一、图像基础知识
1、图像基本概念
2、图像的加载

import torch import numpy as np import matplotlib.pyplot as plt # 像素值的理解 def test01(): # 全0数组是黑色的图像 # [200, 200, 3]中第一个200表示有200个二维数组,第二个200表示每个二维数组中有200个一维数组,3表示每个一维数组中有3个元素。 img = np.zeros([200, 200, 3]) # 展示图像 plt.imshow(img) plt.show() test01()
结果:
另一种写法:
def test03(): # 创建一个全黑的图像,宽度为100像素,高度为100像素 width, height = 100, 100 black_image = np.zeros((height, width, 3), dtype=np.uint8) # 创建一个全黑的数组(黑色为[0, 0, 0]) # 使用matplotlib显示图像 plt.imsave('black_image.png', black_image) # 保存图像到根目录下 plt.imshow(black_image) # 显示图像 # plt.axis('off') # 不显示坐标轴 plt.show() test03()
结果:
import torch import numpy as np import matplotlib.pyplot as plt # 像素值的理解 def test01(): # 全255数组是白色的图像 img = np.full([200, 200, 3], 255) # 创建一个[200, 200, 3]形状的数组,并用255填充 # 展示图像 plt.imshow(img) plt.show() test01()
结果:
加载图片
# 图像的加载 def test02(): # 读取图像 img = plt.imread("data/img.jpg") # 图像形状 高,宽,通道 print("图像的形状(H, W, C):\n", img.shape) # 展示图像 plt.imshow(img) plt.axis("off") plt.show() test02()
结果:
图像的形状(H, W, C): (500, 793, 3)
二、CNN概述
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成:
1. 卷积层负责提取图像中的局部特征;
2. 池化层用来大幅降低参数量级(降维);
3. 全连接层用来输出想要的结果。
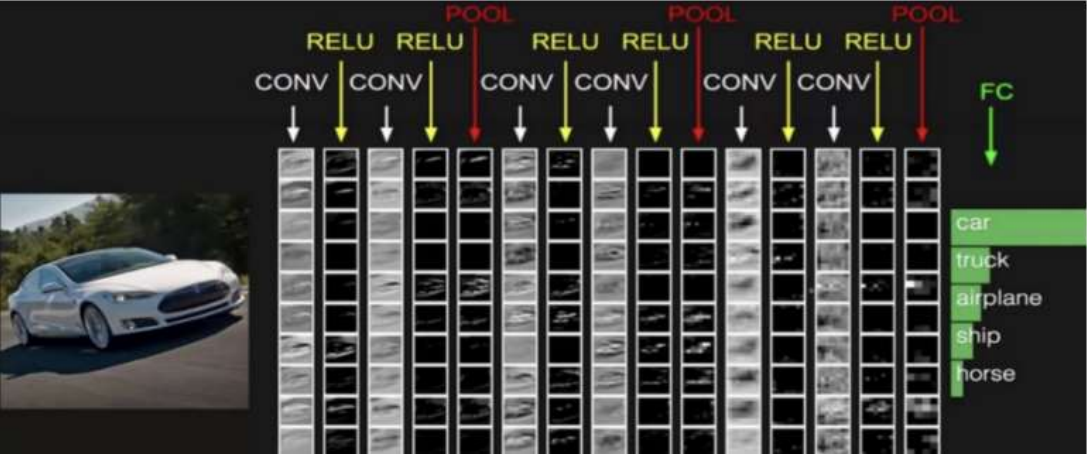
CONV表示卷积层,RELU表示激活函数,POOL表示池化层,FC(full connected)表示全连接层。最后输出每一个类别的概率值。
什么是卷积神经网络?
卷积神经网络的构成
卷积层:特征提取
池化层:降维
全连接层:输出结果
三、卷积层
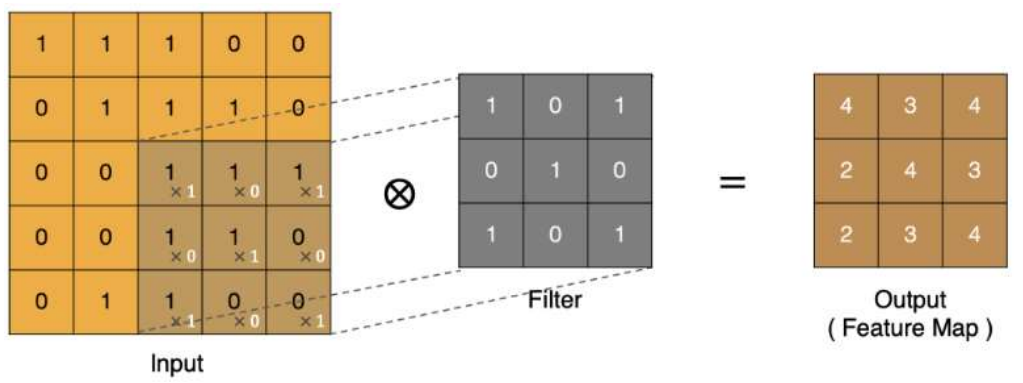
1、卷积计算
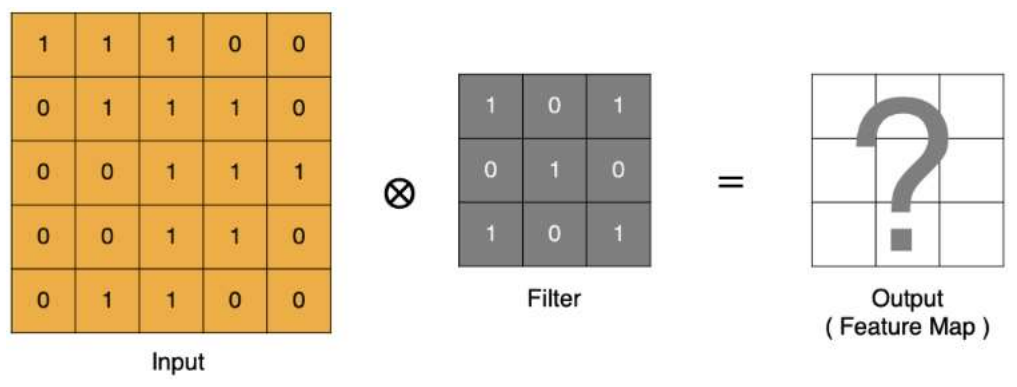
(1). input 表示输入的图像,0-255
(2). filter 表示卷积核(用来提取特征), 也叫做卷积核(滤波矩阵)。不同的卷积核(包括不同大小的卷积核)可以提取不同的特征。
(3). output 经过 filter 得到输出为最右侧的图像,该图叫做特征图(feature map)
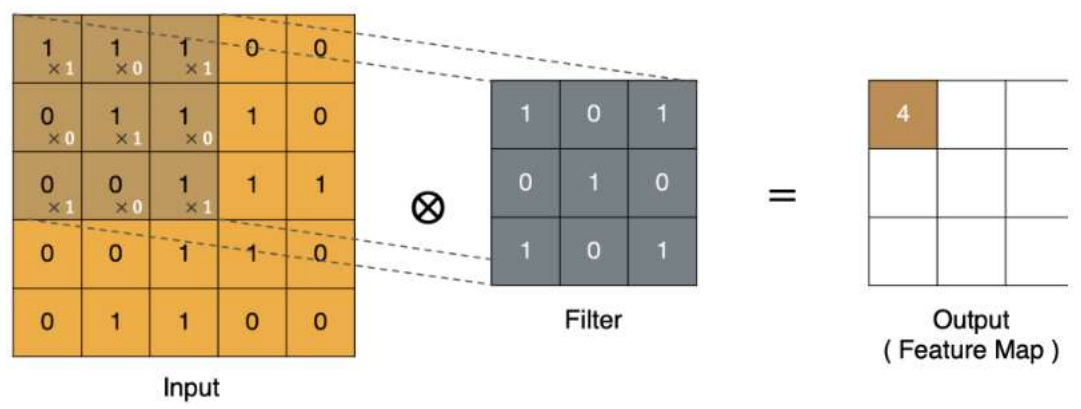
Filter就是卷积核
这里5X5的特征图卷积完成后变成3X3,图像变小了。
Padding
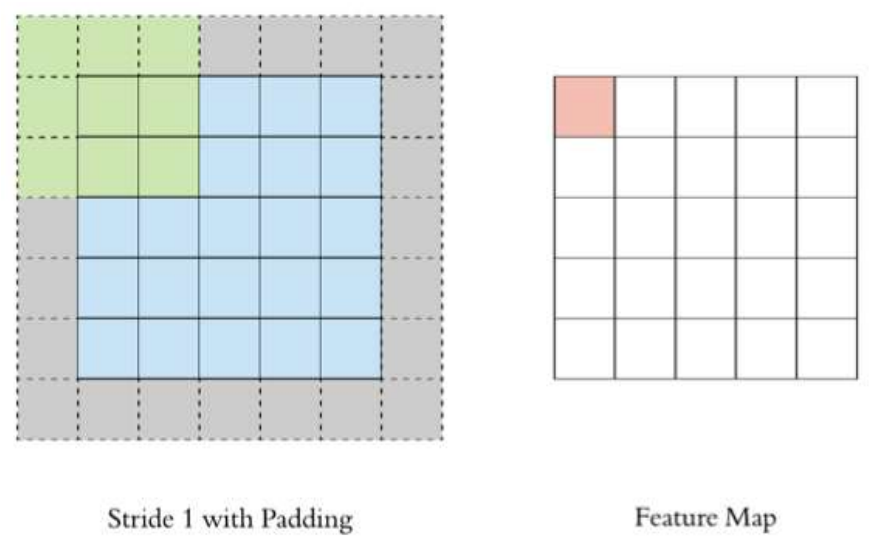
5x5的图像卷积之后还是5x5
Stride(步长)


这里向右或向下移动了两格,即隔2个像素进行扫描,stride值为2.
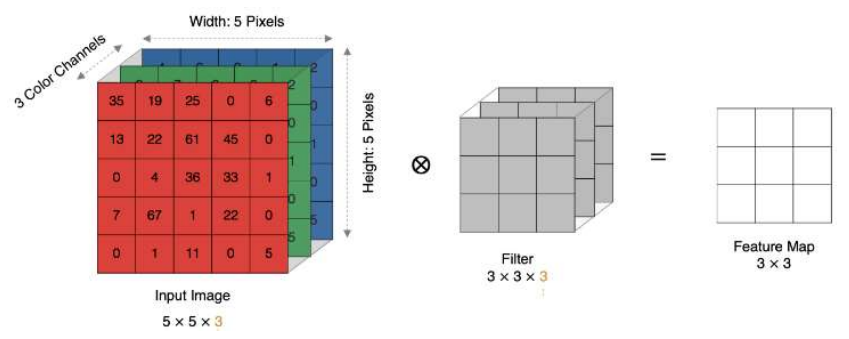
多通道(单卷积核)卷积计算
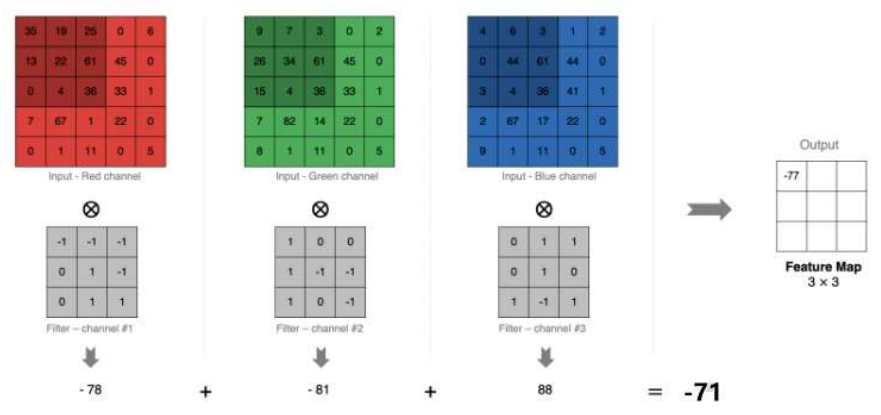
三个不同的滤波矩阵来提取特征,最后将3个特征图add起来。
多卷积核卷积计算
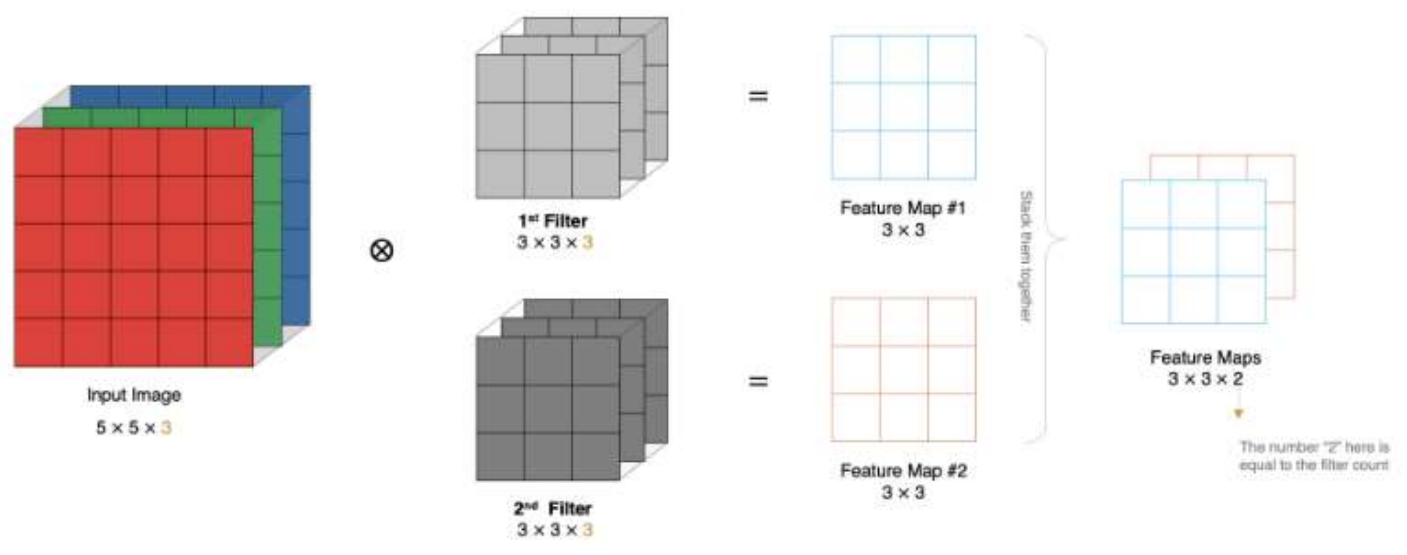
当有多个卷积核进行卷积计算时,会得到多个特征图Feature Map,然后将多个特征图堆叠(stack them together)在一起,数量等于卷积核的数量
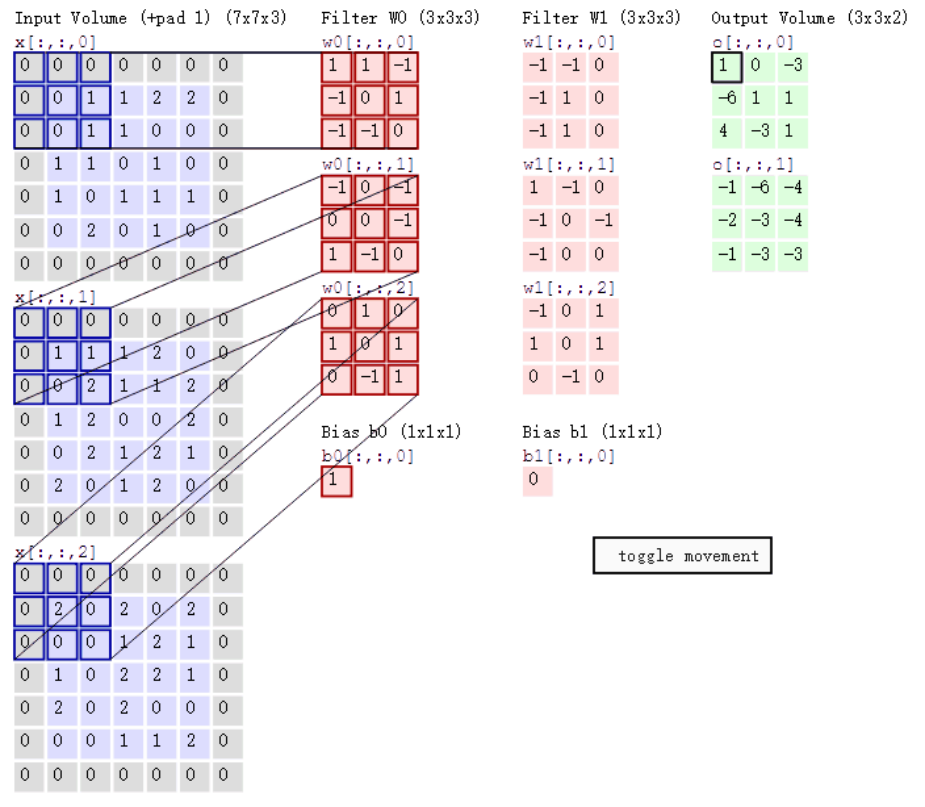
特征图大小
1. size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1*1 、3*3、5*5
2. Padding: 零填充的方式
3. Stride: 步长
那计算方法如下图所示:
1. 输入图像大小: W x W
2. 卷积核大小: F x F
3. Stride: S
4. Padding: P
5. 输出图像大小: N x N
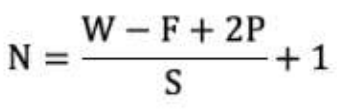
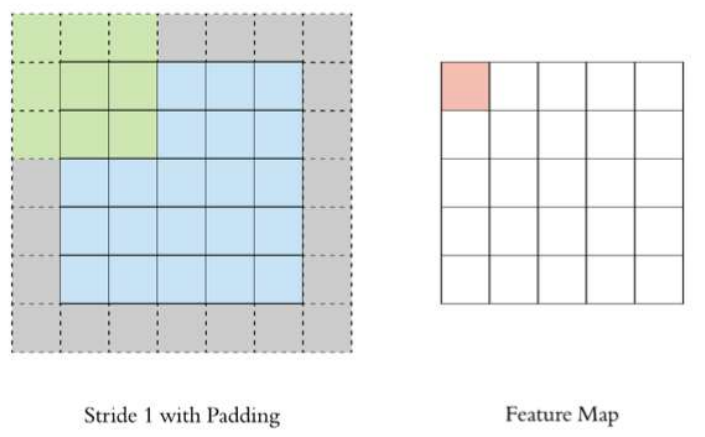
以下图为例:
1. 图像大小: 5 x 5
2. 卷积核大小: 3 x 3
3. Stride: 1
4. Padding: 1
5. (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
注意:这里的padding值为1,2P就是加2.
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) """ 参数说明: in_channels: 输入通道数, out_channels: 输出通道,也可以理解为卷积核kernel的数量 kernel_size:卷积核的高和宽设置,一般为3,5,7... stride:卷积核移动的步长 padding:在四周加入padding的数量,默认补0 """
示例
import torch import torch.nn as nn import matplotlib.pyplot as plt def test(): # 读取图像, 形状: (500, 793, 3),即图像的通道数为3 img = plt.imread('data/img.jpg') print("原始图形状:",torch.tensor(img).shape) plt.imshow(img) plt.axis('off') plt.show() # 构建卷积层 # out_channels表示卷积核个数,in_channels表示输入通道数 # 修改out_channels,stride,padding观察特征图的变化情况 conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=2, padding=0) # 输入形状: (BatchSize, Channel, Height, Width) img = torch.tensor(img).permute(2, 0, 1) # permute交换维度,将图像的形状(H,W,C)变为(C,H,W) print("交换维度后形状:",torch.tensor(img).shape) # torch.Size([3, 500, 793]) # img 形状: torch.Size([1, 3, 500, 793]) img = img.unsqueeze(0) # 在0维上升1维 print("在0维上升1维后形状:",torch.tensor(img).shape) # 在0维上升1维大小: torch.Size([1, 3, 500, 793]) # 将图像送入卷积层中 feature_map_img = conv(img.to(torch.float32)) # 打印特征图的形状 print("特征图形状:",feature_map_img.shape) # 特征图形状: torch.Size([1, 3, 249, 396]) if __name__ == '__main__': test()
结果:
原始图大小: torch.Size([500, 793, 3]) 交换维度后大小: torch.Size([3, 500, 793]) 在0维上升1维大小: torch.Size([1, 3, 500, 793]) 特征图形状: torch.Size([1, 3, 249, 396])
输出值为4维张量[1, 3, 249, 396],其中(500-3)/2 + 1=249.5,(793-3)/2 + 1=396
四、池化层
1、池化层计算
池化层 (Pooling) 对特征图降低维度, 缩减模型大小,提高计算速度.
池化的作用:降维,减小数据的大小
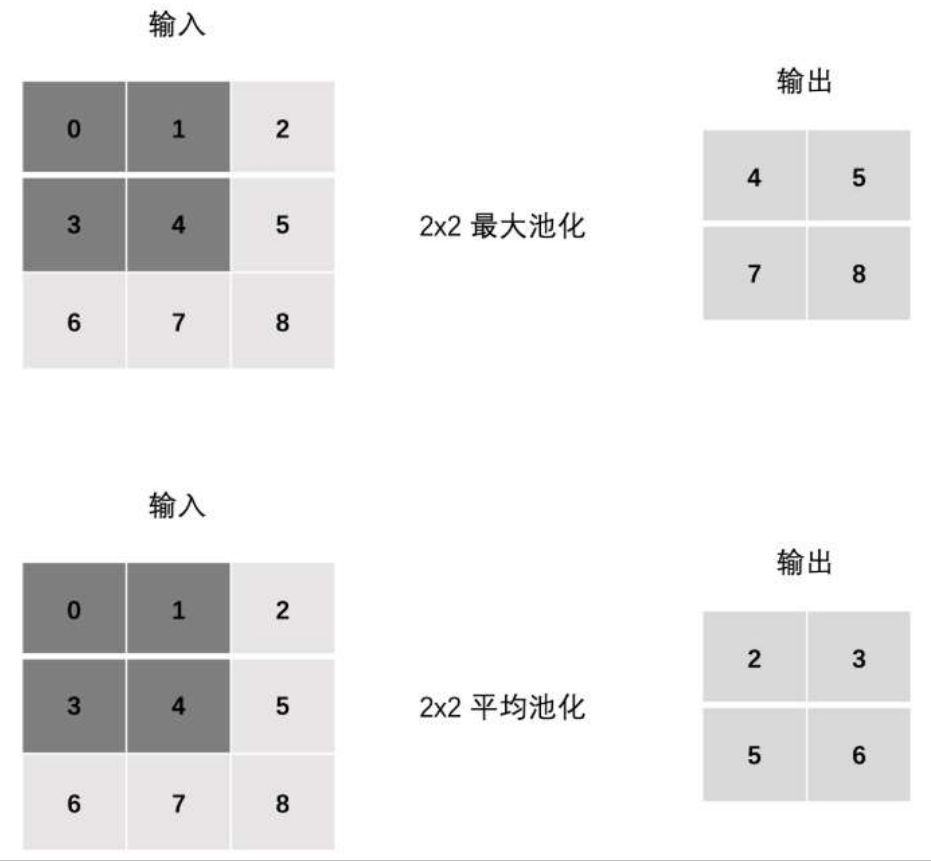
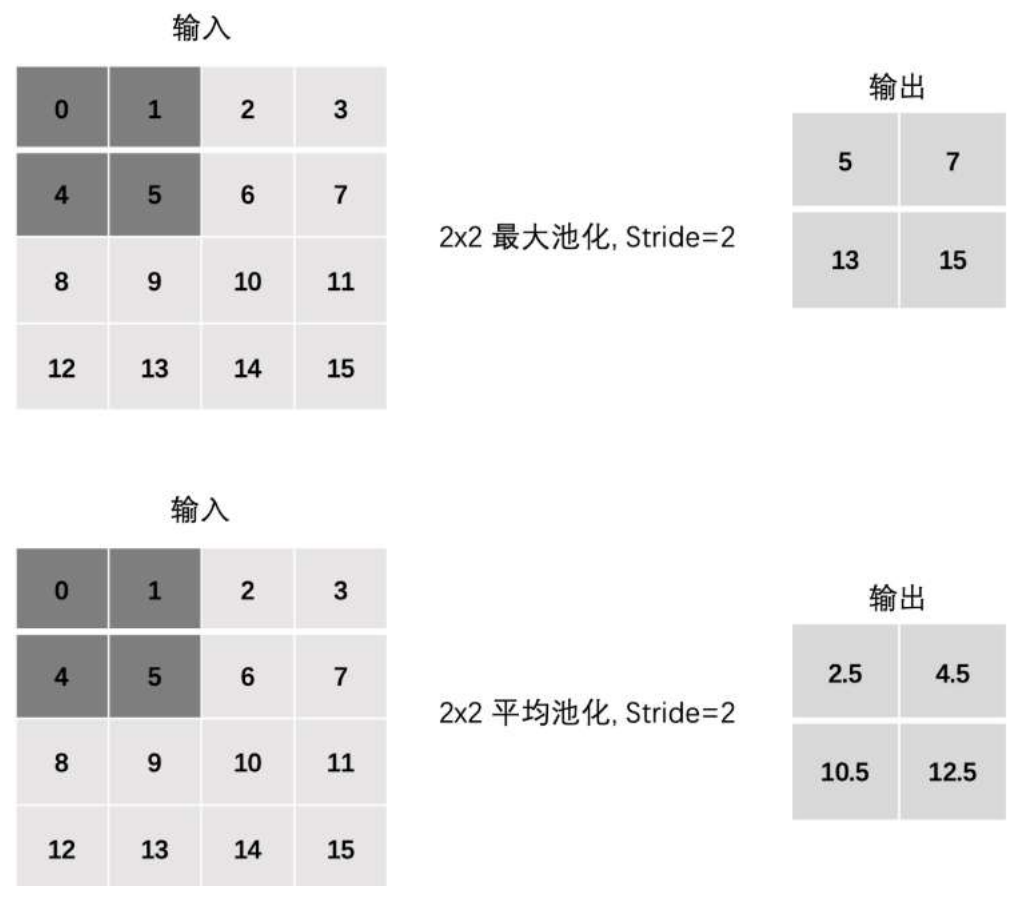
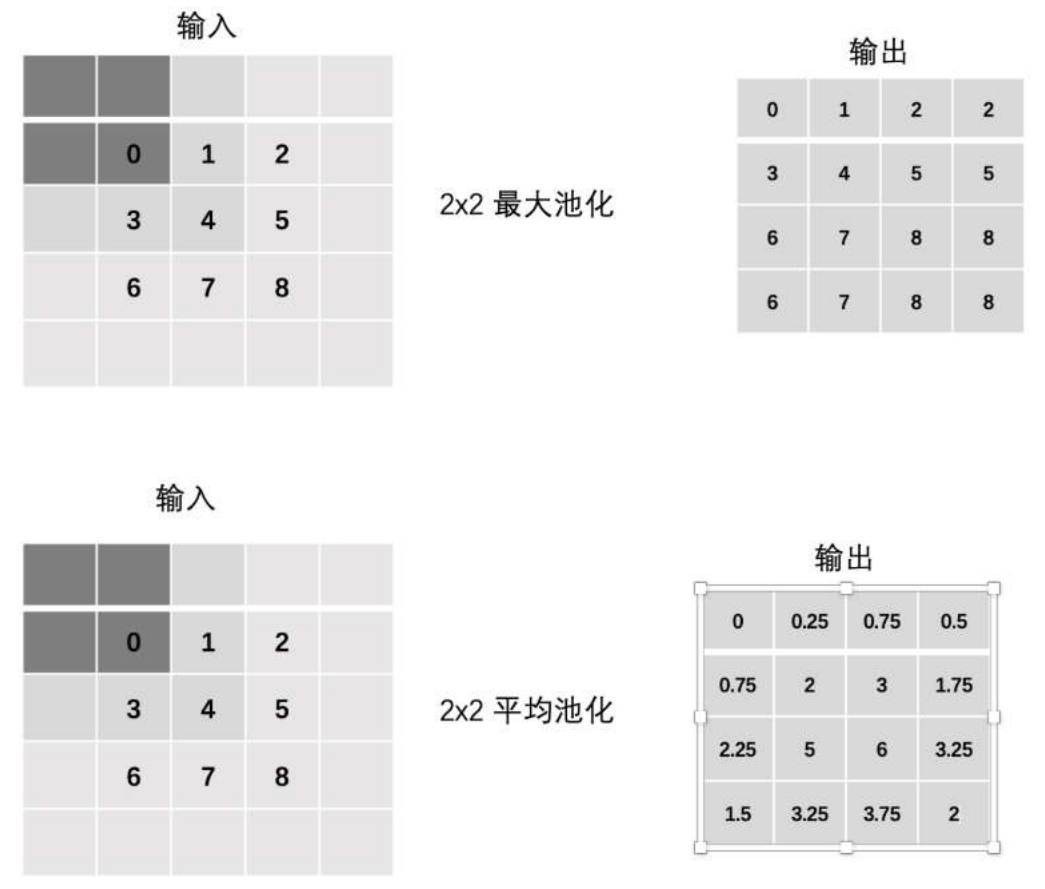
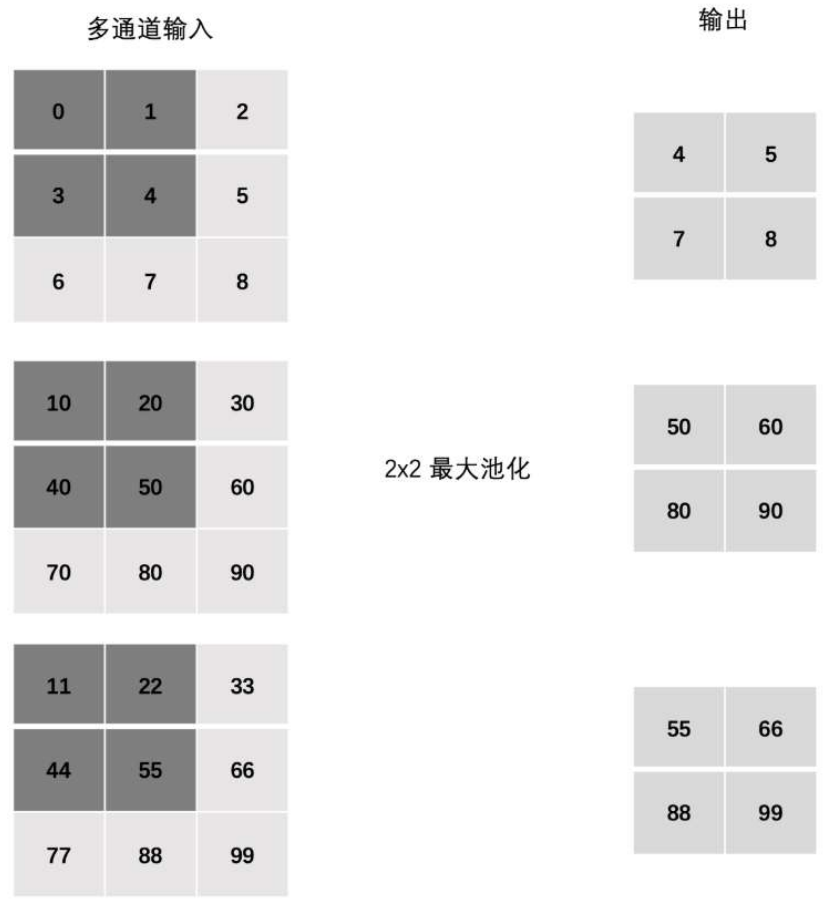
池化的分类:最大池化(MaxPool2d)和平均池化(AvgPool2d)
# 最大池化 nn.MaxPool2d(kernel_size=2, stride=2, padding=1) # 平均池化 nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
示例:
import torch import torch.nn as nn # 1. 单通道池化 def test01(): # 定义输入输数据 【1,3,3 】 inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]]]).float() # 修改stride,padding观察效果 # 1. 最大池化 polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0) output = polling(inputs) print("最大池化:\n", output) # 2. 平均池化 polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=0) output = polling(inputs) print("平均池化:\n", output) test01()
结果:
最大池化: tensor([[[4., 5.], [7., 8.]]]) 平均池化: tensor([[[2., 3.], [5., 6.]]])
多通道池化
import torch import torch.nn as nn # 2. 多通道池化 def test02(): # 定义输入输数据 【3,3,3 】 inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]], [[10, 20, 30], [40, 50, 60], [70, 80, 90]], [[11, 22, 33], [44, 55, 66], [77, 88, 99]]]).float() # 最大池化 polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0) output = polling(inputs) print("多通道池化:\n", output) test02()
结果:
多通道池化: tensor([[[ 4., 5.], [ 7., 8.]], [[50., 60.], [80., 90.]], [[55., 66.], [88., 99.]]])
五、图像分类案例
咱们使用前面的学习到的知识来构建一个卷积神经网络, 并训练该网络实现图像分类. 要完成这个案例,咱们需要学习的内容如下:
1. 了解 CIFAR10 数据集

from torchvision.datasets import CIFAR10 from torchvision.transforms import Compose from torchvision.transforms import ToTensor # 1. 数据集基本信息 def create_dataset(): # 加载数据集:训练集数据和测试数据 train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()])) valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()])) # 返回数据集结果 return train, valid if __name__ == '__main__': # 数据集加载 train_dataset, valid_dataset = create_dataset() # 数据集类别 print("数据集类别:", train_dataset.class_to_idx) # 数据集中的图像数据 print("训练集数据集:", train_dataset.data.shape) print("测试集数据集:", valid_dataset.data.shape) # 图像展示 plt.figure(figsize=(2, 2)) plt.imshow(train_dataset.data[1]) plt.title(train_dataset.targets[1]) plt.show()
结果:
数据集类别: {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
训练集数据集: (50000, 32, 32, 3)
测试集数据集: (10000, 32, 32, 3)
这是一个卡车truck的图像。
2. 搭建卷积神经网络
最终输出10个类别。
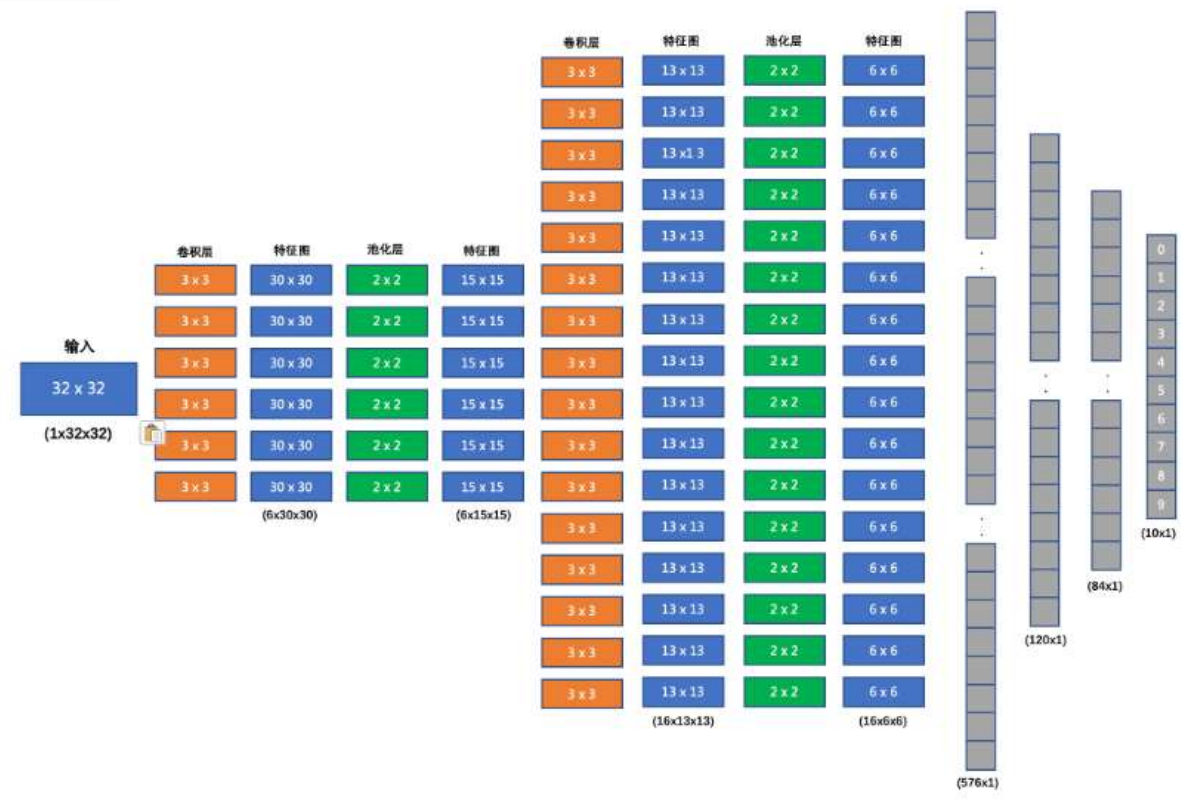
我们要搭建的网络结构如下:
1. 输入形状: 32x32
2. 第一个卷积层输入 3 个 Channel(上图中输入应该为3x32x32), 输出 6 个 Channel(输出通道out_channels,即卷积核kernel的数量), Kernel Size 为: 3x3
(32-3)/1 + 1 = 30,即第一次卷积之后特征值为30x30
3. 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
(30-2)/2+1=15,即经过池化层后特征图变为15x15
4. 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
(15-3)/1+1 = 13,即经过第二次卷积之后,特征图变为13x13
5. 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
(13-2)/2+1 = 6.5,即经过第二次池化后,特征图大小变为6x6
6. 第一个全连接层输入 576 维, 输出 120 维
7. 第二个全连接层输入 120 维, 输出 84 维
8. 最后的输出层输入 84 维, 输出 10 维
3. 编写训练函数
4. 编写预测函数
# 1.导入依赖包 import torch import torch.nn as nn from torchvision.datasets import CIFAR10 from torchvision.transforms import ToTensor from torchvision.transforms import Compose import torch.optim as optim from torch.utils.data import DataLoader import time import matplotlib.pyplot as plt from torchsummary import summary BATCH_SIZE = 8 # 2. 获取数据集 def create_dataset(): # 加载数据集:训练集数据和测试数据 train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()])) # train值为true表示是训练集 valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()])) # train值为false表示不是训练集,即为测试集 # 返回数据集结果 return train, valid # if __name__ == '__main__': # # 数据集加载 # train_dataset, valid_dataset = create_dataset() # # 数据集类别 # print("数据集类别:", train_dataset.class_to_idx) # # 数据集中的图像数据 # print("训练集数据集:", train_dataset.data.shape) # print("测试集数据集:", valid_dataset.data.shape) # # 图像展示 # plt.figure(figsize=(2, 2)) # plt.imshow(train_dataset.data[1]) # plt.title(train_dataset.targets[1]) # plt.show() # 3.模型构建 class ImageClassification(nn.Module): # 定义网络结构 def __init__(self): super(ImageClassification, self).__init__() # 定义网络层:卷积层+池化层 self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3) self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3) self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 全连接层 self.linear1 = nn.Linear(576, 120) self.linear2 = nn.Linear(120, 84) self.out = nn.Linear(84, 10) # 定义前向传播 def forward(self, x): # 卷积+relu+池化 x = torch.relu(self.conv1(x)) x = self.pool1(x) # 卷积+relu+池化 x = torch.relu(self.conv2(x)) x = self.pool2(x) # 将特征图做成以为向量的形式:相当于特征向量 x = x.reshape(x.size(0), -1) # reshape方法改变数据的形状,列为-1表示列不指定,根据行来确定列值。x.size(0)表示获取x的行数,x.size(0)的值为8 # 全连接层 x = torch.relu(self.linear1(x)) x = torch.relu(self.linear2(x)) # 返回输出结果 return self.out(x) # if __name__ == '__main__': # # 模型实例化 # model = ImageClassification() # summary(model, input_size=(3, 32, 32), batch_size=1) # 4.训练函数编写 def train(model, train_dataset): criterion = nn.CrossEntropyLoss() # 构建多分类交叉熵损失函数 optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法,Adam优化器 epoch = 20 # 训练轮数 for epoch_idx in range(epoch): # 构建数据加载器 dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True) # shuffle为true表示打乱数据的顺序 sam_num = 0 # 样本数量 total_loss = 0.0 # 损失总和 start = time.time() # 开始时间 # 遍历数据进行网络训练 for x, y in dataloader: output = model(x) # 将数据送入网络中 loss = criterion(output, y) # 计算损失 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 参数更新 total_loss += loss.item() # 统计损失和 sam_num += 1 print('epoch:%2s loss:%.5f time:%.2fs' % (epoch_idx + 1, total_loss / sam_num, time.time() - start)) # 模型保存 torch.save(model.state_dict(), 'data/image_classification.pth') def test(valid_dataset): # 构建数据加载器 dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True) # 加载模型并加载训练好的权重 model = ImageClassification() model.load_state_dict(torch.load('data/image_classification.pth')) model.eval() # 计算精度 total_correct = 0 total_samples = 0 # 遍历每个batch的数据,获取预测结果,计算精度 for x, y in dataloader: output = model(x) total_correct += (torch.argmax(output, dim=-1) == y).sum() total_samples += len(y) # 打印精度 print('Acc: %.2f' % (total_correct / total_samples)) if __name__ == '__main__': # 数据集加载 train_dataset, valid_dataset = create_dataset() # 模型实例化 model = ImageClassification() # 模型训练 # train(model, train_dataset) # 模型预测 test(valid_dataset)
模型参数输出:
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [1, 6, 30, 30] 168 MaxPool2d-2 [1, 6, 15, 15] 0 Conv2d-3 [1, 16, 13, 13] 880 MaxPool2d-4 [1, 16, 6, 6] 0 Linear-5 [1, 120] 69,240 Linear-6 [1, 84] 10,164 Linear-7 [1, 10] 850 ================================================================ Total params: 81,302 Trainable params: 81,302 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.01 Forward/backward pass size (MB): 0.08 Params size (MB): 0.31
训练结果:
epoch: 1 loss:1.61376 time:44.82s epoch: 2 loss:1.31522 time:44.24s epoch: 3 loss:1.20431 time:40.55s epoch: 4 loss:1.13685 time:43.41s epoch: 5 loss:1.08888 time:36.56s epoch: 6 loss:1.05069 time:29.25s epoch: 7 loss:1.01706 time:32.03s epoch: 8 loss:0.98581 time:33.38s epoch: 9 loss:0.96305 time:33.78s epoch:10 loss:0.94286 time:33.68s epoch:11 loss:0.92469 time:35.65s epoch:12 loss:0.90097 time:31.33s epoch:13 loss:0.88612 time:30.08s epoch:14 loss:0.87420 time:29.74s epoch:15 loss:0.85541 time:31.94s epoch:16 loss:0.84346 time:30.35s epoch:17 loss:0.83216 time:29.92s epoch:18 loss:0.81702 time:30.58s epoch:19 loss:0.80673 time:36.04s epoch:20 loss:0.79584 time:30.14s
测试结果:
Acc: 0.62
从程序的运行结果来看,网络模型在测试集上的准确率并不高。我们可以从以下几个方面来进行优化:
1. 增加卷积核输出通道数
2. 增加全连接层的参数量
3. 调整学习率
4. 调整优化方法
5. 修改激活函数
6. 等等...
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2022-02-07 Volatile详解
2022-02-07 多线程之锁优化
2022-02-07 内存可见性以及synchronized实现可见性和Volatile实现可见性
2022-02-07 JVM内存结构、Java对象模型和Java内存模型
2022-02-07 多线程之线程优先级
2022-02-07 多线程之线程停止
2021-02-07 Mysql训练:第二高的薪水(IFNULL,OFFSET,LIMIT)