
软工实践寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》并更好地提出问题;熟悉GitHub的操作使用以及git相关语句的使用;完成WordCount编程 |
| 作业正文 | 寒假作业2/2 |
| 其他参考文献 | CSDN+博客园 |
目录:
- part1:阅读构建之法并提问
- part2:完成WordCount编程
- Github地址
- PSP表格
- 解题思路
- 代码规范制定链接
- 设计与实现的过程
- 性能改进
- 单元测试
- 异常处理
- 心得体会及收获
part1:阅读《构建之法》并提问
1.在第二章个人开发流程中对比了大学生和工程师分别完成项目的各个阶段所花时间的占比,得出现象工程师在“需求分析”和“测试”这两方面花的时间明显比大学生高,但是在具体编码上,工程师比学生要花的时间少,因此显然从学生到职业程序员,并不是更加没完没了地写程序——花在写代码的时间反而少了许多。
我的观点:我认为从学生到职业程序员,随着编程能力的提升,职业程序员在写具体代码中能更加轻松的实现,但是大学生由于各项能力的不足,花的时间明显更多。我认为这样的比较显得太过于片面,由此并不可以得出大学生在成为的职业程序员的过程中,花在代码上的时间就一定更少。
2.第四章中提出了结对编程的概念,结对编程的好处很多,如可以提高设计和代码质量,可以给工作带来很大信心以及可以互相交流经验,促进学习等。
我的观点:结对编程虽然有很多好处,但与此同时,结对编程并未考虑到两位成员的能力,它对于两个人的不同的能力要求很高,如果两个的能力一样高或一样低,该如何分配项目中的任务等一系列的问题,所以结对编程的风险也是很大的,我们该如何权衡呢?
3.在第三章中,提出了团队的软件流程TSP,TSP对团队成员的要求很多,其中提出理性地工作,反对个人需要灵感和激情,认为这只属于业余爱好者。职业人士只有每天持续的工作才会有所成就。
我的观点:这种说法我无法认同。现在的大部分公司的很多程序员每天干着同样的工作,如果年轻时没有得到一个很好的地位,等到老了的时候思维就没有年轻的时候那么活跃了,甚至到后期可能面临失业的情况。所以我觉得在工作时应该保持激情,不断学习新的知识,灵感也需要不断地去涌现,这两者都是不可或缺的,因为这是你走向成功的一种渠道。
4.第八章中谈到了需求分析,一个软件团队必须了解和挖掘出软件利益者的需求才能动手开发项目。
我的观点:如果团队所挖掘的需求和软件利益者的需求有一定差距,但这个需求可能是团队认为所必须的,可能会带来更大的收益,这就与客户的需求起了一定的冲突。这种情况是该完全按照客户的要求来做还是应该和客户进行沟通交流,试图说服他们。
5.第十六章中谈到的四个象限划分产品,通过四个象限对一个产品的各种功能进行分类。我们也可以通过这四个象限对一个团队的多个产品进行分类,帮助团队实施正确的产品开发策略。
我的观点:如果对一个团队的多个产品进行分类,我认为四个象限所圈定的范围太过于局限,有没有可能用更高的象限去划分这些产品呢?能否通过其他的标准来圈定这些象限呢?
附加题
众所周知,学习软件工程专业的同学大部分是男同学,那么可以猜想第一个程序员是不是男的呢?答案是no。
话说这位贵族小姐,她来头不小。是19世纪英国著名诗人拜伦的女儿,她是一名数学家,也是世界上第一位程序员。她的名字是Ada Lovelace。(由于名字较长,下面简称阿达)
阿达一生做出的成就不少。她设计了巴贝奇分析机上解伯努利方程的一个程序,证明了计算机狂人巴贝奇的分析其可以用于许多问题的求解。后来她在1843年发表的论文里提到了一个叫循环和子程序的概念,并且她相信以后创作复杂音乐、制图和科学研究是可以通过机器来创作的,这在当时是大胆的预见,但在今天都逐渐成为了现实。
现在看来,阿达首先为计算机拟定的“算法”,以及写作的那份“程序设计流程图”都是极为难得和珍贵的,也是史上第一件计算机程序。
后来据说国防部花了10年时间,把所需软件的全部功能混合在一种计算机语言里,为的是想让它能成为军方数千种电脑的标准。
于是在1981年,为了纪念这位程序员,这种语言被正式命名为ADA(阿达)语言,艾达·洛夫雷斯也被公认为“世界上第一位软件工程师”。
part2:完成WordCount编程
Github地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 14 | 15 |
| • Estimate | • 估计这个任务需要多少时间 | 1120 | 1300 |
| Development | 开发 | 440 | 500 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 30 |
| • Design Spec | • 生成设计文档 | 20 | 25 |
| • Design Review | • 设计复审 | 25 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 35 |
| • Design | • 具体设计 | 60 | 80 |
| • Coding | • 具体编码 | 360 | 400 |
| • Code Review | • 代码复审 | 35 | 45 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 45 |
| Reporting | 报告 | 30 | 40 |
| • Test Repor | • 测试报告 | 10 | 20 |
| • Size Measurement | • 计算工作量 | 20 | 25 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1144 | 1310 |
解题思路
问题如下:
1.如何读取文件
2.如何统计字符数
3.如何统计单词总数
4.如何统计有效行数
5.如何统计出现频率前10的各个单词数
6.如何输出到指定文件中
解决方法:
1.用BufferReader读取文件
2.统计在ASCII码范围内的字符数即可
3.用正则表达式来分割字符串,再统计总数
4.用正则表达式来统计有效行数,忽略空行
5.前十频率单词的统计用Map<String,Integer>,再根据键的字典序和值的大小排序
6.用BufferWriter输出到指定文件
代码规范制定链接
设计与实现过程
1.读取文件功能实现
public static String readFromFile(String filePath) {
int temp;
BufferedReader br = null;
StringBuilder sbuilder = null;
try {
br = new BufferedReader(new FileReader(filePath));
sbuilder = new StringBuilder();
while((temp = br.read()) != -1) {
sbuilder.append((char)temp);
}
}catch(FileNotFoundException e) {
e.printStackTrace();
}catch(IOException e) {
e.printStackTrace();
}finally {
br.close();
}
}
return sbuilder.toString();
}
2.统计字符数功能实现
public static int getCharactersNum(String str) {
//字符数统计数量
int num = 0;
char[] temp = str.toCharArray();
for(int i = 0; i < temp.length; i++) {
if(temp[i] >= 0 && temp[i] <= 127) {
num++;
}
}
return num;
}
3.统计单词数功能实现
public static int getWordsNum(String str) {
//单词数的统计量
int num = 0;
String[] temp1 = str.split(Break);
for(int i = 0; i < temp1.length; i++) {
if(temp1[i].matches(word))
{
num++;
String temp = strs[i].toLowerCase();
if(wordsMap.containsKey(temp))
{
int j = wordsMap.get(temp);
wordsMap.put(temp, j+1);
}
else
{
wordsMap.put(temp, 1);
}
}
}
return num;
}
4.统计有效行数功能实现
public static int getLineNum(String str) {
//行数统计数量
File file=new File(str);
int count=0;
if(file.exists()){
BufferedReader in = new BufferedReader(new FileReader(file));
String line;
while((line = in.readLine()) != null){
if(!line.equals("") ){
count ++;
}
}
in.close();
}
return count;
}
5.统计前十频率单词功能实现
public static List<Map.Entry<String, Integer>> sortHashmap() {
List<Map.Entry<String, Integer>> list;
list = new ArrayList<Map.Entry<String, Integer>>(wordsMap.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>(){
public int compare(Entry<String, Integer> m1, Entry<String, Integer> m2) {
if(m1.getValue().equals(m2.getValue())) {
return m1.getKey().compareTo(m2.getKey());
}else return m2.getValue()-m1.getValue();
}
});
return list;
}
int i = 0;
for(Map.Entry<String, Integer> map : list) {
assertEquals(map.getKey(),result[i]);
i++;
System.out.println(map.getKey()+" : "+map.getValue());
}
先排序key后排序value最后输出
6.输出到指定文件功能实现
public static void writeToFile(int characters, int words, int lines, String filePath) {
FileOutputStream fos = null;
OutputStreamWriter writer = null;
BufferedWriter bw = null;
int i = 0;
String str = "characters: " + characters + "\nwords: " + words + "\nlines: " + lines +"\n";
List<Map.Entry<String, Integer>> list = sortHashmap();
for(Map.Entry<String, Integer> map : list){
if(i < 10){
str += map.getKey() + ": " + map.getValue() + "\n";
i++;
}else break;
}
}
思路:先完成读取文件,再分别写出统计字符数、单词数、有效行数的函数,对于前十频率单词的统计,应使用map将单词封装起来,再进行字典序和值大小的排序,最后输出到指定的文件中。
性能改进
输入输出流的选择上使用了BufferReader和BufferWriter,有缓冲区性能更加好,使用StringBuilder效率会更高,统计有效行的实现修改了一种方法,添加异常处理,更加严谨,读取行数使用多线程会更加可观
单元测试
1.测试统计字符数
@Test
void testGetCharactersCount(){
String str="words\nfiles\nFiles\nwindows26\nwindows1998\n123456f\nfill\n\rzzz\nzzzwh\n\n\n";
int looptime=10000;
String teststr="";
for(int i=0;i<looptime;i++){
teststr+=str;
}
assertEquals(Lib.getCharactersCount(teststr),660000);
}
2.测试统计单词数
@Test
void testGetWordsCount(){
String str="words\nfiles\nFiles\nwindows26\nwindows1998\n123456f\nfill\n\rzzz\nzzzwh\n\n\n";
int looptime=10000;
String teststr="";
for(int i=0;i<looptime;i++){
teststr+=str;
}
assertEquals(Lib.getWordsCount(teststr),70000);
}
3.测试统计有效行数
@Test
void testGetLinesCount(){
String str="words\nfiles\nFiles\nwindows26\nwindows1998\n123456f\nfill\n\rzzz\nzzzwh\n\n\n";
int looptime=10000;
String teststr="";
for(int i=0;i<looptime;i++){
teststr+=str;
}
assertEquals(Lib.getLineCount(teststr),90000);
}
4.测试单词频数
@Test
void testSortHashMap(){
int looptime1 = 1000;
int looptime2 = 1500;
int looptime3 = 2000;
String str1 = "words\n";
String str2 = "files\n";
String str3 = "Files\n";
String str4 = "windows26\n";
String str5 = "windows1998\n";
String str6 = "123456f\n";
String str7 = "fill\n";
String str8 = "course\n";
String str9 = "zzz\n";
String str10 = "zzzwh\n";
String testStr1 = " ";
for(int i = 0; i < looptime1; i++) {
testStr1 += str1;
testStr1 += str2;
testStr1 += str3;
testStr1 += str4;
}
for(int i = 0; i < looptime2; i++) {
testStr1 += str5;
testStr1 += str6;
testStr1 += str7;
}
for(int i = 0; i< looptime3; i++) {
testStr1 += str8;
testStr1 += str9;
testStr1 += str10;
}
String[] result = {"files","zzzwh", "fill", "windows1998", "windows26", "words","boot","course","nike", "Files", "123456f",
"zzz"};
Map<String, Integer> wordsMap = new HashMap<String, Integer>();
System.out.println(Lib.getWordsCount(testStr1));
System.out.println(Lib.getCharactersCount(testStr1));
List<Map.Entry<String, Integer>> list = Lib.sortHashmap();
int i = 0;
for(Map.Entry<String, Integer> map : list) {
assertEquals(map.getKey(),result[i]);
i++;
System.out.println(map.getKey()+" : "+map.getValue());
}
}
public static void main(String args[]) {
WordCountTest wt=new WordCountTest();
wt.testGetCharactersCount();
wt.testGetWordsCount();
wt.testGetLinesCount();
wt.testSortHashMap();
}
单元测试结果:
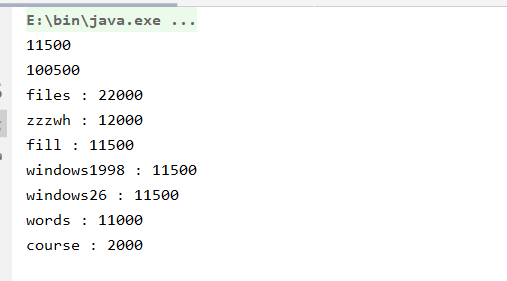
代码覆盖率结果:

出现了一些bug,暂时还未能够解决,希望能得到老师的指点。之后先将测试数据发给同学测试看看能否成功
优化覆盖率应避免不必要和重复的代码,特别对于分支和选择结构等。
异常处理
仅仅讨论了IOException和FileNotFoundException,无自定义异常类,剩余的后续加强修改
心得体会及收获
通过这次作业,我更加深入了解到了java文件的读入和输出,也更加熟练了对Github的操作及使用,这为我后来的学习打下了牢固的基础。新出现的单元测试和代码覆盖率也是让我眼界大开,这些都是只能通过查阅资料去学习的。在编程的过程中也询问了很多同学得到了很多代码上的帮助,也让我深刻意识到与别人之间的差距,愿今后能更加努力,多多了解项目并参与进去。
