目标检测模型
R-CNN
-
R-CNN模型思路
- 利用选择性搜索方法,在一张图片中,找出2000个可能存在目标的候选区域
- 将候选区域的大小进行调整,调整为已经训练好的CNN网络输入图像的大小
- 利用训练好的CNN网络对2000个候选区域进行特征提取
- 将得到的特征经过SVM分类器对每个候选框分类,每一个类别使用一个SVM分类一次
- 对得到的分类矩阵进行NMS非极大抑制,删除效果不好的,以及重合度高的候选框
- 对bbox做回归微调
-
选择性搜索
- 开始时以每个像素为一组,计算出每个像素的纹理
- 将相近的组集合起来形成更大的像素组,然后继续合并各个像素组
- 不断迭代1与2的操作,达到终止条件后停止迭代,根据最终的分组确定候选框
-
NMS非极大抑制
- 目的:由于候选框中可能有重叠,对于一张图片中的同一个位置的某一物体可能有多个候选框,非极大抑制的目的就是去除冗余的候选框,保留最好的那一个候选框
- 迭代过程
- 对所有候选框进行筛选,将不属于任何分类的候选框剔除
- 对剩下的候选框按照SVM分类器得出的置信度排序,依次计算loU,剔除重合度大的框
-
bbox回归修正候选框
- 目的:选择性搜索算法得到的候选框大小位置已经固定,但不一定准确,需要进行修正
- 大体思路:候选框与实际框做回归训练,得到框的四个位置数据的修正系数,则最终输出的框的位置则是筛选后的框与修正系数相乘后的结果。
-
loU交并比(位置准确性的考量)
两个框的交集比上并集 -
R-CNN缺点
- 训练阶段多,微调网络+训练SVM+边框修正
- 训练耗时大
- 处理速度慢
SPPNet
R-CNN利用选择性搜索选择出2000张图片后,分别进行卷积运算,耗时较多。
-
SPPNet模型:
- 直接将整张图片进行卷积运算,得到整张图的特征图
- 让SS得到的候选区域直接映射到特征图相关区域
- 映射过来的特征向量通过SPP层(空间金字塔变换层),输出固定大小的特征向量给fc层
-
映射规定
x' = [x/S]+1
其中,S就是CNN中所有步长的乘积,包括卷积步长池化步长。
计算出xmin',xmax',ymin',ymax',即可映射。 -
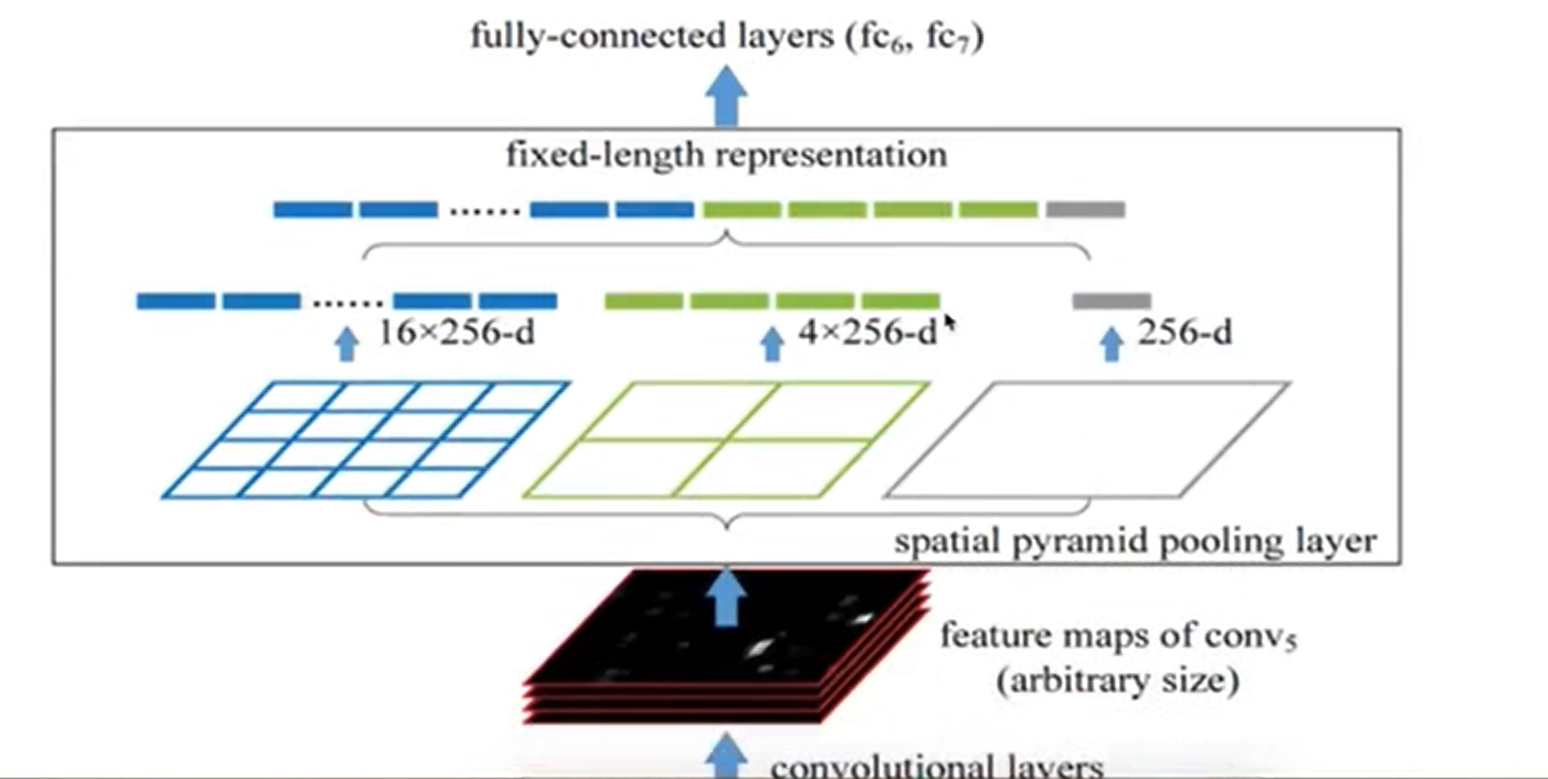
SPP层规定
SPP层将每一个候选区域分成1×1,2×2,,4×4三张子图,分别进行最大池化,得到(16+4+1)×256=5376结果,
![OmHpD0.png]()
-
SPPNet总结
- 不用再对2000张图片分开卷积,减少运算时间
- 训练速度依然过慢,效率低,依然要分阶段训练
Fast R-CNN
-
改进之处:
提出一个Rol pooling,然后整合整个模型,把CNN、Rolpooling、分类器、bbox回归几个模块整合到一起训练。 -
步骤
- 将整个图片输入到基础卷积网络,提取特征图,选择性搜索结果映射到特征图(与SPPNet一样)
- Rol pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个Rol特征向量(对每一个候选区域都会进行)
- softmax分类,输出类别有K个类别加上“背景”类,同时bbox回归。反向传播。
-
Rol pooling
与SPPNet中的SPP层类似,不是金字塔形,只做一次最大池化,输出固定类型。 -
优点
- 删除了SVM与SPPnet,训练统一
-
缺点
- 没有实现真正的端到端,还需要是用ss算法,操作耗时。
Faster R-CNN
-
主要创新
在Fast R-CNN中放弃是用选择性搜索算法,加入一个提取边缘的神经网络,候选框的工作交给了神经网络来做,(候选区域生成、特征提取、分类、位置精修)统一到了一个深度网络框架中。
Faster R-CNN可以简单看成区域生成网络(RPN)+Fast R-CNN。 -
RPN网络
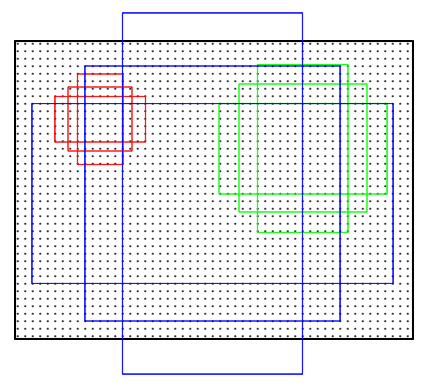
1. 用n×n(默认3×3=9)的大小窗口扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每一个滑窗位置考虑k种(论文中k=9)可能的参考窗口,参考窗口称为anchors
2. 3*3卷积核的中心点对应原图的位置称为anchors的中心点,三种尺度(128,,256,,512),三种长宽比(1:1,,1:2,,2:1),每个特征图中的像素点有9种框
![Ob1Y5t.png]()
3. 通过softmax判断anchors属于foreground还是background
4. 再利用bounding box regression修正anchors获取精确的proposals,输出默认300个候选区域给Rol pooling -
Faster R-CNN训练过程
- RPN的训练
- 分类:softmax,sigmod,logisticregression
- 候选框调整:均方差修正
- Fast R-CNN的训练
- 预测类别的训练:softmax
- 预测位置的训练:均方差损失
- 样本准备:正负anchors样本比例为1:3,lou最高为正样本,lou>0.7位正样本,lou小于0.3为负样本,其余忽略。
- RPN的训练
YOLO
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测。
YOLOV1
-
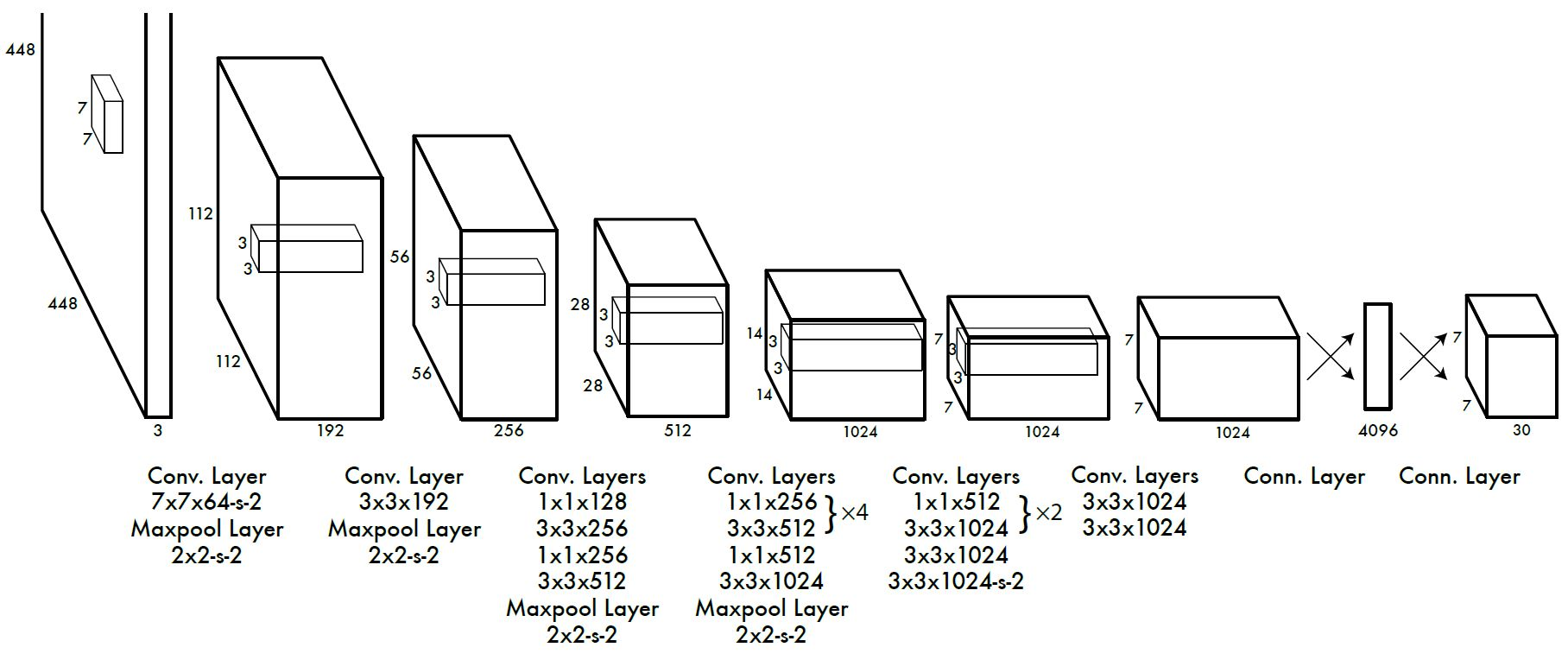
网络结构
GoogleNet + 4个卷积 + 2个全连接层
![OXEZIf.png]()
-
设计思路
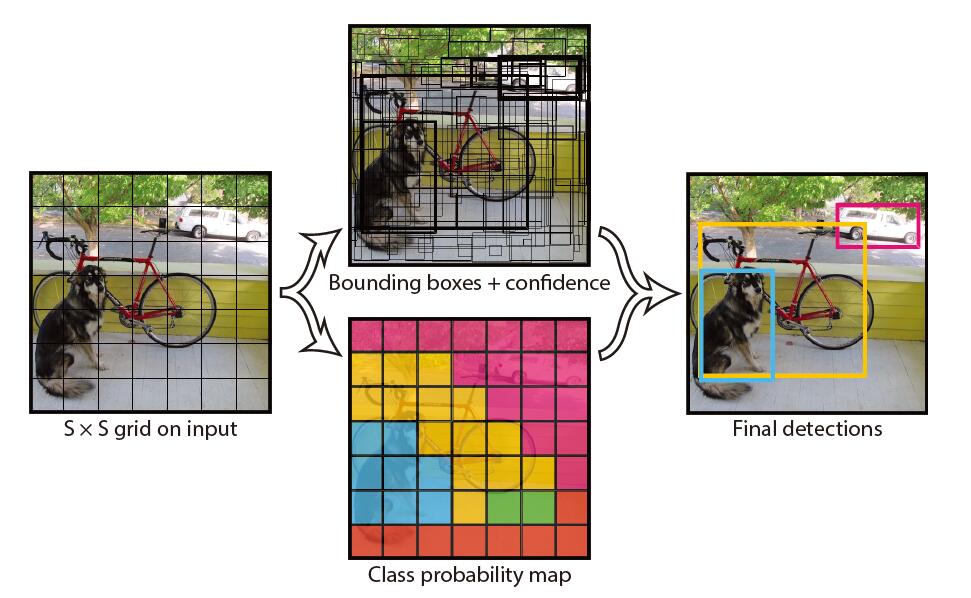
- 将输入的图片分割成S×S的网格(yolov1中s=7),每个网格生成B(B=2)个预测框。训练时,目标的中心落在哪个grid cell,就有该grid cell负责预测该目标。负责预测目标的grid cell中生成的两个bbox与标签中的ground truth的iou哪一个大则大的负责预测该目标。
![Ov8Bgs.jpg]()
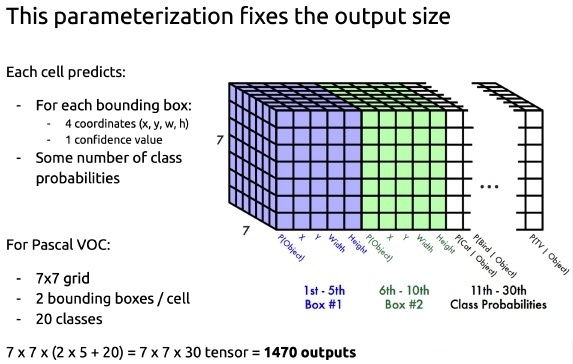
- 对每一个grid cell,网络会输出B个bbox的x,y,w,h参数、边界框的置信度c以及grid cell对每一个类别的概率(yolov1中类别个数为20)。边界框的置信度为\(\operatorname{Pr}(\text { object }) * \mathrm{IO}_{p r e d}^{t r u t h}\),其中,\(\operatorname{Pr}(\text { object })\)表示边界框含有目标的可能性,\(\mathrm{IO}_{p r e d}^{t r u t h}\)表示边界框与ground truth的IOU。grid cell对每一个类别的概率是在各个边界框存在物体的条件下的概率,即\(\operatorname{Pr}\left(\text { class }_{i} \mid \text { object }\right)\)
- 一张图片分成7×7的网格,每个网格训练出2×4个位置参数、2×1个置信度参数以及20个类别概率,共30个参数,这也是网络输出7×7×30的原因。
![Ov1iaF.jpg]()
- 将输入的图片分割成S×S的网格(yolov1中s=7),每个网格生成B(B=2)个预测框。训练时,目标的中心落在哪个grid cell,就有该grid cell负责预测该目标。负责预测目标的grid cell中生成的两个bbox与标签中的ground truth的iou哪一个大则大的负责预测该目标。
-
bounding box参数归一化
边界框参数x,y,w,h并不是传统意义上相对于grid cell的位置,为了更好的训练,对其进行如下处理:- x等于bbox中心相对于grid cell左上角在x方向的偏移量。
- y等于bbox中心相对于grid cell左上角在y方向的偏移量。
- w等于bbox的宽度除以整张图片的宽度(不是grid cell了)
- h等于bbox的长度除以整张图片的长度。

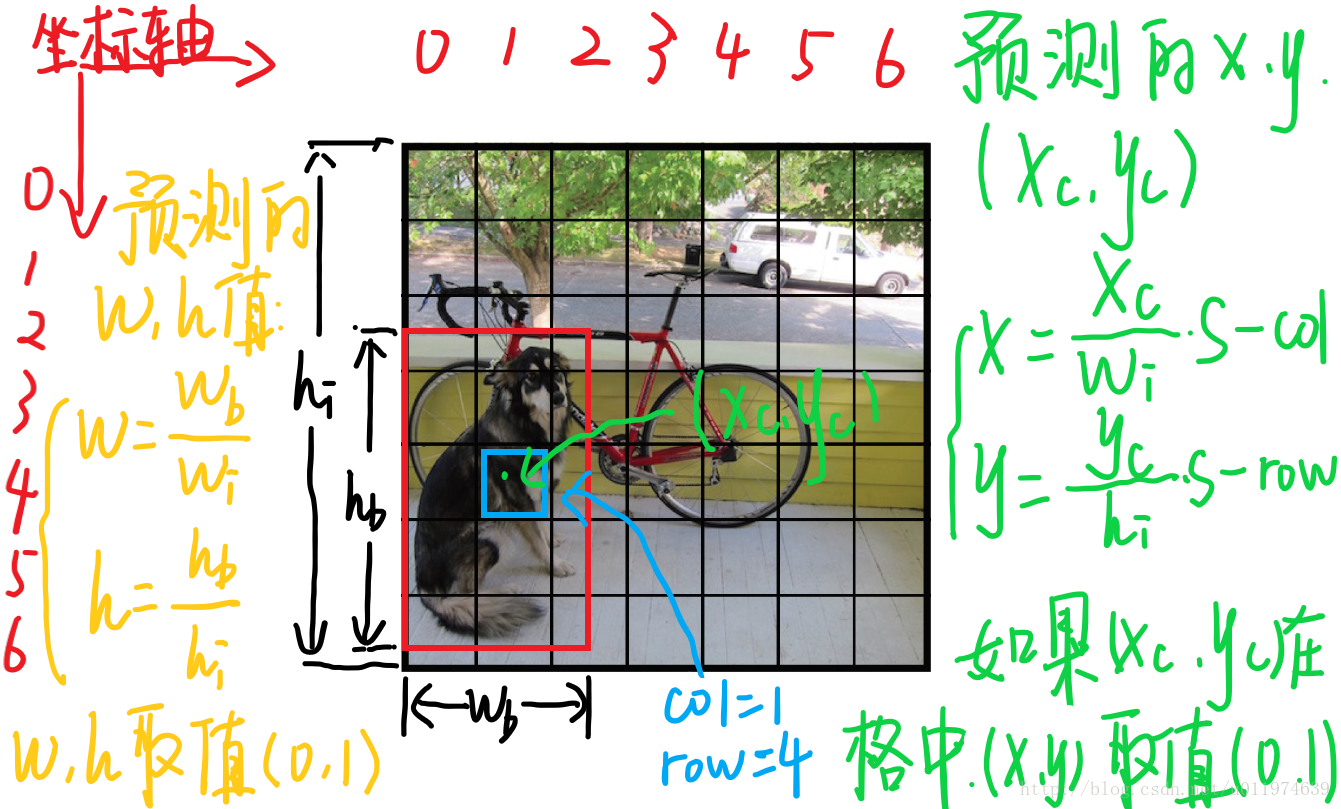
-
网络训练
将图片转换成448×448×3的大小,输入网络,最终输出7×7×30的张量,根据下式计算损失函数![OvY7bq.png]()
式中:- \(1_{i j}^{o b j}\)表示当第i个grid cell中的第j个bounding box负责预测物体时,\(1_{i j}^{o b j}=1\),否则\(1_{i j}^{o b j}=0\).
- \(1_{i j}^{noobj}\)的含义与\(1_{i j}^{o b j}\)相反。
- \(1_{i}^{o b j}\)表示当第i个grid cell中存在目标,则\(1_{i}^{o b j}=1\),否则\(1_{i}^{o b j}=0\).
- \(\lambda_{\text {coond }}=5\),\(\lambda_{\text {noobj }}=0.5\),负责预测的bbox对应的权重设置较大,而不负责预测的权重设置较小。
- 第一行表示bbox中心坐标的误差项,第二行表示bbox的高与宽的误差项(为消除大小框问题采用平方根),第三行表示负责预测目标的bbox置信度的误差项,第四行表示不负责预测目标的bbox置信度误差项,第五行表示grid cell的分类误差项。对于一二三行,只计算负责预测的bbox的损失,第四行计算不负责预测物体的bbox的损失(权重较小),第五行计算存在目标的grid cell的损失。
- x,y,w,h的标签值由ground truth产生,特别说明,yolov1中,c的标签值为负责预测的bbox与ground truth的IOU。
计算损失函数,然后反向传播,更新卷积核、全连接层中w、b参数,直到拟合。
-
预测阶段
- 利用训练阶段训练出的网络,生成7×7×30的张量,得到原始的bbox,共7×7×2=98个
![Ov8Dvn.jpg]()
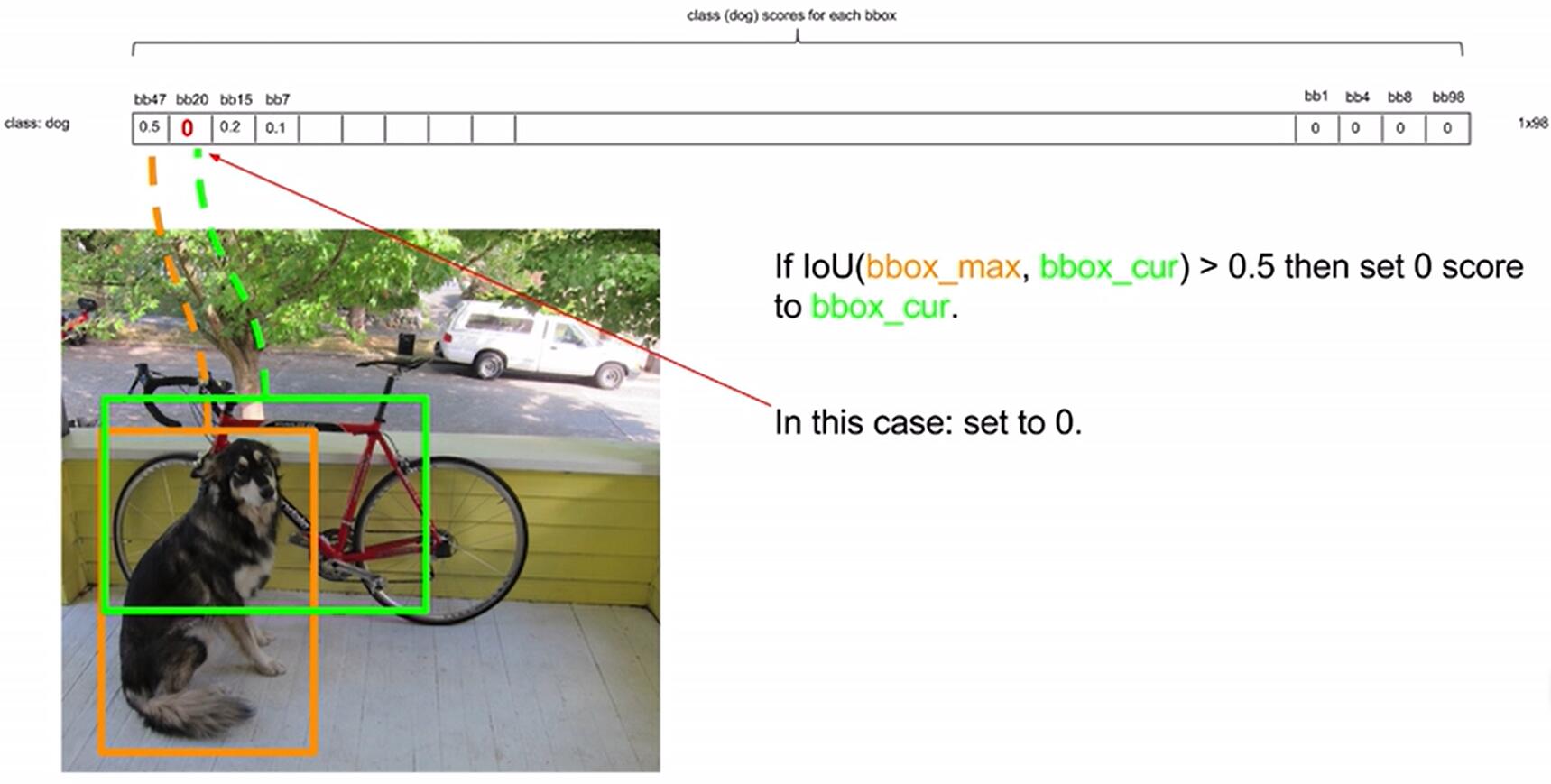
- 将每个grid cell得到的类别概率向量乘以该grid cell的两个bbox的置信度,得到每个bbox属于某一类别的概率。
![OvdL38.jpg]() ,最终得到98个20×1的向量。
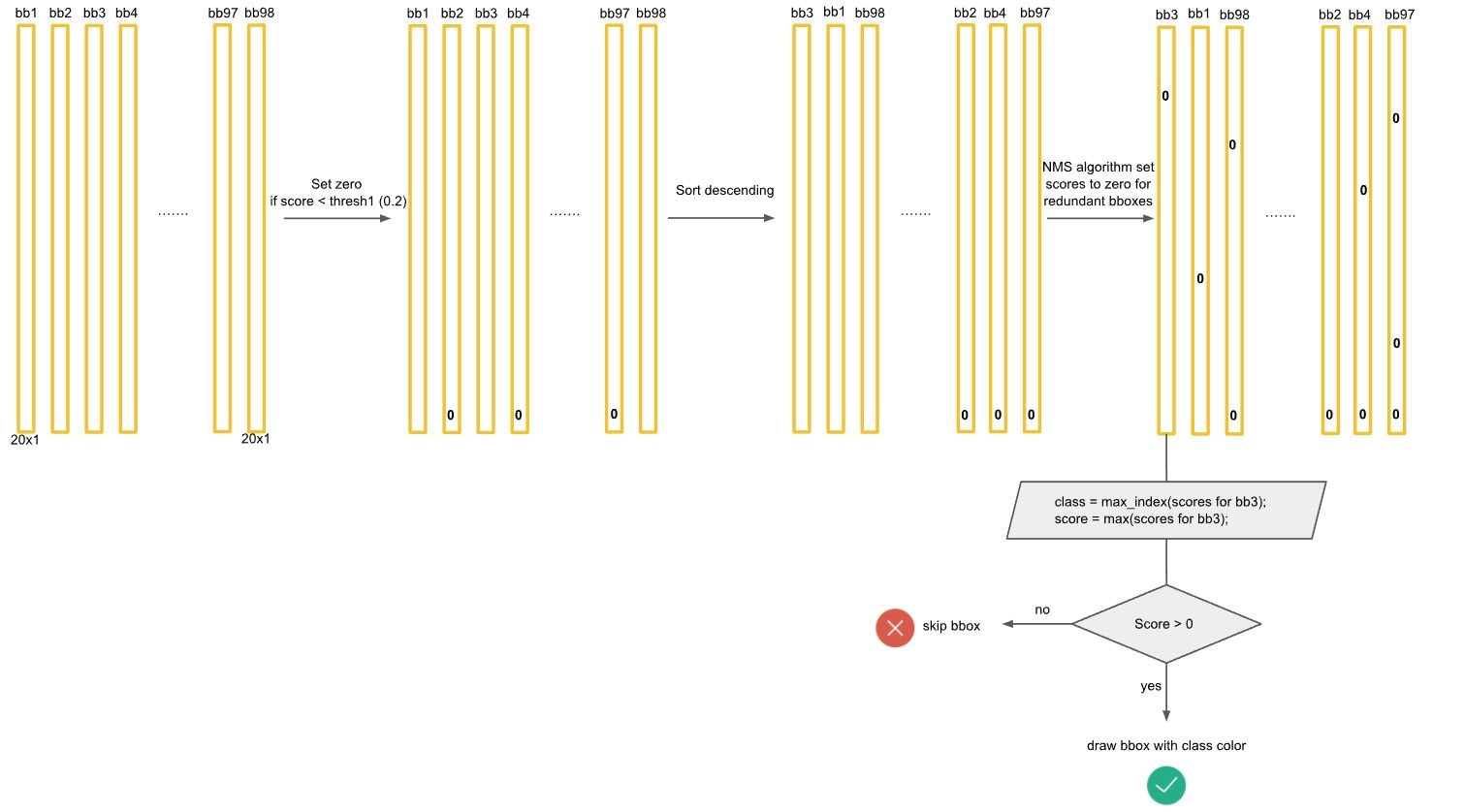
,最终得到98个20×1的向量。 - 进行NMS非极大抑制,即:第一步,将得到的98个20×1的向量中,小于置信度阈值的值归为0.第二步,对20个类分类别的进行NMS,例如,先对第一个类Dog类进行NMS,根据Dog类的概率排序,用概率最大的bbox分别与其他dog概率不为零的bbox计算IOU,当IOU大于阈值,就将置信度较小的bbox的dog类置信度设为0,以此类推,当最大bbox已经与所有不为零的bbox进行了处理,则用排名第二的再次进行相同处理,知道dog类处理完成。20个类每一个类都进行相应处理。
![OvwfP0.jpg]()
- 处理后得到一个稀疏矩阵,此时,每一个bbox对应的20个概率中,若还存在不为零的概率,则选出该bbox中最大概率对应的类别,画出该bounding box,写上对应概率与框。
![Ov05FI.png]()
- 经过NMS之后的结果就是最终的预测结果。
![Ov3uSs.jpg]()
- 利用训练阶段训练出的网络,生成7×7×30的张量,得到原始的bbox,共7×7×2=98个
-
缺陷
- 空间限制,一个grid cell只能预测一个类别,对小目标有缺陷,若一个grid cell有多个目标,只能预测出一个,即所有目标全部检出的能力较差,小目标与密集目标能力较差
- 新的场景和不寻常的场景受限,池化层和下采样层会导致空间信息的缺失。
- 损失函数对大小框同等对待,对大框而言一点点误差能接受,而对于小框而言,一点点误差也会带来很大的影响,yolov1的主要误差来源就是分类正确但是定位误差较大
- mAP较低
- 召回率较低
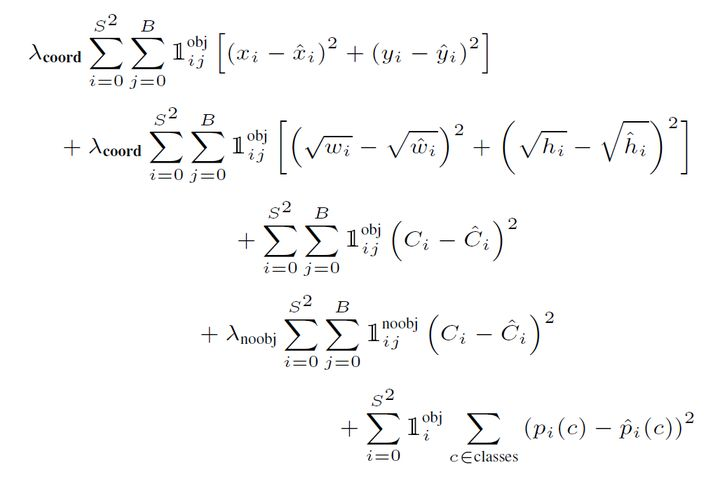


YOLOV2
YOLOv1虽然检测速度宽,但是在检测精度上不如R-CNN系列算法,在物体定位方面也不够准确,召回率较低。因此在保持检测速度的前提下,提出了几种改进策略,如下:
-
Batch Normalization
在每一个卷积后都添加Batch Normalization层,可以提高模型收敛速度,起到一定的正则化效果,降低模型的过拟合,使mAP提高了2.4%。- BN层的具体处理
- 训练阶段
在一个batch的训练中,对每一个样本的同一个神经元,从上一个神经元进行线性计算后,求所有样本该神经元均值、标准差,再做归一化。把归一化后的响应值乘γ再加上β。随后再进行激活处理。(γ、β通过训练得到)
![OxLUEQ.jpg]()
在CNN中进行Batch Norma时,将一个特征图看做一个神经元进行处理, - 预测阶段
预测时,一般一次只需要预测一个样本或很少,此时若计算均值与方差会有偏差,故此训练时,保存每组mini-batch训练数据在网络中每一层的\(\mu_{\text {batch }}\)与\(\sigma_{\text {bateh }}^{2}\),然后使用整个样本统计量对Test数据进行归一化。
\[\mu_{\text {test }}=E\left(\mu_{\text {batch }}\right) \]\[\sigma_{\text {test }}^{2}=\frac{m}{m-1} \mathbf{E}\left(\sigma_{b a t c h}^{2}\right) \]\[B N\left(X_{\text {test }}\right)=\gamma \cdot \frac{X_{\text {test }}-\mu_{\text {test }}}{\sqrt{\sigma_{\text {test }}^{2}+\epsilon}}+\beta \] - 训练阶段
- BN层的具体处理
-
High Resolution Classifier
- YOLOV1在ImageNet分类数据集上采用大小为224×224的图片作为输入进行预训练,然后直接用448×448的高分辨率数据集上进行finetune,检测模型可能难以快速适应高分辨率。
- YOLOV2在采用224×224图像进行分类模型预训练后,再采用448×448的高分辨率样本进行微调(10个epoch),使网络逐渐适应448×448的分辨率,再使用448×448的检测样本进行训练,缓解了分辨率突然变换造成的影响。
-
Convolutional With Anchor Boxes
- YOLOv1在训练过程中学习适应不同物体的形状比较困难,导致在精确定位方面表现较差
- YOLOv2借鉴了Faster R-CNN的方法,用卷积层与RPN来预测Anchor Box的偏移值与置信度.其实,对于中心点(x,y)的预测跟YOLOv1原理相同,都是预测相对于grid的位置,只不过其经过了sigmoid函数公式变换,将中心点约束在一个grid内;对于宽高的预测,跟Faster R-CNN的思想一致,学习目标是anchor的偏移量(而不直接是GT的宽和高,参考RCNN的计算过程)
- 为了使最后的卷积层可以有更大的分辨率,YOLOv2将其中一个Pooling层去掉,并且用416X416大小的输入代替原来的448X448,目的是为了是网络输出的特征图有奇数大小的宽和高,进而使每个特征图在划分网格的时候只有一个中心单元格.
- YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值,网络输出为13×13×(5×(5+20)),其中,第一个5为anchor的个数,第二个5为每一个anchor的位置信息和置信度,20为每一个anchor的类别概率。
-
Dimension Clusters
在Faster-RCNN和SSD中,Anchor Box的尺寸是手动选择的,有一定的主观性.若能选取合适的Anchor Box,可以使模型更加容易学习并预测出准确的bounding box,因此YOLOv2采用k-means聚类方法对训练集做了聚类分析,综合结果,选择5个先验框,大小如下:COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828) VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)其值应是相对于特征框(13×13)的大小
-
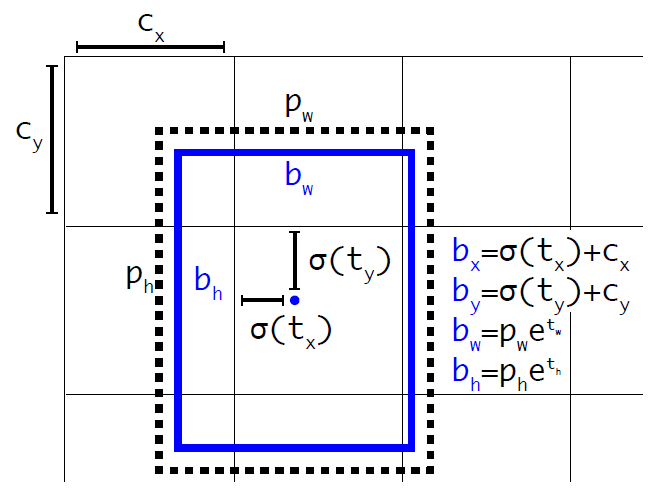
Direct location prediction
- YOLOV2刚引入anchor来预测边界框相对先验框的offsets时,没有对公式做任何限制,模型预测的bounding box中心点可能出现在任何位置,导致模型不稳定
- 调整预测公式,使用sigmoid处理,将范围约束在(0,1)之间。
\[b_{x}=\sigma\left(t_{x}\right)+c_{x} \]\[b_{y}=\sigma\left(t_{y}\right)+c_{y} \]\[b_{w}=p_{w} e^{t_{w}} \]\[b_{h}=p_{h} e^{t_{h}} \]\[\left.\operatorname{Pr}(\text { object }) * \operatorname{IOU}(b, \text { object })=\sigma{\left(t_{o}\right.}\right) \]式中:
\(t_{x}、t_{y}、t_{w}、t_{h}\)为网络输出结果;
\(p_{w}、p_{h}\)是anchor相对于特征图的宽高;
\(b_{x}、b_{y}、b_{w}、b_{h}\)为预测框相对于特征图的位置参数,将其除以特征图的宽(或高)再乘以原图的宽(或高)即可得到原图上的预测框。
![XCaMWR.png]()
-
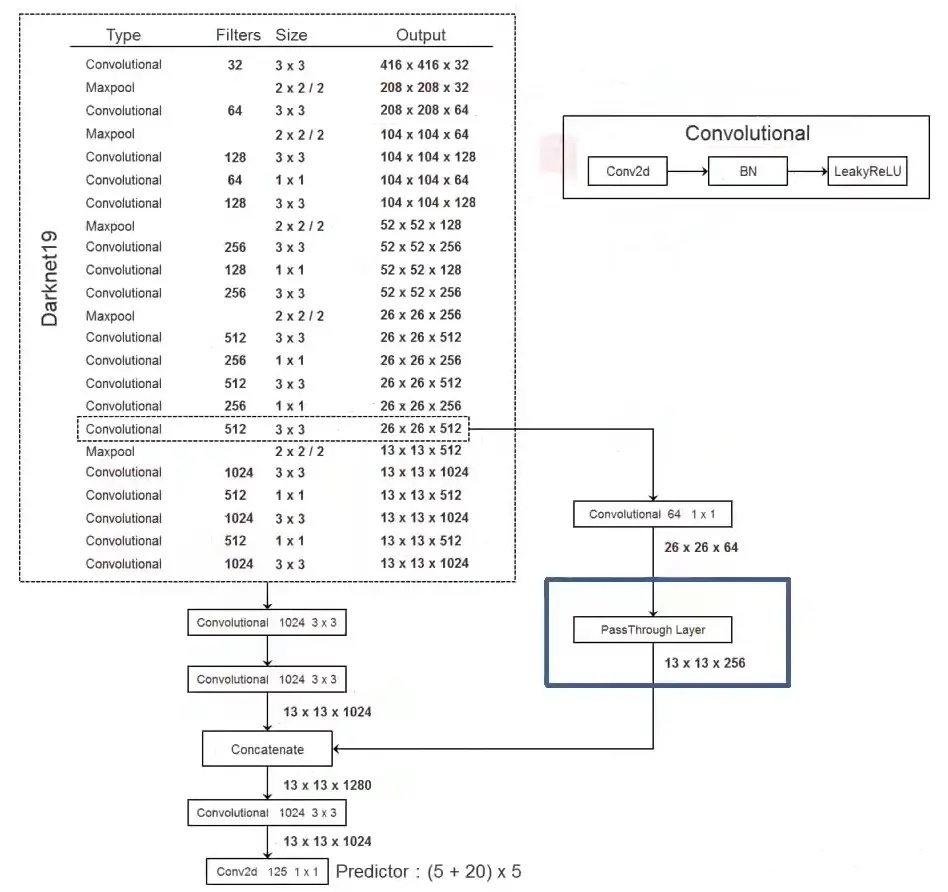
Fine-Grained Features (细粒度特征融合)
YOLOv2图像的输入大小为416X416,经过5次下采样后得到13X13的特征图,并以此特征图采用卷积来做预测,足够预测大物体,但是若要预测小物体还需要更精细的特征图,因此YOLOv2提出了一种 passthrough 层用以利用更加精细的特征图.
![XCwIdU.png]()
YOLOv2利用最后一层下采样的输入(也就是26X26X512的特征图)先经过一个中间卷积层,用64个1×1卷积核进行卷积,再经过passthrough处理,变成13X13X256的特征图,YOLOv2的mAP提升了1%。 -
New Network: Darknet-19
![XC0xcn.jpg]()
-
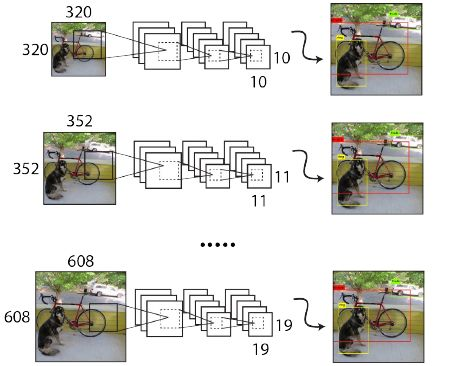
Multi-Scale Training
由于YOLOV2的模型只有卷积层与maxpooling,所以输入可以不限制于416X416大小的图片.为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,就是在训练过程中每间隔一定的迭代次数后改变输入图像的大小:
![XPpldA.png]()
YOLOv2下采样步长为32,因此输入图片大小要选择32的倍数(最小尺寸为320X320 最大尺寸为608X608).在训练过程中,每隔10次迭代随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练.
从VOC数据集的结果可得- 采用较低分辨率的图片mAP值略低,但是速度更快
- 采用较高分辨率的图片mAP值较高,但是速度较慢
-
训练过程
整个训练过程由三个阶段组成,第一阶段,用分辨率为224224的ImageNet 1000类图片预训练darknet-19网络(160个epoch),第二阶段用分辨率为448448的图片微调网络(10个epoch),第三阶段为检测训练,用去掉网络的最后三层(卷积、池化、softmax),用上图的网络进行训练。
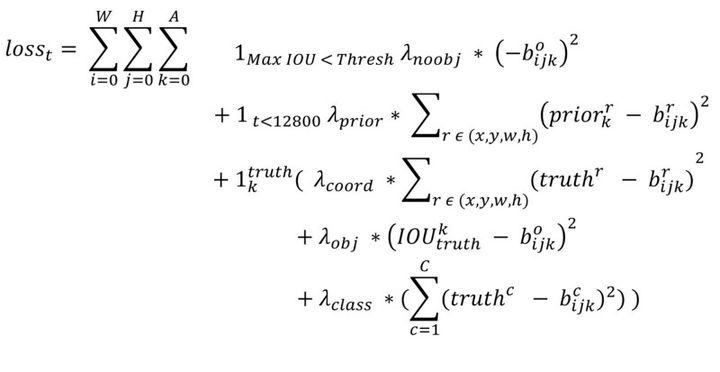
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的先验框计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的边界框只计算置信度误差(此时target为0)。YOLOv2和YOLOv1的损失函数一样,为均方差函数。
![XPu0PO.png]()
- 第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
- 第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。
- 第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
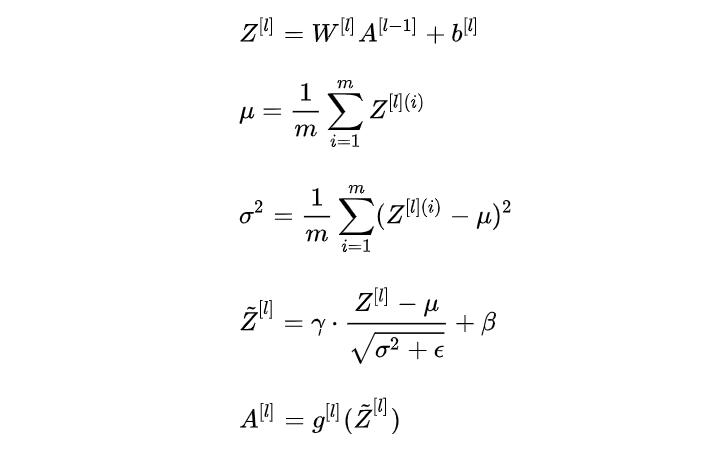
YOLOV3
-
主要创新
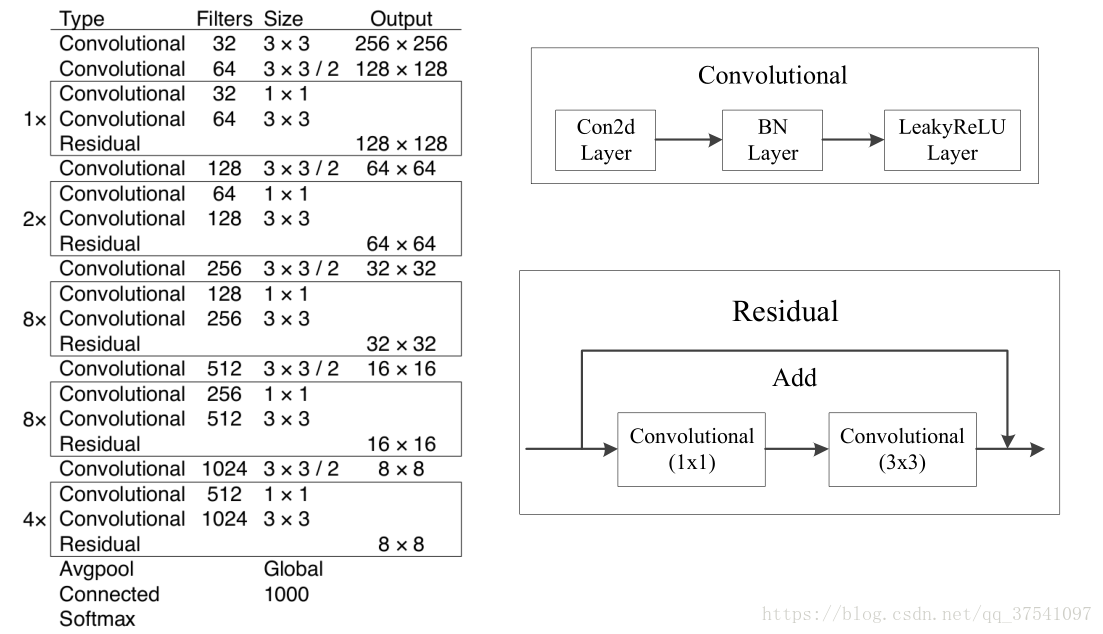
- 残差网络
骨干网络采用了Darknet53,有53层卷积,其中加入了残差网络,防止网络退化。 - FPN网络
借鉴了FPN(Feature Pyramid Network)使用3个尺度的特征map,小的特征map提供语义信息,大的特征map体更细粒度信息。小的特征map通过上采样和大尺度做融合。有效地检测小目标。
- 残差网络
-
网络结构
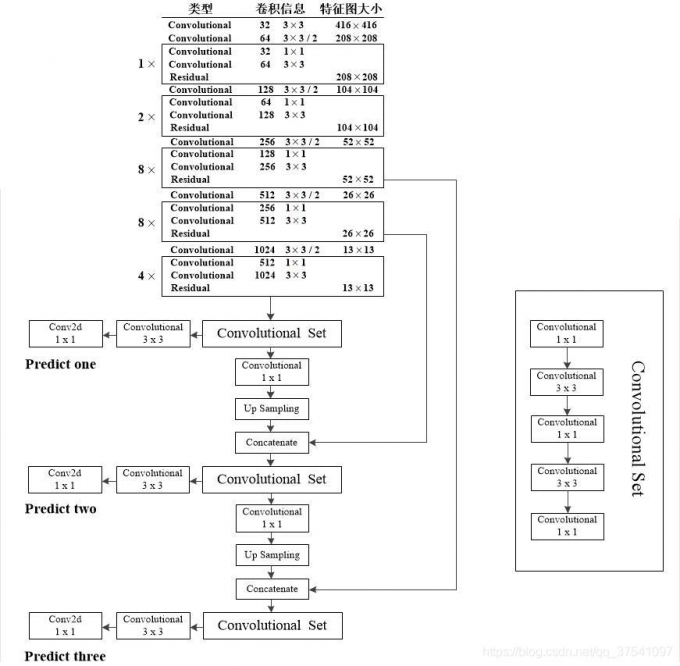
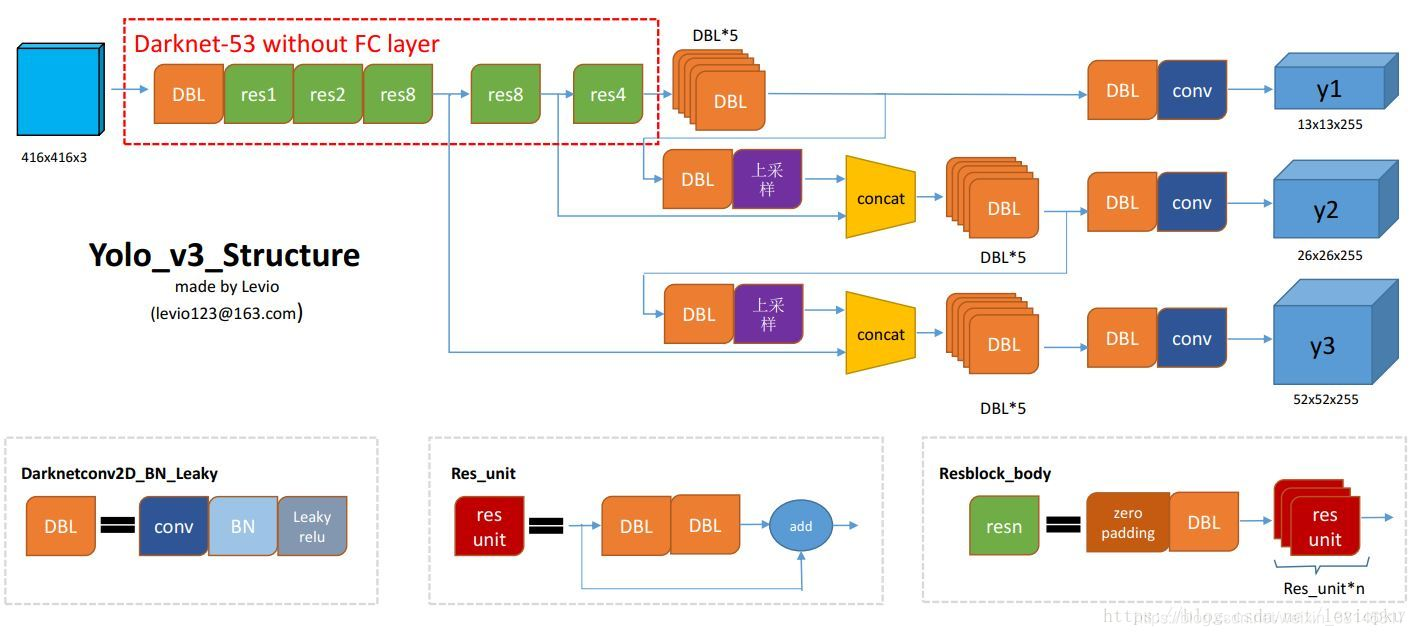
- Darknet-53
![XZaccD.png]()
- yolov3
![XZdyan.md.png]()
![XZBvsU.png]()
- Darknet-53
-
损失函数
![XZ6kAe.md.jpg]()
式中:
乘上\(2-w × h\),加大对小框的损失,更好的检测出小目标.
B为anchor的个数,为3.
其余与yolov1相同
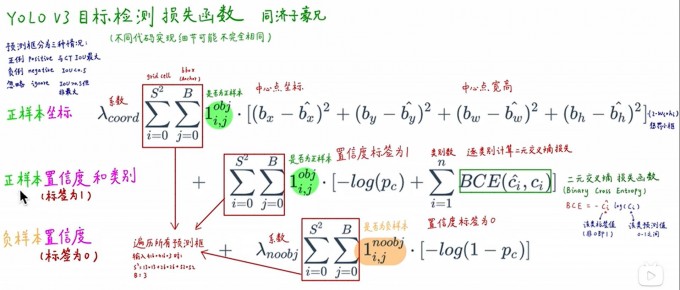
与yolov1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由那个与ground truth的IOU最大的anchor box预测它,而剩余的两个anchor box不予该GT框匹配。(YOLOv3需要假定每个cell至多含有一个ground truth,而在实际上基本不会出现多于1个的情况。)每个GT目标仅与一个anchor相关联,与GT匹配的anchor box计算坐标误差、置信度误差(此时target为1)以及分类误差,而其他anchor box只计算置信度误差(此时target为0)。
对于重叠大于等于0.5的其他先验框(anchor),忽略,不算损失。
YOLOV4
- 主要优化
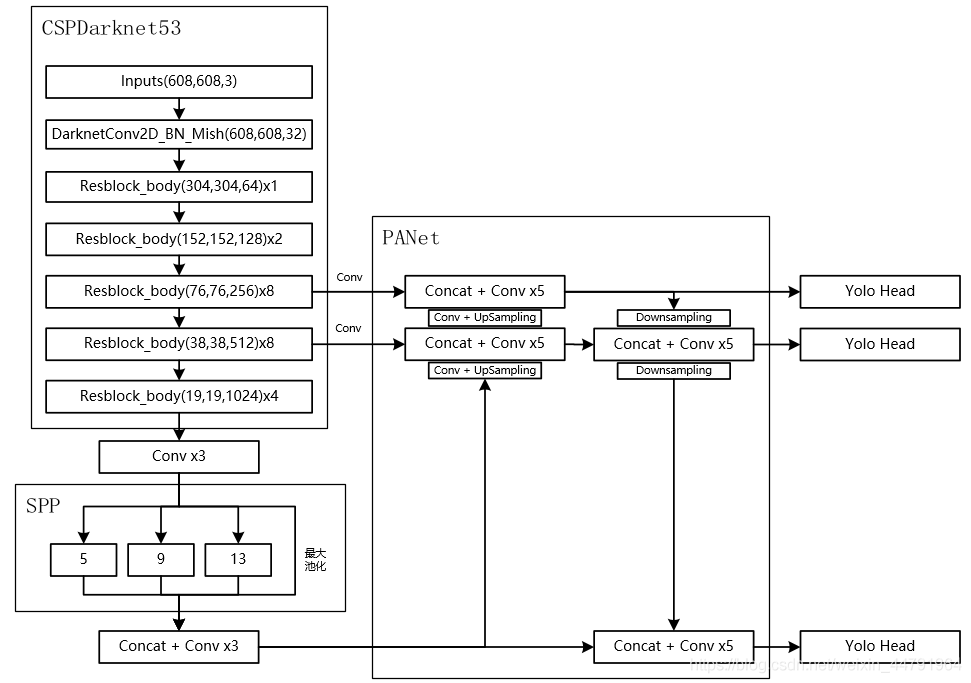
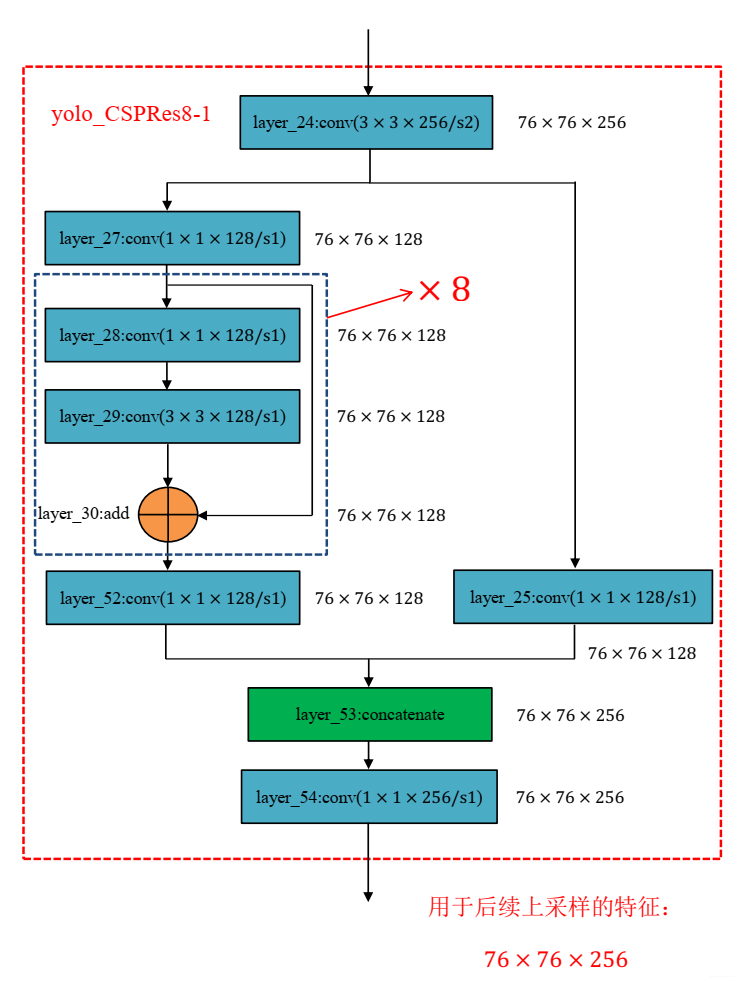
- CSPDarknet-53
主干特征提取网络由DarkNet-53优化为CSPDarknet-53,
![Xu1ifU.png]()
在Darknet-53中的残差结构中加入了CSP结构,即将特征图分为两个部分,其中一部分进行常规处理,最后两部分合并在一起。CSP结构降低计算代价,提升速度的同时,精度也略微提升。
![Xu1LAx.png]()
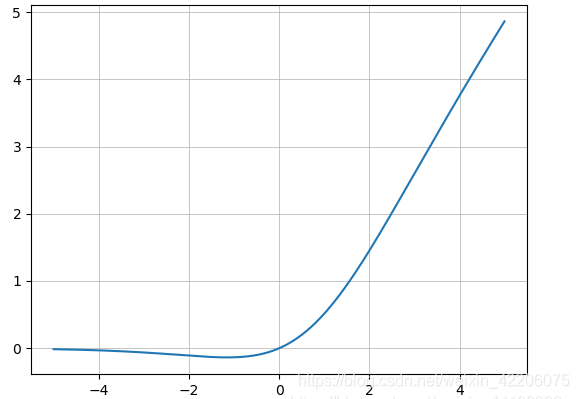
主干特征提取网络中不再使用leaky relu激活函数,改用mish激活函数,
\[M i s h=x \times \tanh \left(\ln \left(1+e^{x}\right)\right) \]![XuYEZj.png]()
mish函数具有以下几个特点:
1、无上限,避免梯度消失
2、有下限,一定的正则化效果;3、光滑;
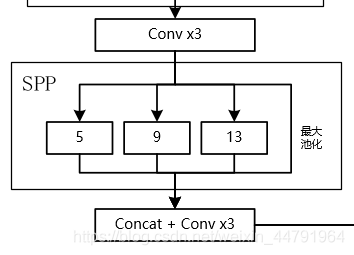
4、非单调.- 颈部采用spp、PAN
- SPP
![XuNMb4.png]()
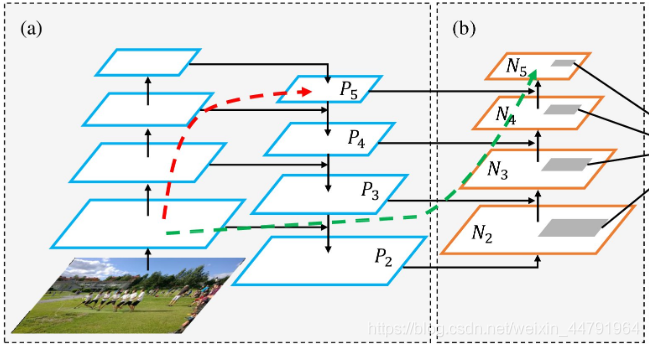
它能够极大地增加感受野,分离出最显著的上下文特征。 - PANet
![XuNxo9.png]()
PANet(Path Aggregation Network路径聚合网络)
YOLOv3中采用的FPN特征金字塔网络进行了自顶向下的特征融合,而PAN网络在FPN的自顶向下的路径之后又添加了一个自底向上的路径,进行特征的反复提取。
- SPP
- Eliminate grid sensitivity
![XCaMWR.png]()
这是yolov3关于计算预测目标中心的计算公式图,但当真实目标中心点非常靠近网格的左上角点或者右下角点时,网络的预测值需要到负无穷或正无穷,一般无法取到。yolov4引入了一个大于1的缩放系数\({\rm scale}_{xy}\)
\[b_{x}=\left(\sigma\left(t_{x}\right) \cdot \text { scale }_{x y}-\frac{\text { scale }_{x y}-1}{2}\right)+c_{x} \]\[b_{y}=\left(\sigma\left(t_{y}\right) \cdot \text { scale }_{x y}-\frac{\text { scale }_{x y}-1}{2}\right)+c_{y} \]通过引入这个系数,网络的预测值能够很容易达到0或者1,我看现在比较新的实现方法包括YOLOv5都将\({\rm scale}_{xy}\)设置为2.- Mosaic数据增强
在数据预处理时将四张图片拼接成一张图片,增加学习样本的多样性。
取四张图片进行翻转、方所、色域变化等,再组合。
![XuBZG9.png]()
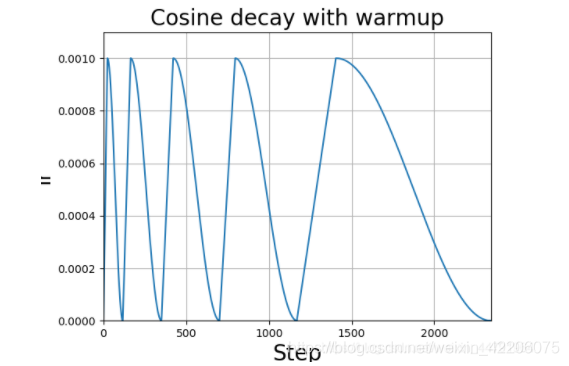
- 学习率余弦退火衰减
在yolov3中,学习率一般都是使用衰减学习率,就是每学习多少epoch,学习率减少固定的值。
在yolov4中,学习率的变化使用了一种比较新的方法:学习率余弦退火衰减。
上升的时候使用线性上升,下降的时候模拟cos函数下降。执行多次。
![XugrnA.png]()
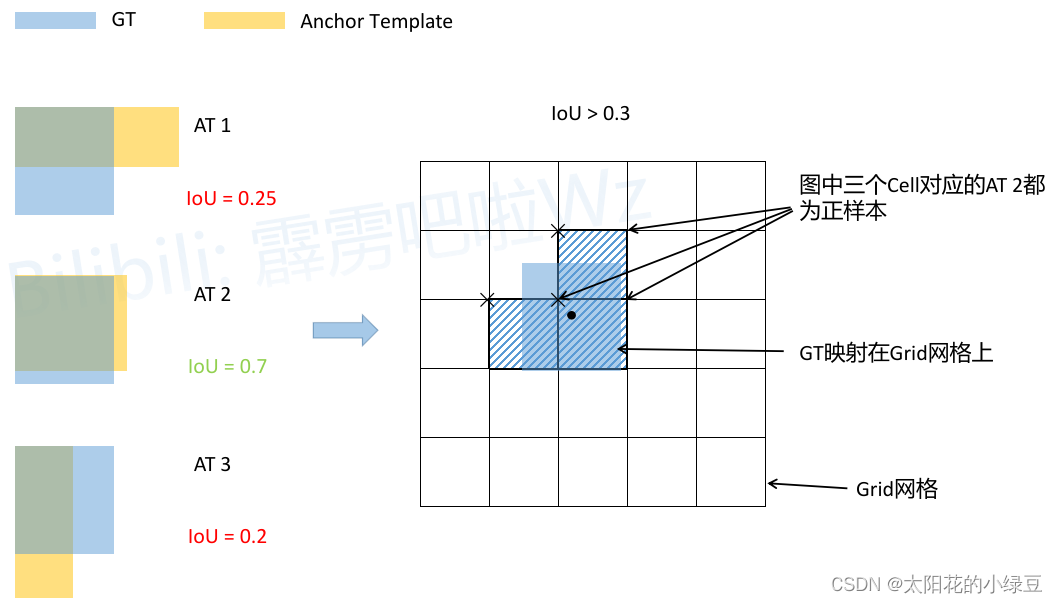
- IoU threshold(正样本匹配)
在YOLOV3中,每一个GT都只对其分配一个其中心点所在grid cell的IOU最大的anchor。
YOLOv4中对中心点的解码中引入了缩放因子,通过缩放后网络预测中心点的偏移范围已经从原来的(0,1)调整到了(?0.5, 1.5)。所以对于同一个GT Boxes可以分配给更多的Anchor,即正样本的数量更多了。只要某一个grid cell的左上角距离GT中心点的横纵距离在-0.5到1.5之间,其对应的anchor也可当做正样本。
![Xu6SBt.png]()
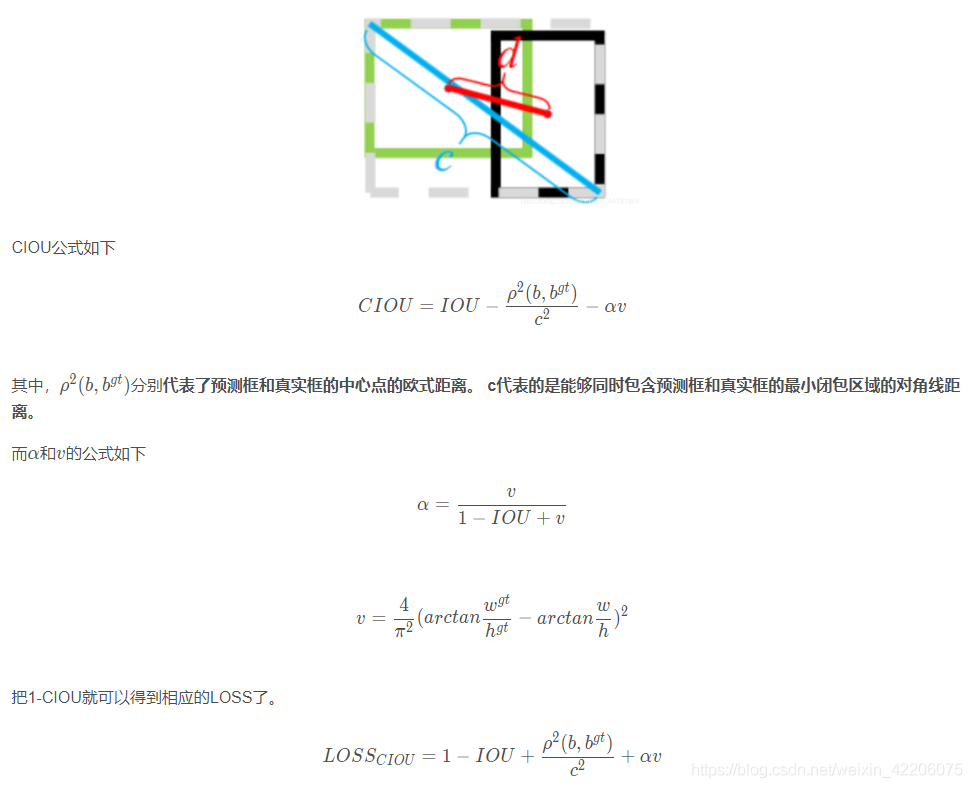
- 损失函数
![Xu6gbt.png]()
![XucRy9.png]()
- Lable Smoothing
Lable Smoothing是分类问题中错误标注的一种解决方法。
对于分类问题,特别是多分类问题,常常把向量转换成one-hot-vector(独热向量)
理论而言,如果标签为1时,模型应该尽力去获得最接近的output,如0.999。而这样真的好吗?如果某些标签错误,那模型拟合的目标反而离我们需要的结果越来越远。因此,使用label_smoothing可以很好的缓解这样的问题。
- CSPDarknet-53

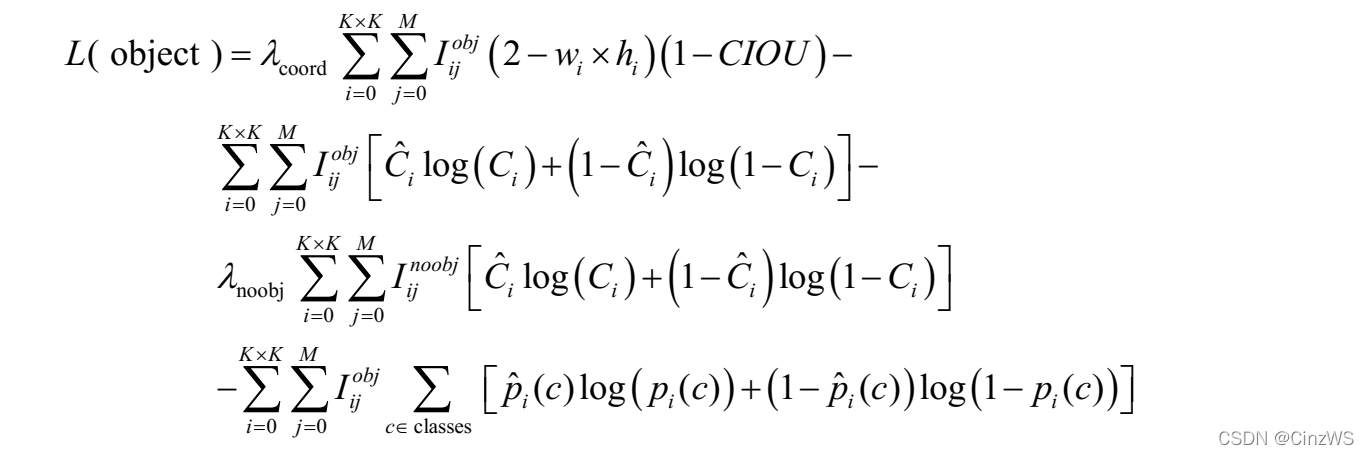


 浙公网安备 33010602011771号
浙公网安备 33010602011771号