一、分类问题Classification
分类案例
1、实例:垃圾邮件检测
任务
输入:电子邮件
输出:此为垃圾邮件/普通邮件

流程
(1)、标注样本邮件为垃圾/普通邮件(人)
(2)、获取批量的样本邮件及其标签,学习其特征(计算机)
(3)、针对新的邮件,自动判断其类别(计算机)
特征
用于帮助判断是否为垃圾邮件的属性:
(1)、发件人包含字符:%&*..
(2)、正文包含:现金、领取等等


2、图像分类

新输入以下图片时,预测结果为苹果

3、数字识别

新输入如下图片时,预测结果为2

4、考试通过预测
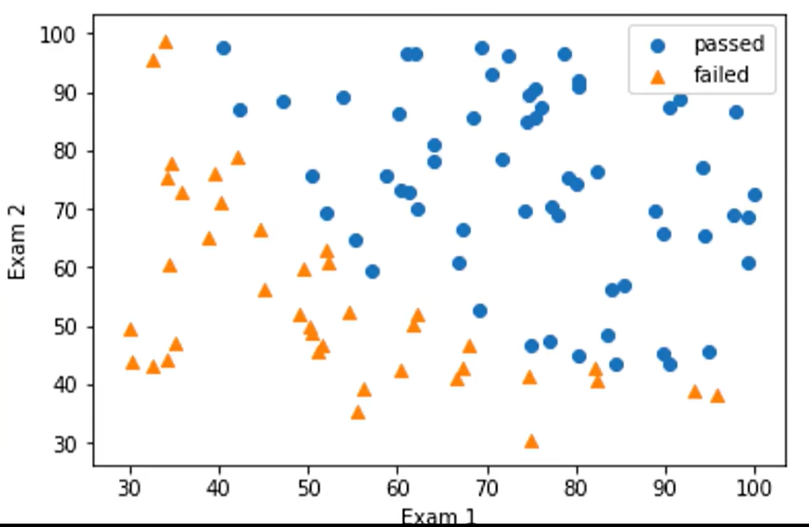
小明,Exam1和Exam2都是70分,是否会通过Exam3?
分类问题定义
分类:根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。
基本框架

其中x1,x2,...xn表示特征,再根据y的值来判断属于哪一类。
解决分类问题的算法:
(1)、逻辑回归:建立一个逻辑回归方程,通过方程去判断这个类别是什么类别。
(2)、KNN近邻模型
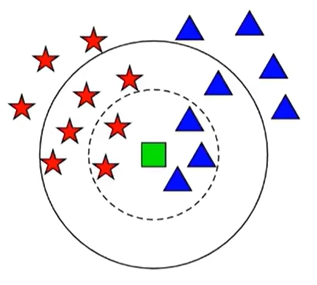
根据新的点与周边的点的距离来判断是什么类别
(3)、决策树
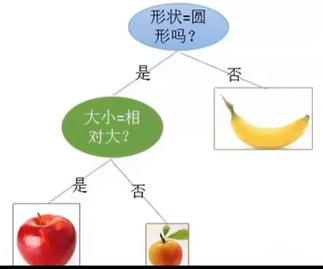
通过问很多问题来建立分支
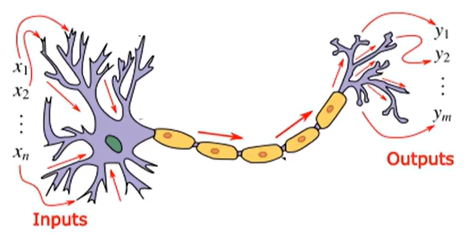
(4)、神经网络
分类任务与回归任务的明显区别
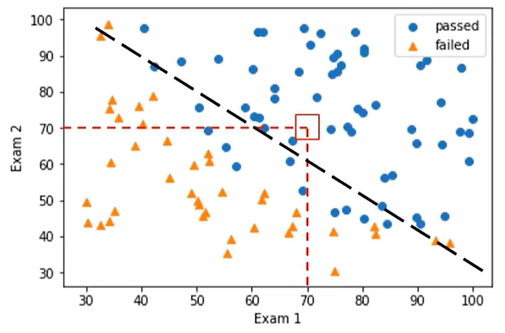
分类目标:判断类别
模型输出:非连续型标签(passed/failed;0/1/2...)
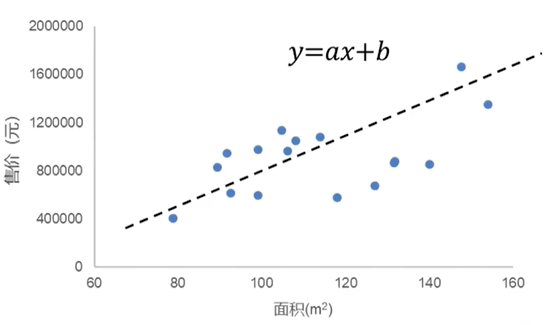 这是一个一元线性回归
这是一个一元线性回归
回归目标:建立函数
关系模型输出:连续型数值(比如0-200000的任意数值)
二、机器学习-监督学习-逻辑回归
如果是一维的话即g(x)=x,则用逻辑回归方程sigmoid来进行二分类。如果是二维的话即g(x)=θ0 + θ1 X1 + θ2 X2 ,则用梯度下降算法求解边界函数,此时边界函数分一阶还是二阶,一阶边界函数是直线,二阶边界函数是曲线。
如何求解分类问题?
任务:根据余额,判断小明是否会去看电影
纵坐标为0和1
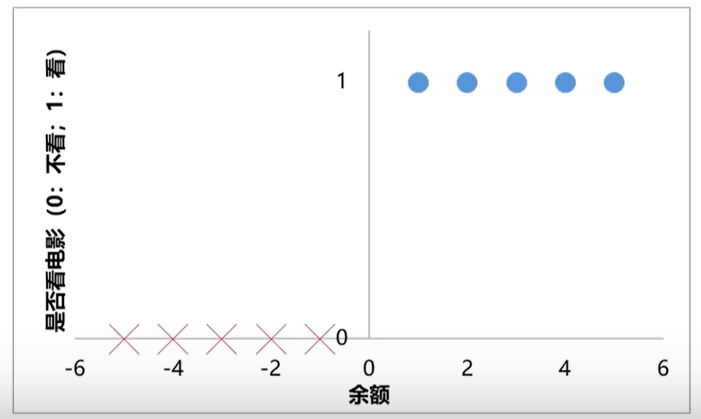
训练数据
余额为1、2、3、4、5:看电影(正样本)
余额为-1、-2、-3、-4、-5:不看电影(负样本) 余额为负,表示有欠账
任务:根据余额,判断小明是否会去看电影
分类任务基本框架:

![]()
y=0:不看电影(负样本)
y=1:看电影(正样本)
任务:寻找f(x)
先使用线性回归模型模拟点的分布:y=0.1364x+0.5
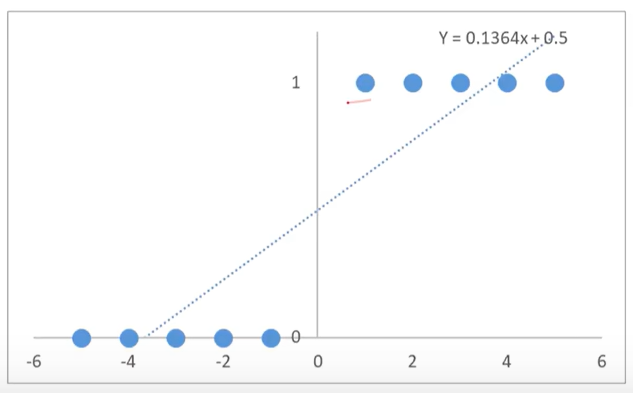
再基于分布函数判断是0还是1.y>0.5:y=1;y<0.5:y=0,这样就完成了一个简单的分类问题预测。
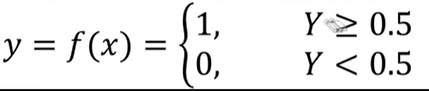
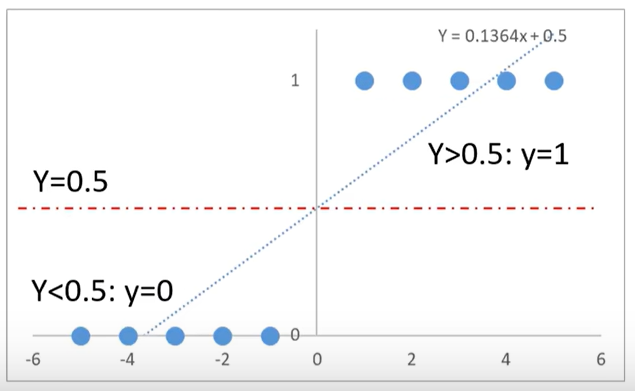
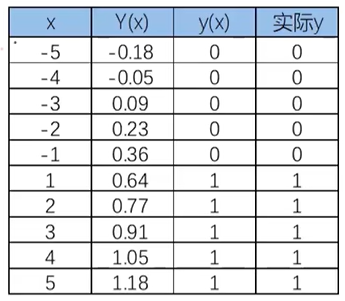
发现用线性回归模型也可以预测分类任务。但是有个非常大的局限性:当样本量变大以后,准确率会下降。
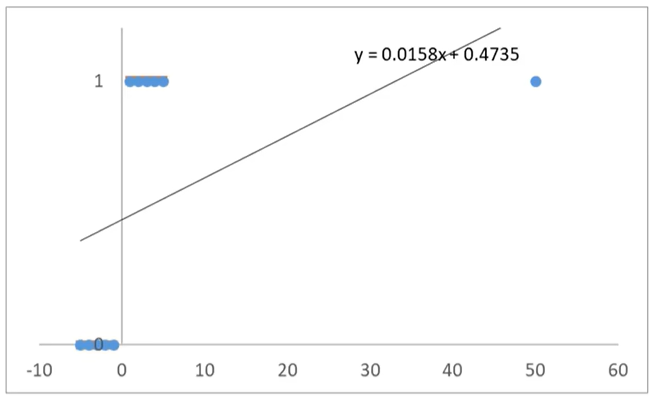
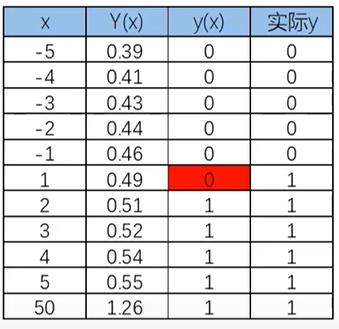
当x距离原点变远,预测开始不准确
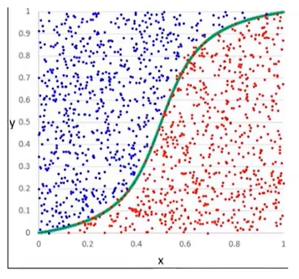
逻辑回归:
逻辑回归的思想和线性回归是一样的,只是方程不一样。
逻辑回归方程(sigmoid方程)
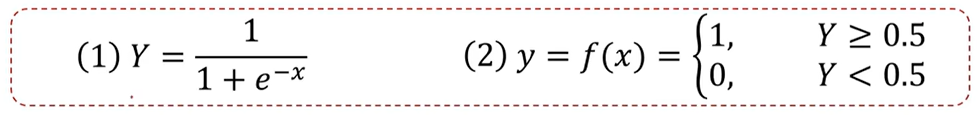
其中,y为类别结果,Y为概率分布函数(值域为(0,1)),x为特征值。
逻辑回归方程曲线:
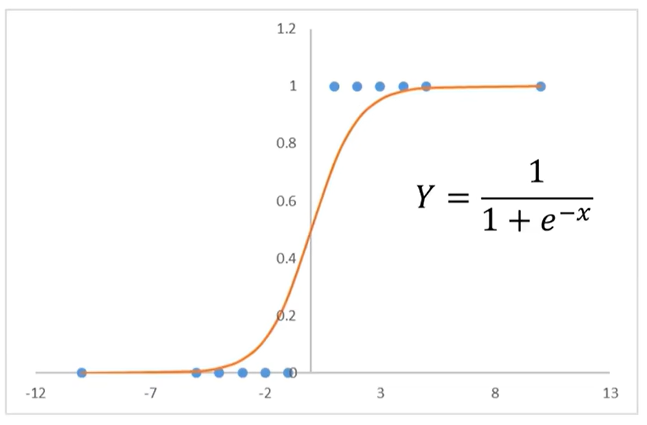
函数图像经过(0,0.5)这个点。
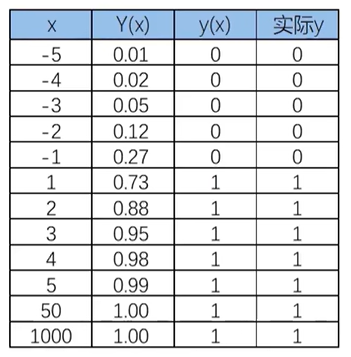
使用逻辑回归拟合数据,可以很好的完成分类任务!
逻辑回归用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别的概率P,根据概率数值判断其所属类别。主要应用场景:二分类问题。
任务:根据余额,判断小明是否会去看电影(余额-10、100)
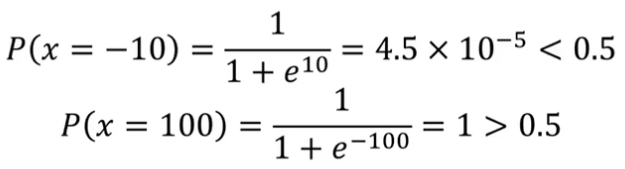
余额-10:不去看电影;余额100:去看电影
当问题更加复杂后,还能用逻辑回归解决二分类问题吗?
当分类任务变得更为复杂:原来只有一个维度即x,这里增加了一个维度,即x1,x2,x1,x2 均为输入,而三角形和圆形则为输出。
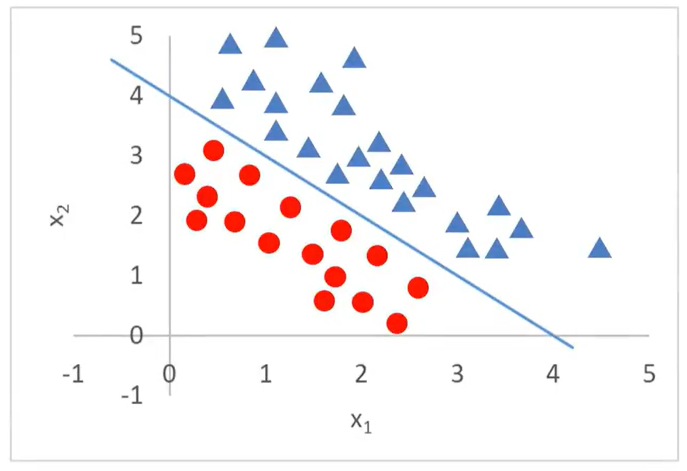
现在用g(x)替换原来的x,如下所示:
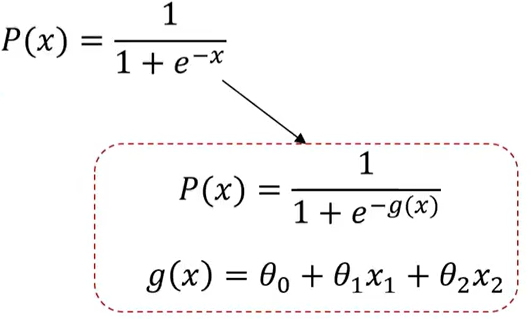
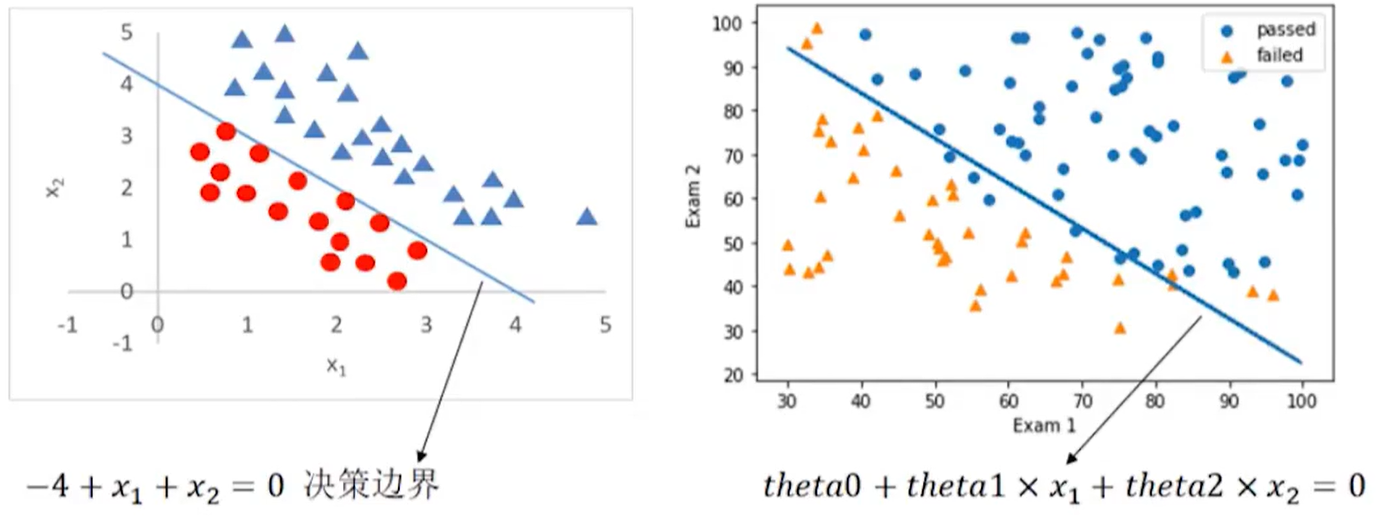
最核心的就是要找到g(x),后面会讲如何找g(x),这里先给出答案:g(x)= -4+x1+x2 ,就是上面图中的蓝色分割线。上面这条分割线的方程就是-4+x1+x2 =0,这样就可以得出以下结论:
g(x)= -4+x1+x2 >0:三角形
g(x)= -4+x1+x2 <0:圆形
此时-4+x1+x2 =0这条边界就叫决策边界(Decision boundary)
你会发现很多分类问题,最核心的点就是把决策边界找出来,不管多少维度,二维的话就是直线或曲线,三维的话就是面。
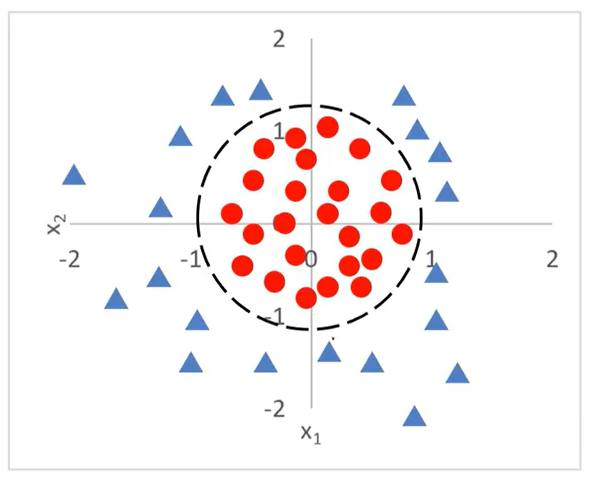
下面看一个更为复杂的问题:决策边界为圆形。
此时g(x)增加了x12和x22,这样的话,通过增加二次项就可以得到一个曲线或圆,
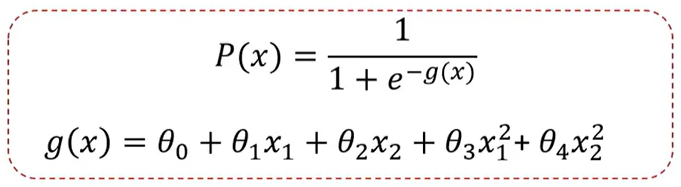
这里先给出结果g(x)= -1 + x12+x22 ,
g(x)= -1 + x12+x22 >0:三角形
g(x)= -1 + x12+x22 <0:圆形
决策方程为: -1 + x12+x22 =0
逻辑回归结合多项式边界函数可解决复杂的分类问题。
根据训练样本,寻找类别边界:
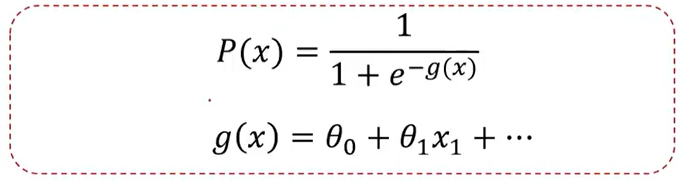
根据训练样本,寻找θ0、θ1、θ2,
分类问题,标签与预测结果都是离散点,使用该损失函数无法寻找极小值点。
现在要建立一个新的损失函数
逻辑回归求解,最小化损失函数(J)
单个样本的损失函数:
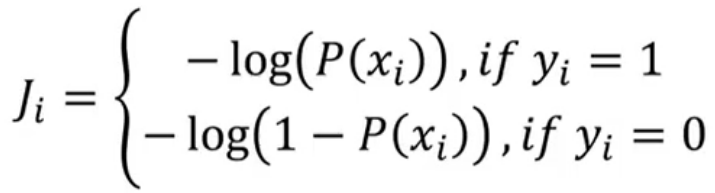
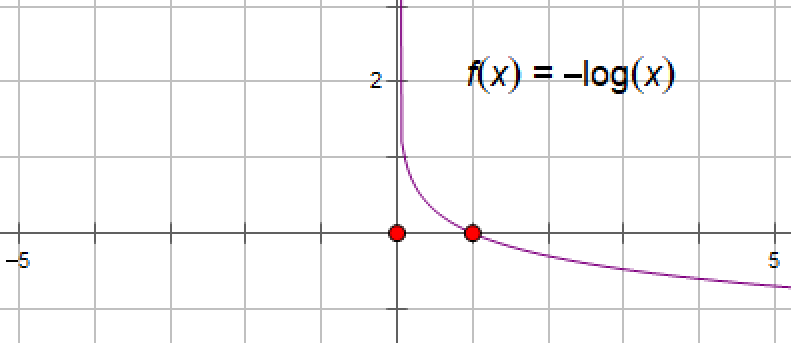
当yi=1(即真实的分类为1)时,损失函数是-log(P(xi)),
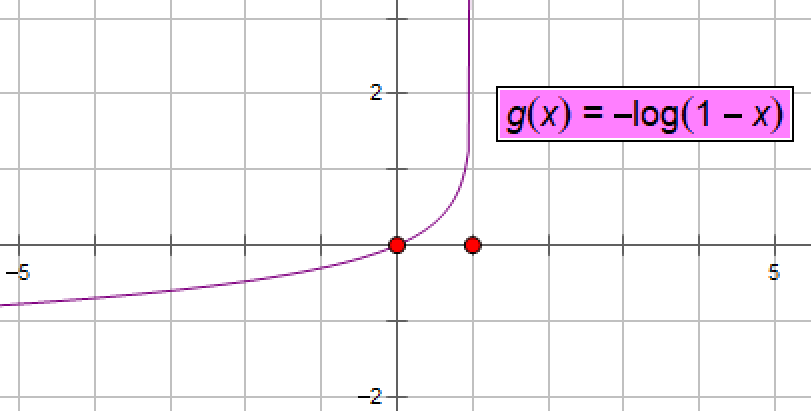
当yi=0(即真实的分类为0)时,损失函数是-log(1-P(xi))
整体样本的损失函数:
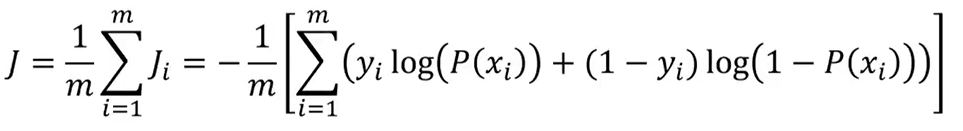
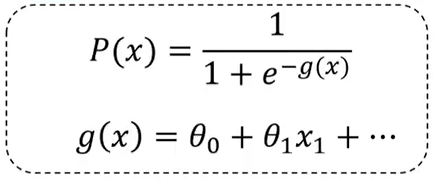
逻辑回归的求解原理:最小化所有样本的损失函数,即求min(J(θ))
逻辑回归的求解仍然用梯度下降算法:

三、实战准备
1、分类散点图可视化
未区分类别散点图:
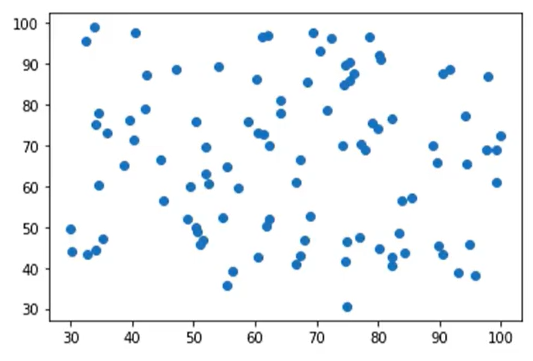
plt.scatter(X1,X2)
区分类别散点图:
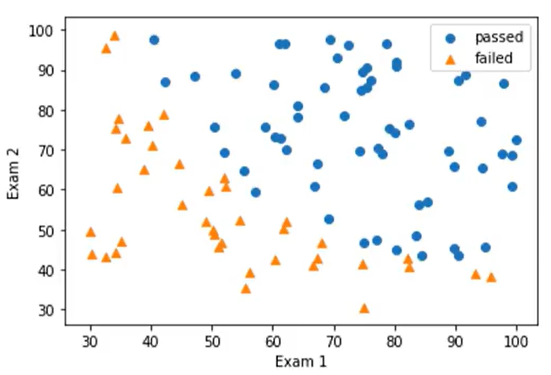
mask=y==1 passed=plt.scatter(X1[mask],X2[mask]) failed=plt.scatter(X1[~mask],X2[~mask],marker='^')
2、逻辑回归模型使用
mask=y==1的意思是当标签为1的时候,mask值为true
passed=plt.scatter(X1[mask],X2[mask]) 表是将y为1的点画出来
failed=plt.scatter(X1[~mask],X2[~mask],marker='^') 中mask取反,即将y为0的点画出来,mark='^'表示用三角形标记。
逻辑回归算法实现二分类:
(1)、模型训练LogisticRegression
from sklearn.linear model import LogisticRegression lr_model= LogisticRegression () lr_model.fit(x,y)
(2)、获得边界函数
边界函数系数:
theta1, theta2 = LR.coef_[0][0],LR.coef_[0][1] theta0 = LR.intercept_[0]
theta1即为θ1,theta2即为θ2,theta0即为θ0,intercept为截距
(3)、对新数据做预测:
predictions =lr_model.predict(x_new)
3、建立新数据集
生成新的属性数据
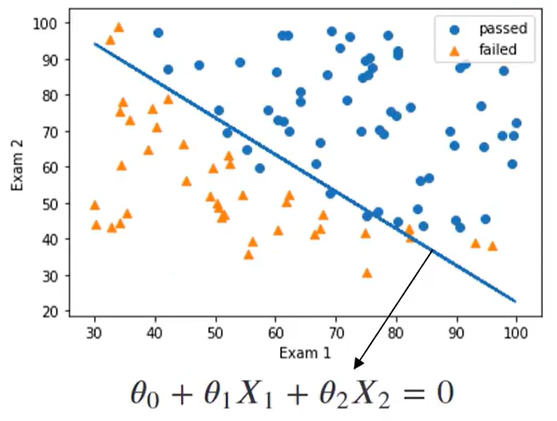
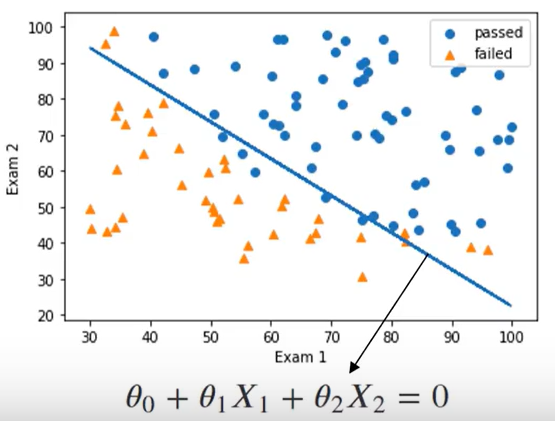
一阶边界函数:θ0 + θ1 X1 + θ2 X2 =0
上图为标准的线性边界函数,并且通过逻辑回归完成了二分类,但是仍然有不少误判,那怎么样可以让模型表现得更好呢?我们可以把一次的边界函数编程二次的边界函数
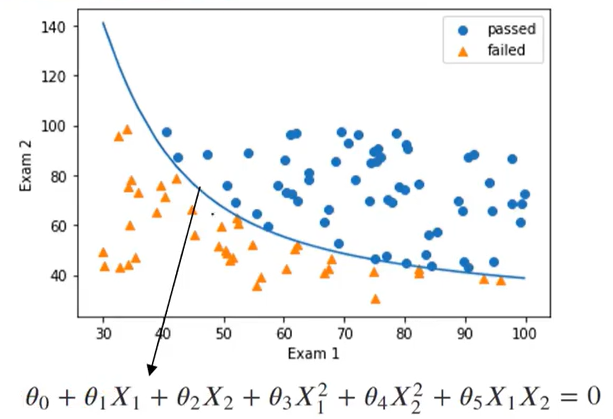
二阶边界函数:θ0 + θ1 X1 + θ2 X2 + θ3 (X1 )2 + θ4 (X2 )2 + θ5 (X1 X2 ) =0
#generate new parameters
X1_2=X1*X1; X2_2=X2*X2; X1_X2=X1*X2 X_new_dic = {'X1':X1,'X2':X2,'X1^2':X1_2,'X2^2':X2_2,'X1X2':X1_X2} X_new = pd.DataFrame(X_new_dic)
4、模型评估
如何判断模型好坏?
预测结果:
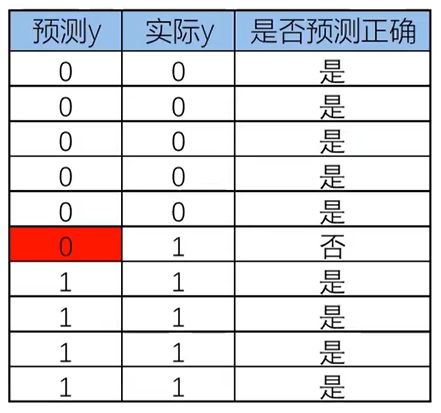
评估指标:准确率,准确率约接近1越好
准确率(类别正确预测的比例):

上表的准确率为90%
如果一未的追求准确率高也不见得是一件好事,可能会导致模型的过拟合
(1)、计算准确率
from sklearn.metrics import accuracy_score y_predict = LR.predict(X) accuracy= accuracy_score(y,y_predict)
(2)、画图看决策边界效果,可视化模型表现:
plt.plot(X1,X2 ,boundary) passed=plt.scatter(X1[mask],X2[mask]) failed=plt.scatter(X1[~maskl,X2[~maskl,marker='^')
四、实战(一):考试通过预测
1、基于examdata.csv数据,建立逻辑回归模型,评估模型表现;
2、预测Exam1=75,Exam2=60时,该同学能否通过Exam3
3、建立二阶边界函数,重复任务1、2
任务:
基于examdata.csv数据,建立逻辑回归模型 预测Exam1=75,Exam2=60时,该同学在Exam3是 passed or failed; 建立二阶边界,提高模型准确度
边界函数:θ0+θ1X1+θ2X2=0
1、加载数据
import pandas as pd import numpy as np data = pd.read_csv('./data/examdata.csv') print(data.head())
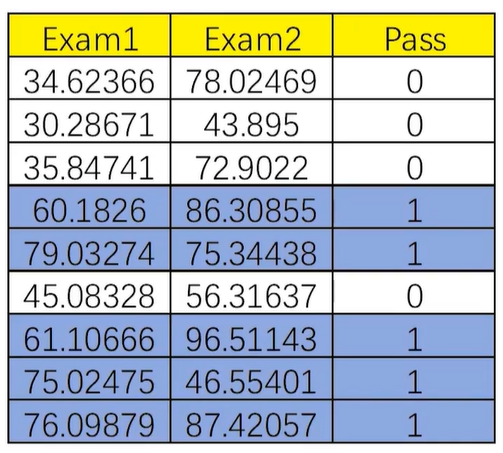
结果:
Exam1 Exam2 Pass 0 34.623660 78.024693 0 1 30.286711 43.894998 0 2 35.847409 72.902198 0 3 60.182599 86.308552 1 4 79.032736 75.344376 1
examdata.csv下载地址:
通过网盘分享的文件:examdata.csv 链接: https://pan.baidu.com/s/1-Ezk1AdxR3Ww5M0cl24xdg 提取码: 565i --来自百度网盘超级会员v6的分享
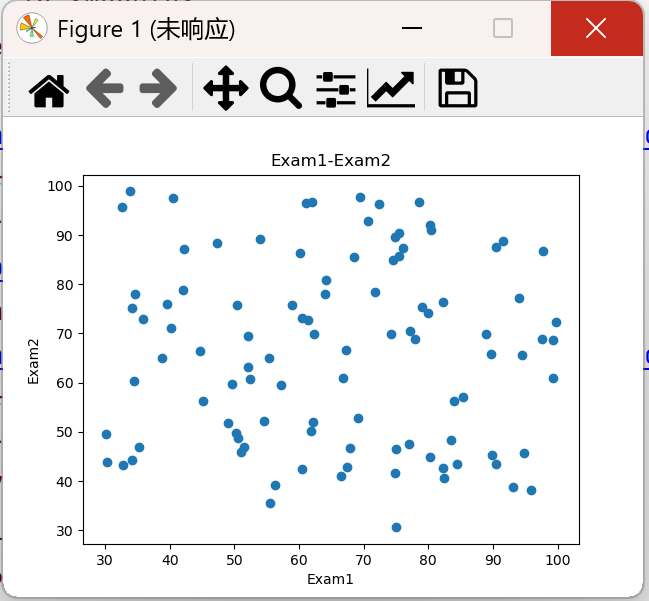
2、第二步:原始数据绘图
import torch import pandas as pd import numpy as np # 原始数据绘图 from matplotlib import pyplot as plt data = pd.read_csv('./data/examdata.csv') # 分别获取标题为Exam1和Exam2的所有行数据 plt.scatter(data.loc[:, 'Exam1'], data.loc[:, 'Exam2']) plt.title('Exam1-Exam2') plt.xlabel('Exam1') plt.ylabel('Exam2') plt.show()
结果:
第三步:添加标签区分
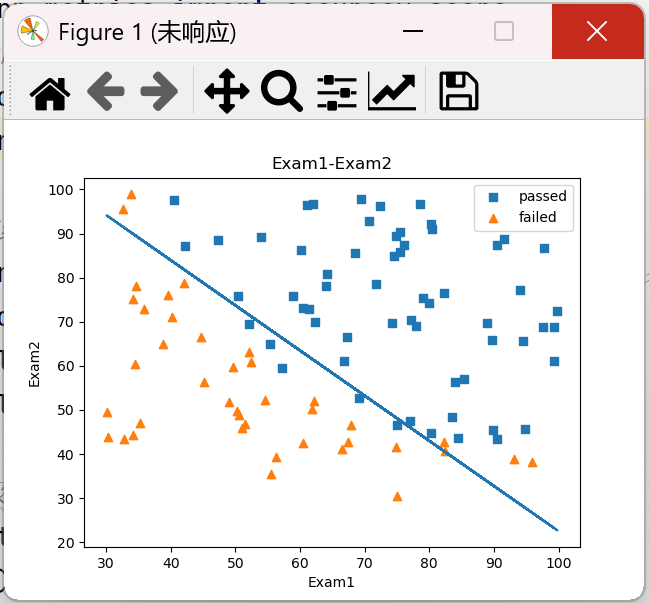
#加载数据 import torch import pandas as pd import numpy as np # 原始数据绘图 from matplotlib import pyplot as plt data = pd.read_csv('./data/examdata.csv') #增加标签mask mask = data.loc[:,'Pass'] == 1 #如果Pass列的值等于1,则mask的值为true print(mask) passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask],marker='s') # 绘制pass值为true的点 failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask],marker='^') # ~表示取反 plt.title('Exam1-Exam2') plt.xlabel('Exam1') plt.ylabel('Exam2') plt.legend((passed,failed),('passed','failed')) plt.show()
结果:

第四步:赋值数据,得到除pass的数据和仅pass以及exam1和exam2的数据
# 将数据赋值给相关变量 x = data.drop(['Pass'], axis=1) # 这里是去除pass那一列,axis=1表示去除这一列 y = data.loc[:, 'Pass'] # 将pass那一列的值赋给y x1 = data.loc[:, 'Exam1'] # 将Exam1那一列的值赋给x1 x2 = data.loc[:, 'Exam2'] # 将Exam2那一列的值赋给x2
第五步:训练模型
#建立模型以及训练模型 from sklearn.linear_model import LogisticRegression LR = LogisticRegression() LR.fit(x,y) #训练模型
第六步:预测结果
#预测结果 y_predict = LR.predict(x) print(y_predict)
第七步:根据我们的预测结果进行评估模型表现
accuracy /ˈækjʊrəsi/
#预测结果 #评估模型表现 看一下准确率 from sklearn.metrics import accuracy_score accuracy = accuracy_score(y,y_predict) print(accuracy)
accuracy的值为0.89
预测结果:
y_test = LR.predict([[70,65]]) print(y_test)
结果:[1]
所以能通过考试
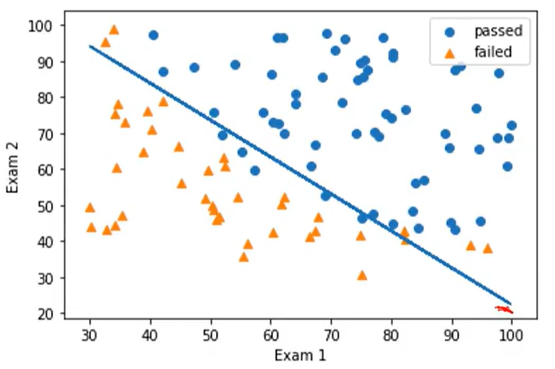
第八步:确定边界函数
1.根据逻辑回归方程得到截距θ0和θ1,θ2;
2.然后根据方程求得x2_new,然后根据方程绘画一阶线性方程
求x2_new可以参照以下公式:
边界函数:θ0 + θ1x1 + θ2 x2 = 0
因为拟合后我们是可以得到θ1、θ2这些参数的,然后可以根据这些参数去求得我们基于预判函数P(x)得到的x2_new
# θ0,θ1,θ2 theta0 = LR.intercept_ theta1,theta2 = LR.coef_[0][0],LR.coef_[0][1] print(theta0,theta1,theta2) x2_new = -(theta0+theta1*x1)/theta2 print(x2_new)
第九步:绘制决策函数图像
plt.plot(x1,x2_new) #画出决策边界
完整代码:
#加载数据 import torch import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 原始数据绘图 from matplotlib import pyplot as plt data = pd.read_csv('./data/examdata.csv') # 将数据赋值给相关变量 x = data.drop(['Pass'], axis=1) # 这里是去除pass那一列 y = data.loc[:, 'Pass'] # 将pass那一列的值赋给y x1 = data.loc[:, 'Exam1'] # 将Exam1那一列的值赋给x1 x2 = data.loc[:, 'Exam2'] # 将Exam2那一列的值赋给x2 #建立模型以及训练模型 LR = LogisticRegression() LR.fit(x,y) #训练模型 #预测结果 y_predict = LR.predict(x) print(y_predict) #预测结果 #评估模型表现 看一下准确率 accuracy = accuracy_score(y,y_predict) print(accuracy) y_test=LR.predict([[70,65]])
print(y_test) # θo,θ1,θ2 theta0 = LR.intercept_ # 截距 theta1, theta2 = LR.coef_[0][0], LR.coef_[0][1] # 系数 print(theta0, theta1, theta2) x2_new = -(theta0 + theta1 * x1) / theta2 print(x2_new) #增加标签mask mask = data.loc[:,'Pass'] == 1 #如果Pass列的值等于1,则mask的值为true print(mask) passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask],marker='s') # 绘制pass值为true的点 failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask],marker='^') plt.title('Exam1-Exam2') plt.plot(x1,x2_new) #画出决策边界 plt.xlabel('Exam1') plt.ylabel('Exam2') plt.legend((passed,failed),('passed','failed')) plt.show()
结果:
二阶拟合
1.首先创建新的数据边界
既然是二阶的,那么我们需要重新定义一下g(x)方程,一共两个函数x1,x2,二阶的话就会有x1^2,x2的平方,x1*x2以及一阶的x1,x2
#创建新数据 x1_2 = x1*x1 x2_2 = x2*x2 x1_x2 = x1*x2 x_new = {'x1':x1,'x2':x2,'x1^2':x1_2,'x2^2':x2_2,'x1x2':x1_x2}#将所有数据放到一个字典里面 x_new = pd.DataFrame(x_new) #方便后面进行模型数据的加载 print(x_new)#预览
结果:
Backend qtagg is interactive backend. Turning interactive mode on. x1 x2 x1^2 x2^2 x1x2 0 34.623660 78.024693 1198.797805 6087.852690 2701.500406 1 30.286711 43.894998 917.284849 1926.770807 1329.435094 2 35.847409 72.902198 1285.036716 5314.730478 2613.354893 3 60.182599 86.308552 3621.945269 7449.166166 5194.273015 4 79.032736 75.344376 6246.173368 5676.775061 5954.672216 .. ... ... ... ... ... 95 83.489163 48.380286 6970.440295 2340.652054 4039.229555 96 42.261701 87.103851 1786.051355 7587.080849 3681.156888 97 99.315009 68.775409 9863.470975 4730.056948 6830.430397 98 55.340018 64.931938 3062.517544 4216.156574 3593.334590 99 74.775893 89.529813 5591.434174 8015.587398 6694.671710
2、建立并训练一个新的模型
#建立并训练一个新模型 LR2 = LogisticRegression() LR2.fit(x_new,y)
3、进行模型评估
此时LR2.predict()中的参数不仅是x1,x2这两个参数了,还需要x_new概括整个(包括x1*x2,x1^2等等)
#模型评估 y2_predict = LR2.predict(x_new) accuracy2 = accuracy_score(y,y2_predict) print(accuracy2)
结果:1.0
即预测正确率100%
4、确定二阶边界函数
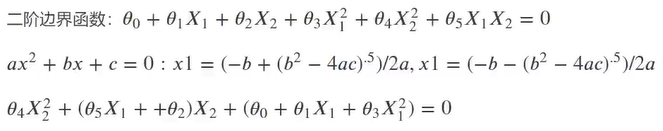
由于x1=(-b-(b2 - 4ac).5)/2a的值为负数,故这个解我们去掉。
我们先根据θ0 、 θ1 、 θ2 、 θ3 、 θ4 、 θ5 和X1的值计算出a、b、c,然后根据a、b、c的值计算出x2的值,有了x2的值就可以画出边界函数图像。
首先需要对x1进行排序,不然图像会出现混乱,保证后面画图不出现交叉
x1_new = x1.sort_values() #将x1_new从小到大排序
print(x1_new) #预览
不排序的结果如下:
因为是二阶边界函数g(x),所以我们需要求解θ0,θ1 ,θ2,θ3,θ4,θ5(具体实现如下图所示:)
#θo,θ1,θ2,θ3,θ4,θ5 theta0 = LR2.intercept_ theta1,theta2,theta3,theta4,theta5 = LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4] a = theta4 b = theta5*x1_new+theta2 c = theta0+theta1*x1_new+theta3*x1_new*x1_new x2_new_boundary = (-b+np.sqrt(b*b-4*a*c))/(2*a) # x2的值,即边界函数纵坐标的值 print(x2_new_boundary)
结果:
63 136.635865 1 135.279599 57 122.501840 70 121.741859 36 115.751248 ... 56 39.038986 47 39.015967 51 38.749210 97 38.741857 75 38.653927 Name: Exam1, Length: 100, dtype: float64
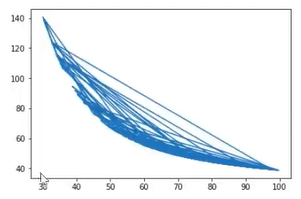
5、绘制二阶边界函数图像
plt.plot(x1_new,x2_new_boundary) #画出决策边界
图像如下:
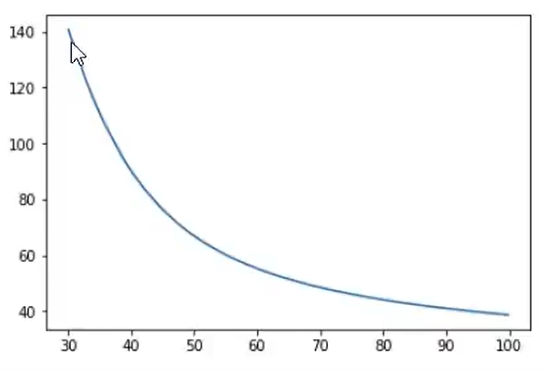
完整代码:
#加载数据 import torch import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 原始数据绘图 from matplotlib import pyplot as plt data = pd.read_csv('./data/examdata.csv') # 将数据赋值给相关变量 x = data.drop(['Pass'], axis=1) # 这里是去除pass那一列 y = data.loc[:, 'Pass'] # 将pass那一列的值赋给y x1 = data.loc[:, 'Exam1'] # 将Exam1那一列的值赋给x1 x2 = data.loc[:, 'Exam2'] # 将Exam2那一列的值赋给x2 #建立一个二阶的边界 #创建新数据 x1_2 = x1*x1 x2_2 = x2*x2 x1_x2 = x1*x2 x_new = {'x1':x1,'x2':x2,'x1^2':x1_2,'x2^2':x2_2,'x1x2':x1_x2}#将所有数据放到一个字典里面 x_new = pd.DataFrame(x_new) #方便后面进行模型数据的加载 print(x_new)#预览 #建立并训练一个新模型 LR2 = LogisticRegression() LR2.fit(x_new,y) #模型评估 y2_predict = LR2.predict(x_new) accuracy2 = accuracy_score(y,y2_predict) print(accuracy2) x1_new = x1.sort_values() #将x1_new从小到大排序 print(x1_new) #预览 #θo,θ1,θ2,θ3,θ4,θ5 theta0 = LR2.intercept_ theta1,theta2,theta3,theta4,theta5 = LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4] a = theta4 b = theta5*x1_new+theta2 c = theta0+theta1*x1_new+theta3*x1_new*x1_new x2_new_boundary = (-b+np.sqrt(b*b-4*a*c))/(2*a) print(x2_new_boundary) #增加标签mask mask = data.loc[:,'Pass'] == 1 #如果Pass列的值等于1,则mask的值为true print(mask) passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask],marker='s') # 绘制pass值为true的点 failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask],marker='^') plt.title('Exam1-Exam2') plt.plot(x1_new,x2_new_boundary) #画出决策边界 plt.xlabel('Exam1') plt.ylabel('Exam2') plt.legend((passed,failed),('passed','failed')) plt.show()
结果:
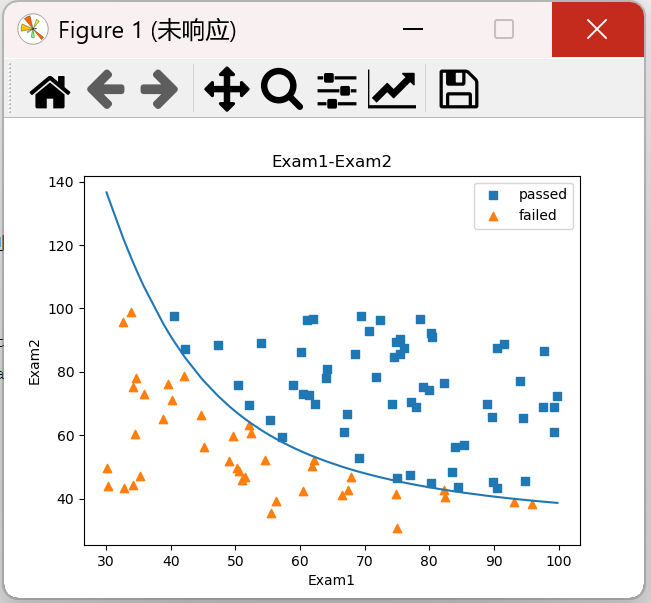
五、实战(二):芯片质量预测
数据集
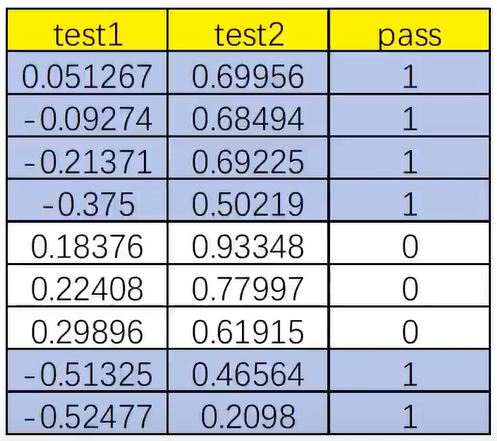
1、基于chip test.csv数据,建立逻辑回归模型(二阶边界),评估模型表现;
2、以函数的方式求解边界曲线
3、描绘出完整的决策边界曲线
1、加载数据集
# 导入模块
import torch import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score import numpy as np #加载数据 import pandas as pd data = pd.read_csv('./data/chip_test.csv') print(data)
结果:
test1 test2 pass 0 0.051267 0.699560 1 1 -0.092742 0.684940 1 2 -0.213710 0.692250 1 3 -0.375000 0.502190 1 4 0.183760 0.933480 0 .. ... ... ... 113 -0.720620 0.538740 0 114 -0.593890 0.494880 0 115 -0.484450 0.999270 0 116 -0.006336 0.999270 0 117 0.632650 -0.030612 0 [118 rows x 3 columns]
chip_test.csv文件免费下载:
通过网盘分享的文件:chip_test.csv 链接: https://pan.baidu.com/s/1kCyzEnf267ucEk392IgaRw 提取码: tmbg --来自百度网盘超级会员v6的分享
2、添加标签区分
#添加标记 mask = data.loc[:,'pass']==1 print(mask) #可视化有标记的数据 fig1 = plt.figure() passed = plt.scatter(data.loc[:,'test1'][mask],data.loc[:,'test2'][mask]) failed = plt.scatter(data.loc[:,'test1'][~mask],data.loc[:,'test2'][~mask]) plt.title('test1-test2') plt.xlabel('test1') plt.ylabel('test2') plt.legend((passed,failed),('passed','failed')) plt.show()
结果:
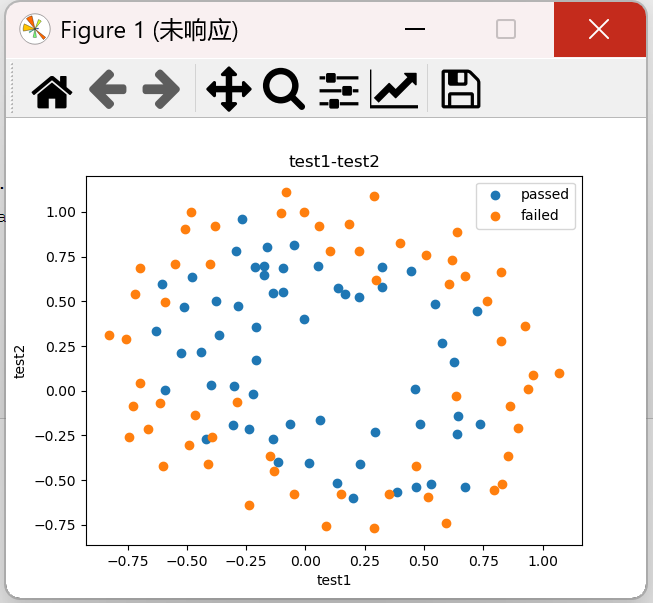
3、建立新数据集
#定义 X,y X = data.drop(['pass'],axis=1) # x为test1和test2两列 axis=1表示去掉列 y = data.loc[:,'pass'] # y为pass列 X1 = data.loc[:,'test1'] X2 = data.loc[:,'test2'] #create new data # 增加二次项特征 X1_2 = X1*X1 X2_2 = X2*X2 X1_X2 = X1*X2 X_new = {'X1':X1,'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1_X2':X1_X2} X_new = pd.DataFrame(X_new) print(X_new)
结果:
X1 X2 X1_2 X2_2 X1_X2 0 0.051267 0.699560 0.002628 0.489384 0.035864 1 -0.092742 0.684940 0.008601 0.469143 -0.063523 2 -0.213710 0.692250 0.045672 0.479210 -0.147941 3 -0.375000 0.502190 0.140625 0.252195 -0.188321 4 0.183760 0.933480 0.033768 0.871385 0.171536 .. ... ... ... ... ... 113 -0.720620 0.538740 0.519293 0.290241 -0.388227 114 -0.593890 0.494880 0.352705 0.244906 -0.293904 115 -0.484450 0.999270 0.234692 0.998541 -0.484096 116 -0.006336 0.999270 0.000040 0.998541 -0.006332 117 0.632650 -0.030612 0.400246 0.000937 -0.019367 [118 rows x 5 columns]
4、建立并训练模型
#建立并训练模型 from sklearn.linear_model import LogisticRegression LR = LogisticRegression() LR.fit(X_new,y)
5、预测模型
y_predict = LR.predict(X_new) # 使用训练好的模型预测
print(y_predict)
结果:
[1 1 1 1 0 1 1 1 1 1 1 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 0 1 0 0 1]
6、评估模型
# 计算准确率 from sklearn.metrics import accuracy_score accuracy = accuracy_score(y,y_predict) print(accuracy)
结果:0.8135593220338984
7、获取边界函数图像X2的值
# 获取theta theta0 = LR.intercept_ theta1,theta2,theta3,theta4,theta5 = LR.coef_[0][0],LR.coef_[0][1],LR.coef_[0][2],LR.coef_[0][3],LR.coef_[0][4] print(theta1,theta2,theta3,theta4,theta5) # 计算a、b、c a = theta4 b = theta5*X1_new+theta2 c = theta0+theta1*X1_new+theta3*X1_new*X1_new print(a,b,c) # 计算X2_new_boundary X2_new_boundary = (-b+np.sqrt(b*b-4*a*c))/(2*a) print(X2_new_boundary)
8、绘制初步边界函数图像
plt.plot(X1_new,X2_new_boundary)
图像如下所示:

发现这里只绘制了一半,是因为上面我们只取了边界函数图像的一部分,即(-b+np.sqrt(b*b-4*a*c))/(2*a),而(-b-np.sqrt(b*b-4*a*c))/(2*a)的边界函数的值我们没有考虑。
9、画完整决策边界
(1)、以函数的方式求解边界曲线
定义f(x)用于计算上边界和下边界,
def f(x): """ 用于计算上下边界。 函数返回两个值,分别是基于输入x计算出的两个可能的X2边界值。 """ a = theta4 b = theta5*x+theta2 c = theta0+theta1*x+theta3*x*x # 方程a*x**2+b*x+c=0的两个根 X2_new_boundary1 = (-b+np.sqrt(b*b-4*a*c))/(2*a) # 上边界 X2_new_boundary2 = (-b-np.sqrt(b*b-4*a*c))/(2*a) # 下边界 return X2_new_boundary1,X2_new_boundary2
(2)、计算上下边界
# 计算上下边界 # 列表用于存储上下边界的值 X2_new_boundary1 = [] X2_new_boundary2 = [] # 取出x中的每个值,计算出对应的上、下边界 for x in X1_new: X2_new_boundary1.append(f(x)[0]) # X2_new_boundary1 X2_new_boundary2.append(f(x)[1]) # X2_new_boundary2 print(X2_new_boundary1,X2_new_boundary2)
(3)、绘制上下边界
plt.plot(X1_new,X2_new_boundary1) # 上边界
plt.plot(X1_new,X2_new_boundary2) # 下边界
结果:
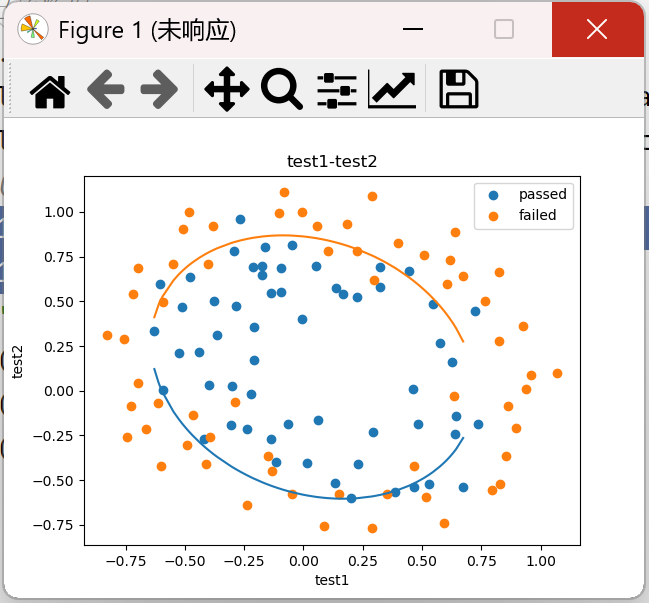
发现左右两侧均有空缺,原因是x1的值本身是有间隔的,由于中间缺了一些数,故画得不全。我们不用原来的x1,直接生成新的比较密集的数据,由于数据集中的值在[-0.9,1.1],生成[-0.9,1.1]的数据集,中间有19000个数据,再画曲线的时候,就不会有缺口了。因为此时已经有了边界函数图像,只是加密了x1的值。
10、在更密集的坐标中画决策边界
(1)、更密集的坐标中
#在更密集的坐标中 X1_range = [-0.9 + x/10000 for x in range(0,19000)] X1_range = np.array(X1_range) # 转换为NumPy数组,计算更高效 X2_new_boundary1 = [] X2_new_boundary2 = [] for x in X1_range: X2_new_boundary1.append(f(x)[0]) X2_new_boundary2.append(f(x)[1])
(2)、绘制上下边界
plt.plot(X1_range,X2_new_boundary1,'r') plt.plot(X1_range,X2_new_boundary2,'r')
结果:
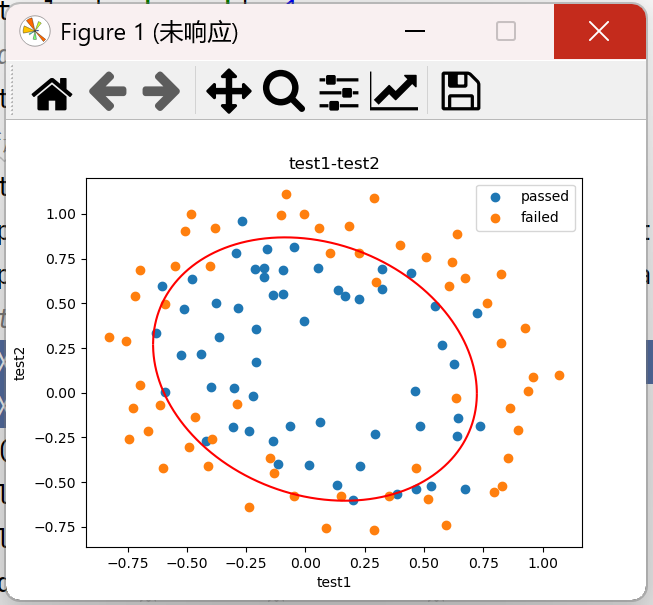
完整代码:
# 导入模块 import pandas as pd import torch from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score import numpy as np def f(x): """ 用于计算上下边界。 函数返回两个值,分别是基于输入x计算出的两个可能的X2边界值。 """ a = theta4 b = theta5*x+theta2 c = theta0+theta1*x+theta3*x*x # 方程a*x**2+b*x+c=0的两个根 X2_new_boundary1 = (-b+np.sqrt(b*b-4*a*c))/(2*a) # 上边界 X2_new_boundary2 = (-b-np.sqrt(b*b-4*a*c))/(2*a) # 下边界 return X2_new_boundary1,X2_new_boundary2 #加载数据 data = pd.read_csv('./data/chip_test.csv') # print(data) # visualize the data from matplotlib import pyplot as plt #定义 X,y X = data.drop(['pass'],axis=1) # x为test1和test2两列 axis=1表示去掉列 y = data.loc[:,'pass'] # y为pass列 X1 = data.loc[:,'test1'] X2 = data.loc[:,'test2'] #create new data # 增加二次项特征 X1_2 = X1*X1 X2_2 = X2*X2 X1_X2 = X1*X2 X_new = {'X1':X1,'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1_X2':X1_X2} X_new = pd.DataFrame(X_new) print(X_new) #建立并训练模型 from sklearn.linear_model import LogisticRegression LR = LogisticRegression() LR.fit(X_new,y) y_predict = LR.predict(X_new) # 使用训练好的模型预测 print(y_predict) # 计算准确率 accuracy = accuracy_score(y,y_predict) print(accuracy) # 对X1进行排序 X1_new = X1.sort_values() # 获取theta theta0 = LR.intercept_ theta1,theta2,theta3,theta4,theta5 = LR.coef_[0][0],LR.coef_[0][1],LR.coef_[0][2],LR.coef_[0][3],LR.coef_[0][4] print(theta1,theta2,theta3,theta4,theta5) # 计算a、b、c a = theta4 b = theta5*X1_new+theta2 c = theta0+theta1*X1_new+theta3*X1_new*X1_new print(a,b,c) # 计算X2_new_boundary X2_new_boundary = (-b+np.sqrt(b*b-4*a*c))/(2*a) print(X2_new_boundary) # d = np.array(b*b-4*a*c) # 判别式deta(拼音) # 计算上下边界 # 列表用于存储上下边界的值 X2_new_boundary1 = [] X2_new_boundary2 = [] # 取出x中的每个值,计算出对应的上、下边界 for x in X1_new: X2_new_boundary1.append(f(x)[0]) # X2_new_boundary1 上边界 X2_new_boundary2.append(f(x)[1]) # X2_new_boundary2 下边界 print(X2_new_boundary1,X2_new_boundary2) #在更密集的坐标中 X1_range = [-0.9 + x/10000 for x in range(0,19000)] X1_range = np.array(X1_range) # 转换为NumPy数组,计算更高效 X2_new_boundary1 = [] X2_new_boundary2 = [] for x in X1_range: X2_new_boundary1.append(f(x)[0]) X2_new_boundary2.append(f(x)[1]) #添加标记 mask = data.loc[:,'pass']==1 # print(mask) import matplotlib.pyplot as plt #可视化有标记的数据 fig1 = plt.figure() passed = plt.scatter(data.loc[:,'test1'][mask],data.loc[:,'test2'][mask]) failed = plt.scatter(data.loc[:,'test1'][~mask],data.loc[:,'test2'][~mask]) # plt.plot(X1_new,X2_new_boundary) plt.plot(X1_range,X2_new_boundary1,'r') plt.plot(X1_range,X2_new_boundary2,'r') plt.title('test1-test2') plt.xlabel('test1') plt.ylabel('test2') plt.legend((passed,failed),('passed','failed')) plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号