一、字符编码和字符集
1、字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本f符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
字符编码 Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示 。
2、字符集
二进制数↔十进制数↔字符编码↔字符(文字、符号、数字)
字符集 Charset :也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
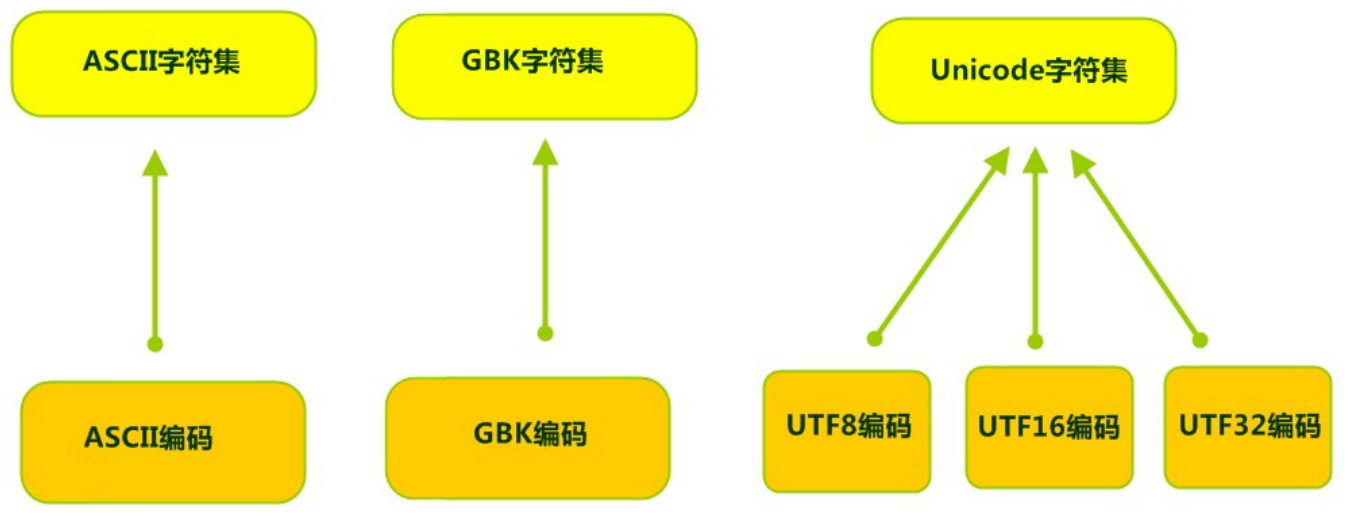
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
1)、ASCII字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
|
Bin
(二进制)
|
Oct
(八进制)
|
Dec
(十进制)
|
Hex
(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
00
|
0
|
0x00
|
NUL(null)
|
空字符
|
|
0000 0001
|
01
|
1
|
0x01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
02
|
2
|
0x02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
03
|
3
|
0x03
|
ETX (end of text)
|
正文结束
|
|
...
|
... | ... | ... | ... | ... |
|
0111 1010
|
0172
|
122
|
0x7A
|
z
|
小写字母z
|
|
0111 1011
|
0173
|
123
|
0x7B
|
{
|
开花括号
|
|
0111 1100
|
0174
|
124
|
0x7C
|
|
|
垂线
|
|
0111 1101
|
0175
|
125
|
0x7D
|
}
|
闭花括号
|
|
0111 1110
|
0176
|
126
|
0x7E
|
~
|
波浪号
|
|
0111 1111
|
0177
|
127
|
0x7F
|
DEL (delete)
|
删除
|
2)、ISO-8859-1字符集
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
ISO-5559-1使用单字节编码,兼容ASCII编码。
3)、GBxxx字符集
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
4)、Unicode字符集
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
(1)、128个US-ASCII字符,只需一个字节编码。
(2)、拉丁文等字符,需要二个字节编码。
(3)、大部分常用字(含中文),使用三个字节编码。
(4)、其他极少使用的Unicode辅助字符,使用四字节编码。
二、为什么要使用转换流?
在IDEA中,使用 FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的 UTF-8 编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
如果要读取GBK编码的文本文件,那么就需要使用转换流。
public static void main(String[] args) throws IOException { FileReader fileReader = new FileReader("C:\\Users\\miracle\\Desktop\\c.txt"); int read; while ((read = fileReader.read()) != -1 ) { System.out.print((char)read); } fileReader.close(); }
注意:现在创建txt文件都是UTF-8编码。为了进行演示,可以将txt文件另存为ANSI格式的文件,在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码;
结果如下:
���
那么如何读取GBK编码的文件呢?
public static void main(String[] args) throws IOException { InputStreamReader fileReader = new InputStreamReader(new FileInputStream("C:\\Users\\miracle\\Desktop\\c.txt"), "GBK"); int read; while ((read = fileReader.read()) != -1 ) { System.out.print((char)read); } fileReader.close(); }
结果如下:
你好
三、InputStreamReader类
转换流 java.io.InputStreamReader ,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
1、构造方法
InputStreamReader(InputStream in) : 创建一个使用默认字符集的字符流。
InputStreamReader(InputStream in, String charsetName) : 创建一个指定字符集的字符流。
构造举例,代码如下:
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt")); InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
指定编码读取

public class ReaderDemo2 { public static void main(String[] args) throws IOException { // 定义文件路径,文件为gbk编码 String FileName = "E:\\file_gbk.txt"; // 创建流对象,默认UTF8编码 InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName)); // 创建流对象,指定GBK编码 InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK"); // 定义变量,保存字符 int read; // 使用默认编码字符流读取,乱码 while ((read = isr.read()) != ‐1) { System.out.print((char)read); // ��Һ� } isr.close(); // 使用指定编码字符流读取,正常解析 while ((read = isr2.read()) != ‐1) { System.out.print((char)read);// 大家好 } isr2.close(); } }
四、OutputStreamWriter类
转换流 java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
OutputStreamWriter(OutputStream in) : 创建一个使用默认字符集的字符流。
OutputStreamWriter(OutputStream in, String charsetName) : 创建一个指定字符集的字符流。
构造举例,代码如下:
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt")); OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");
指定编码写出
public class OutputDemo { public static void main(String[] args) throws IOException { // 定义文件路径 String FileName = "E:\\out.txt"; // 创建流对象,默认UTF8编码 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName)); // 写出数据 osw.write("你好"); // 保存为6个字节 osw.close(); // 定义文件路径 String FileName2 = "E:\\out2.txt"; // 创建流对象,指定GBK编码 OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK"); // 写出数据 osw2.write("你好");// 保存为4个字节 osw2.close(); } }
转换流理解图解

五、转换文件编码
将GBK编码的文本文件,转换为UTF-8编码的文本文件。
案例分析
1)、指定GBK编码的转换流,读取文本文件。
2)、使用UTF-8编码的转换流,写出文本文件。
public class TransDemo { public static void main(String[] args) { // 1.定义文件路径 String srcFile = "file_gbk.txt"; String destFile = "file_utf8.txt"; // 2.创建流对象 // 2.1 转换输入流,指定GBK编码 InputStreamReader isr = new InputStreamReader(new FileInputStream(srcFile) , "GBK"); // 2.2 转换输出流,默认utf8编码 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(destFile)); // 3.读写数据 // 3.1 定义数组 char[] cbuf = new char[1024]; // 3.2 定义长度 int len; // 3.3 循环读取 while ((len = isr.read(cbuf))!=‐1) { // 循环写出 osw.write(cbuf,0,len); } // 4.释放资源 osw.close(); isr.close(); } }
六、使用转换流读取txt文件的内容
将读取的每行数据append到StringBuffer中。
public class TxtAnalysisTest { public static void main(String[] args) throws IOException { String lineTxt_cr = null;//行读字符串 String encoding="GBK"; File file = new File("C:\\Users\\miracle\\Desktop\\a.txt"); if(file.isFile() && file.exists()) { //判断文件是否存在 InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);//考虑到编码格式 BufferedReader bufferedReader = new BufferedReader(read); // 字符缓冲输入流 StringBuffer xpStr = new StringBuffer(); //文件文本字符串 while((lineTxt_cr = bufferedReader.readLine()) != null){ //处理字符串lineTxt_cr xpStr.append(lineTxt_cr); } // 释放资源 bufferedReader.close();
read.close(); System.out.println(xpStr); } } }
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端