MySQL中索引是在存储引擎层实现的,常用的有Innodb,MyISAM存储引擎。
查看你的mysql现在提供什么存储引擎?
Show engines;
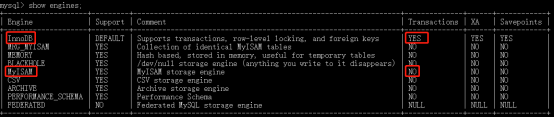
从中可以看出:默认支持的是Innodb,支持事务、行级锁定、外键。
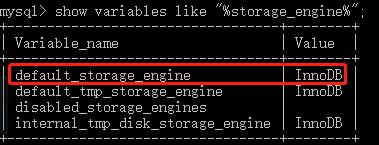
查看mysql当前默认的存储引擎:
Show variables like “%storage_engine%”;

一、InnoDB存储引擎:(适合高并发)
特点:
1. InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。相比较MyISAM存储引擎,InnoDB写的处理效率差一点并且会占用更多的磁盘空间保留数据和索引。
2. 提供了对数据库事务ACID的支持(原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability),实现了SQL标准的四种隔离级别。
3. 设计目标就是处理大容量的数据库系统,MySQL运行时InnoDB会在内存中建立缓冲池,用于缓冲数据和索引。
4. 执行“select count(*) from table”语句时需要扫描全表,因为使用innodb引擎的表不会保存表的具体行数,所以需要扫描整个表才能计算多少行。
5. InnoDB引擎是行锁,粒度更小,所以写操作不会锁定全表,在并发较高时,使用InnoDB会提升效率。即存在大量UPDATE/INSERT操作时,效率较高。
6. InnoDB清空数据量大的表时,是非常缓慢,这是因为InnoDB必须处理表中的每一行,根据InnoDB的事务设计原则,首先需要把“删除动作”写入“事务日志”,然后写入实际的表。所以,清空大表的时候,最好直接drop table然后重建。即InnoDB一行一行删除,不会重建表。
使用场景:
1. 经常UPDETE/INSERT的表,使用处理多并发的写请求
2. 支持事务,必选InnoDB。
3. 可以从灾难中恢复(日志+事务回滚)
4. 支持外键约束、列属性AUTO_INCREMENT
二、MyISAM存储引擎
特点:
1 . MyISAM不支持事务,不支持外键,SELECT/INSERT为主的应用可以使用该引擎。
2. 每个MyISAM在存储成3个文件,扩展名分别是:
1) frm:存储表定义(表结构等信息)
2) MYD(MYData),存储数据
3) MYI(MYIndex),存储索引
3. 不同MyISAM表的索引文件和数据文件可以放置到不同的路径下。
4. MyISAM类型的表提供修复的工具,可以用CHECK TABLE语句来检查MyISAM表健康,并用REPAIR TABLE语句修复一个损坏的MyISAM表。
5. 在MySQL5.6以前,只有MyISAM支持Full-text全文索引
使用场景:
1. 经常SELECT/INSERT的表,插入不频繁,查询非常频繁
2. 不支持事务
3. 做很多count 的计算。
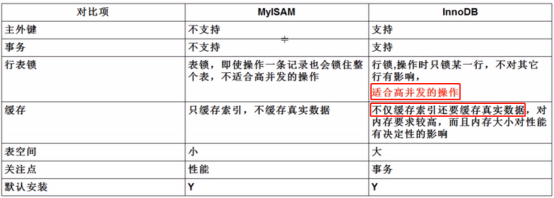
三、MyISAM和Innodb区别:
MyISAM类型不支持事务处理,而InnoDB类型支持。MyISAM类型强调的是性能,其执行速度比InnoDB类型更快,而InnoDB提供事务支持支持外键等高级数据库功能。
具体实现的差别:
1、MyISAM 是非事务安全型的,而InnoDB是事务安全型的。
2、MyISAM 锁的粒度是表级,不适合高并发的操作。而InnoDB支持行级锁定,适合高并发的操作。
3、MyISAM 不支持外键,而InnoDB支持外键
4、MyISAM只缓存索引,不缓存真实数据。Innodb不仅缓存索引还缓存真实数据,比从表中查找更快。
MyISAM 相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。
InnoDB 表比MyISAM表更安全。
互联网公司用mysql比较多。
Innodb不仅缓存索引还缓存真实数据,这样就比从表中查数据更快。
四、存储优化(插入大量数据):
1、禁用索引
对于使用索引的表,插入记录时,MySQL会对插入的记录建立索引。如果插入大量数据,建立索引会降低插入数据速度。为了解决这个问题,可以在批量插入数据之前禁用索引,数据插入完成后再开启索引。
禁用索引的语句: ALTER TABLE table_name DISABLE KEYS
开启索引语句: ALTER TABLE table_name ENABLE KEYS
2、禁用唯一性检查
唯一性校验会降低插入记录的速度,可以在插入记录之前禁用唯一性检查,插入数据完成后再开启。
禁用唯一性检查的语句:SET UNIQUE_CHECKS = 0;
开启唯一性检查的语句:SET UNIQUE_CHECKS =1;
3、禁用外键检查
插入数据之前执行禁止对外键的检查,数据插入完成后再恢复,可以提高插入速度。
禁用:SET foreign_key_checks = 0;
开启:SET foreign_key_checks = 1;
4、批量插入数据
插入数据时,可以使用一条INSERT语句插入一条数据,也可以一条INSERT语句插入多条数据。尽量使用多个值表的insert语句,这样可以大大缩短客户机与数据库的连接、关闭等损耗。这比使用分开INSERT语句快(在一些情况中几倍)。
第一种:使用Values
INSERT INTO 表名(字段1,字段2,字段3) VALUES(第一个值,第二个值,第三个值), (第1个值,第2个值,第3个值)
xml中sql:
<insert id="insert" parameterType="java.util.List"> INSERT INTO function_group_menu (id, function_group_id ,menu_id, del_flag, create_by, create_time) VALUES <foreach collection="list" item="info" separator=","> (FUNCTION_GROUP_MENU_SEQ.nextVal, #{info.functionGroupId}, #{info.menuId}, #{info.delFlag},#{info.createBy},#{info.createTime}) </foreach> </insert>
第二种: 利用UNION SELECT 批量插入
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
INSERT INTO 表名(字段1,字段2,字段3) SELECT 第一个值,第二个值,第三个值 UNION SELECT 第1个值,第2个值,第3个值
xml中sql:
<insert id="insertBatch"> insert into SYS_ENTERPRISE_STANDARD(ID,MATERIAL_NAME,MATERIAL_CODE,MATERIAL_STANDARD,MATERIAL_ADDR,STANDARD,STANDARD_DESCRIBE,CREATE_BY,CREATE_TIME,UPDATE_BY,UPDATE_TIME,ENTERPRISE_ID)<foreach collection="list" item="item" open="(" close=")" separator="union all"> select #{item.id}, #{item.materialName}, #{item.materialCode}, #{item.materialStandard}, #{item.materialAddr}, #{item.standard}, #{item.standardDescribe}, #{item.createBy}, #{item.createTime}, #{item.updateBy}, #{item.updateTime}, #{item.enterpriseId} from dual </foreach></insert>
5、禁止自动提交
插入数据之前执行禁止事务的自动提交,数据插入完成后再恢复,可以提高插入速度。
禁用:SET autocommit = 0;
开启:SET autocommit = 1;

