在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 DISTINCT 用于返回唯一不同的值。
查询指定列并且结果不出现重复数据
SELECT DISTINCT 字段名 FROM 表名;
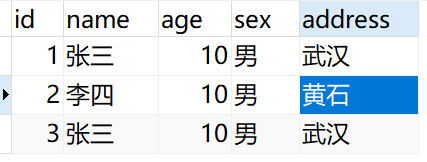
student表如下:
CREATE TABLE `student` ( `id` int(0) NOT NULL, `name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `age` int(0) NULL DEFAULT NULL, `sex` varchar(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
添加几条记录
1、单个字段进行去重
查询学生来至于哪些地方
-- 查询学生来至于哪些地方 select address from student; -- 去掉重复的记录 select distinct address from student;
结果如下:

2、多个字段去重
对name、age、sex、age四个字段去重
select distinct name,age,sex,address from student;
结果如下:

注意:不要对id进行去重,因为id都不一样,否则distinct无效。

