议精华总结
引入
本文面向有一定计网基础的读者。
TCP, UDP, IP 可以说是计网的常客了,它们三紧密联系,以至于经常看见“TCP/IP”这样的名词,但实际上 UDP 也是基于 IP 的,但似乎很少见“UDP/IP”。
也不奇怪,人人都说 UDP 与 TCP 相比过于简单,因此提的少。但是这并不意味着 UDP 用的少,相反它经常用于那些不要求数据可靠性的场景:音频传输、视频传输、在线游戏等。这些场景对数据可靠性、完整性要求不高,丢失少量数据包带来的影响并不大,比如音频传输中丢包的经典表现是听不清或听不到对方说的话;视频传输中丢包的经典表现是卡顿。
我认为先熟悉简单的 UDP 协议,能更好地理解复杂的 TCP 协议。
UDP协议简介
UDP, User Datagram Protocol 用户数据报协议。UDP 是传输层协议之一,应用程序可以调用该协议向其他计算机发送数据,只不过它不像它的兄弟 TCP 一样可靠,UDP 只是简单的将数据发送给指定目标,不提供任何保证(差错纠正、流量控制、拥塞控制,这些都是 TCP 才有的)。
与 TCP 相比,UDP 仅有的两个优点是:
- 保留消息边界:一般情况下,应用程序调用 UDP 发送数据时,只产生一个 UDP 数据报,从而也只发送一个 IP 数据报。从 socket 编程的角度来说就是,发送端调用 API 发送一次数据,接收端也只需要调用一次 API 便可接收到完整的数据。
- 其实这里面有很多前提的,比如:(1)UDP 协议实现会限制一次发送 UDP 数据报的长度,尽量避免发生 IP 分片;(2)数据在传输过程中没有丢失、出错,接收端接收到的是完整无误的 UDP 数据报。
- 提供差错检测:虽然 UDP 不提供差错恢复,但是它却提供了差错检测(是的,做事只做一半,能检测到差错,却不能恢复)。
一句话总结:UDP 是无连接、面向消息、保留消息边界、具有差错检验功能的传输层协议。
UDP头部
一个典型 UDP 数据报的格式如下图所示:
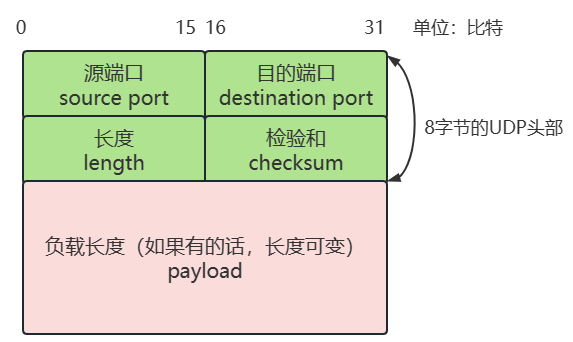
各个字段的解释如下:
-
源端口:占 2 字节,用于标识发送方进程(端口是抽象概念,没有物理实体)。可选字段,如果不要求对方回复,可以置 0。
-
目的端口:占 2 字节,用于标识接收方进程。
-
长度:占 2 字节,表示整个 UDP 数据报的长度,单位是字节。由于 16 比特能够表示的无符号数范围是 ,因此理论上 UDP 数据报最大长度为 65535 字节,即 64KB。
- 实际上该字段最小值 8(没有 payload,只有 UDP 头)。
- 该字段是冗余的,因为 IP 头里也有一个长度字段表示 IP 数据报长度,UDP 数据报的长度可以间接计算得到:[ UDP数据报长度 = IP数据报长度 - IP头部长度 ]。
-
检验和:占 2 字节,用于表示整个 UDP 数据报存在比特差错,通过某种算法计算得到。IPv4 可选但强烈推荐,IPv6 强制要求。
- 一个端到端的检验和。由发送方计算,接收方检测,传输过程中不会被途经设备修改(除非经过了 NAT 地址转换)。
- 若该字段为 0x0000 则表示发送方没有计算检验和。因此当计算结果恰好为 0x0000 时,会设置为反码 0xFFFF(那计算结果有没有可能恰好是 0xFFFF 呢?这冲突吗?我不知道= =)。
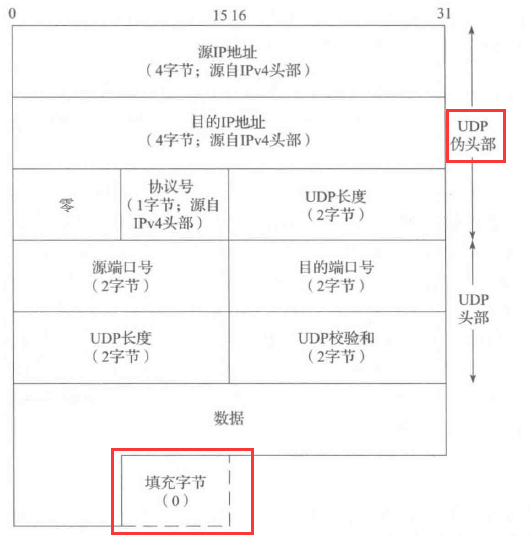
- 两个“虚”的部分参与检验和的计算:虚 0 字节和虚 IP 头部,但这两个虚的部分不会真正发送出去,只用于计算检验和。检验和计算要求 UDP 数据报的长度为偶数,因此会在奇数长度的 UDP 数据报末尾填充字节 0。此外,它还使用了一个 12 字节的伪 IP 头部,包含源 IP 地址、目的 IP 地址、零填充、协议号、长度。
-
负载:应用程序要发送的数据。
关于最大UDP数据报长度的讨论
上文介绍过,仅从 UDP 协议的角度来说,UDP 数据报的最大长度是 65535 字节。
但是 UDP 数据报是封装在 IP 数据报里的,而 IP 数据报的最大长度也是 65535 字节,也就限制了最大 UDP 数据报的最大长度要扣除一个 IP 头的长度。没有选项的 IP 头长度为 20 字节,因此一般 UDP 数据报的长度为 65515 字节,再扣除 8 字节的 UDP 头部长度,UDP 的最大负载为 65507 字节。
实现限制
不过,这一切都建立在 IP 头没有额外选项的前提下,这对于 UDP 协议的实现来说太过麻烦,毕竟实现者无法判断用户是否使用 IP 头的额外选项。
因此在实现中会提供 API 供应用程序查询最大 IP 数据报长度,典型值为 8192 或 65535 字节(当然也提供了 API 设置该值,但有没有范围限制呢?鬼知道这么实现者的心思= =)。
查询得知最大 IP 数据报长度后,便可自行决定最大 UDP 数据报长度。
UDP数据报截断
上文介绍过,UDP 是保留消息边界的传输协议,发送方调用发送 API 发送一次,接收方只需要调用一次接收 API 便可接收到完整的数据报。
然而在实现中,接收 API 允许指定一次读操作完成时返回的最大字节数,在不知道接收到的 UDP 数据报究竟多大的情况下,有可能并不能一次性全部接收完(虽然通过种种限制,一般情况下都是能一次接收完的)。当接收到的 UDP 数据报长度超过了指定的读取大小会发生什么呢?
通常做法有两个:截断和留到下个读操作。截断直接丢弃了超出的部分,导致接收方得到的数据不完整;留到下个读操作将超出部分保留,导致每次读操作都不能保证读到一个完整的数据报。因此截断是大多数实现者的做法。
路径MTU发现
MTU, Maximum Transmission Unit 最大传输单元,是链路层的最大有效载荷,即最大的 IP 数据报的大小,典型值为 1500 字节。
路径 MTU 是指:包含所有链路的整个网络上,最小的 MTU。
路径 MTU 发现是指:通过设置不发生 IP 分片,确定到达目的地的 MTU 大小。
UDP数据报与IP分片
IP 分片概念:当 IP 数据报大小超过 MTU 便要进行分片,将 IP 数据报拆分为多个片段,每个片的最终大小都不超过 MTU。
- 若设置了 IP 头不分片标志(DF, Don't Fragment),则转发设备直接丢弃该数据报。
- IP 分片可能发生在多个设备上进行多次,因为各个局域网链路的 MTU 可能不同。
- IP 分片只在目的地进行重组。因为分片经过路由转发的路径有可能不同,一个转发设备大概率不能“看到”所有分片,只能看到分片的一个子集,不具备重组分片的条件。
通过一个例子来理解 IP 分片的原理:以 MTU=1500 为例,对一个大小为 3020 字节、负载为 UDP 数据报的 IP 数据报进行分片的结果如下图所示。
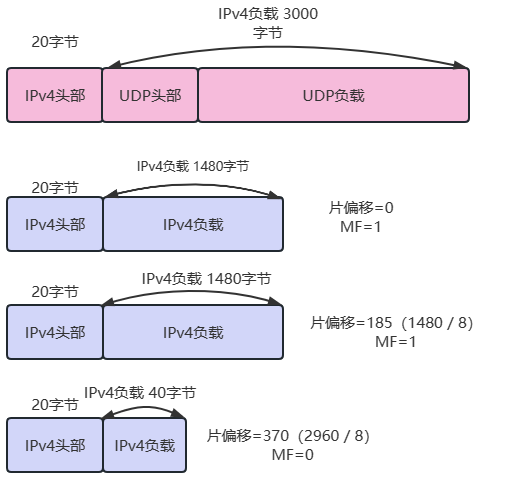
原理要点概括如下:
-
IP 分片针对的是 IP 数据报的负载。
-
每个分片都有 IP 头部。
-
MF、标识和片偏移用于目的地进行分片重组,获得原始 IP 数据报,这三个字段在 IP 头部中,图中没有详细展示)。
-
标识:用于标识分片属于同一个原始 IP 数据报,由进行分片的设备设置,来自同一个原始 IP 数据报的分片的标识相同。
-
MF:More Fragment,表示还有更多分片。最后一片的 MF=0,其余片的 MF=1。
-
片偏移:分片负载的第一个字节在原始 IP 数据报中的偏移量,单位是 8 字节。
-
分片具体过程如下:
- 因此分片个数的计算公式为:,此例子中为
- 显然第一个分片能承担 1480 字节负载,剩余 3000-1480=1520 字节;
- 第二个分片继续承担 1480 字节负载,剩余 1520-1480=40 字节;
- 第三个分片承担剩余 40 字节负载。
IP 分片的其他要点:
-
每个分片都要有 IP 头部,会引入额外的传输开销。
-
每个分片的 IP 头部都要修改总长度字段。
-
任何一个分片在转发过程中丢失,都意味着整个数据报丢失。
-
通常转发设备优先转发片偏移更大的分片,这样做的好处是接收方可以提前确定所需缓存空间的最大值(最后一个分片的片偏移 * 8 + 最后一个分片的总长度 = 原始 IP 数据报的长度)。
重组超时和超时重传
重组超时:接收方 IP 层收到任何一个分片就启动一个计时器,随后到达的其他分片不会重置计时器,若计时结束还没有收到所有分片,则重组超时。
响应:根据 IP 协议实现的不同而略有差异,所有方案都丢弃所有分片,部分方案产生 ICMP 错误报文通知发送方,而部分方案不产生 ICMP 错误。
超时重传:UDP 本身没有超时重传机制,需要应用程序自行设置。
UDP-Lite
UDP-Lite 是 UDP 的改进,仅仅将 UDP 头部中的长度字段改成了检验和覆盖范围。
出现原因:有些应用程序可以接受在发送和接收的数据里存在比特差错,那么检验和就没有必要覆盖整个数据报,只需要覆盖那些不允许存在比特差错的数据。
UDP-Lite 头部如下所示:

检验和覆盖范围:占 2 字节,单位为字节,表示从 UDP-Lite 头部的第 1 个字节开始,被检验和覆盖的字节数。
- 0 是特殊值,表示覆盖整个数据报,即 64KB。
- 1-7 无效,因为头部都占 8 字节了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)