一、过拟合与欠拟合
1、回归任务的过拟合和欠拟合
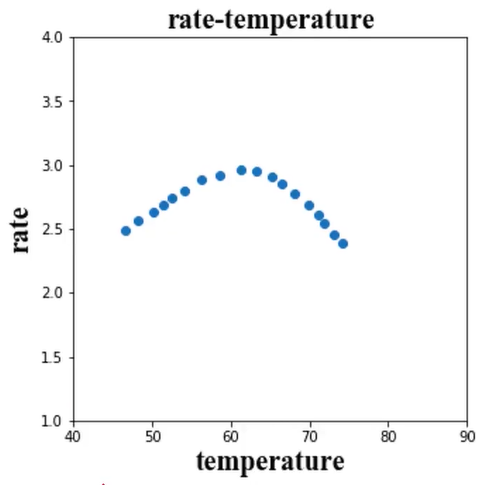
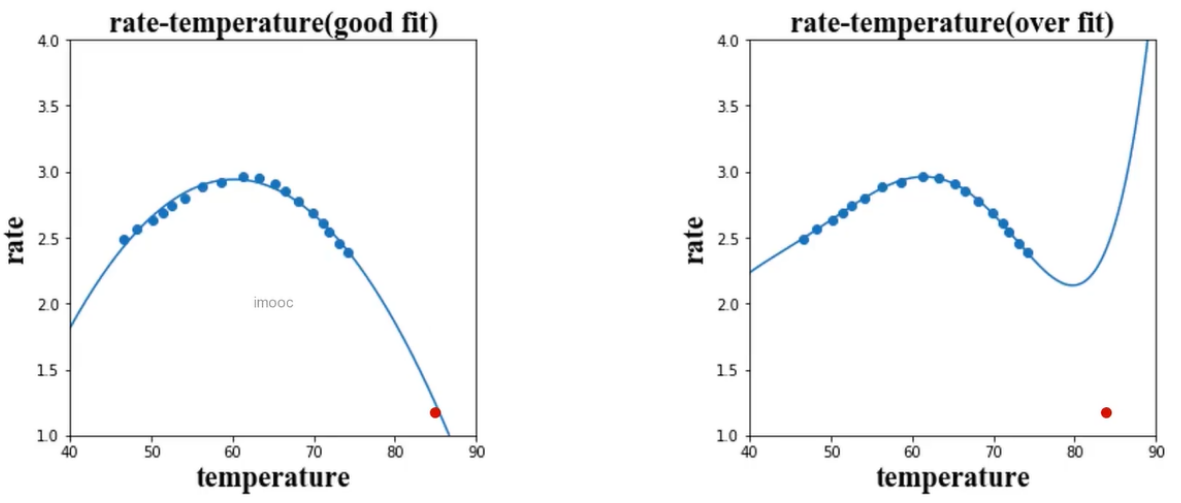
拟合反应速率(rate)与温度(temperature)数据,预测85度时的反应速率。
(1)、good fit
好的模型的预测结果如下图,即开口向下的抛物线,
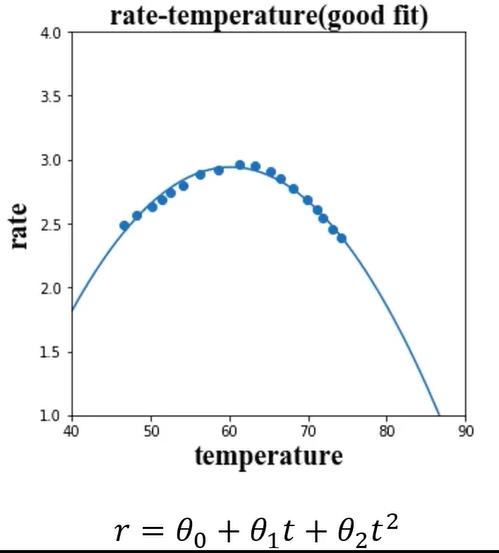
这是一个回归的任务,由于数据点不符合线性分布,故不是线性回归,可以理解为多项式回归,即二项式:r=θ0 + θ1t + θ2t2 。
建模的时候不知道是一次的线性回归还是高幂次的多项式回归,下面来看一下其他的预测结果:
(2)、under fit
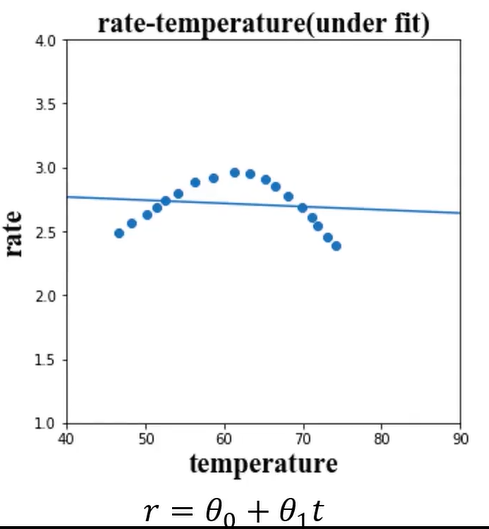
under fit表示欠拟合
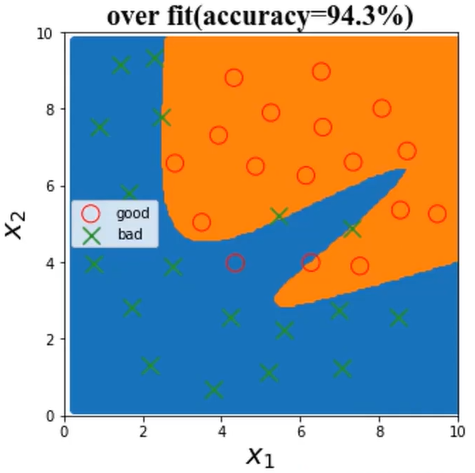
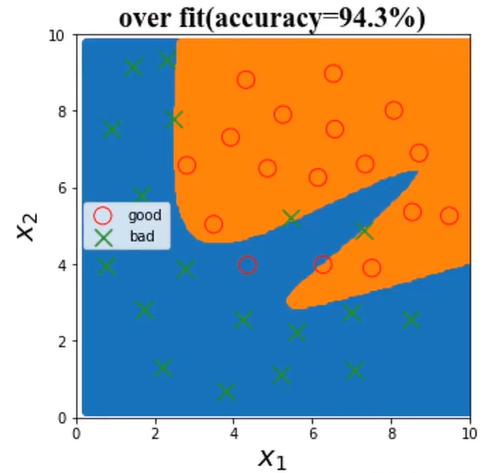
(3)、over fit
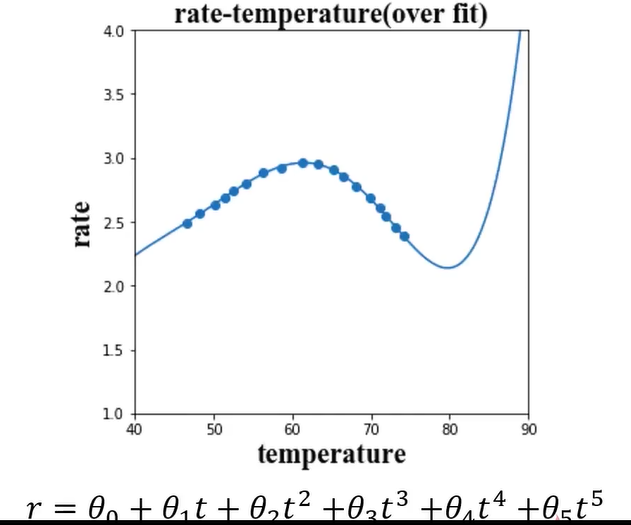
over fit表示过拟合
2、分类任务的过拟合和欠拟合
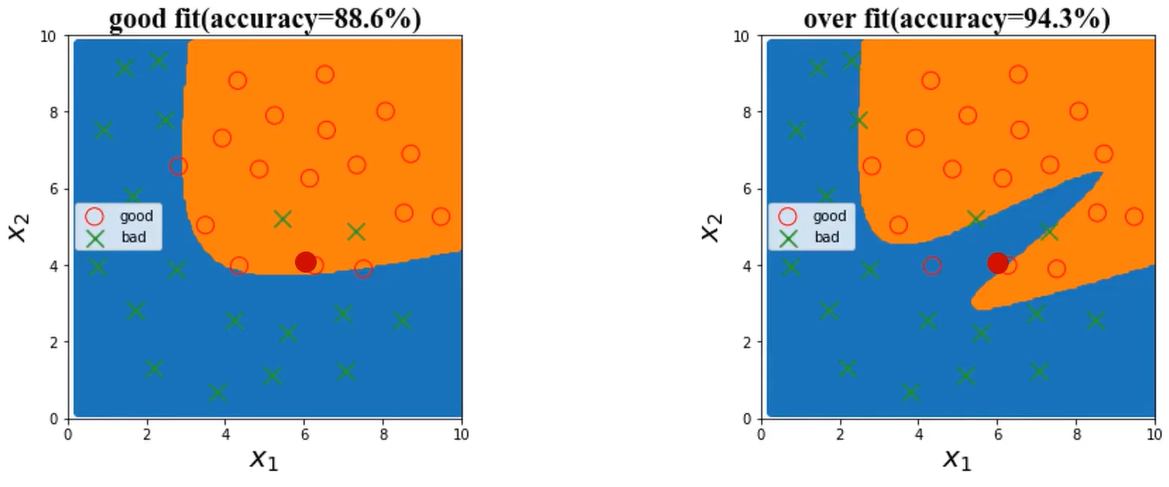
根据检测数据x1、x2,及其标签,判断x1=6、x2=4时所属类别
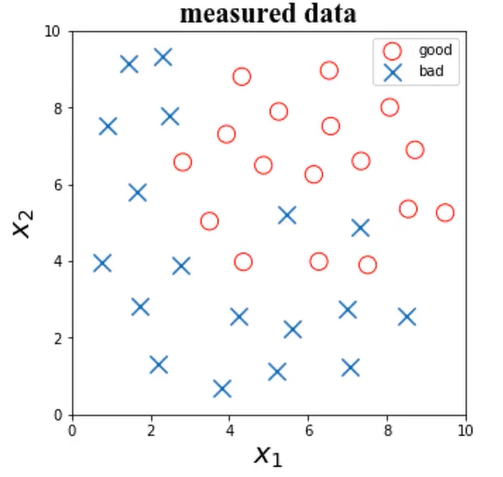
(1)、good fit
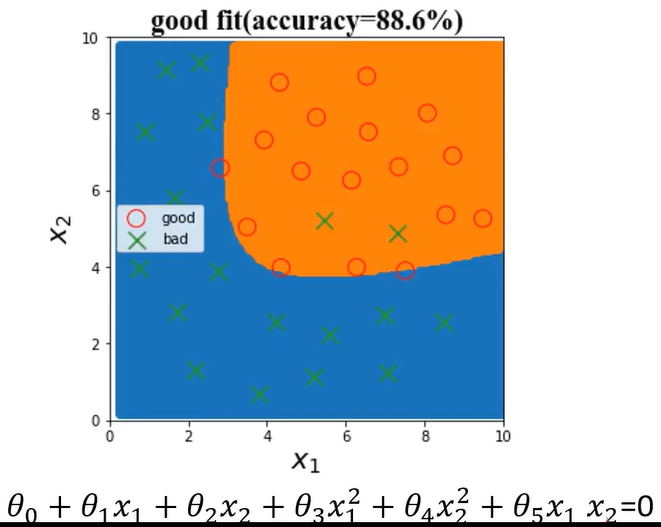
决策边界是二次多项式。
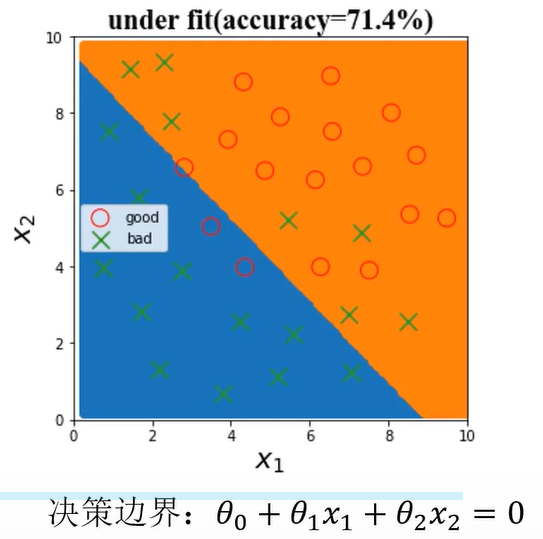
(2)、under fit
(3)、over fit
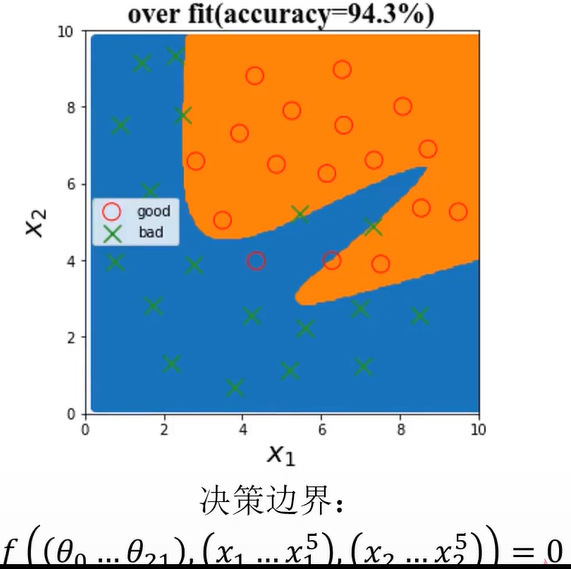
模型不合适,导致其无法对数据实现有效预测

欠拟合可以通过观察训练数据及时发现,通过优化模型结果解决
3、如何解决过拟合问题 ?
原因:
(1)、模型结构过于复杂(维度过高)
(2)、使用了过多属性,模型训练时包含了干扰项信息
解决办法:
(1)、简化模型结构(使用低阶模型,比如线性模型)
(2)、数据预处理,保留主成分信息(数据PCA处理),即降维
(3)、在模型训练时,增加正则化项(regularization)
数据PCA处理:
21维属性变量通过PCA降到5维
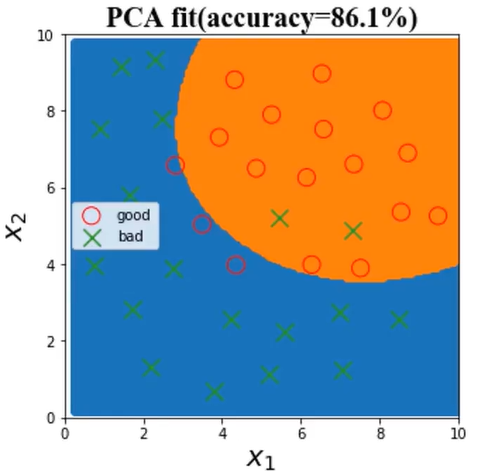
除了可视化,还可以通过测试数据集的准确率上升来判断是否符合预期。
尝试降到更低维度?如降到2维,则有可能是直线了。
增加正则项
(1)、线性回归
最小化损失函数(J):
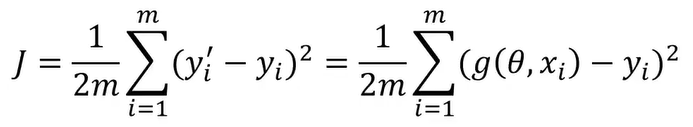
正则化处理后的损失函数(J):
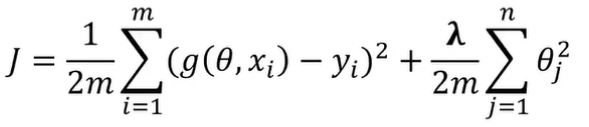
通过引入正则化项,λ取值大的情况下,可约束θ取值,有效控制各个属性数据的影响。
(1)、逻辑回归
最小化损失函数(J):
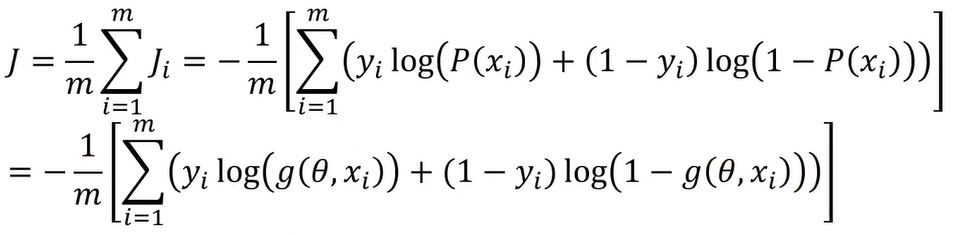
正则化处理后的损失函数(J):
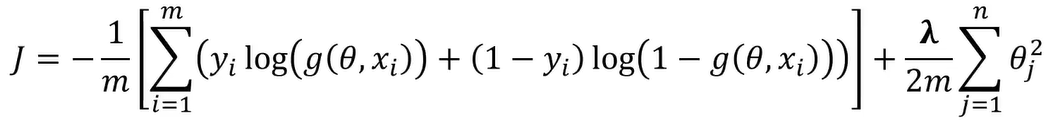
加入正则化项,λ=500000
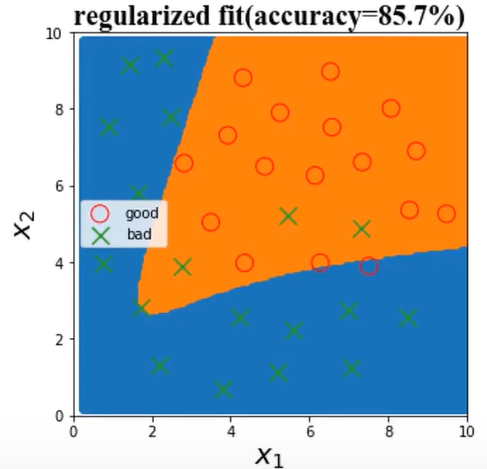
二、数据分离与混淆矩阵
1、数据分离
建立模型的意义,不在于对训练数据做出准确预测,更在于对新数据的准确预测。
线性回归任务:拟合反应速率(rate)与温度(temperature)数据,预测85度时的反应速率
逻辑回归任务:根据检测数据x1、x2,及其标签,判断x1=6、x2=4时所属类别
上面两个例子过拟合,导致新数据预测不准确。
回顾模型训练与评估流程

没有新数据用于评估模型表现怎么办?
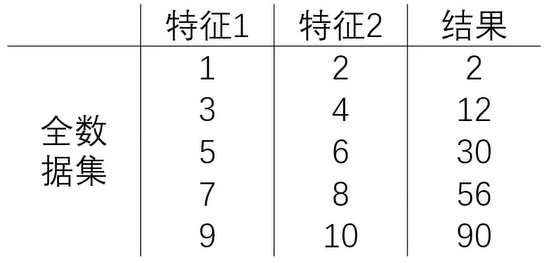
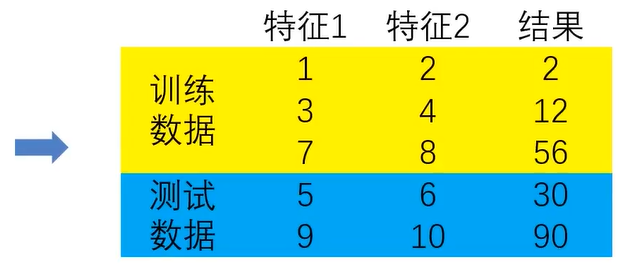
解决办法:对全数据进行数据分离,部分用于训练,部分用于新数据的结果预测!
分离训练数据与测试数据
1、把数据分成两部分:训练集、测试集
2、使用训练集数据进行模型训练
3、使用测试集数据进行预测,更有效地评估模型对于新数据的预测表现。
这样,在没有额外采集新数据的情况下,也能更好的评估模型。
示例:
2、混淆矩阵confusion matrix
使用准确率进行模型评估的局限性

分类任务中,计算测试数据集预测准确率(accuracy)以评估模型表现
局限性:无法真实反映模型针对各个分类的预测准确度。
使用准确率进行模型评估的局限性
二分类任务
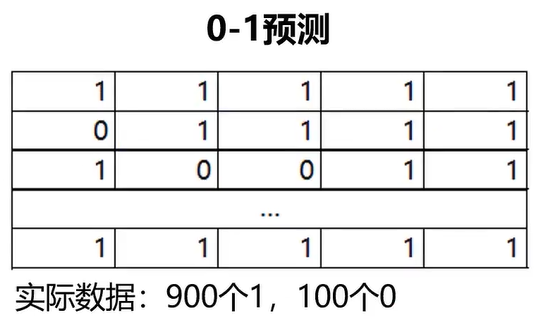
模型1:850个1预测正确,50个0预测正确,准确率90%
模型2:预测所有的样本结果都是1准确率90%(空准确率)
模型1、2表现有差异吗? 不一样,模型2相当于啥都没做。而模型1的适用性会更广一些。
准确率可以方便的用于衡量模型的整体预测效果,但无法反应细节信息,具体表现在:
(1)、没有体现数据预测的实际分布情况(0、1本身的分布比例)
(2)、没有体现模型错误预测的类型
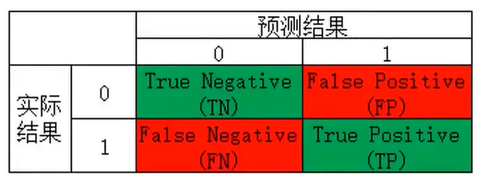
混淆矩阵
混淆矩阵,又称为误差矩阵,用于衡量分类算法的准确程度。
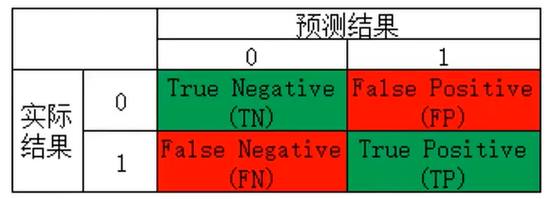
• True Positives(TP):预测准确、实际为正样本的数量(实际为1,预测为1)
• True Negatives(TN):预测准确、实际为负样本的数量(实际为0,预测为0)
• False Positives(FP):预测错误、实际为负样本的数量(实际为0,预测为1)
• False Negatives(FN):预测错误、实际为正样本的数量(实际为1,预测为0)
记忆方法:(预测结果正确或错误,预测结果为正样本或负样本)
通过混淆矩阵,计算更丰富的模型评估指标
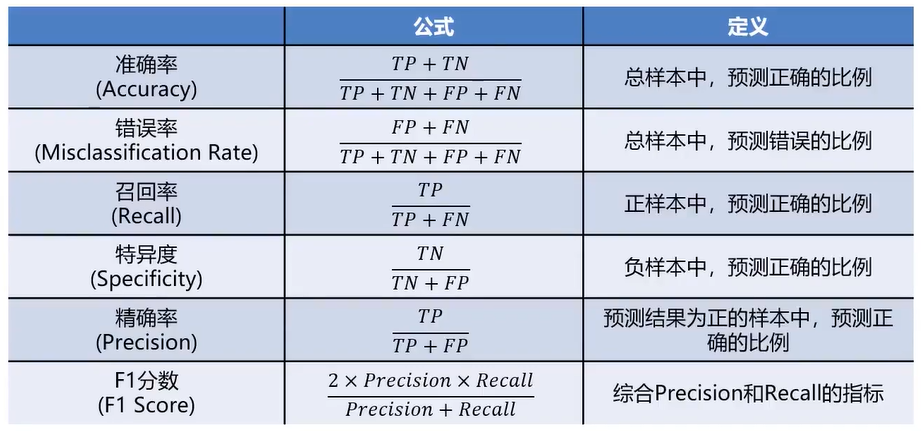
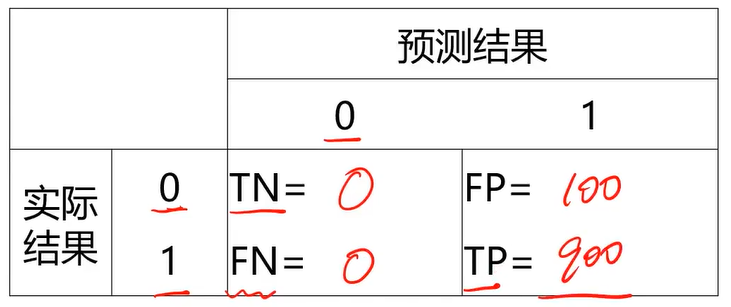
举例:
0-1预测
实际:900个1,100个0
预测:1000个1,0个0
假设负样本为0,正样本为1
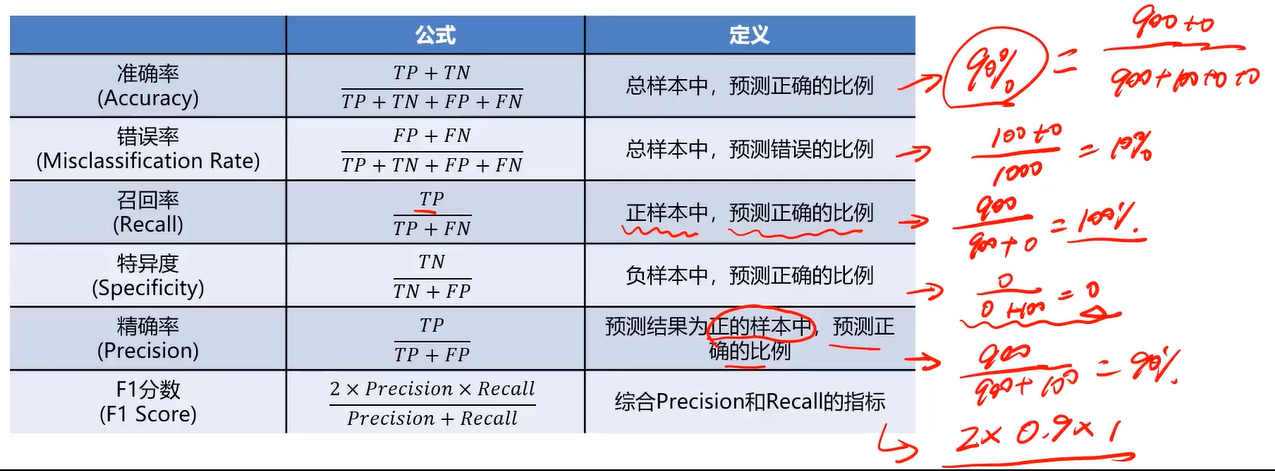
混淆矩阵指标特点:
(1)、分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息(TP\TN\FP\FN)。
(2)、通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型。
哪个衡量指标更关键?
衡量指标的选择取决于应用场景
(1)、垃圾邮件检测 (正样本为“垃圾邮件”):
希望普通邮件(负样本)不要被判断为垃圾邮件(正样本),即:判断为垃圾邮件的样本都是判断正确的,需要关注精确率;
还希望所有的垃圾邮件尽可能被判断出来,需要关注召回率。
(2)、异常交易检测 (正样本为“异常交易”):希望判断为正常的交易(负样本)中尽可能不存在异常交易,需要关注特异度。
三、模型优化
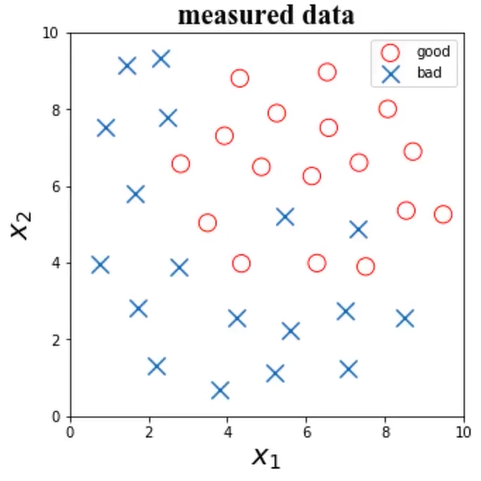
任务:根据检测数据x1、x2及其标签,判断x1=6、x2=4时所属类别
问题一:用什么算法??
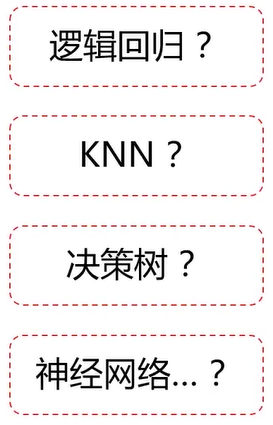
问题二:具体算法的核心结构或参数如何选择??
逻辑回归边界函数用什么:线性、多项式??
KNN 的核心参数n_neighbors取多少合适??
问题三:模型表现不佳,怎么办??
训练数据准确率太低(欠拟合)
测试数据准确率下降明显(过拟合)
召回率/特异度/精确率低
如何提高模型表现?
1、数据的重要性
数据质量决定模型表现的上限!数据不好,肯定得不到一个好的结果。
Always check:
1、数据属性的意义,是否为无关数据。(如身体健康指数中,姓名是无关的属性)
2、不同属性数据的数量级差异性如何(身高的单位用米,体重的单位用千克,如1.5米和100千克,这两个量级可能差了100倍,这可能会影响模型的表现)
3、是否有异常数据(可以用异常检测来看看是否有异常点)
4、采集数据的方法是否合理,采集到的数据是否有代表性
5、对于标签结果,要确保标签判定规则的一致性(统一标准)
Always try:
1、删除不必要的属性,减少过拟合、节约运算时间
2、数据预处理:归一化、标准化,平衡数据影响,加快训练收敛
3、确定是否保留或过滤掉异常数据,提高鲁棒性
4、尝试不同的模型,对比模型表现,帮助确定更合适的模型
举例:
任务:根据检测数据x1、x2及其标签,判断x1=6、x2=4时所属类别
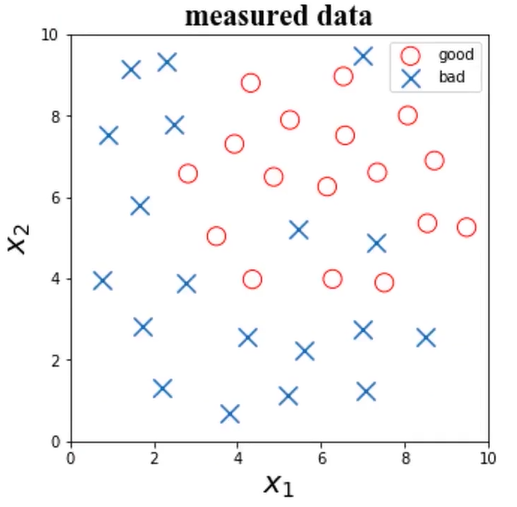
是否有需要剔除的异常数据?
数据量级差异如何 ?
是否需要降低数据维度 ?
(1)、查找异常数据
一个异常数据点,x1=7、x2=9.5,y=0
潜在异常数据点:x1=5.47、x2=5.2,y=0; x1=7.31、x2=4.87,y=0
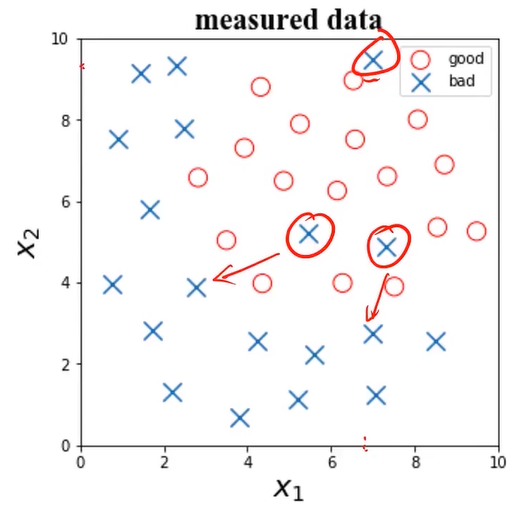
这里通过可视化来判断异常,如果数据维度很高无法可视化,可以进行概率密度函数的计算,找到低概率密度点,找到点之后再去看看具体的数据是不是有异常。
处理:移除第一个异常点,保留第二、三个潜在异常点。
(2)、对比各特征数据范围
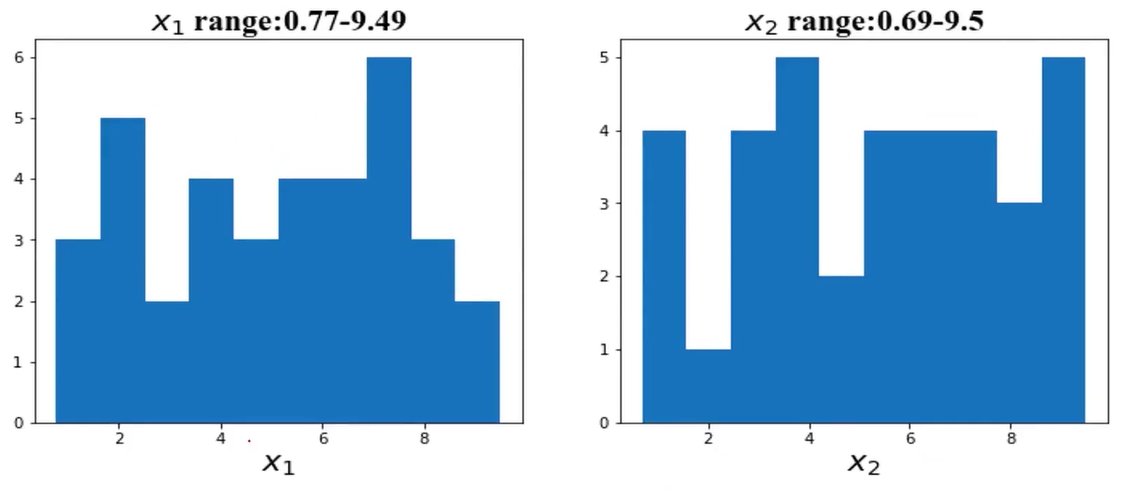
x1的范围为0.77-9.49,x2的范围:0.69-9.5,可以判断两个属性的数据范围接近
(3)、确认数据维度是否可以减少
对数据进行PCA分析,发现需要保留两个维度的数据
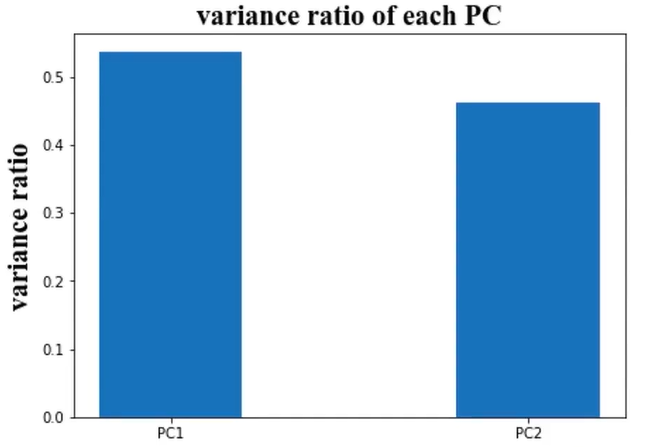
保留x1、x2,也可尝试使用PC1、PC2
2、尝试不同的模型

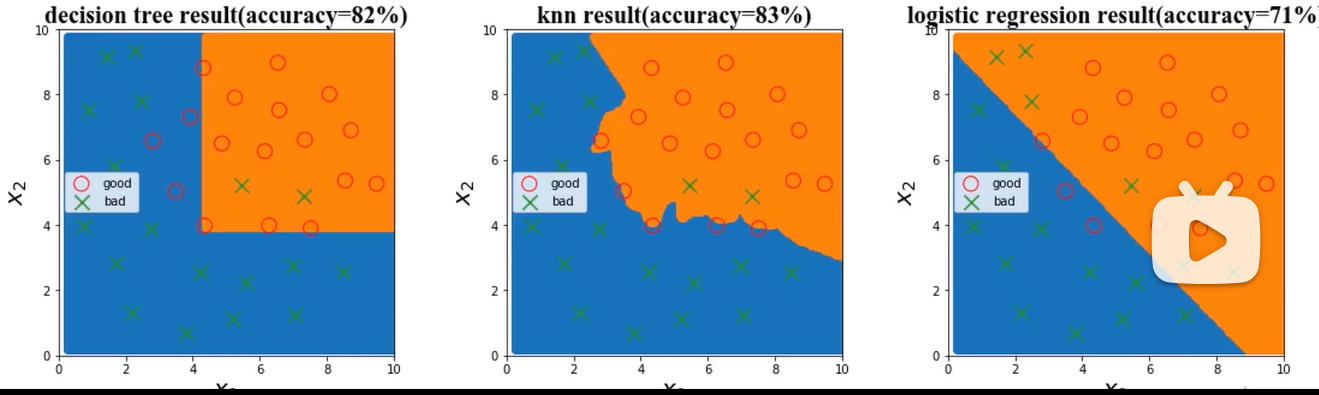
第一个模型为决策树,第二个模型为KNN,第三个模型为逻辑回归,边界函数为线性的
模型优化
目标:在确定模型类别后,如何让模型表现更好
三方面:数据、模型核心参数、正则化
尝试以下方法:
(1)、扩大数据样本
(2)、增加或减少数据属性
(3)、对数据进行降维处理
(4)、遍历核心参数组合,评估对应模型表现(比如:逻辑回归边界函数考虑多项式、KNN尝试不同的n_neighbors值)
(5)、对模型进行正则化处理,调整正则项λ的数值
举例:选择使用KNN模型,尝试不同n_neighbors值对结果的影响
方式一:可视化
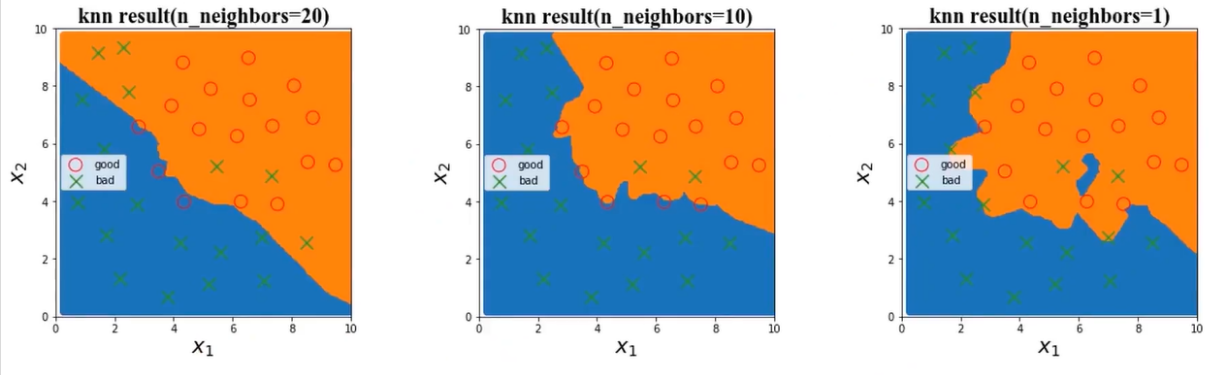
当n_neighbors值为20时,接近一条直线,当当n_neighbors值为1时,边界很复杂,而且图中橙色区域中间还有一片蓝色区域。
KNN模型中,模型复杂度由n_neighbors值决定。n_neighbors值越小,模型复杂度越高
方式二:计算准确率
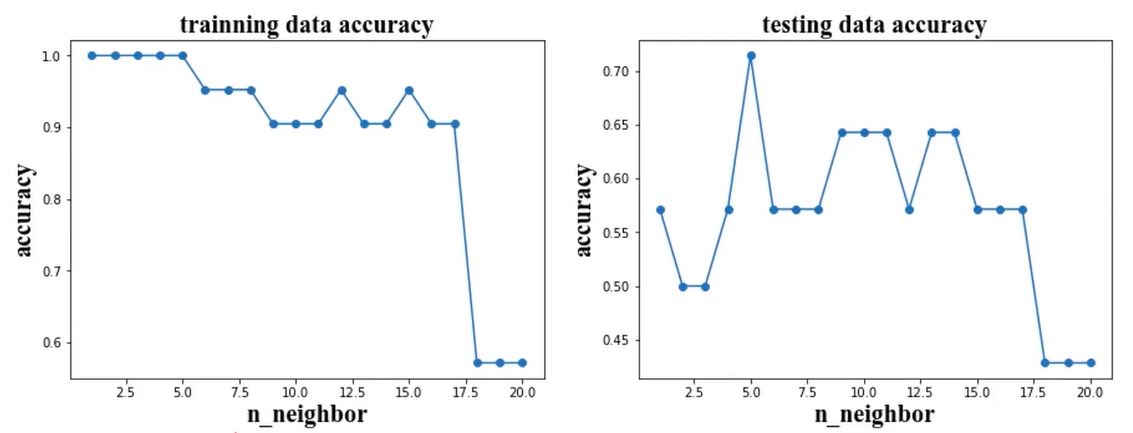
上图中,根据训练数据集和测试数据集都计算了准确率,在训练时,当n_neighbors值越小时,模型越复杂,准确率很高。但是测试数据集在n_neighbors值越小时,准确率并没有很高,反而出现了下降,此时可以理解为过拟合。当n_neighbors值很大时,不管是训练数据还是测试数据,准确率都比较低,可以理解为欠拟合的情况。当n_neighbors取值10左右时,训练和测试的准确率都很高。
训练数据集准确率 随着模型复杂而提高
测试数据集准确率 在模型过于简单或过于复杂的情况时下降
四、实战准备
酶活性预测
生成新数据并用于预测:
X_range =np.linspace(40,90,300).reshape(-1,1)
y_range_predict = lr1.predict(X_range)
生成多项式(二次)数据:
from sklearn.preprocessing importPolynomialFeatures
poly2= PolynomialFeatures(degree=2) # 创建实例,即最高次项为2次
X_2_train = poly2.fit_transform(X_train) # 训练数据转换 fit_transform只需要用一次
X_2_test = poly2.transform(X_test) # 测试数据转换
polynomial表示多项式,/ˌpɑːliˈnoʊmiəl/
质量好坏预测
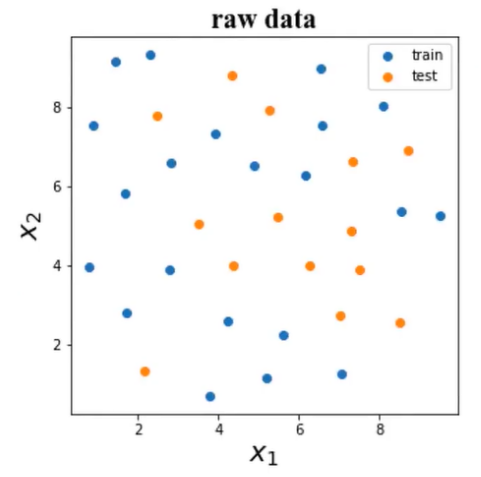
数据分离:
from sklearn.model selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=4,test_size=0.4)
test_size值为0.4表示测试数据占40%,训练数据占60%
生成决策区域数据:
xx,yy=np.meshgrid(np.arange(0,10,0.05)np.arange(0,10,0.05)) # 间距为0.05 即有200个点
x_range = np.c_[xx.ravel(),yy.ravel()]
y_range_predict = knn.predict(x _range) # 预测
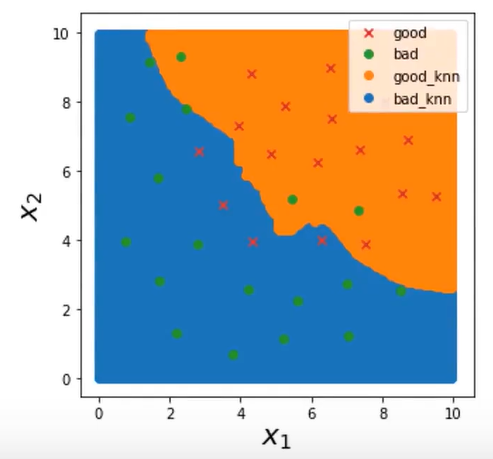
先建立KNN模型,模型完成训练之后,如x1范围[0,10],x2范围[0,10],间距为0.05,即每个方向有200个点,遍历输入数据的所有组合,所有的点都放到模型中进行预测,根据预测结果判断是0还是1,0用蓝色画点,1用橙色画点,当画得比较密集的时候,就形成了两个区域,就看不出来里面是密密麻麻的点,
可视化决策区域:
bad_knn = plt.scatter(x_range[:,0][y_range_predict==0],x_range[: 1][y_range_predict==0])
good_knn = plt.scatter(x_range[:,0][y_range_predict==1],x_range[: 1][y_range_predict==1])
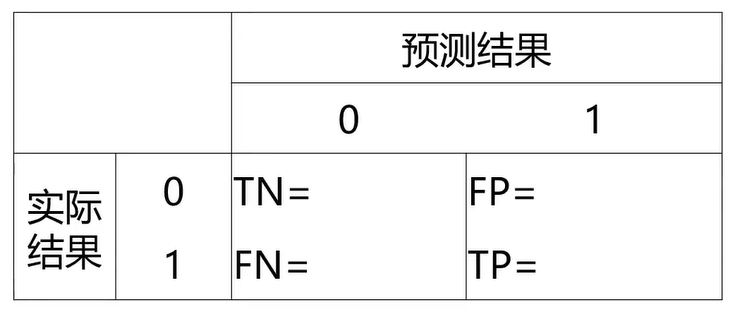
计算混淆矩阵
from sklearn.metrics import confusion_matrix
cm= confusion_matrix(y_test,y_test_predict)
TP = cm[1,1]
TN = cm[0, 0]
FP = cm[0, 1]
FN = cm[1, 0]
计算召回率、特异度、精确率、F1分数:
recall =TP/(TP+FN)
specificity = TN/(TN+FP)
precision=TP/(TP+FP)
f1 = 2*precision*recall/(precision+recall)
五、实战(一)-酶活性预测-一维线性回归问题
1、基于T-R-train.csv数据,建立线性回归模型,计算其在T-R-test.csv数据上的r2分数,可视化模型预测结果
2、加入多项式特征(2次、5次),建立回归模型
3、计算多项式回归模型对测试数据进行预测的r2分数,判断哪个模型预测更准确
4、可视化多项式回归模型数据预测结果判断哪个模型预测更准确
数据集下载地址:
通过网盘分享的文件:blog中用到的文件 链接: https://pan.baidu.com/s/1NFX-JdOdmlAowVWGWIfT1w 提取码: k9qu --来自百度网盘超级会员v6的分享
1、加载数据

#加载数据 import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score data_train = pd.read_csv('./data/T-R-train.csv') print(data_train)
结果:
T rate 0 46.53 2.49 1 48.14 2.56 2 50.15 2.63 3 51.36 2.69 4 52.57 2.74 5 54.18 2.80 6 56.19 2.88 7 58.58 2.92 8 61.37 2.96 9 63.34 2.95 10 65.31 2.91 11 66.47 2.85 12 68.03 2.78 13 69.97 2.69 14 71.13 2.61 15 71.89 2.54 16 73.05 2.45 17 74.21 2.39
2、定义X_train和y_train
#define X_train and y_train X_train = data_train.loc[:,'T'] y_train = data_train.loc[:,'rate']
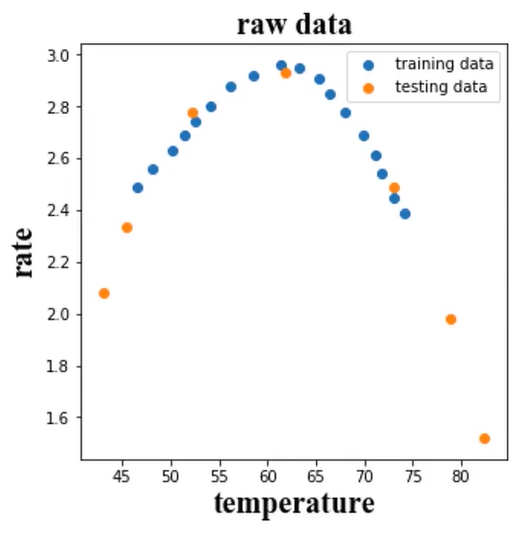
3、可视化数据
# 可视化数据 fig1 = plt.figure(figsize=(5, 5)) plt.scatter(X_train, y_train) plt.title('raw data') plt.xlabel('temperature') plt.ylabel('rate') plt.show()
结果:
4、建立线性回归模型
#将X_train转换为一维数组(若不转换会因为维度问题而无法建立下面的线性回归模型) X_train = np.array(X_train).reshape(-1,1) #建立线性回归模型 lr1 = LinearRegression() lr1.fit(X_train,y_train)
5、加载测试数据
#加载测试数据 data_test = pd.read_csv('./data/T-R-test.csv') X_test = data_test.loc[:,'T'] y_test = data_test.loc[:,'rate'] print(data_test)
结果:
T rate 0 45.376344 2.334559 1 52.186380 2.775735 2 61.863799 2.930147 3 73.154122 2.488971 4 78.888889 1.981618 5 82.473118 1.518382 6 43.046595 2.080882
6、预测结果
#这里测试数据也要转换成一维数组 X_test = np.array(X_test).reshape(-1,1) # 预测结果 # make prediction on the training and testing data y_train_predict = lr1.predict(X_train) y_test_predict = lr1.predict(X_test)
7、计算R方值(R2)
# 计算R方值(R2) r2_train = r2_score(y_train, y_train_predict) r2_test = r2_score(y_test, y_test_predict) print('training r2:', r2_train) print('test r2:', r2_test)
结果:
training r2: 0.016665703886982186 test r2: -0.7583363437351327
R2分数越接近1越好
8、生成新数据(为画直线做准备)
#生成新数据 X_range = np.linspace(40,90,300).reshape(-1,1)#新数据X的范围是40-90,然后共有300个点 y_range_predict = lr1.predict(X_range)
9、可视化数据
# 可视化数据 fig2 = plt.figure(figsize=(10, 10)) plt.plot(X_range, y_range_predict) plt.scatter(X_train, y_train) plt.title('prediction data') plt.xlabel('temperature') plt.ylabel('rate') plt.show()
结果:
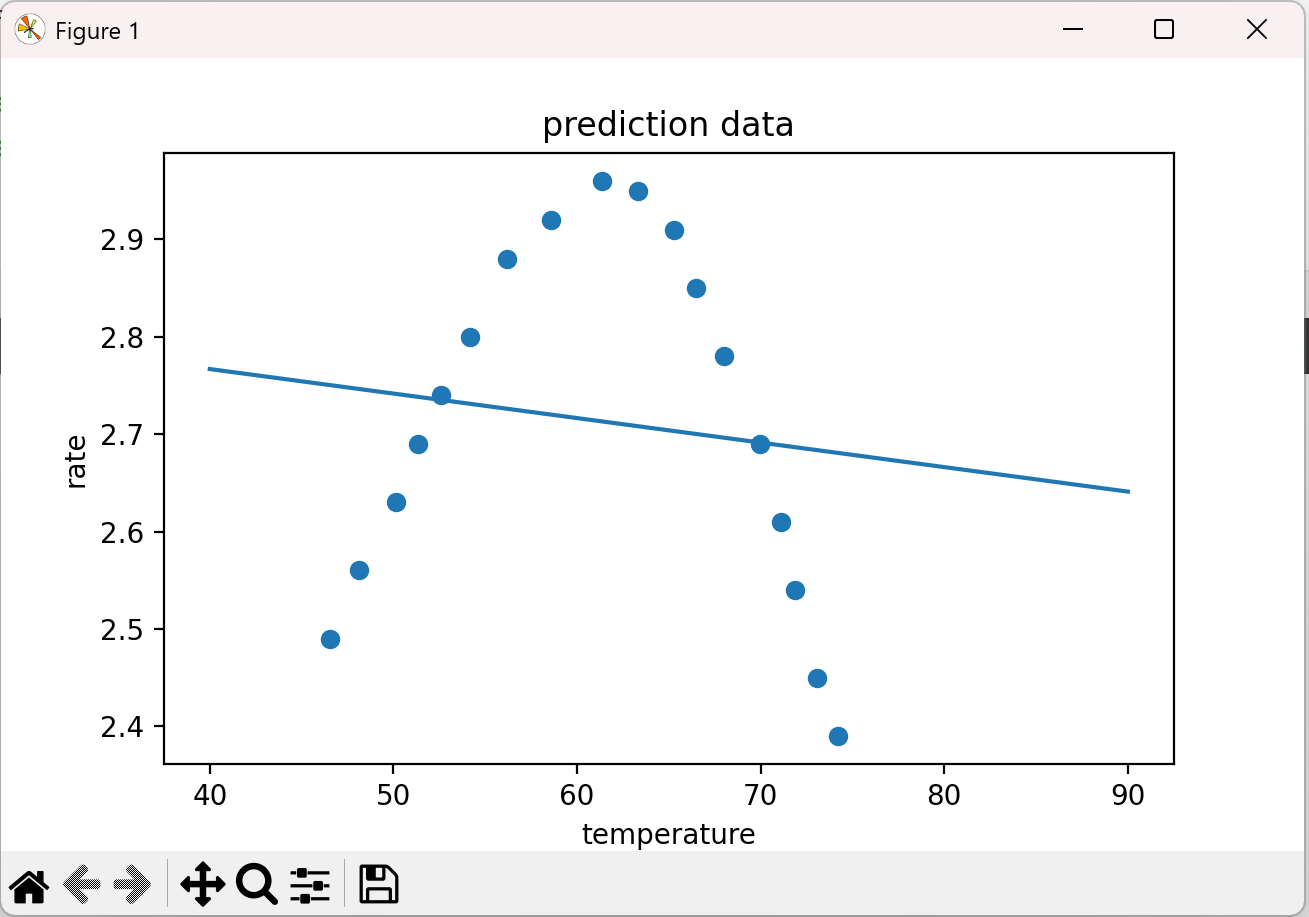
之前我们提到过,r2越接近1模型效果越好,可以看到此时用相对简单的线性回归模型无论是训练数据还是测试数据预测效果都不好,然后我们生成新数据并将其预测结果可视化出来,也可以明显看出该模型效果不太好,这就是欠拟合的表现。下面我们加入多项式特征,让模型复杂一点看看效果。
10、生成多项式数据
# 多项式模型 # 加入多项式特征 from sklearn.preprocessing import PolynomialFeatures poly2 = PolynomialFeatures(degree=2) # 这里degree=2代表的是2次,相应的degree=3代表的就是3次,以此类推 X_2_train = poly2.fit_transform(X_train) # 将原来的数据进行转换 X_2_test = poly2.fit_transform(X_test) poly5 = PolynomialFeatures(degree=5) X_5_train = poly5.fit_transform(X_train) X_5_test = poly5.fit_transform(X_test) print(X_2_train.shape) print(X_5_train.shape)
结果:
(18, 3) (18, 6)
这里我们看到加入不同的多项式特征,维度会有不同的变化
11、训练模型和预测模型、计算R2值
# 训练以及评估模型 # 训练二次多项式模型 lr2 = LinearRegression() lr2.fit(X_2_train, y_train) # 预测二次多项式模型 y_2_train_predict = lr2.predict(X_2_train) y_2_test_predict = lr2.predict(X_2_test) # 计算二次多项式模型的R方值(R2) r2_2_train = r2_score(y_train, y_2_train_predict) r2_2_test = r2_score(y_test, y_2_test_predict) # 训练五次多项式模型 lr5 = LinearRegression() lr5.fit(X_5_train, y_train) # 预测五次多项式模型 y_5_train_predict = lr5.predict(X_5_train) y_5_test_predict = lr5.predict(X_5_test) # 计算五次多项式模型的R方值(R2) r2_5_train = r2_score(y_test, y_5_test_predict) r2_5_test = r2_score(y_test, y_5_test_predict) print('training r2_2:', r2_2_train) print('test r2_2:', r2_2_test) print('training r2_5:', r2_5_train) print('test r2_5:', r2_5_test)
结果:
training r2_2: 0.970051540068943 test r2_2: 0.996395455646867 training r2_5: 0.5437828889274186 test r2_5: 0.5437828889274186
从模型评估中可看出,当多项式为2阶时,训练数据和测试数据效果都很好。当多项式为5阶时,训练数据效果很好但测试数据效果很一般,这时因为模型过于复杂,出现了过拟合的情况。下面生成新数据并对其进行预测,最后进行可视化看看效果。
12、生成新数据(为了画线)
# 生成新数据 X_2_range = np.linspace(40, 90, 300).reshape(-1, 1) X_2_range = poly2.transform(X_2_range) # 数据转换 y_2_range_predict = lr2.predict(X_2_range) X_5_range = np.linspace(40, 90, 300).reshape(-1, 1) X_5_range = poly5.transform(X_5_range) # 数据转换 y_5_range_predict = lr5.predict(X_5_range)
13、可视化
# 可视化数据 fig3 = plt.figure(figsize=(10, 10)) plt.plot(X_range, y_2_range_predict) # 这里画图用X_range是因为X_2_range和X_5_range的维度过高,无法将图形展示出来。 plt.scatter(X_train, y_train) plt.scatter(X_test, y_test) plt.title('polynomial prediction result (2)') plt.xlabel('temperature') plt.ylabel('rate') plt.show()
结果:
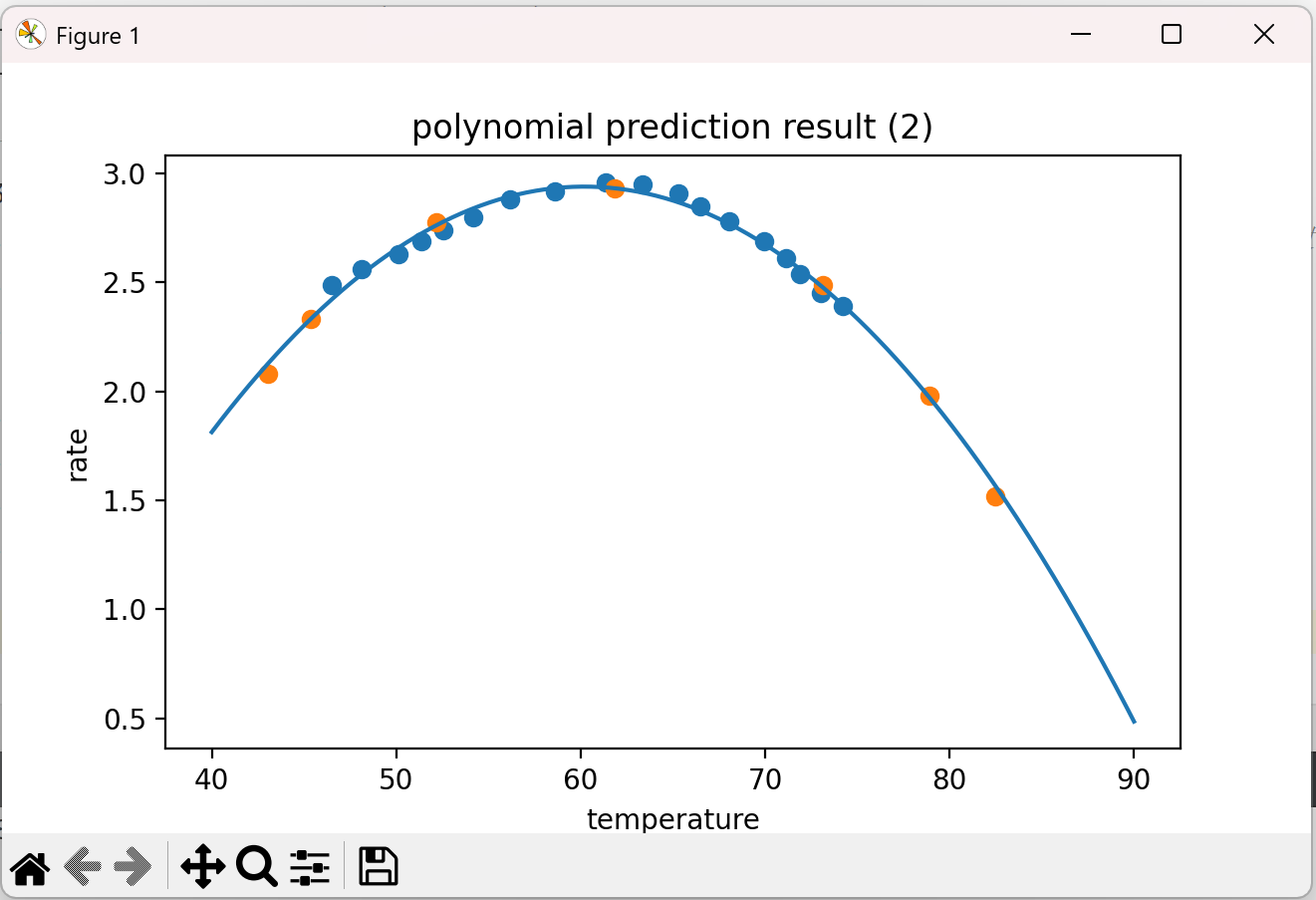
完整代码:
#加载数据 import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score data_train = pd.read_csv('./data/T-R-train.csv') print(data_train) #define X_train and y_train X_train = data_train.loc[:,'T'] y_train = data_train.loc[:,'rate'] # 可视化数据 # fig1 = plt.figure(figsize=(5, 5)) # plt.scatter(X_train, y_train) # plt.title('raw data') # plt.xlabel('temperature') # plt.ylabel('rate') # plt.show() #将X_train转换为一维数组(若不转换会因为维度问题而无法建立下面的线性回归模型) X_train = np.array(X_train).reshape(-1,1) #建立线性回归模型 lr1 = LinearRegression() lr1.fit(X_train,y_train) #加载测试数据 data_test = pd.read_csv('./data/T-R-test.csv') X_test = data_test.loc[:,'T'] y_test = data_test.loc[:,'rate'] print(data_test) #这里测试数据也要转换成一维数组 X_test = np.array(X_test).reshape(-1,1) # 预测结果 # make prediction on the training and testing data y_train_predict = lr1.predict(X_train) y_test_predict = lr1.predict(X_test) # 计算R方值(R2) r2_train = r2_score(y_train, y_train_predict) r2_test = r2_score(y_test, y_test_predict) print('training r2:', r2_train) print('test r2:', r2_test) #生成新数据 X_range = np.linspace(40,90,300).reshape(-1,1)#新数据X的范围是40-90,然后共有300个点 y_range_predict = lr1.predict(X_range) # 可视化数据 # fig2 = plt.figure(figsize=(10, 10)) # plt.plot(X_range, y_range_predict) # plt.scatter(X_train, y_train) # plt.title('prediction data') # plt.xlabel('temperature') # plt.ylabel('rate') # plt.show() # 多项式模型 # 加入多项式特征 from sklearn.preprocessing import PolynomialFeatures poly2 = PolynomialFeatures(degree=2) # 这里degree=2代表的是2次,相应的degree=3代表的就是3次,以此类推 X_2_train = poly2.fit_transform(X_train) # 将原来的数据进行转换 X_2_test = poly2.fit_transform(X_test) poly5 = PolynomialFeatures(degree=5) X_5_train = poly5.fit_transform(X_train) X_5_test = poly5.fit_transform(X_test) print(X_2_train.shape) print(X_5_train.shape) # 训练以及评估模型 # 训练二次多项式模型 lr2 = LinearRegression() lr2.fit(X_2_train, y_train) # 预测二次多项式模型 y_2_train_predict = lr2.predict(X_2_train) y_2_test_predict = lr2.predict(X_2_test) # 计算二次多项式模型的R方值(R2) r2_2_train = r2_score(y_train, y_2_train_predict) r2_2_test = r2_score(y_test, y_2_test_predict) # 训练五次多项式模型 lr5 = LinearRegression() lr5.fit(X_5_train, y_train) # 预测五次多项式模型 y_5_train_predict = lr5.predict(X_5_train) y_5_test_predict = lr5.predict(X_5_test) # 计算五次多项式模型的R方值(R2) r2_5_train = r2_score(y_test, y_5_test_predict) r2_5_test = r2_score(y_test, y_5_test_predict) print('training r2_2:', r2_2_train) print('test r2_2:', r2_2_test) print('training r2_5:', r2_5_train) print('test r2_5:', r2_5_test) # 生成新数据 X_2_range = np.linspace(40, 90, 300).reshape(-1, 1) X_2_range = poly2.transform(X_2_range) # 测试数据转换 y_2_range_predict = lr2.predict(X_2_range) X_5_range = np.linspace(40, 90, 300).reshape(-1, 1) X_5_range = poly5.transform(X_5_range) # 测试数据转换 y_5_range_predict = lr5.predict(X_5_range) # 可视化数据 fig3 = plt.figure(figsize=(10, 10)) plt.plot(X_range, y_2_range_predict) # 这里画图用X_range是因为X_2_range和X_5_range的维度过高,无法将图形展示出来。 plt.scatter(X_train, y_train) plt.scatter(X_test, y_test) plt.title('polynomial prediction result (2)') plt.xlabel('temperature') plt.ylabel('rate') plt.show()
六、实战(二)-质量好坏预测-二维逻辑回归分类问题
1、基于data_class_raw.csv数据,根据高斯分布概率密度函数,寻找异常点并剔除(异常检测)
2、基于data_class_processed.csv(处理好的新数据)数据进行PCA处理,确定重要数据维度及成分
3、完成数据分离,数据分离参数:random_state=4 test_size=0.4
4、建立KNN模型完成分类,n_neighbors取10,计算分类准确率,可视化分类边界
5、计算测试数据集对应的混淆矩阵,计算准确率、召回率、特异度、精确率、F1分数
6、尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图
数据集下载地址:
通过网盘分享的文件:blog中用到的文件
链接: https://pan.baidu.com/s/1NFX-JdOdmlAowVWGWIfT1w 提取码: k9qu
--来自百度网盘超级会员v6的分享
1、加载数据
#加载数据
import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt data = pd.read_csv('./data/data_class_raw.csv') print(data)
结果:
x1 x2 y 0 0.77 3.97 0 1 1.71 2.81 0 2 2.18 1.31 0 ...
2、定义X和y
#define X and y X = data.drop(['y'],axis=1) y = data.loc[:,'y']
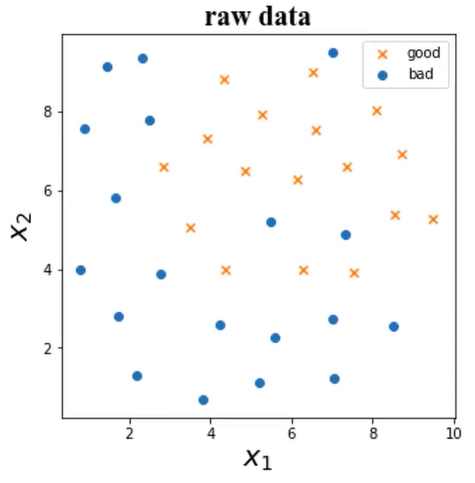
3、可视化初始数据
# 可视化数据 fig1 = plt.figure(figsize=(10, 10)) bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) #y==0表示坏样本 good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) plt.legend((good, bad), ('good', 'bad')) plt.title('raw data') plt.xlabel('x1') plt.ylabel('x2') plt.show()
结果:
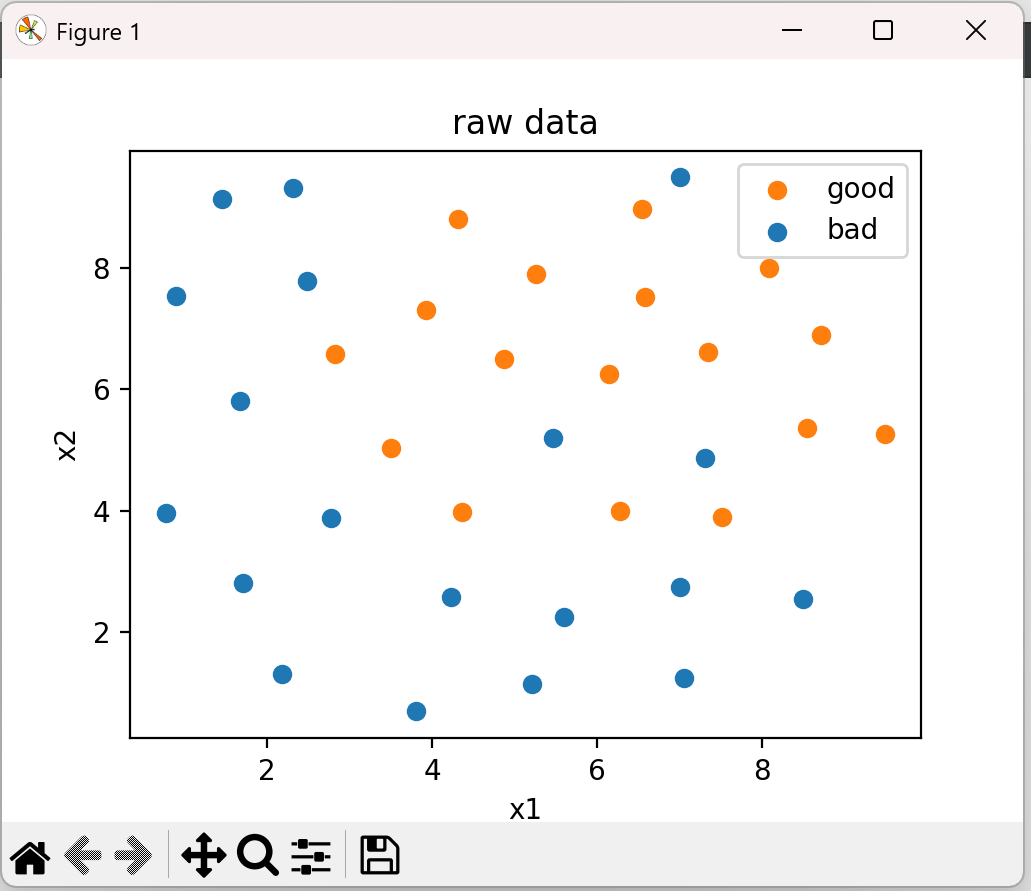
从图中可以看到坏样本有一个异常数据。
4、异常检测(看看坏样本有没有异常数据)
from sklearn.covariance import EllipticEnvelope ad_model = EllipticEnvelope(contamination=0.02) # 概率分布阈值contamination,即ε,默认值为0.1,这里指定为0.02 ad_model.fit(X[y == 0]) # y==0表示坏样本 y_predict_bad = ad_model.predict(X[y == 0]) print(y_predict_bad)
结果:
[ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 -1]
值为1表示正样本(即坏样本),值为-1表示负样本,即异常点
5、可视化异常点
# 可视化异常点 fig2 = plt.figure(figsize=(5, 5)) bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) plt.scatter(X.loc[:, 'x1'][y == 0][y_predict_bad == -1], X.loc[:, 'x2'][y == 0][y_predict_bad == -1], marker='x', s=150) plt.legend((good, bad), ('good', 'bad')) plt.title('raw data') plt.xlabel('x1') plt.ylabel('x2') plt.show()
结果:
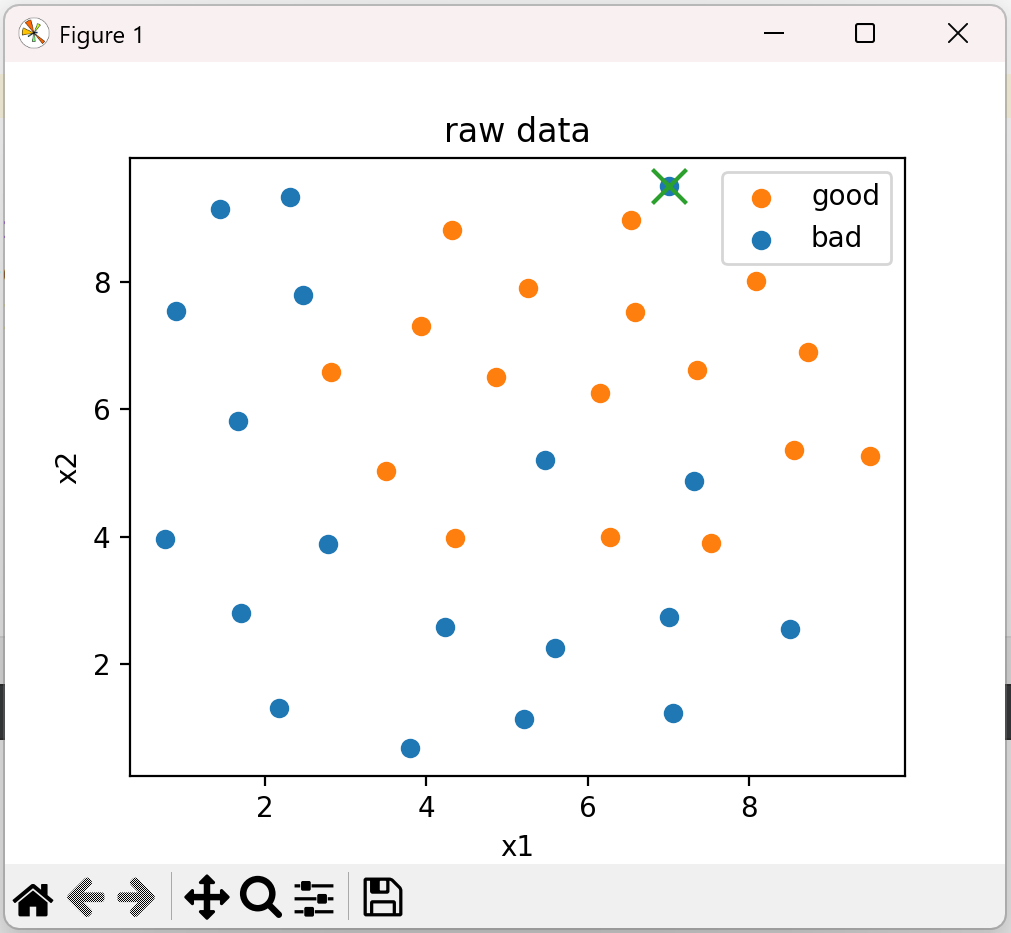
这里把坏样本中有异常的数据去掉,图中坏样本异常的数据应该是好样本。
完整代码:
#加载数据 import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt data = pd.read_csv('./data/data_class_raw.csv') print(data) #define X and y X = data.drop(['y'],axis=1) y = data.loc[:,'y'] # 可视化数据 # fig1 = plt.figure(figsize=(10, 10)) # bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) # good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) # plt.legend((good, bad), ('good', 'bad')) # plt.title('raw data') # plt.xlabel('x1') # plt.ylabel('x2') # plt.show() # 异常检测 from sklearn.covariance import EllipticEnvelope ad_model = EllipticEnvelope(contamination=0.02) # 概率分布阈值contamination,即ε,默认值为0.1,这里指定为0.02 ad_model.fit(X[y == 0]) # y==0表示坏样本 y_predict_bad = ad_model.predict(X[y == 0]) print(y_predict_bad) # 可视化异常点 fig2 = plt.figure(figsize=(5, 5)) bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) plt.scatter(X.loc[:, 'x1'][y == 0][y_predict_bad == -1], X.loc[:, 'x2'][y == 0][y_predict_bad == -1], marker='x', s=150) plt.legend((good, bad), ('good', 'bad')) plt.title('raw data') plt.xlabel('x1') plt.ylabel('x2') plt.show()
如图,绿叉处就是寻找出的异常点. 至此,任务第一步完成,下面进行第二步。
1、加载去掉异常点后的数据
#加载数据 import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt data = pd.read_csv('./data/data_class_processed.csv') print(data)
2、定义X和y
#define X and y X = data.drop(['y'],axis=1) y = data.loc[:,'y']
3、进行与原数据等维度PCA,计算每个主成分的方差比例
# pca # 对数据进行标准化处理 from sklearn.preprocessing import StandardScaler X_norm = StandardScaler().fit_transform(X) print(X_norm) # 进行与原数据等维度PCA from sklearn.decomposition import PCA pca = PCA(n_components=2) # 同等维度处理 # 等维度PCA后的数据X_reduced X_reduced = pca.fit_transform(X_norm) # 参数为:标准化处理之后的数据X_norm # 计算每个主成分的方差比例 var_ratio = pca.explained_variance_ratio_ print(var_ratio) # 可视化方差比例 fig4 = plt.figure(figsize=(5, 5)) plt.bar([1, 2], var_ratio) plt.show()
结果:
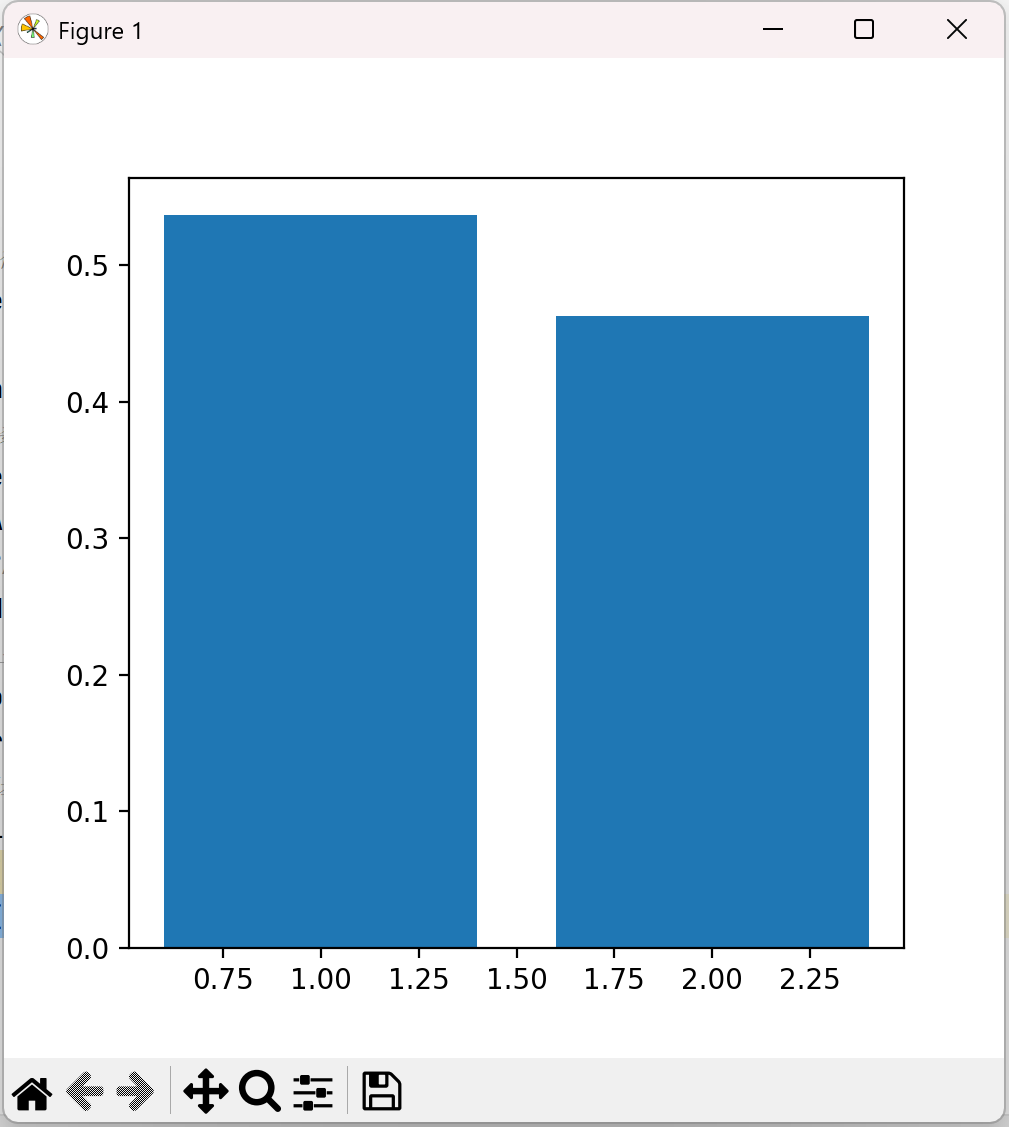
至此第二步完成,下面进行第三步——数据分离
4、数据分离
# 数据分离 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4, test_size=0.4) print(X_train.shape, X_test.shape, X.shape)
结果:
(21, 2) (14, 2) (35, 2)
5、建立KNN模型,计算训练数据和测试数据的准确率
# 建立knn 模型 from sklearn.neighbors import KNeighborsClassifier knn_10 = KNeighborsClassifier(n_neighbors=10) knn_10.fit(X_train, y_train) # 训练模型 # 预测 y_train_predict = knn_10.predict(X_train) y_test_predict = knn_10.predict(X_test) # 计算准确率 from sklearn.metrics import accuracy_score accuracy_train = accuracy_score(y_train, y_train_predict) accuracy_test = accuracy_score(y_test, y_test_predict) print("training accuracy:", accuracy_train) print("testing accuracy:", accuracy_test)
结果:
training accuracy: 0.9047619047619048 testing accuracy: 0.6428571428571429
6、生成决策区域数据,并可视化
# 生成决策区域数据 xx,yy=np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05)) #生成对应的数据组合 print(yy.shape) x_range = np.c_[xx.ravel(),yy.ravel()] #转换成两列 print(x_range.shape) y_range_predict=knn_10.predict(x_range) # 可视化决策区域 fig4 = plt.figure(figsize=(10, 10)) knn_bad = plt.scatter(x_range[:, 0][y_range_predict == 0], x_range[:, 1][y_range_predict == 0]) knn_good = plt.scatter(x_range[:, 0][y_range_predict == 1], x_range[:, 1][y_range_predict == 1]) bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) plt.legend((good, bad, knn_good, knn_bad), ('good', 'bad', 'knn_good', 'knn_bad')) plt.title('prediction result') plt.xlabel('x1') plt.ylabel('x2') plt.show()
结果:
(200, 200) (40000, 2)
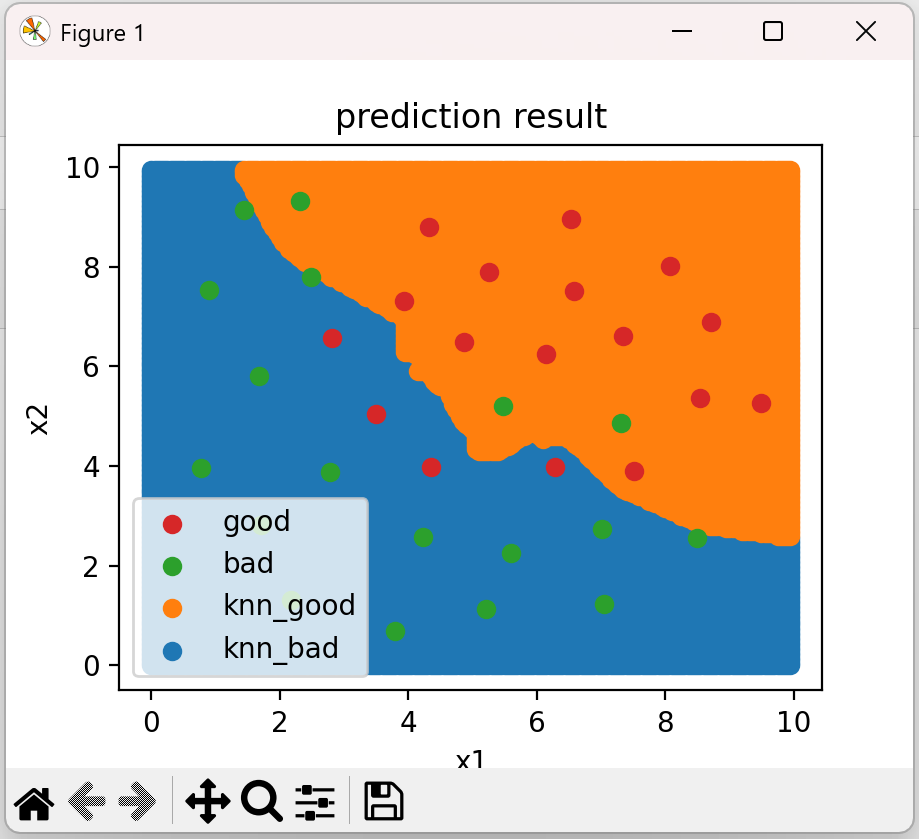
7、计算混淆矩阵
# 计算混淆矩阵 from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test,y_test_predict) print(cm) TP = cm[1, 1] # 5 TN = cm[0, 0] # 4 FP = cm[0, 1] # 2 FN = cm[1, 0] # 3 print(TP, TN, FP, FN)
结果:
[[4 2] [3 5]] 5 4 2 3
8、计算准确率、召回率、特异度、精确率、F1分数
# 计算准确率、召回率、特异度、精确率、F1分数 accuracy = (TP + TN)/(TP + TN + FP + FN) # 计算准确率 print(accuracy) recall = TP/(TP + FN) # 召回率 print(recall) specificity = TN/(TN + FP) # 特异度 print(specificity) precision = TP/(TP + FP) # 精确率 print(precision) F1 = 2*precision*recall/(precision+recall) # F1分数 print(F1)
结果:
0.6428571428571429 0.625 0.6666666666666666 0.7142857142857143 0.6666666666666666
9、尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率
# 尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图 n = [i for i in range(1, 21)] accuracy_train = [] accuracy_test = [] for i in n: knn = KNeighborsClassifier(n_neighbors=i) knn.fit(X_train, y_train) # 训练模型 y_train_predict = knn.predict(X_train) # 预测训练数据 y_test_predict = knn.predict(X_test) # 预测测试数据 # 计算准确率 accuracy_train_i = accuracy_score(y_train, y_train_predict) accuracy_test_i = accuracy_score(y_test, y_test_predict) accuracy_train.append(accuracy_train_i) accuracy_test.append(accuracy_test_i) print(accuracy_train, accuracy_test)
结果:
[1.0, 1.0, 1.0, 1.0, 1.0, 0.9523809523809523, 0.9523809523809523, 0.9523809523809523, 0.9047619047619048, 0.9047619047619048, 0.9047619047619048, 0.9523809523809523, 0.9047619047619048, 0.9047619047619048, 0.9523809523809523, 0.9047619047619048, 0.9047619047619048, 0.5714285714285714, 0.5714285714285714, 0.5714285714285714] [0.5714285714285714, 0.5, 0.5, 0.5714285714285714, 0.7142857142857143, 0.5714285714285714, 0.5714285714285714, 0.5714285714285714, 0.6428571428571429, 0.6428571428571429, 0.6428571428571429, 0.5714285714285714, 0.6428571428571429, 0.6428571428571429, 0.5714285714285714, 0.5714285714285714, 0.5714285714285714, 0.42857142857142855, 0.42857142857142855, 0.42857142857142855]
10、根据上面计算的准确率作图
x轴为n_neighbors(1-20)的值,y轴为计算出来的准确率
fig5 = plt.figure(figsize=(12, 5)) plt.subplot(121) plt.plot(n, accuracy_train, marker='o') plt.title('training accuracy vs n_neighbors') plt.xlabel('n_neighbors') plt.ylabel('accuracy') plt.subplot(122) plt.plot(n, accuracy_test, marker='o') plt.title('testing accuracy vs n_neighbors') plt.xlabel('n_neighbors') plt.ylabel('accuracy') plt.show()
结果:
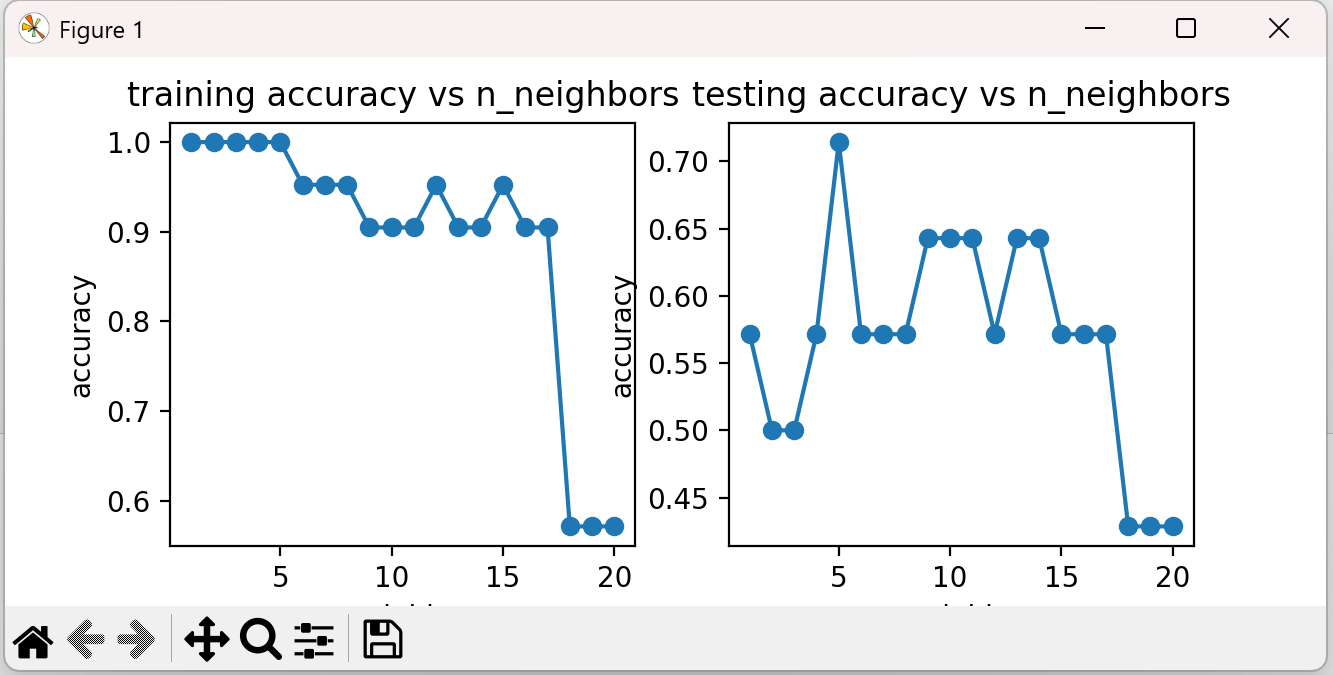
至此,本次的实战任务就完成了
完整代码:
#加载数据 import torch import pandas as pd import numpy as np # from matplotlib import pyplot as plt import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt data = pd.read_csv('./data/data_class_processed.csv') print(data) #define X and y X = data.drop(['y'],axis=1) y = data.loc[:,'y'] # pca # 对数据进行标准化处理 from sklearn.preprocessing import StandardScaler X_norm = StandardScaler().fit_transform(X) print(X_norm) # 进行与原数据等维度PCA from sklearn.decomposition import PCA pca = PCA(n_components=2) # 同等维度处理 # 等维度PCA后的数据X_reduced X_reduced = pca.fit_transform(X_norm) # 参数为标准化处理之后的数据X_norm # 计算每个主成分的方差比例 var_ratio = pca.explained_variance_ratio_ print(var_ratio) # 可视化方差比例 # fig4 = plt.figure(figsize=(5, 5)) # plt.bar([1, 2], var_ratio) # plt.show() # 数据分离 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4, test_size=0.4) print(X_train.shape, X_test.shape, X.shape) # 建立KNN模型 from sklearn.neighbors import KNeighborsClassifier knn_10 = KNeighborsClassifier(n_neighbors=10) knn_10.fit(X_train, y_train) # 训练模型 # 预测 y_train_predict = knn_10.predict(X_train) y_test_predict = knn_10.predict(X_test) # 计算准确率 from sklearn.metrics import accuracy_score accuracy_train = accuracy_score(y_train, y_train_predict) accuracy_test = accuracy_score(y_test, y_test_predict) print("training accuracy:", accuracy_train) print("testing accuracy:", accuracy_test) # 生成决策区域数据 xx,yy=np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05)) #生成对应的数据组合 print(yy.shape) x_range = np.c_[xx.ravel(),yy.ravel()] #转换成两列 print(x_range.shape) y_range_predict=knn_10.predict(x_range) # 可视化决策区域 # fig4 = plt.figure(figsize=(10, 10)) # knn_bad = plt.scatter(x_range[:, 0][y_range_predict == 0], x_range[:, 1][y_range_predict == 0]) # knn_good = plt.scatter(x_range[:, 0][y_range_predict == 1], x_range[:, 1][y_range_predict == 1]) # bad = plt.scatter(X.loc[:, 'x1'][y == 0], X.loc[:, 'x2'][y == 0]) # good = plt.scatter(X.loc[:, 'x1'][y == 1], X.loc[:, 'x2'][y == 1]) # plt.legend((good, bad, knn_good, knn_bad), ('good', 'bad', 'knn_good', 'knn_bad')) # plt.title('prediction result') # plt.xlabel('x1') # plt.ylabel('x2') # plt.show() # 计算混淆矩阵 from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test,y_test_predict) print(cm) TP = cm[1, 1] # 5 TN = cm[0, 0] # 4 FP = cm[0, 1] # 2 FN = cm[1, 0] # 3 print(TP, TN, FP, FN) # 计算准确率、召回率、特异度、精确率、F1分数 accuracy = (TP + TN)/(TP + TN + FP + FN) # 计算准确率 print(accuracy) recall = TP/(TP + FN) # 召回率 print(recall) specificity = TN/(TN + FP) # 特异度 print(specificity) precision = TP/(TP + FP) # 精确率 print(precision) F1 = 2*precision*recall/(precision+recall) # F1分数 print(F1) # 尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图 n = [i for i in range(1, 21)] accuracy_train = [] accuracy_test = [] for i in n: knn = KNeighborsClassifier(n_neighbors=i) knn.fit(X_train, y_train) # 训练模型 y_train_predict = knn.predict(X_train) # 预测训练数据 y_test_predict = knn.predict(X_test) # 预测测试数据 # 计算准确率 accuracy_train_i = accuracy_score(y_train, y_train_predict) accuracy_test_i = accuracy_score(y_test, y_test_predict) accuracy_train.append(accuracy_train_i) accuracy_test.append(accuracy_test_i) print(accuracy_train, accuracy_test) fig5 = plt.figure(figsize=(12, 5)) plt.subplot(121) plt.plot(n, accuracy_train, marker='o') plt.title('training accuracy vs n_neighbors') plt.xlabel('n_neighbors') plt.ylabel('accuracy') plt.subplot(122) plt.plot(n, accuracy_test, marker='o') plt.title('testing accuracy vs n_neighbors') plt.xlabel('n_neighbors') plt.ylabel('accuracy') plt.show()
总结:
1、通过进行异常检测,帮助找到了潜在的异常数据点;
2、通过PCA分析,发现需要保留2维数据集;
3、实现了训练数据与测试数据的分离,并计算模型对于测试数据的预测准确率
4、计算得到混淆矩阵,实现模型更全面的评估
5、通过新的方法,可视化分类的决策边界
6、通过调整核心参数n_neighbors值,在计算对应的准确率,可以帮助我们更好的确定使用哪个模型
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2023-02-20 微信小程序:如何使用weui.wxss中的icon?
2023-02-20 微信小程序:地图组件入门
2022-02-20 Lists工具类